

Last month, Microsoft researchers published a paper with a blunt headline: large language models corrupt your documents when you delegate work to them. I think this matters a lot more than most AI coverage suggests.
Right now, much of the conversation around AI still revolves around coding. That’s important, but it’s also narrow. The bigger commercial opportunity sits inside the daily flow of knowledge work: Word documents, spreadsheets, decks, diagrams, ledgers, reports, policies, transcripts, and structured files moving through businesses all day long.
That’s exactly the space this research tries to measure.
Microsoft introduced a benchmark called DELEGATE-52. It simulates long delegated workflows across 52 professional domains and 310 work environments. These aren’t toy tasks. They’re complex, multi-step editing jobs on realistic business documents. And the headline result is hard to ignore: even the best frontier models degrade documents over time, often in ways that are hard to spot.
If you want to read the original work, you can find the Microsoft Research paper, the arXiv version, and the DELEGATE-52 benchmark repository.
Why this benchmark matters
I haven’t seen many serious evaluations aimed at delegated document work. DELEGATE-52 is one of the first that actually looks like the kind of work knowledge workers hand off every day.
The benchmark covers 52 domains including accountancy, robotics, aviation, translation, slide editing, databases, music notation, and more. Each environment contains a real source document plus 5 to 10 complex editing tasks. The model has to perform those edits across a sequence of interactions, then reverse them later.
That last point is important.
This is not “change one line and stop.” The benchmark tests long-horizon delegation. A model edits a document, then later gets asked to undo that edit and restore the original. Then it edits again, then reverts again. By the end of the whole workflow, the final document should match the starting one exactly.
That setup mirrors real delegated work much better than one-shot prompts do. In real operations, a document gets revised, reorganized, reformatted, split apart, recombined, translated, normalized, and passed through several rounds of changes. The challenge is not whether an LLM can make a change once. The challenge is whether it can make changes repeatedly without silently damaging the document.
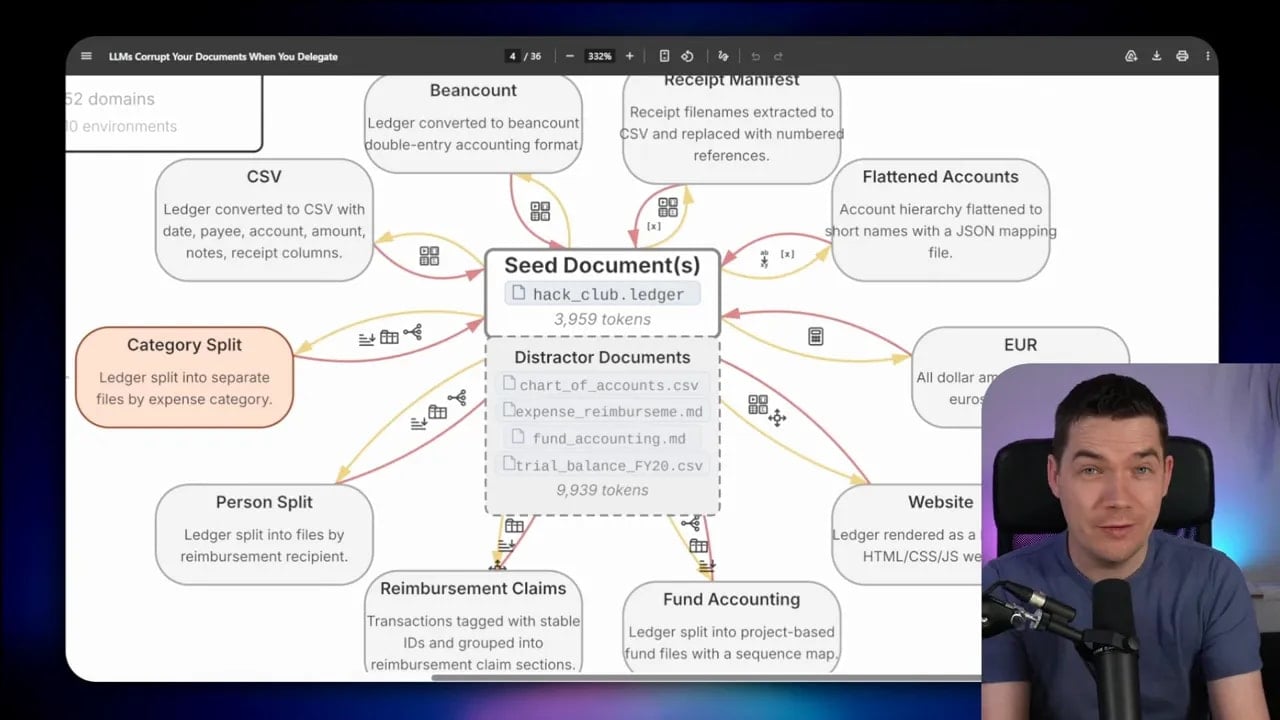
How DELEGATE-52 actually tests document reliability
Here’s the basic pattern.
Take an accounting ledger as an example. A model might first get a forward edit such as:
- Split the ledger into separate files by expense category.
Then, on the next turn, it gets a backward edit:
- Merge those category ledgers back into a single accounting ledger ordered by transaction date.
If the model handled both tasks correctly, the result should be identical to the original ledger.
The benchmark repeats this pattern many times. One edit might convert dollar amounts to euros using a stated exchange rate. The next asks the model to convert them back. Another might extract receipt filenames into a CSV and replace them with numeric references. The revert step should restore the original references in the original document.
After 10 of these round trips, or 20 interactions total, the source document should still be intact.
That’s a clean and clever way to measure delegated editing. It doesn’t ask whether the model produced something plausible. It asks whether the document survived the workflow.
The results are worse than most people expect
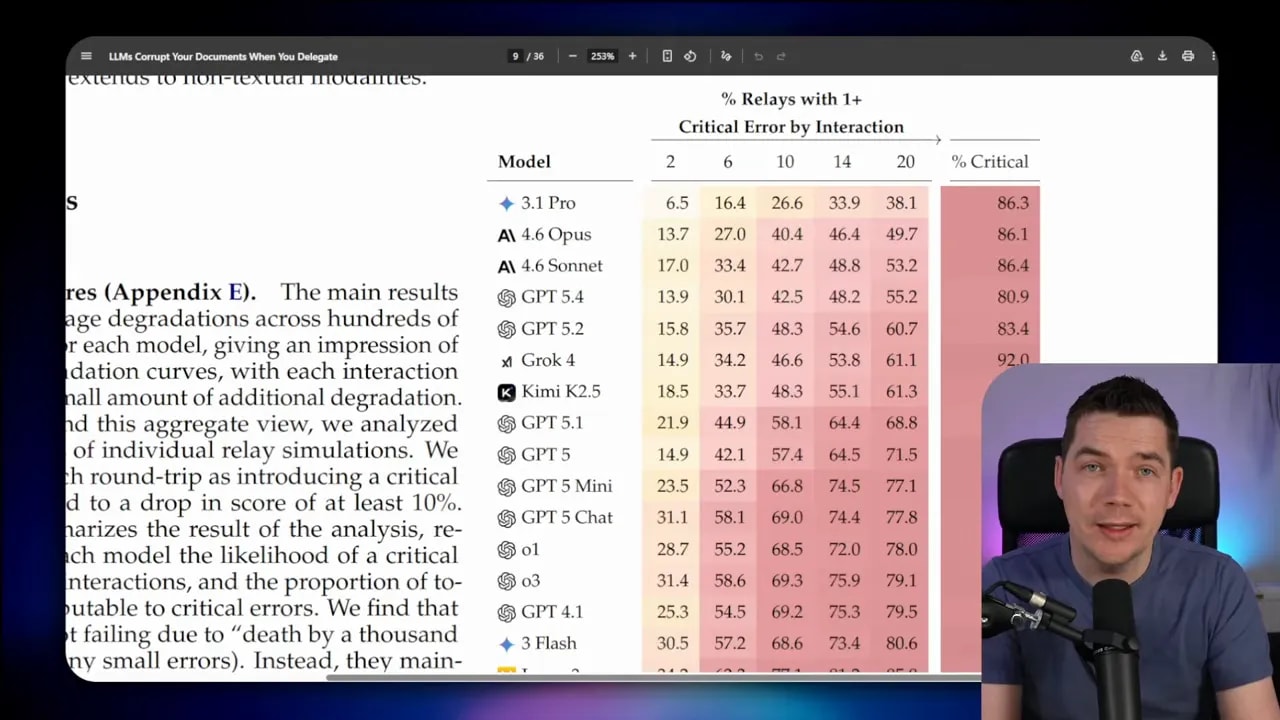
Microsoft evaluated 19 models across six model families: OpenAI, Anthropic, Google, Mistral, xAI, and Moonshot.
The broad result was clear: current models degrade documents during delegation.
Even frontier systems like Gemini 3.1 Pro, Claude 4.6 Opus, and GPT-5-class models ended long workflows with roughly 25% content corruption on average. Across all tested models, average degradation was closer to 50%.
That alone is striking. But the failure pattern is even more important than the average score.
Most runs did not degrade smoothly. Models often looked competent for several rounds. They reconstructed documents almost perfectly, then suddenly fell off a cliff in one interaction. A single turn could wipe out 10, 20, or even 30 points of reconstruction quality.
According to the paper, about 80% of total degradation came from these rare but severe failures.
That means stronger models don’t really eliminate the problem. They mostly delay it. One of the better models in the study still hit at least one critical failure in the vast majority of runs by the time it reached 20 interactions.
There’s also a subtle risk here. Better models tend to preserve document structure while corrupting content. So the file still looks polished. The headings stay in place. The table shape still looks right. The formatting may even appear untouched. But the actual substance inside the document has drifted.
Weaker models often fail more visibly by deleting chunks outright. That sounds worse, but it’s actually easier to catch. A polished-looking wrong answer is the more dangerous failure mode for delegated work.
Performance depends on the domain
The models weren’t equally bad across all document types.
They did better in more programmatic domains like Python and databases. They did worse in natural language-heavy and niche professional formats such as earnings statements and music notation.
That tracks with what many builders already see in practice. Code and structured text give the model tighter rules. Business documents often mix prose, formatting, embedded references, subtle context, domain conventions, and fragile ordering constraints. That creates far more room for quiet corruption.
The researchers set a pretty reasonable threshold for delegated readiness: a model needs to score 98% or higher after 20 interactions in a domain.
Out of all 52 domains, Python was the only one that met that bar.
That tells you something important. The issue is not just that models make mistakes. The issue is that most business document workflows still don’t support safe delegation without extra control layers.
I ran the benchmark myself
One thing I liked about this release is that Microsoft published the benchmark openly. So I tested it myself.
I ran four environments in the accounting domain using a frontier model. The same failure pattern showed up almost immediately.
In one run, the model handled the first four rounds very well. It reproduced the source ledger almost perfectly. Then in round five, I saw minor degradation. That error carried into round six. After that, the run collapsed. The output no longer resembled the original ledger in any meaningful way.
Another run did better, but it still landed below the 98% threshold. It scored 94.3%. That may sound decent in isolation, but if you are delegating financial document edits, 94.3% is nowhere near reliable enough.
The worst run started badly from the very first step. It scored around 36% almost immediately, which meant the model couldn’t faithfully reproduce the document even in a single-shot setting. From there, things only got worse until it dropped close to zero by round nine.
This is why average scores can hide the real risk. You can get a few good-looking turns, then a catastrophic break. If the workflow is long enough, the odds of hitting one of those cliff-edge moments keep rising.
A concrete example from the accounting dataset
One of the environments I looked at was the Paris Community Theatre Ledger in the accounting set. The source document was a ledger. The benchmark then applied a series of deep edits to it.
The tasks included things like:
- Split expenses by production and create a main-stage ledger for major shows.
- Revert the document back to its prior version.
- Move ticket revenue transactions into a new file.
- Revert that change as well.
By the end of the 20-turn workflow, the final ledger should have matched the original source ledger exactly.
Across my four tests, none of the final outputs matched the original perfectly.
That’s the core issue in one sentence. The model can look competent while editing. But if it can’t preserve the original document state through a long sequence of edits and reversions, then it’s not a reliable delegate.
This isn’t limited to plain text
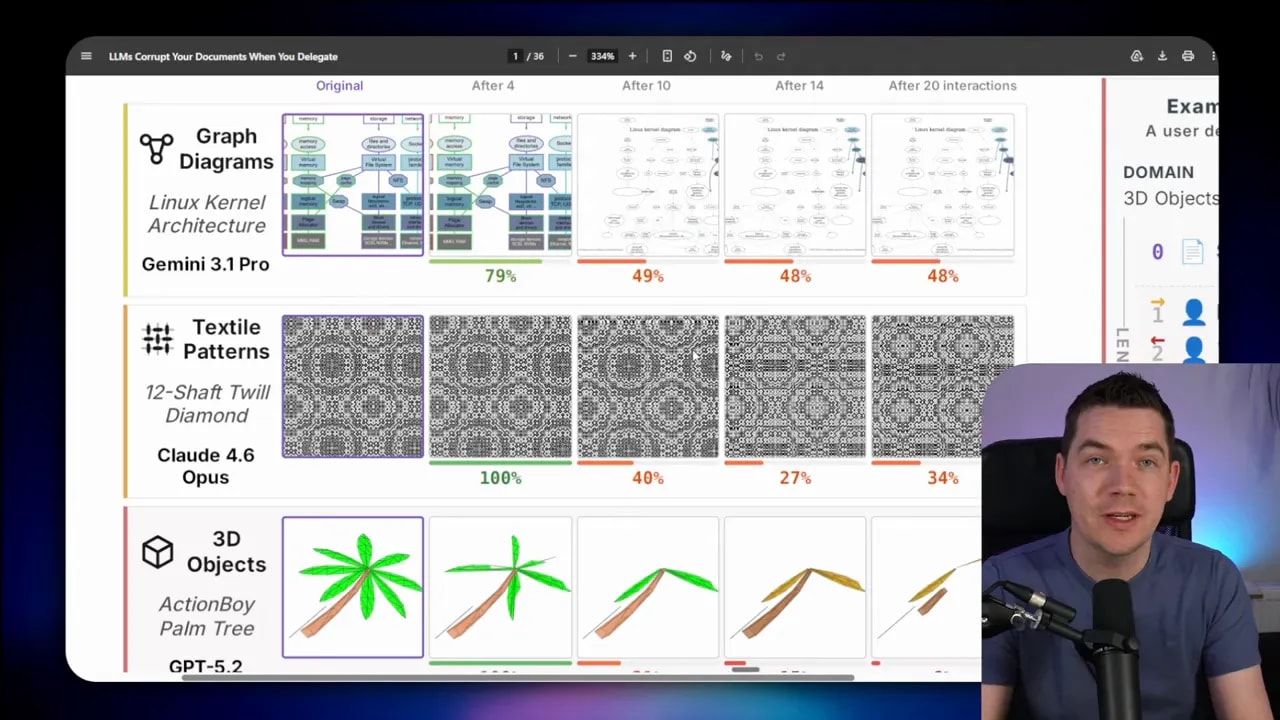
Most of the degradation in the study shows up in textual documents, but some domains make the damage visible in a more dramatic way.
The paper includes cases like graph diagrams, textile patterns, and 3D objects represented through text-based schemas. One example starts as a graph of Linux kernel architecture and ends after repeated interactions as something visibly distorted. Another begins as a palm tree and drifts into a completely different form.
That’s useful because it makes the underlying issue obvious. The same thing that happens to ledgers and reports also happens to diagrams and structured visual outputs. The artifact gradually stops being the original artifact.
The researchers also tested image-generation models in visual editing workflows. Those models performed much worse than text-based LLMs. The best visual models scored around 28% to 30% reconstruction, while top text models were still reaching 70% to 80% in some settings.
So if text-based delegated editing is still fragile, fully delegated image editing is even further away.
Why raw chat-based editing goes wrong
In the main benchmark setup, the model has no real workspace. It can’t save a file artifact and patch it over time. Instead, each turn forces it to regenerate the entire document inside the conversation.
That means the model has to keep attending back to the original seed document somewhere earlier in the context window, remember the latest state, apply the requested edit, and then emit a full fresh version of the file.
That’s a fragile process.
LLMs are probabilistic. They predict the next token based on context. As the context gets longer, and as the conversation accumulates more previous states, the odds of one wrong token or one misread section go up. Once the model diverges from the source document, that divergence compounds. The next turn builds on a flawed version. The turn after that builds on a worse one.
At a high level, the benchmark confirms what many builders have felt already: repeated full regeneration is a poor foundation for reliable document delegation.
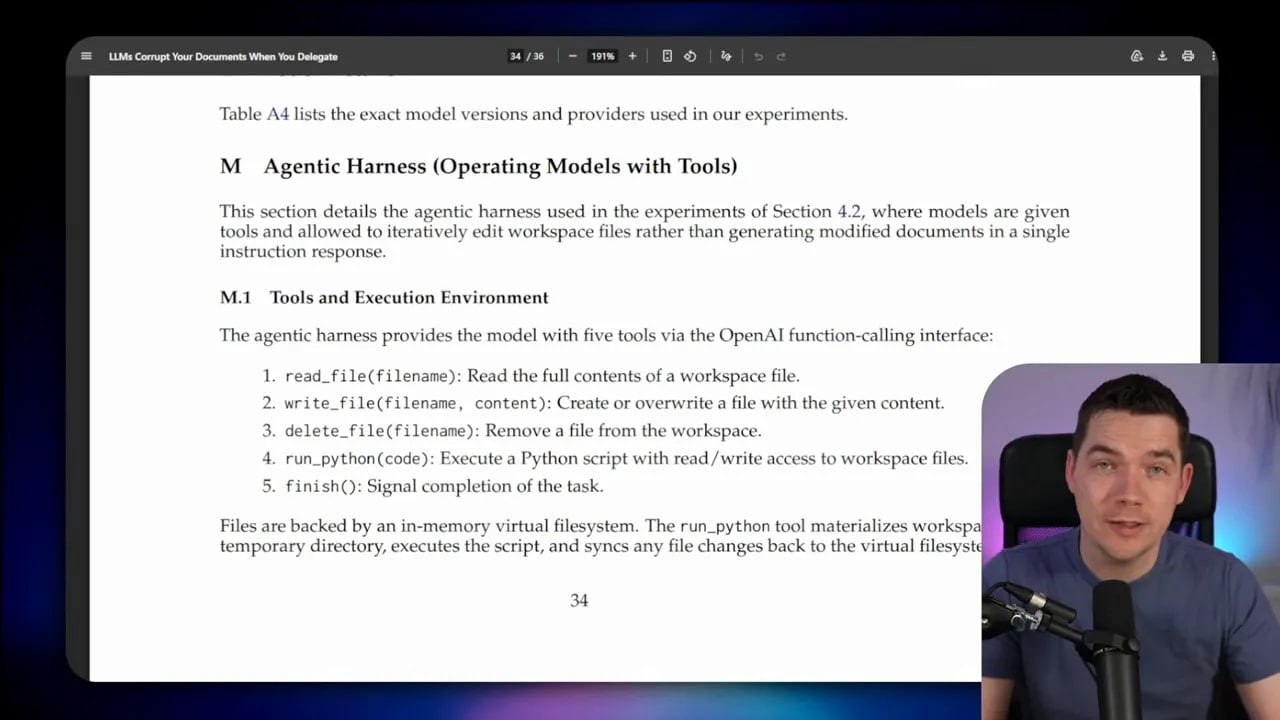
Microsoft’s tool-based agent harness actually made results worse
The researchers didn’t stop with raw LLM calls. They also built a basic agent harness to see whether tool use would help.
The harness gave models tools to:
- Read files
- Write files
- Delete files
- Run Python code
- Finish the task
That sounds like a step in the right direction. In theory, tools should reduce corruption by letting the model make targeted programmatic changes instead of rewriting whole files.
But the benchmark showed the opposite. The tested models performed worse with this agentic setup than without it. On average, the tool-enabled runs suffered about 6% more degradation.
At first glance, that seems counterintuitive. If tools should help, why did they hurt?
The paper gives a couple of reasons.
First, tools create overhead. These agent loops used 8 to 12 tool calls on average per task and consumed two to five times more input tokens than the no-tool version. Long context is already a weak spot for current models, so that extra token load likely made things worse.
Second, many benchmark tasks weren’t simple spreadsheet operations. They required reasoning, interpretation, text understanding, and multi-step coordination. In practice, models often leaned on file writing rather than code execution. Better models used code more often than older ones, but that still didn’t rescue the overall result.

Where I think the framing needs a correction
This is the one part of the research where I’d push back a little.
Not because the data is wrong. The data is the data. My issue is with what the experiment really proves.
The paper shows that raw LLM delegation performs badly. It also shows that a generic tool harness with read, write, delete, and code execution performs badly. I agree with both results.
But I don’t think that means “tools don’t help document editing” in a broad sense. I think it means a generic harness without a surgical edit path doesn’t help enough.
That’s a very different claim.
There are two fundamentally different ways an LLM can modify a file:
- Full regeneration: the model reads the file and emits the entire modified version each time.
- Surgical editing: the model proposes a small, targeted patch and leaves the rest of the file untouched.
DELEGATE-52’s main experiment clearly measures the first pattern. The basic harness still leans heavily on it because the available tools make full rewrite easy and exact patching awkward.
That matters a lot.
The missing tool: edit instead of rewrite
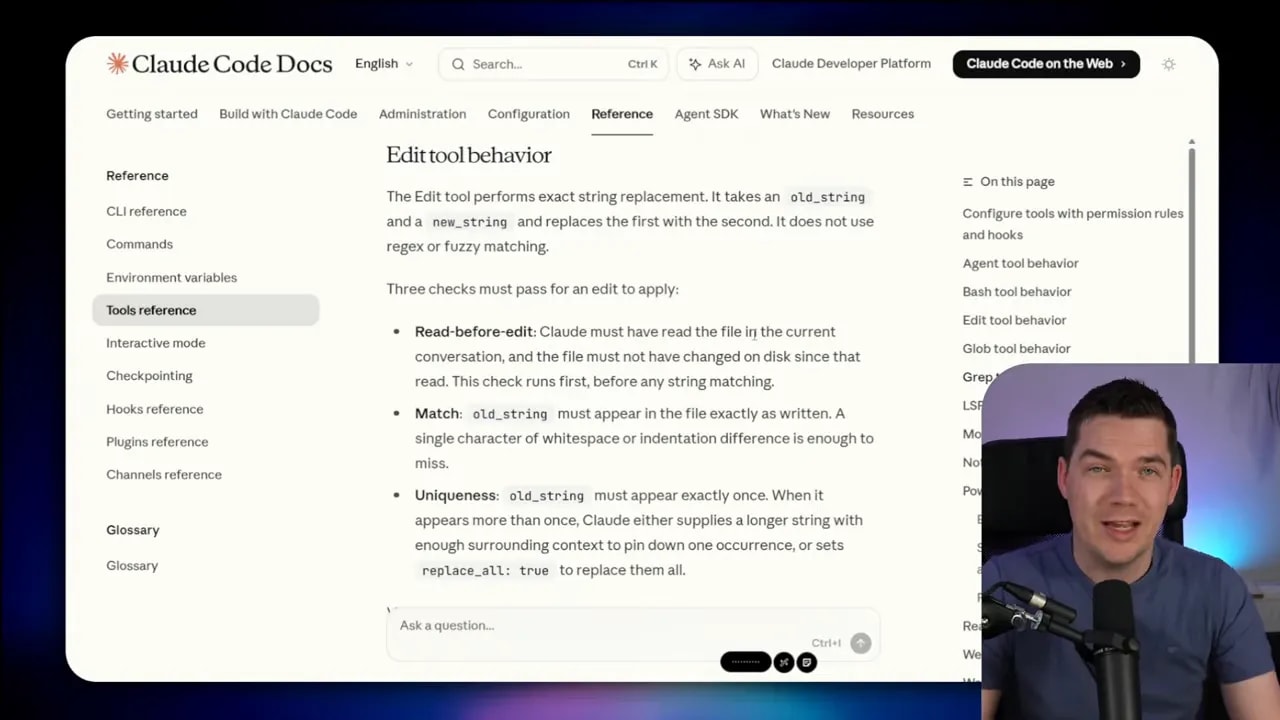
If I were designing this harness, I would have included an explicit edit file or multi-edit tool.
With that kind of tool, the model doesn’t regenerate the whole document. It reads the file once, identifies the exact text span that needs changing, and submits a patch. The harness then verifies the patch before applying it.
A good edit tool typically enforces three rules:
- The file must have been read in the current conversation.
- The string to replace must match the file exactly, including whitespace.
- The target string must appear only once so the edit lands in the right place.
This changes the whole safety model.
If the model gets the patch wrong, the change simply fails to apply. The harness rejects it. The file does not silently drift. Failure becomes visible and contained instead of being baked into the document.
That is very different from asking the model to rewrite an entire 5,000-token file from memory and context.
Why opinionated harnesses work better
I think the bigger lesson here is that production AI systems need an opinionated harness.
A harness is more than a bag of tools. It encodes the workflow assumptions the model can’t enforce by itself.
That’s why systems like Claude Code are interesting in this context. Their file updates revolve around edit and multi-edit tools rather than blind rewrites. They require read-before-edit. They require exact match replacement. They use checks that prevent stale memory edits. They also support checkpointing so changes can be reverted cleanly.
I’m not saying those systems are flawless. They’re not. There are still edge cases and failure reports. But the pattern is correct. The harness narrows the model’s options and makes safe behavior easier than risky behavior.
Even Anthropic’s published skills for handling Word documents push the model to use the edit tool directly instead of writing Python scripts for document changes. That’s a strong signal. Simpler, constrained edits are often safer than handing the model a blank coding sandbox and hoping it chooses wisely.
You can read more about Anthropic’s tool use approach and their public agent skills repository if you want examples of this style of steering.
The three design rules I’d act on immediately
If you’re building document-editing agents, these are the three practical rules I’d take from all of this.
1. Separate edit from write
Don’t give the model one generic write-file tool and hope for the best.
Give it two distinct options:
- Edit for targeted string replacement
- Write for full rewrites
Then make full rewrites uncomfortable. The tool descriptions, system instructions, and examples should push the model to prefer edit. Rewrite should be a fallback for cases where patching truly can’t work.
2. Enforce read-before-edit
The model should not be allowed to modify a file it hasn’t read in the current session. That reduces stale-memory errors and forces grounding in the latest file state.
3. Require exact string matching
Exact match down to whitespace is one of the simplest and strongest safety checks you can add. If the patch doesn’t match, the change fails. That’s a good failure mode.
These aren’t abstract best practices. They are concrete harness rules that directly address the kind of corruption DELEGATE-52 exposes.
Three factors that make the failure mode worse
The paper also explored what amplifies document corruption. I think these are especially useful because they point to design levers you can control.
1. Larger documents degrade faster
The main benchmark used seed documents averaging around 3,000 to 5,000 tokens. The researchers then varied document size to isolate the effect.
The drop was substantial.
With a 1,000-token seed document, one setup reached around 91.4 after 20 turns. With a 10,000-token version of the same task pattern, performance fell to about 59.9.
So document size compounds degradation. Bigger files create more opportunity for the model to lose track, and those errors snowball over repeated interactions.
If you are dealing with large documents, splitting work into smaller controlled units is a sensible move.
2. Longer interaction chains keep getting worse
The benchmark’s standard workflow uses 10 round trips, which means 20 total interactions. For some models, the researchers extended that to 50 round trips, or 100 interactions, by repeating the same edit patterns.
The result was exactly what you’d expect if context rot is real: degradation kept accumulating, and none of the models showed a meaningful plateau.
One example dropped from 72.9 at 20 turns to 58.7 at 100 turns.
Longer chains mean a larger and messier context window. Eventually the model drifts.
This is why I still think context resets matter. Some vendors are pushing context compaction as the answer. I’m not convinced it fully solves the problem. This research suggests that long context still decays in practice, especially for delegated document workflows.
3. Distractor context hurts performance
The benchmark also included distractor documents to mimic realistic work environments.
For an accounting ledger, that might include related but unnecessary files such as a chart of accounts CSV, reimbursement policy, trial balance, or fund accounting notes. That mirrors real retrieval systems, which often bring in documents that are loosely related but not directly needed.
When the researchers removed distractors and gave the model only the essential documents, scores generally improved.
Again, that’s not surprising. LLMs struggle with context distraction. If your retrieval system pulls in irrelevant chunks, your agent has more chances to latch onto the wrong detail or waste attention on noise.
What this means for RAG and long-running agents
A lot of AI systems quietly create their own failure conditions through sloppy context handling.
If you’re using retrieval-augmented generation, poor recall and noisy retrieval can make delegated editing much less reliable. If the model receives extra context that doesn’t matter, or misses the one chunk that does, the odds of corruption go up.
That means practical retrieval discipline matters:
- Use re-ranking to sort the best evidence to the top.
- Apply thresholds so weak matches don’t enter the context at all.
- Keep the active context narrow and task-specific.
- Hand off between sessions or windows carefully instead of dragging the whole history forever.
I also think isolated sub-agents are useful for large-document processing. If a document is huge, breaking the task into smaller bounded contexts can reduce confusion. Many modern SDKs and harness patterns already support that style of architecture.
The main point is simple: if the context window becomes a junk drawer, document quality suffers.
Why human review is still necessary
Microsoft’s threshold for delegated readiness was 98% after 20 interactions. I think that’s a sensible minimum, and current systems generally aren’t there outside narrow structured domains.
Until your system can prove that level of performance in the exact workflow you care about, you still need human-in-the-loop review.
That doesn’t mean a human has to inspect every token manually. It means your system should include approval gates where mistakes are most costly.
For document workflows, one of the best interfaces you can offer is a diff view. Show the original document beside the edited result. Highlight exactly what changed. If the model made a tiny accidental alteration in a clause, value, date, or reference number, a diff makes that visible immediately.
This is another reason surgical editing helps. It makes changes explicit. It is much easier to review a narrow patch than to compare two long regenerated files and hope nothing subtle slipped through.
The practical takeaway for builders
If I compress the whole paper into one operational lesson, it’s this: current LLMs are poor delegates for long-running document editing unless the harness does a lot of safety work for them.
The benchmark proves that raw full-document regeneration is unreliable. It also shows that giving a model generic tools is not enough. What matters is the structure of the harness and the allowed editing pattern.
The pieces I’d prioritize are:
- An edit or multi-edit tool that applies small validated patches instead of rewriting whole files.
- An opinionated harness that enforces read-before-edit and other workflow rules.
- Strict matching checks so failed edits are rejected rather than silently applied.
- Tight context management so long interactions and distractor documents don’t rot the task.
- Human approval gates for any workflow where accuracy must stay extremely high.
That reframes the Microsoft result in a useful way.
I don’t read it as “document agents don’t work.” I read it as “document agents fail if you let the model behave like a free-form text generator instead of constraining it like a careful editor.”
That distinction matters a lot.
Because if you are building AI systems for real business workflows, the difference between rewrite and patch, between generic and opinionated, and between hidden corruption and visible failure is the difference between a neat demo and something you can actually trust.
