

One of the biggest problems with AI agents shows up right after they seem to be working.
An agent answers well. It reasons well enough. It picks tools. It performs actions. Then one day it sends the wrong email, charges the wrong customer, deletes the wrong file, or writes bad data into production. By the time the system realizes it made a mistake, the damage is already done.
That is the real issue with tool-calling agents. The hard part is often not detecting the mistake. The hard part is detecting it before execution.
Apple recently published a paper on what it calls a reinforced agent, and I think the idea matters because it is so simple. You do not need a huge orchestration layer. You do not need to retrain your model. You do not need to rebuild your whole stack. You insert a reviewer agent into the loop before a tool call actually fires.
That one move changes the timing of error detection, and timing is everything here.

The real problem is state recovery
Most discussions about tool calling focus on accuracy. Did the model choose the right tool? Did it fill the parameters correctly? Should it have used a tool at all?
Those are useful questions. But they miss the operational problem that matters most in production: state recovery.
If an agent makes a bad call and that call changes the outside world, rolling it back can be hard, expensive, or impossible.
Think about actions like these:
- Sending an email
- Executing a payment
- Deleting files
- Writing into a production database
- Triggering an external workflow
In all of those cases, a post-hoc correction is much weaker than a pre-execution block. If the agent catches the mistake after the tool runs, the system is already in a hole. Sometimes that hole is shallow. Sometimes it is a crater.
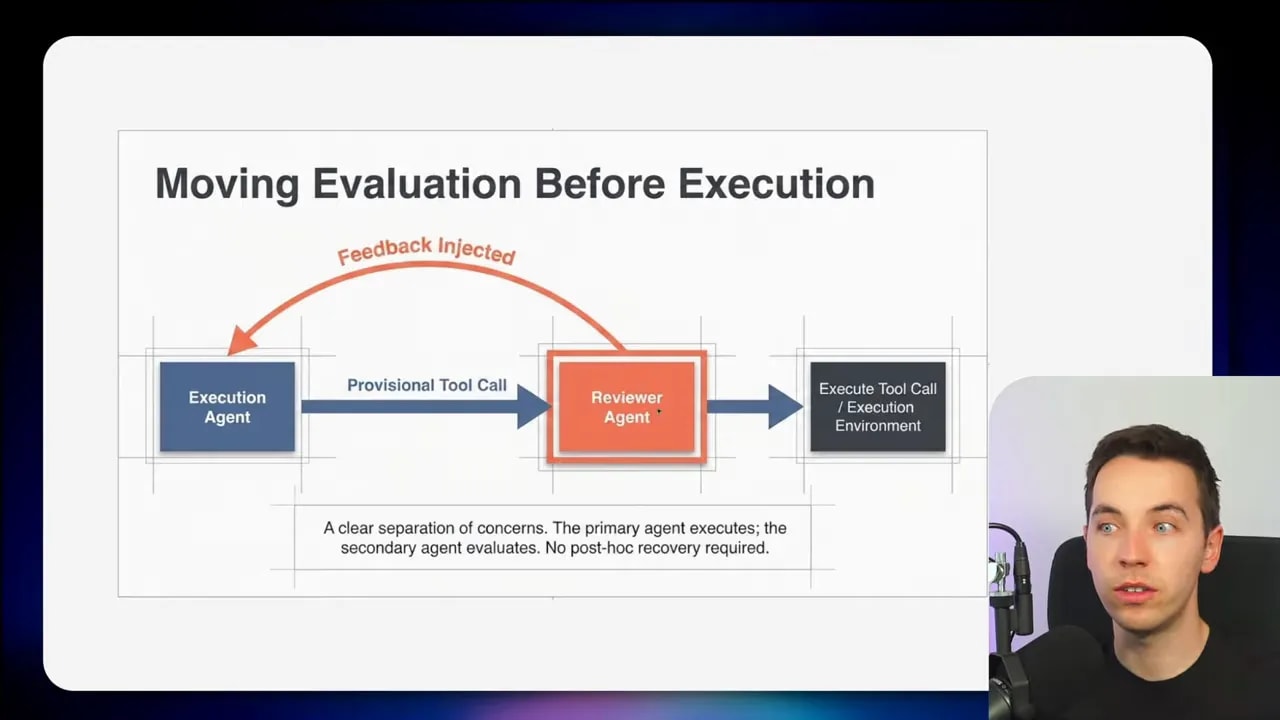
That is why this paper is interesting. It moves evaluation into the execution loop itself. Instead of asking whether the action was good after the fact, it asks whether the action should be allowed to happen in the first place.
How the reviewer agent works
The architecture is straightforward.
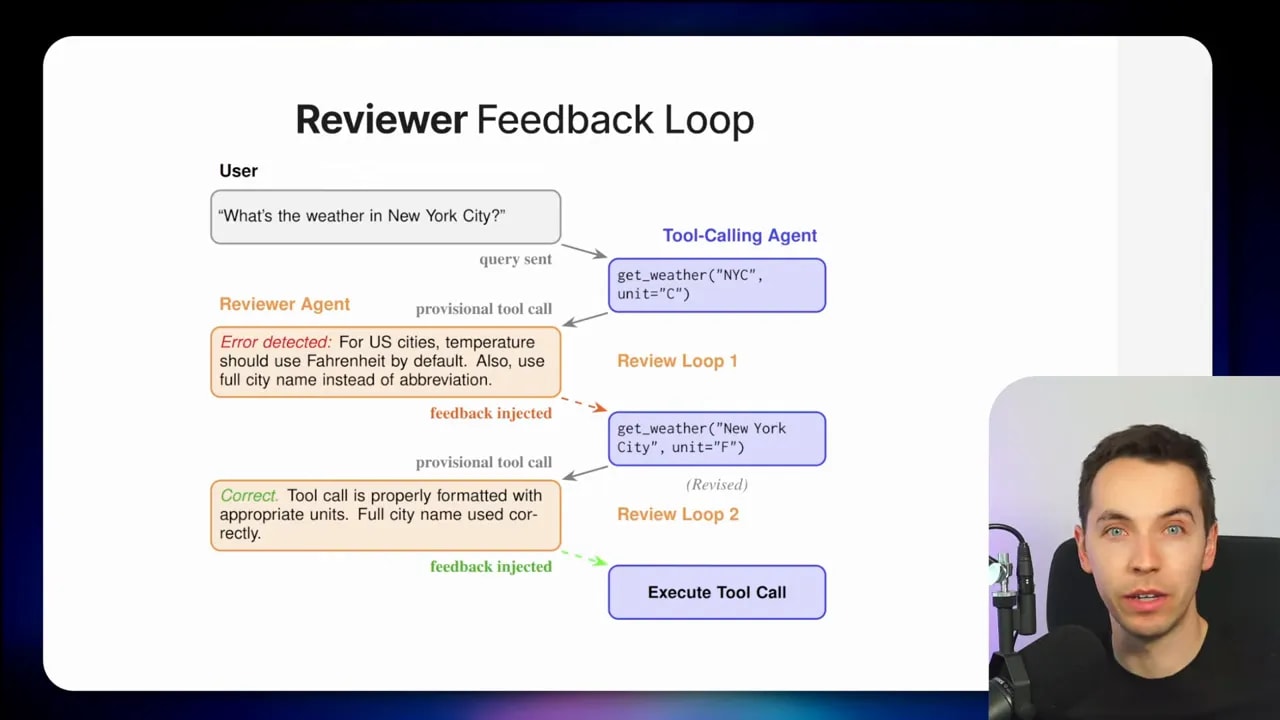
You still have your main agent. It reads the user request, decides what tool to call, and fills in the arguments. But instead of immediately executing that tool call, the system sends the provisional call to a second model: the reviewer agent.
The reviewer acts like a gate.
If the reviewer approves the call, the tool executes as generated. If the reviewer rejects it, the call goes back to the main agent, which then generates a new attempt. That loop can continue until the reviewer is satisfied or until you hit a limit that you define.
The key detail is that the reviewer does not actually execute the tool. It inspects the proposed call before execution.
A simple example makes this easier to see.
Say the request is: What is the weather in New York City in Celsius?
The main agent may select a weather tool but accidentally set the unit to Fahrenheit. In a normal setup, that call would fire, the wrong result would come back into context, and the agent would then spend the rest of the interaction trying to recover from its own mistake.
With reviewer gating, the wrong call gets intercepted first. The reviewer sees that the request asked for Celsius, rejects the provisional call, and sends feedback back into the loop. The main agent gets another chance to generate the tool call. If it now selects the right tool with the right arguments, the reviewer approves it and the system proceeds.
That may sound small, but it changes the failure mode of the whole system.
Without review, a bad tool call becomes part of the context and pollutes everything that comes next. With review, the agent has a chance to correct the call before it creates downstream damage.
Why this is different from ordinary evaluation
A lot of agent evaluation happens after execution. You run a benchmark. You inspect logs. You score tool choice, parameter accuracy, and final outcomes.
That is useful for research and debugging, but it does not save you in production at the moment the tool fires.
Apple’s setup moves review from an external analysis step into the live control loop. That is the core shift.
The paper frames tool-calling quality around three areas:
- Tool selection: did the model choose the right tool from the available set?
- Parameter accuracy: did it fill in the arguments correctly?
- Scope recognition: should it be calling any tool at all?
Those categories are practical. They cover most of the mistakes that show up in agent systems. The important step here is that the reviewer checks these issues before execution, instead of treating them as something to audit later.
The helpfulness and harmfulness framing is the right one
One thing I liked about this paper is the way it measures reviewer performance.
It uses two metrics:
- Helpfulness: the percentage of main-agent errors that the reviewer successfully corrects
- Harmfulness: the percentage of previously correct responses that the reviewer breaks or degrades
This is the right framing because a reviewer can absolutely make things worse.
It is very easy to build a reviewer that blocks too much, second-guesses good calls, or creates pointless loops. If you only measure how often it catches bad calls, you miss half the story.
A reviewer is useful only if it catches enough real mistakes without damaging too many correct actions.
That tradeoff matters a lot in agent design. A skeptical reviewer may feel safer at first, but if it rejects good calls all day, you end up with slower systems, frustrated users, and lower total reliability.
The headline result: about a 3-to-1 benefit-to-risk ratio
The paper reports that reasoning models worked better than standard chat models as reviewers.
In the setup they tested, a reasoning reviewer corrected roughly three errors for every one correct response it broke. That is the source of the 3-to-1 benefit-to-risk ratio.
Standard language models also helped, but less effectively.
The authors also found that prompt optimization improved results further. In other words, some of the gains did not come from a fancy new training procedure. They came from clearer instructions and tighter review behavior.
That part is worth paying attention to because it means this pattern is accessible. You can implement it quickly and improve it with prompt work before you consider heavier options like fine-tuning.

Why the numbers should be read carefully
The 3-to-1 result is interesting, but it is not the whole story.
Every experiment in the paper uses GPT-4o as the base agent. That matters because GPT-4o is a non-reasoning model. The reviewer’s gains are being measured against the mistakes made by that base agent.
I think that almost certainly inflates the practical appeal of the headline number.
Here is why.
If your main agent is already a reasoning model, it will likely avoid some of the exact mistakes that the reviewer is catching in this paper. In that case, the low-hanging fruit is already gone. The reviewer may still help, but the helpfulness number could drop because the main agent has fewer obvious failures to correct.
That does not break the architecture. The pattern still makes sense. But it should change how you interpret the evaluation.
The comparison I really want to see is this:
- Reasoning model as the main agent
- Reasoning or alternative model as the reviewer
- The same helpfulness and harmfulness analysis on top of that stronger baseline
That would tell us much more about whether reviewer gating is still worth the latency and cost once the primary agent itself is stronger.
The authors do mention this limitation, but I think it deserves more attention than it got.
Prompting made a bigger difference than many people expect
One of the more practical takeaways from the paper is that the early versions of the reviewer did not behave especially well.
It tended to become over-skeptical. It would reject too many tool calls and create redundant loops. That is exactly the failure mode you would expect from a poorly instructed gatekeeper.
After prompt changes, the paper reports that redundant review loops dropped from 23% to 8%.
That is a large improvement from a simple intervention.
There is an important lesson in that. If you adopt this architecture, do not assume the first reviewer prompt is good enough. The difference between a useful reviewer and an annoying one can come down to prompt language that makes the reviewer more precise, less paranoid, and more disciplined about what deserves a rejection.
That is one of the reasons I like inference-time control patterns. You can often test and improve them very quickly without waiting on data pipelines, labeling cycles, or training runs.

This safety layer is not free
The architecture is simple, but the cost is real.
The most obvious downside is latency.
Apple reports:
- 6.2x latency overhead on single-turn, high-volume applications
- 2.4x latency overhead on multi-turn agents
Those are not small increases.
Every tool call now requires another model round trip before execution. If your agent is customer-facing, interactive, or voice-based, that delay becomes visible very quickly.
People feel latency before they appreciate safety. That is just how product experience works.
Then there is the direct inference cost. Two model calls per tool event can add up fast, especially for agents that trigger many tools in one session. Background agents may tolerate that better than real-time ones, but cost still compounds.
So the tradeoff is clear:
- You get better pre-execution checking
- You pay for it in time and tokens
Whether that trade is worth it depends on the risk of the action being gated. For an irreversible payment, the extra cost may be trivial compared to a bad execution. For a chat interface where a tool only fetches harmless data, the overhead may feel excessive.
The reviewer can only catch what it can recognize
This is another point that matters a lot in practice.
The reviewer is still a model working from context. It is not magic. It can only flag errors that it can detect from the information available to it.
That creates some clear limits.
For example, it may struggle with:
- Subtle parameter mistakes
- Domain-specific rules that are missing from context
- Business constraints the reviewer was never told about
- Cases where the provisional call looks valid but the actual tool outcome would be problematic
That last point is especially important. The reviewer sees the proposed call, not the execution result. It can stop a bad-looking action up front, but it cannot reason over the real-world outcome of a tool that has not run yet.
So this approach has a ceiling. It improves tool calling by catching visible mistakes before execution, but it does not replace other forms of validation, sandboxing, retrieval, or system-level safeguards.
If you want the reviewer to catch more nuanced issues, you may need to enrich its context with retrieval, policy documents, tool-specific constraints, or domain knowledge. Without that, its helpfulness is bounded by what a general-purpose reviewer can infer.
Model choice matters more than people like to admit
The paper also notes that the reviewer does not have to use the same model as the main agent. In fact, using a different model can be a good idea.
That makes sense.
If both agents share the same habits, blind spots, and biases, they may fail in the same way. A reviewer with a different training profile can act as a more useful checker because it looks at the same provisional call from a different angle.
This is part of the appeal of adversarial or semi-adversarial agent design. You do not always want the second model to think exactly like the first one. Some variation is healthy if the task is inspection rather than generation.
In Apple’s setup, reasoning models such as o3-mini, and later GPT-5, outperformed standard chat models in the reviewer role. That result is not surprising. Reviewing a tool call is basically a structured reasoning task. You need to inspect intent, compare it against the arguments, detect mismatch, and decide whether the action fits the request.
That is a very different job from free-form response generation.
Three ways to run reviewer collaboration
The paper describes three collaboration patterns between the primary agent and the reviewer. Each one has a different balance of quality, cost, and speed.
1. Progressive feedback
This is the most direct pattern.
- The primary agent generates a tool call.
- The reviewer inspects it and gives feedback.
- The primary agent tries again.
- The cycle repeats until approval or until you hit a cap.
This pattern is easy to understand and often easy to implement. It can also become the most token-hungry approach because each failed review creates another round of generation and checking.
If you use this method, you should define strict caps. Otherwise the system can get stuck in unproductive loops, especially if the reviewer is too strict or the main agent struggles with the task.
2. Best-of-N selector
In this setup, the main agent generates N candidate tool calls, often with varying temperature settings. The reviewer then evaluates all the candidates and selects the best one.
This can work well when diversity helps. If the first guess is sometimes wrong but the second or third guess is often good, then selecting from multiple candidates may outperform repeated correction loops.
The downside is obvious. You pay for several candidate generations up front.
3. Best-of-N grading
This is similar to the selector pattern, but instead of choosing a single candidate directly, the reviewer scores each one. A threshold then determines whether any of them are safe enough to execute.
This method is useful when you want stronger gating. The system does not have to pick the least-bad option. It can reject all of them if none clears the bar.
That is attractive for higher-stakes actions where “good enough” is not actually good enough.

There is no universal winner across these three. The right choice depends on your use case:
- If you want simplicity, progressive feedback is easiest to reason about.
- If candidate diversity tends to help, best-of-N selection may be better.
- If strict safety thresholds matter most, best-of-N grading is appealing.
How this fits with tool search and programmatic tool calling
I think it is easy to frame papers like this as if one approach replaces another. That is not the right way to think about it.
A few months ago, I covered Anthropic’s newer tool-calling patterns, including tool search and programmatic tool calling. Those techniques solve a different problem.
If you want the background on those methods, I covered them here in my breakdown of tool search and programmatic tool calling.
Tool search helps by reducing context overload. Instead of stuffing a huge set of tool definitions into the prompt, the system retrieves the relevant tool schemas when needed. That lowers token usage and reduces ambiguity.
Programmatic tool calling takes another route. The model writes a Python script, and a sandbox executes it without another LLM sitting inside the inner loop. That can improve efficiency significantly because the system is relying more on code execution and less on repeated model mediation.
Those ideas are mostly about context management and execution efficiency.
Apple’s reviewer architecture makes a different bet. It assumes the first proposed action is wrong often enough that spending extra compute on a pre-execution check is worth it.
These approaches are complementary.
You can absolutely combine them in one system:
- Use tool search to reduce prompt size
- Use programmatic execution where scripting is safer and cheaper
- Use a reviewer gate before high-risk tool calls fire
A mature agent stack will often mix several of these patterns rather than betting on one trick to solve everything.
Why reviewer gating is attractive compared with fine-tuning
There are many ways to improve tool calling. Fine-tuning is one option, and in some cases it makes sense. But it carries a lot of cost beyond the actual training run.
You need:
- Good training data
- A process for collecting and cleaning it
- Evaluation to confirm the fine-tuned model actually improved the target behavior
- Checks to make sure you did not introduce new failure modes or overfit the task
That is a lot of work.
Reviewer gating is one of the few strong inference-time levers you can introduce quickly. It does not require an extra training cycle. It does not require a new labeled dataset. It does not require a long tuning project before you can test whether it helps.
You can add it to an existing agent loop, measure helpfulness and harmfulness in your own environment, and decide from there.
That makes it very appealing for teams that need practical safety gains now rather than months from now.
If someone wants to go deeper on building agent systems with these kinds of harness patterns, retrieval layers, and control loops, the AI Architects course covers that broader system design side in more depth.
Where this pattern fits best
I would not put reviewer gating in front of every tool call by default.
The latency overhead is too high for that to be a universal rule. Instead, I think this pattern fits best where an agent is doing something costly to undo.
That includes:
- Email sending
- Payments and financial transactions
- File deletion
- Production database writes
- External system updates that cannot be cleanly rolled back
These are exactly the actions where the old “just recover after the fact” mindset breaks down.
If the risk of a false positive from the reviewer is a few extra seconds, that may be acceptable. If the risk of a false negative is an irreversible business action, the extra gate starts to look very reasonable.
By contrast, this may be a poor fit for:
- Low-stakes read-only tool calls
- Fast conversational agents where latency is critical
- Voice systems that need immediate turn-taking
- Very high-volume agents where inference cost dominates the economics

Where the paper still leaves open questions
Even though I like the architecture, there are still some unanswered questions that matter for production use.
How much does it help when the main agent is already strong?
This is the biggest one for me.
If the primary model is already a strong reasoning model, the reviewer may have fewer valuable corrections to make. The architecture may still be good for high-stakes actions, but the cost-benefit ratio could shift a lot.
How should the reviewer be specialized?
A general reviewer will miss domain-specific edge cases. That means real deployments may need reviewer prompts, retrieval, or policy layers that are tuned for particular tools or business rules.
What about tools that execute code in sandboxes?
The paper also has natural limits around sandbox code execution and other actions where the important failure mode only becomes visible during runtime. A reviewer can inspect the intent and provisional call, but some issues only appear after execution starts.
How much friction can the product tolerate?
The 6.2x and 2.4x latency figures are hard to ignore. In some products, that kills the pattern immediately. In others, it is acceptable because the gated actions happen in the background or carry high enough risk to justify the delay.
The simple bet behind Apple’s approach
If I strip away all the extra framing, Apple’s bet is very simple:
The best place to spend extra compute in a tool-calling agent may be on reviewing the tool call before execution.
That is the whole idea.
Not more orchestration layers. Not immediate fine-tuning. Not waiting until after the tool runs and hoping recovery is easy. Just one extra model in the loop that asks, “Should this action actually happen?”
I like the idea because it lines up with how real systems fail. A lot of agent errors are survivable after the fact. Tool-calling errors often are not. Once the outside world changes, clever reasoning does not always help you.
If you want the original research, Apple published the paper here: Reinforced Agent: Inference-Time Feedback for Tool-Calling Agents.
That is why this paper stands out. It does not promise perfection. It does not remove tradeoffs. But it offers a clean, practical control point for one of the most expensive failure modes in modern AI agents.
And for many real systems, that is exactly the kind of idea that matters.
