

Anthropic recently announced a feature for managed agents called Dreaming. OpenClaw released something very similar before that, with the same name. That timing matters less than the pattern itself, because this feature points to a much bigger shift in agent design.
Agents are moving beyond simple request and response systems. The new goal is improvement over time. That means an agent shouldn’t just complete a task, forget everything, and start from zero on the next run. It should carry forward useful lessons, clean up what it knows, and get better without needing the same instructions repeated forever.
That’s what Dreaming is trying to solve.
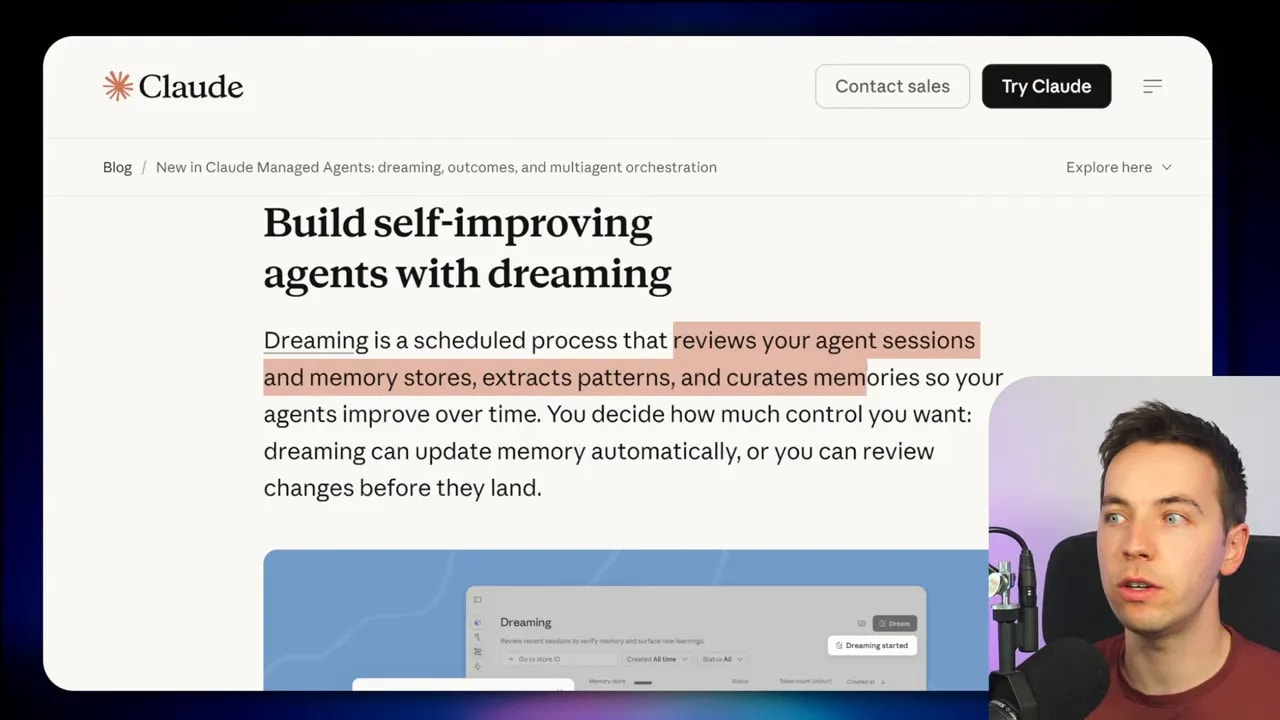
At a high level, Dreaming is a scheduled background process that runs between active sessions. It looks back over what happened, reviews stored memory, finds patterns, removes duplication, and tries to produce a cleaner memory state for future runs.
In plain English, it’s sleep-time compute for agents.
What agent Dreaming actually is
The easiest way to understand Dreaming is to think about how people work after a busy day. You collect lots of messy inputs. Some are important. Some are repeated. Some conflict with each other. Some are old and no longer useful. If you had time to sit down later and organize your notes, you’d probably end up with something much more useful than the raw pile you started with.
That is exactly the role Dreaming plays in an agentic system.
During live sessions, an agent writes facts, observations, preferences, and decisions into memory. Over time that memory becomes noisy. You end up with:
- Duplicate facts
- Conflicting instructions
- Outdated entries
- Minor details that shouldn’t have been saved in the first place
- Important information buried under low-value clutter
A Dreaming process goes back through those records and tries to turn them into something cleaner and more useful. It can:
- Consolidate repeated memories into one clear statement
- Curate what deserves to stay and what should be ignored
- Reflect on recurring themes across sessions
- Promote durable insights into long-term memory
- Reduce the amount of junk loaded into future context windows
This idea has been building in open source for a while. A good framing came from Letta, which described sleep time as an opportunity to apply compute to stateful agents. That phrase is important. If an agent has state, then downtime becomes useful. You can spend idle compute improving memory rather than waiting for the next live request.
That turns memory from a passive storage layer into an active improvement loop.
Why Anthropic’s Dreaming feature matters
Anthropic’s version packages this pattern into its managed agent platform. The system lets Claude reflect on past sessions, read existing memory stores, and create a reorganized memory store with new structure and insights.
One useful implementation detail stands out here. The process creates a new reorganized memory store instead of directly editing the original. That’s a smart safety measure. It means the system can propose a cleaned-up memory state without permanently altering the source memory. If the output is bad, stale, or misleading, you can throw it away.
That separation matters because memory systems can fail in subtle ways. Once an agent starts carrying lessons across time, bad lessons can become persistent behavior.
Still, Anthropic’s release should be read as a sign of where the market is going. Major providers now see memory consolidation as a core agent capability. This is no longer a fringe experiment. It’s becoming a standard pattern.
The downside of managed Dreaming systems
I like the direction. I’m much less convinced by the idea that most teams should hand this over to a managed platform by default.
Managed agent platforms can be useful, but they come with tradeoffs that become more serious the moment memory enters the picture.
1. Cost can climb fast
Dreaming runs in the background. That means extra model calls, extra storage, and extra processing over time. If every session creates memory, and every memory set gets reviewed and reorganized later, the bill doesn’t stay flat for long.
2. Vendor lock-in gets worse
If your long-term memory lives inside one managed agent product, switching becomes painful. You’re no longer swapping only models or inference providers. You’re also trying to migrate behavior, context history, and memory structure. That’s much harder.
3. You lose control over memory design
Memory should match the job. A generalized memory layer may work reasonably well for common cases, but it rarely beats a memory system built specifically for one agent in one domain. Legal drafting, support triage, coding assistance, and operations workflows all have different memory needs.
4. You inherit memory risks
One of the biggest dangers is memory poisoning. That happens when an injected instruction or bad memory survives across sessions and gets treated as valid long after it should have been rejected. A mistake made today can show up again days or weeks later.
That’s why memory deserves deliberate design. It shouldn’t be treated like a simple checkbox feature.
OpenClaw shows how this works in practice
If you want a concrete example of Dreaming, OpenClaw is much easier to inspect because the implementation is transparent. You can open the repository, go into the memory core files, and see how the system works.
That transparency is useful for two reasons.
First, you can understand the pattern rather than treating it like magic. Second, you can copy the architecture into your own stack without having to adopt the whole platform.
You can even point a coding agent such as Claude Code or Codex at those files and ask it to analyze the implementation, then build a similar memory layer into your own system.
How OpenClaw stores memory
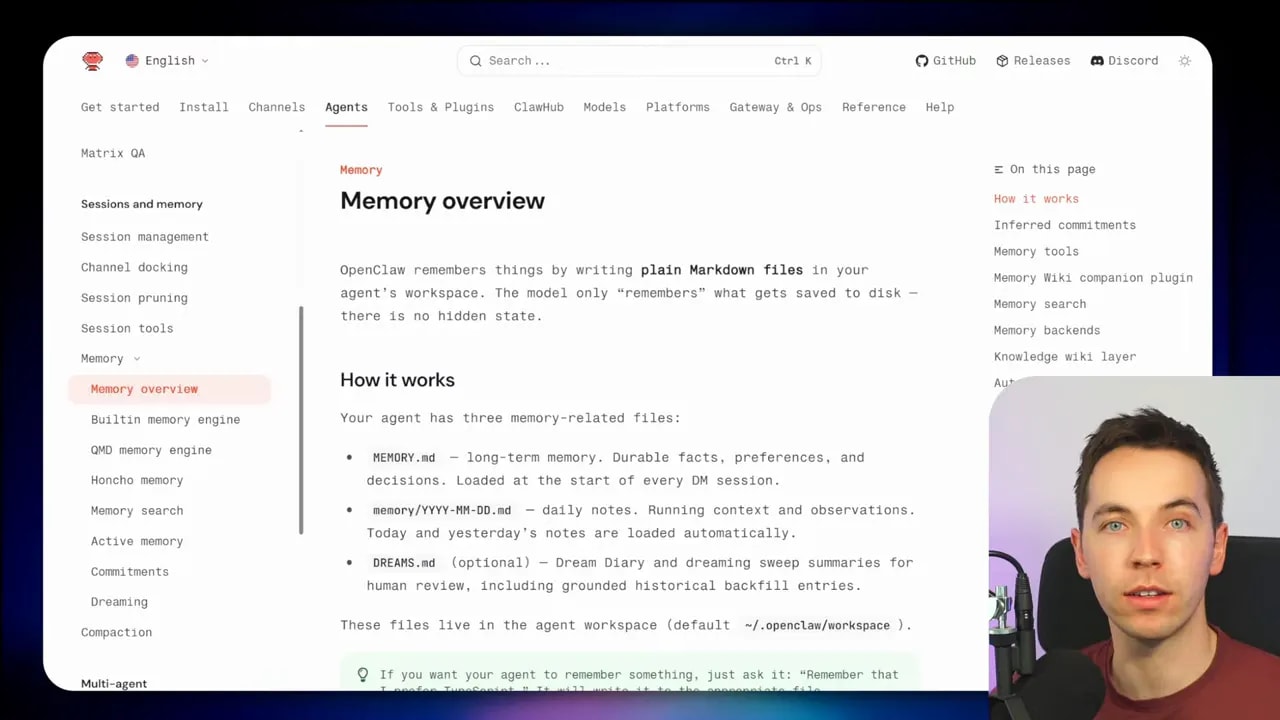
OpenClaw uses a surprisingly simple storage pattern. It writes memory as plain Markdown files inside the agent’s workspace.
That might sound basic, but simple storage often goes much further than people expect. For many agent workflows, plain files are easy to inspect, easy to back up, easy to version, and easy to move between systems.
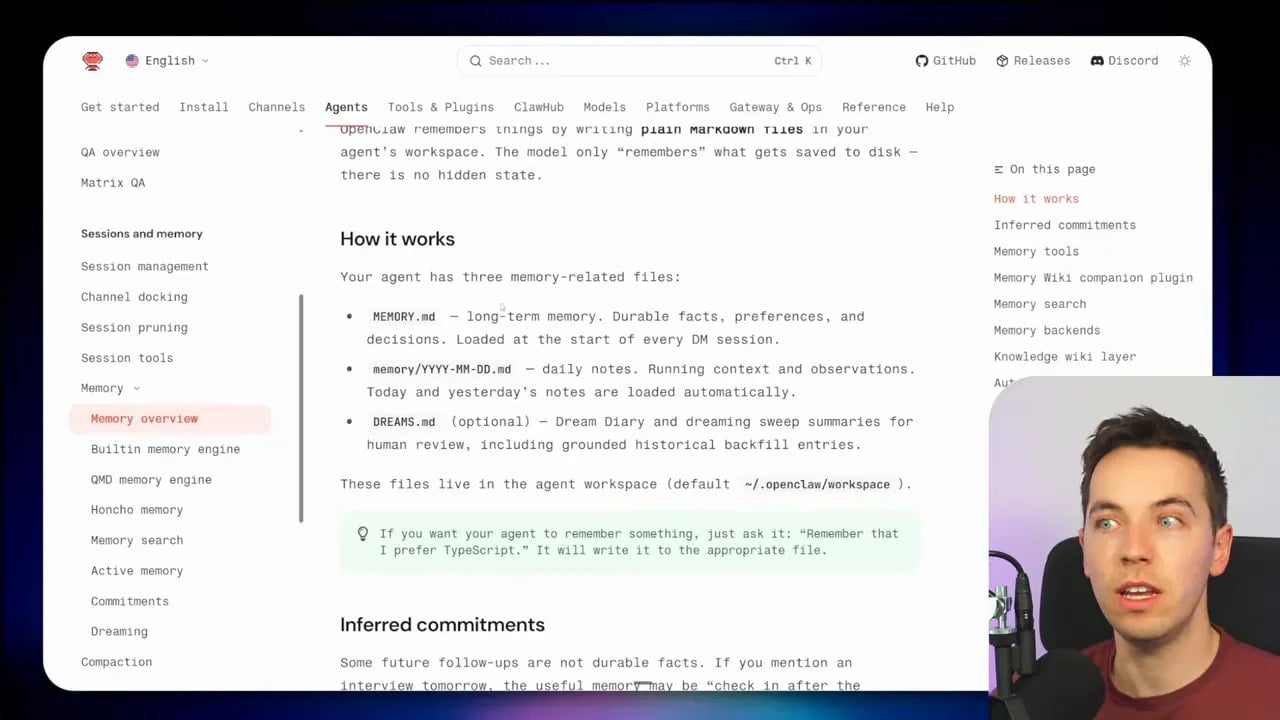
Within OpenClaw, three memory-related files matter most:
- memory.md for long-term memory, including durable facts, preferences, and decisions
- daily notes markdown files for in-run context and recent observations
- dreams.md for human-readable output from the Dreaming process
memory.md is the core long-term memory file. OpenClaw loads it at the start of every session. This is where the agent keeps the information it believes should persist.
Daily notes hold recent working context. Today’s and yesterday’s notes are loaded automatically. That gives the agent a short-term record without forcing every temporary detail into long-term memory.
dreams.md is where the Dreaming process leaves readable output. This helps with inspection. You can review what the system has been thinking about during background consolidation instead of leaving everything hidden inside machine-only state.
OpenClaw also stores machine state in a separate folder when Dreaming is enabled. So there’s a distinction between internal process data and the human-readable memory artifacts.
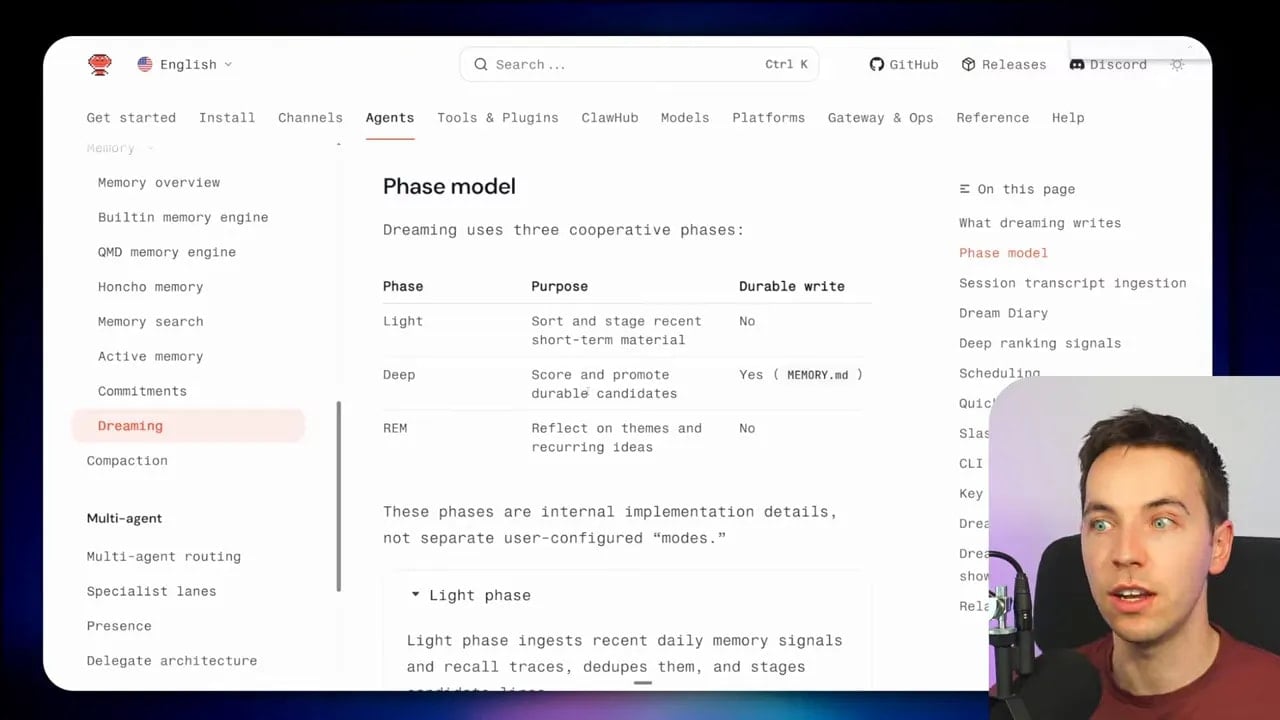
The three phases of Dreaming in OpenClaw
OpenClaw leans hard into the sleep metaphor. It runs Dreaming in phases:
- Light
- REM
- Deep
This isn’t just branding. The phases map to different kinds of memory work.
Light phase: sort recent material
The light phase stages and organizes short-term material. Think of this as the initial pass where recent signals get collected and prepared.
This is useful because raw session output is messy. Before the system can reason well about what matters, it needs a clean picture of recent observations.
REM phase: reflect on themes
The REM phase looks for themes and recurring ideas. This is where the system starts asking, “What keeps showing up?”
That matters because repetition is often a good indicator of importance. If the same instruction, preference, error, or workflow pattern appears over and over, it may deserve promotion into a more durable form.
REM also produces reinforcement signals that the next phase can use.
Deep phase: score and promote durable memory
The deep phase is where memory gets judged. The system scores candidate memories and decides whether they should be promoted into long-term memory.
If a candidate passes that threshold, OpenClaw may write it into memory.md. It may also update dreams.md with relevant outputs from the process.
This is the most important phase because it decides what the agent will carry into every future session.
How OpenClaw decides what is worth saving
You don’t want an agent to save everything. If it does, memory becomes bloated and unreliable. So OpenClaw uses ranking signals during the deep phase to estimate what is worth keeping.
Two examples mentioned in the implementation are:
- Frequency: how many short-term signals an entry accumulated
- Relevance: an average retrieval quality score for the entry
The exact scoring details matter less than the principle. Long-term memory should be earned.
A useful memory usually has some combination of these traits:
- It shows up repeatedly
- It helps with future tasks
- It remains true over time
- It reduces repeated mistakes or repeated instructions
A weak memory often looks very different. It may be temporary, specific to one moment, easy to infer again, or based on a misunderstanding.
If you build your own Dreaming layer, this ranking logic is one of the most important parts to get right. Without it, your agent will remember too much, remember the wrong things, or promote noise into policy.
Where Dreaming fits well
This feature is useful, but only in the right shape of workflow. I wouldn’t bolt it onto every agent and hope for the best.
Dreaming fits especially well when the agent does repetitive work.
Examples include:
- Legal drafting with recurring style rules and document conventions
- Support ticket triage with repeated categories and standard handling patterns
- Internal assistants that keep missing the same organizational context
- Coding agents that repeatedly need the same project conventions explained
Repetition creates raw material for consolidation. If an agent repeatedly encounters the same processes, the same exceptions, and the same corrections, then a sleep-time memory pass can capture those lessons and reduce wasted effort later.
Another strong fit is when an agent spends the first part of every run rediscovering how it should work.
Maybe it has to relearn:
- Project conventions
- Output formats
- Tool usage patterns
- Preferred decision rules
- Common edge cases
If that context hasn’t been formalized into explicit skills or static system design yet, Dreaming can help the agent absorb it gradually.
That’s the key phrase here: slowly and continuously. Dreaming is less like training a model and more like keeping an agent’s notes in order as it works.

Where Dreaming does not fit well
Some teams will hear “self-improving memory” and assume they need it immediately. In many cases, they don’t.
Dreaming is a poor fit when work is highly varied. If every task is different, there may be little stable structure to consolidate. The system can end up promoting random patterns that aren’t actually durable.
It also fits poorly for one-off or short-lived agents. If the agent exists briefly, does one task, and disappears, there’s no meaningful return on building a background memory layer.
Another bad fit is any setup where you need exact clarity on what the agent knows at all times.
That’s a subtle point, but it matters a lot in production. Sometimes reviewing memory consolidation takes more time than it saves. If your team must inspect every active rule, every retained instruction, and every source of behavior with precision, dynamic memory may add too much uncertainty.
There’s also the issue of failure modes:
- Memory can bloat
- Entries can contradict each other
- Wrong lessons can be baked in
- Old facts can be treated as current
- Low-quality signals can become high-confidence behavior
An agent with a bad memory can be worse than an agent with no memory. At least a stateless agent only fails in the present. A stateful agent can fail consistently over time.
Why generalized memory layers often disappoint
There’s a reason I keep coming back to deliberate design. Memory sounds universal, but it usually isn’t.
A generalized Dreaming layer can help with broad cleanup, but the best memory systems are usually domain-specific. That’s because different agents need different answers to a few key questions:
- What should be remembered?
- For how long?
- At what level of detail?
- Who can write to memory?
- Who can overwrite it?
- What evidence is required before memory becomes durable?
A coding agent might need durable memory for repo conventions, dependency choices, and architecture decisions.
A legal assistant may need stable memory for jurisdiction, firm style, client preferences, and approved clause standards.
A support triage system may need memory for account policies, escalation rules, and repeated issue patterns, but should probably avoid storing fragile issue-by-issue assumptions.
That’s why a broad “dream layer” rarely beats one built for a specific workflow. The closer your memory policy is to the real job, the better your outcomes usually are.
Markdown is simple, but the storage layer is flexible
OpenClaw uses Markdown files, and I think that’s a smart reminder that you don’t always need a complicated storage stack to get useful results.
Still, the pattern is more important than the file type.
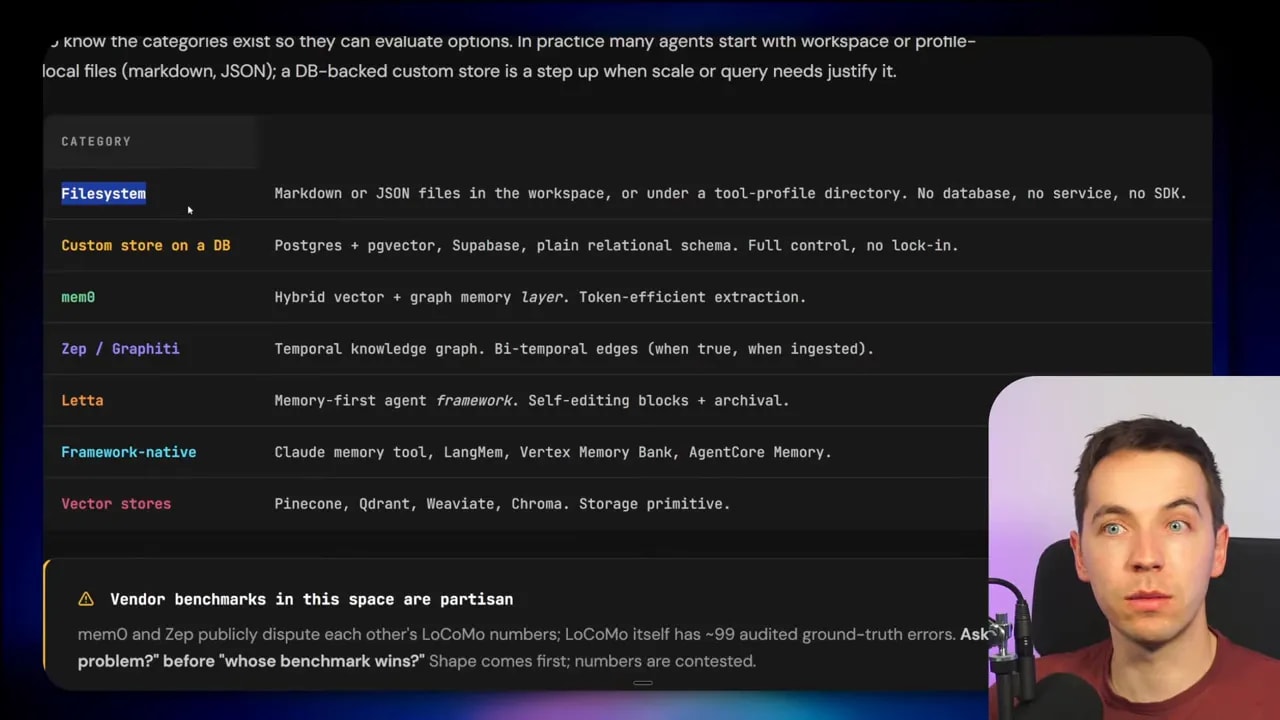
You can keep the same Dreaming architecture and swap out storage for something else if your use case needs it. Options mentioned include:
- Relational databases such as SQL systems
- Vector databases for semantic retrieval
- Graph databases for relationship-heavy memory
- External memory platforms such as Mem0 or Zep
There are also systems like Hermes, which include their own persistence memory layer out of the box and can integrate with external memory providers such as Hancho or Mem0.
The point isn’t that one storage layer is always best. The point is that Dreaming can sit above many different storage choices.
You can think of the stack in two parts:
- Storage: where memories live
- Consolidation logic: how memories get reviewed, cleaned, ranked, and promoted
Those parts don’t have to be tightly coupled. A lot of teams benefit from separating them.
A practical mental model for building your own Dreaming layer
If I were adding this to my own agentic system, I wouldn’t start by copying the branding. I’d start with a simple memory loop.
Step 1: Separate short-term and long-term memory
Don’t dump everything into one store. Keep recent session material in a temporary area and long-lived facts in a more stable area.
Step 2: Run a scheduled background pass
This could happen daily, after a number of sessions, or when enough new memory has accumulated to justify review.
Step 3: Read both memory and session history
The system should look at what the agent stored and how that memory showed up in actual work. That gives context for consolidation.
Step 4: Find recurring themes and conflicts
Look for repetition, contradiction, and stale content. This is where the system begins to make sense of what happened.
Step 5: Score candidate memories
Use simple ranking logic to decide what is durable. Frequency and relevance are good starting points.
Step 6: Write proposed memory to a new store
Don’t overwrite original memory immediately. Create a fresh reorganized store or a proposed patch set. That gives you an exit if the output is bad.
Step 7: Promote only high-confidence items
Long-term memory should stay small, clear, and useful. Promotion should be selective.
That basic loop captures most of the value without committing you to any one provider.
The real problem Dreaming is trying to solve
The AI industry keeps running into the same issue. Agents often force people to repeat themselves. Important context gets lost. Good corrections don’t stick. Every new session feels like a partial reset.
Dreaming exists because stateless interaction has limits.
If agents are going to handle serious, repeated work, they need a way to improve across time. They need continuity. They need memory that can be shaped and cleaned rather than just accumulated.
Anthropic’s release shows that major model providers understand this. Open source projects like OpenClaw show that the underlying pattern is already visible and usable without waiting for a managed product to package it.
That’s the interesting part here. Anthropic didn’t introduce a strange new concept. It wrapped a pattern that open source builders have been settling on for a while: use downtime to consolidate memory, reduce clutter, and improve future behavior.
Why memory can create more problems than it solves
Memory sounds like an obvious upgrade. In practice, it can make agents dangerously confident.
If a bad memory gets promoted into the long-term layer, the agent may keep repeating the same wrong assumption. If stale information isn’t cleared, the system can treat old facts as current. If duplication and contradiction aren’t managed, retrieval quality gets worse instead of better.
This is why I don’t treat memory as a simple add-on. It affects behavior at the foundation level.
Good memory can reduce repeated instructions and improve consistency.
Bad memory can create:
- Silent drift in behavior
- Persistent hallucinated preferences
- Old policies acting like current ones
- Cross-session contamination from injected prompts
- Long-term confidence in false conclusions
That’s also why Anthropic’s idea of writing a new reorganized store instead of editing the original is worth paying attention to. It adds a buffer between reflection and commitment.
