

Over the last year, I’ve seen a steady stream of headlines declaring that RAG is dead. Then the proposed replacement changes every few weeks. Sometimes it’s long context windows. Sometimes it’s agentic file exploration. Sometimes it’s context engineering, memory systems, or agent skills.
Most of those headlines are too dramatic. But something genuinely interesting did happen recently. Pinecone, the company that helped define the modern RAG stack, published a framing that basically admits agentic RAG has real architectural problems. Then it launched a product called Nexus as the answer.
That matters.
Pinecone’s argument is blunt. In many agent systems, most of the effort is spent on retrieval rather than reasoning. Outputs still need human review. Task completion rates often stall around the middle. Latency becomes unpredictable. Token usage runs away fast.
That’s a pretty strong admission from the market leader in vector databases.
What makes this even more interesting is that Pinecone isn’t alone. Andrej Karpathy’s LLM wiki idea went viral for almost the same reason. Google introduced a Knowledge Catalog. Microsoft has its compiled ontology in Fabric IQ. Different companies are arriving at a very similar architectural pattern from different directions.
The pattern is simple to describe:
- Stop making the agent rediscover knowledge from raw data every time.
- Build an intermediate knowledge layer above the raw data.
- Let the agent query that layer instead of poking directly at all the underlying sources.
That shift sounds small, but it changes where the hard work happens. Instead of doing expensive reasoning and retrieval at query time, you do more of it at build time or ingestion time.
That’s the core idea behind compiled knowledge.
Why standard RAG started to break down
It helps to separate the RAG story into phases.
The first wave was what I’d call naive RAG. A question comes in. You run a search. You get back some chunks. The model uses those chunks to produce an answer. That setup was useful because it was simple, but it had obvious flaws. If the wrong chunks came back, the answer was weak. If the retrieval was noisy, the model still tried to push through.
That version really is on its way out.
People improved it with query expansion, decomposition, clarification, reranking, and hybrid retrieval. Those techniques helped. But the more meaningful jump was agentic RAG, which I’d call RAG 2.0.
In agentic RAG, retrieval sits inside a loop. The agent can decide:
- when to query
- which source to query
- whether the results are good enough
- whether to search again
- whether to use tools or sub-agents
That sounds far more intelligent, and in many cases it is. But after the last six to twelve months, I think it’s clear that wrapping retrieval in an agent loop doesn’t actually solve the base problem. It mostly hides it.
You still have an agent trying to reconstruct knowledge from scattered fragments every single time it gets asked something important.
Pinecone described vector retrieval in a way I think is very useful. It’s like the “10 blue links” era of search, but for agents. A vector or hybrid search gives you a handful of independent chunks. Then the model has to infer the structure, relationships, and truth from those fragments.
That gets shaky very quickly.
The three big problems with agentic RAG
1. It’s non-deterministic
Ask the same question ten times and your agent may follow ten different strategies.
One run may choose one tool. Another may use a sub-agent. Another may reformulate the query differently. Another may search a different source. Across multiple steps, that drift compounds.
The more loops an agent runs, the less stable the retrieval path often becomes.
This is exactly the issue Karpathy was pointing at with the LLM wiki concept. If a subtle question needs synthesis across several documents, an LLM has to rediscover and piece those fragments together every single time. If your system has 10, 20, or 30 possible tools, there’s no guarantee it picks the right path consistently.
2. Better reasoning can’t fix poor retrieval
This is the part people often skip.
If the underlying data is messy, fragmented, or unstructured, adding a smarter model on top doesn’t magically fix it. Intelligence on top of bad retrieval is still limited by bad retrieval.
That means many “agent failures” are actually data access failures. The model isn’t always failing because it can’t reason. It’s failing because it never had the right structured context in the first place.
3. Token cost and latency explode
Every loop costs money. Every rerank costs money. Every tool call adds delay. Every reflection step adds more tokens. Every sub-agent can blow out context even more.
That’s why agent systems often feel slow in practice. They spend huge amounts of time rediscovering facts that could have been prepared in advance.
Pinecone shared benchmark figures showing agentic RAG consuming around 49,000 tokens per question on average in one setup. A coding agent consumed over 500,000 tokens, likely because it was loading full files and using sub-agents. Even if you take those numbers with caution, the pattern makes sense. More looping means more cost and more waiting.
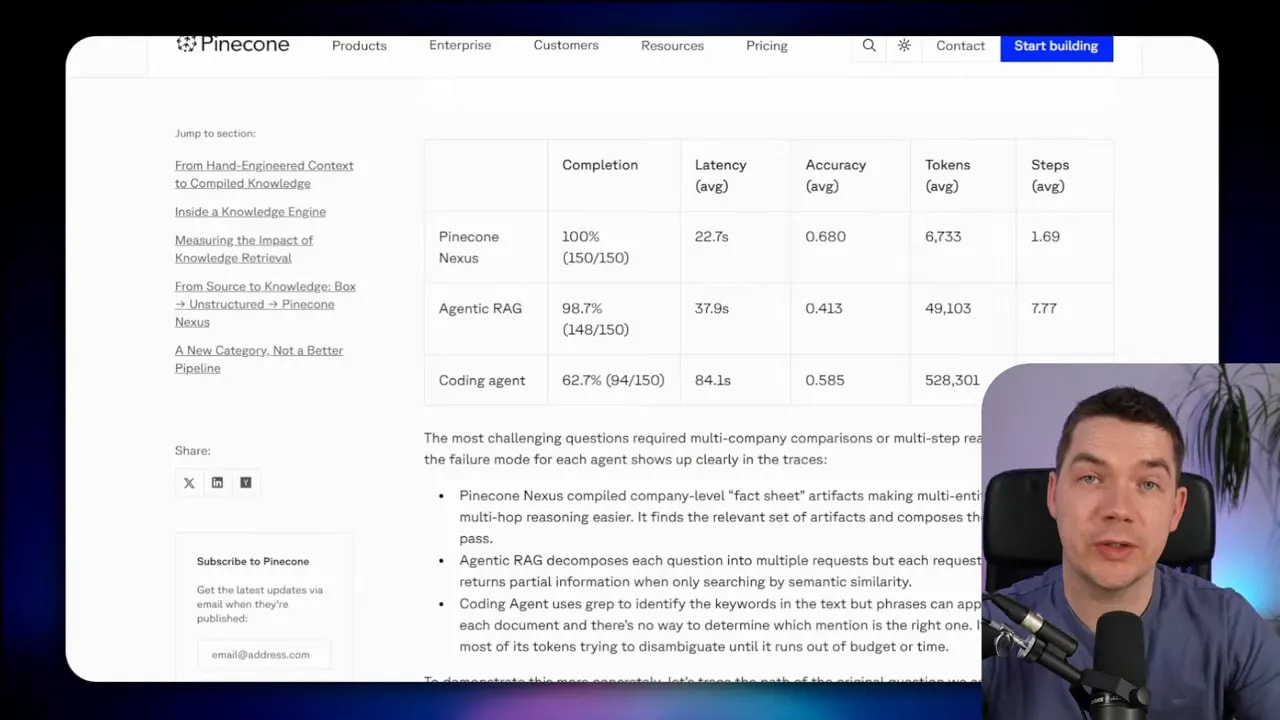
Pinecone’s headline claim was that roughly 85% of an agent’s effort goes into retrieval. Whether the exact percentage holds in every system is less important than the direction of the argument. Agents spend a huge amount of time figuring out where knowledge lives and how to gather it.
That’s the inefficiency this new pattern tries to remove.
The pattern replacing “search everything at query time”
The replacement isn’t “RAG is gone.” It’s more like this:
Compile a task-ready knowledge layer in advance, then let the agent query that layer directly.
That’s what Pinecone Nexus is trying to do.
It’s also what Karpathy’s LLM wiki is doing in a much lighter form. His version is elegant because it’s basically just markdown files that accumulate synthesized knowledge over time. No huge infrastructure requirement. No giant platform setup. The key insight is the same: create a persistent artifact that compounds knowledge so the model doesn’t start from zero every time.
Google and Microsoft are also moving in this direction, though their versions are more tightly bound to enterprise data systems.
- Google Knowledge Catalog acts like a refreshed semantic layer over data sources and exposes that to agents via MCP.
- Microsoft Fabric IQ uses a compiled ontology where the graph shape is defined up front and then connected to underlying data.
- Pinecone Nexus compiles structured artifacts from raw source data and lets agents query those artifacts.
- Karpathy’s LLM wiki maintains a persistent, compounding knowledge artifact built from source files.
All of these approaches put something in between raw data and the agent.
That intermediate layer is the real pattern.
This idea isn’t actually new
I don’t think this should be framed as some sudden revolution. It’s a new version of an older idea.
GraphRAG was already doing a form of knowledge compilation. You ingest data, extract entities and relationships, place them on a graph, and query that graph later. That’s still a knowledge layer. It’s just a different format.
What’s changed is the level of attention this pattern is getting, and the fact that major companies are now shipping products around it.
That alone tells you something important: standard agentic retrieval is hitting limits in production systems.
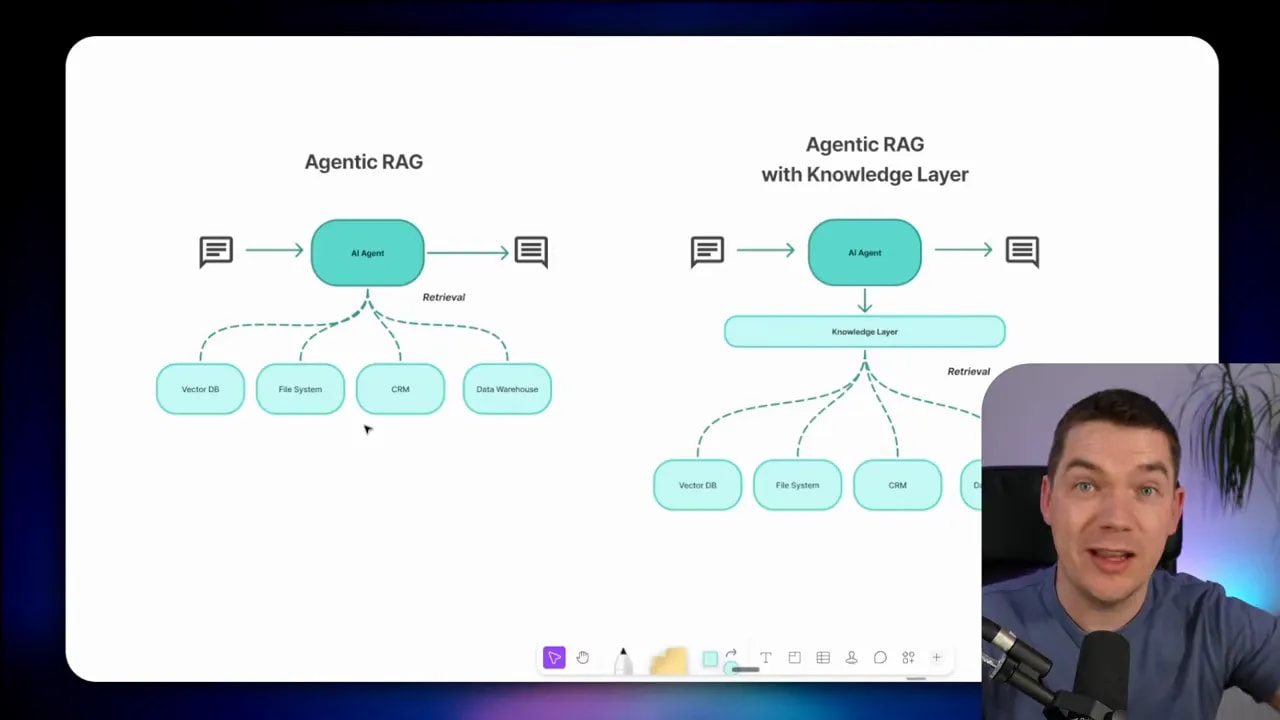
How Pinecone Nexus works at a high level
Pinecone describes Nexus as a compiled knowledge engine that sits between your data sources and your agent.
The easiest way to understand it is to compare two setups:
- Traditional agentic RAG: the agent plans a retrieval strategy, queries multiple sources, gets back chunks, reasons over them, and eventually produces an answer.
- Compiled knowledge layer: the agent makes one structured request to the knowledge engine, and the engine returns a structured answer built from precompiled artifacts.
Pinecone’s demo makes that contrast very clear.
The example question is whether a specific company qualifies for a renewal discount. In a standard agentic RAG setup, the agent would need to collect contract terms, usage metrics, policy rules, and probably customer-specific details. That means multiple tool calls, multiple retrieval steps, lots of chunks, and then a final synthesis.
In the Nexus version, the agent makes a single tool call with a defined request and response shape. The system returns structured information that already answers the question.
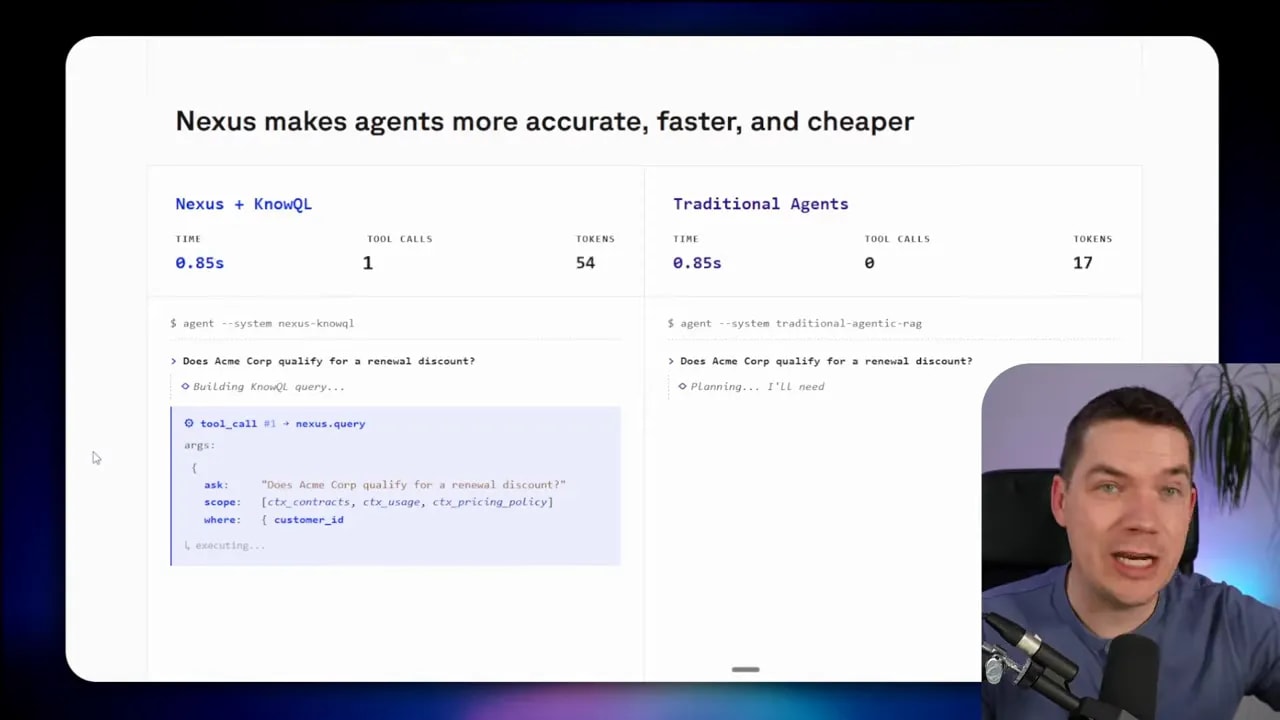
That difference matters because the output is no longer “a pile of retrieved context.” It’s an answer-shaped object with governed fields.
In other words, the retrieval layer has been upgraded from search to prepared knowledge access.
The core building block: artifacts
The central object in Nexus is the artifact.
An artifact is a typed, governed, compiled piece of information built for a specific task or job.
Think of it as a task-ready view of the data.
If an agent needs to answer a financial question, it might query an artifact containing revenue, margin, and key metrics for a company. If a compliance agent needs to inspect risk exposure, it may use a different artifact built from the same underlying documents but shaped differently.
That point is important. The same raw source data can produce multiple artifacts depending on the job you’re optimizing for.
This is where compiled knowledge differs from ordinary retrieval. Standard retrieval asks, “What chunks seem relevant?” Compiled knowledge asks, “What information structure will help this task succeed repeatedly?”
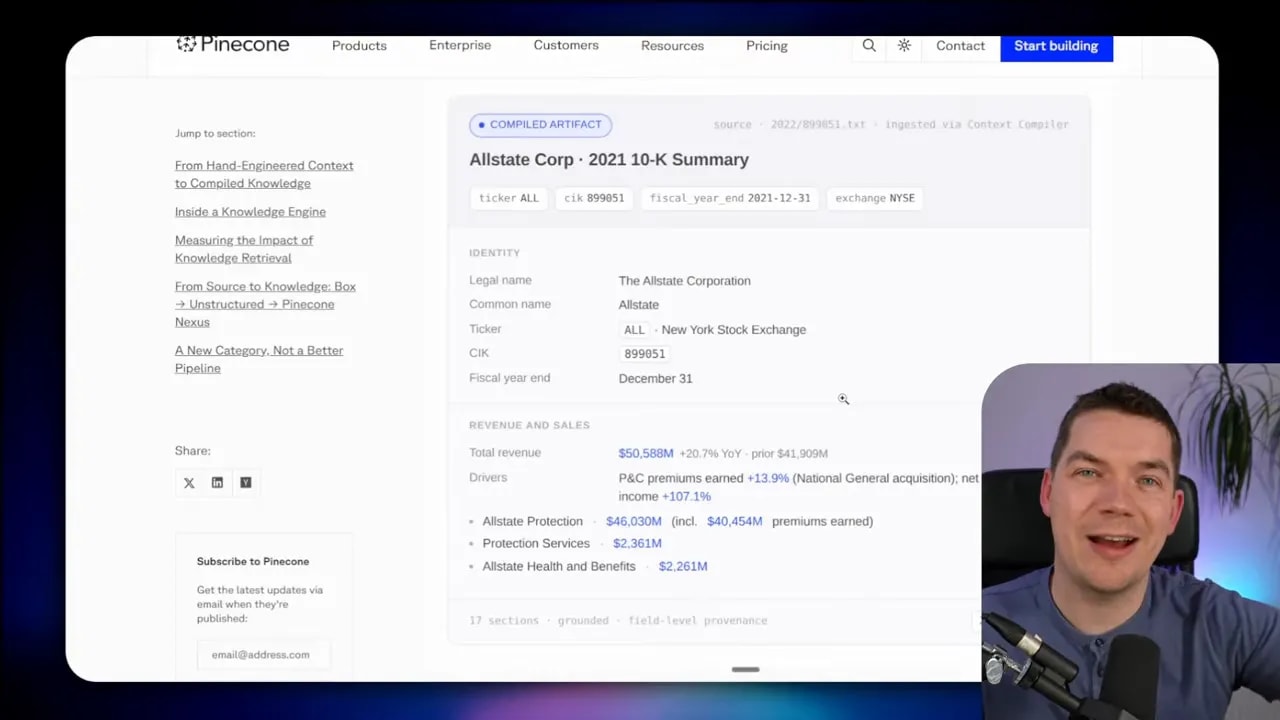
Pinecone shows artifacts organized across different contexts such as finance, sales, marketing, and support. Each context has task-specific artifacts that support the common work done in that area. Then above those sits a more general knowledge collection that can span contexts when needed.
That means you don’t just have one giant universal knowledge base. You have purpose-shaped knowledge views.
The context compiler: where the real magic happens
The most interesting part of the Nexus architecture is what Pinecone calls the context compiler.
This is an autonomous coding agent that builds those task-optimized artifacts.
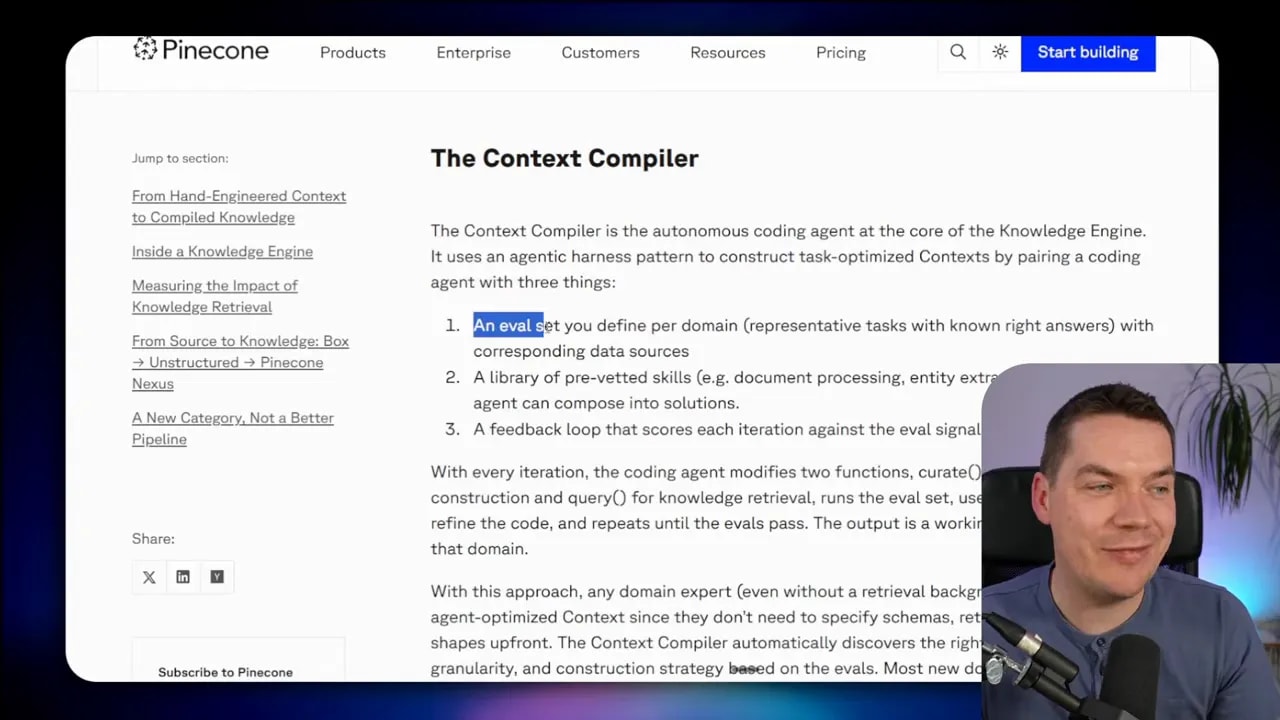
Instead of asking a human to manually define every schema up front, Pinecone’s approach tries to discover the right artifact structure through an evaluation loop. The compiler uses:
- an eval set of representative tasks with known correct answers
- a library of skills such as parsing, chunking, entity extraction, and document processing
- an agentic harness that iterates until the artifact design passes the evals
That’s quite a novel setup.
It means the schema is not initially hand-authored in detail by the user. Instead, the system tries to infer what shape of artifact best supports the known tasks in that domain.
I think this is both clever and limiting.
It’s clever because a domain expert could, in theory, define the typical tasks and right answers without needing deep retrieval expertise. The compiler then discovers the structure and logic needed to support those tasks.
It’s limiting because this pattern depends heavily on known tasks. If you can’t define representative jobs and expected outputs in advance, then compilation gets much harder. This is not ideal for infinite open-ended exploration.
That’s one of the biggest truths about compiled knowledge layers. They work best when the question shapes are at least somewhat known ahead of time.
That’s also why this pattern maps so well to Karpathy’s LLM wiki. The wiki is also a maintained knowledge artifact. It moves reasoning from query time to build time. It includes maintenance logic. It improves cross-reference quality. It accumulates knowledge instead of rediscovering it.
Same pattern. Different implementation.
Build time versus query time
The simplest way to think about all of this is to split the system into two phases.
Build time
- Raw data comes in from sources like file stores, CRM systems, databases, or vector stores.
- A compiler agent processes that data.
- It extracts, assembles, and structures knowledge into artifacts.
- Those artifacts are optimized for specific tasks and domains.
Query time
- The agent asks for a structured answer.
- The knowledge engine retrieves the relevant artifact or artifact view.
- The answer comes back with much less reasoning required at runtime.
So instead of paying the full cognitive cost every time a question arrives, you prepay some of that cost when data is ingested or updated.
That’s why compiled knowledge can cut token usage and latency so sharply for repeated tasks.
KnowQL: a query language for knowledge, not chunks
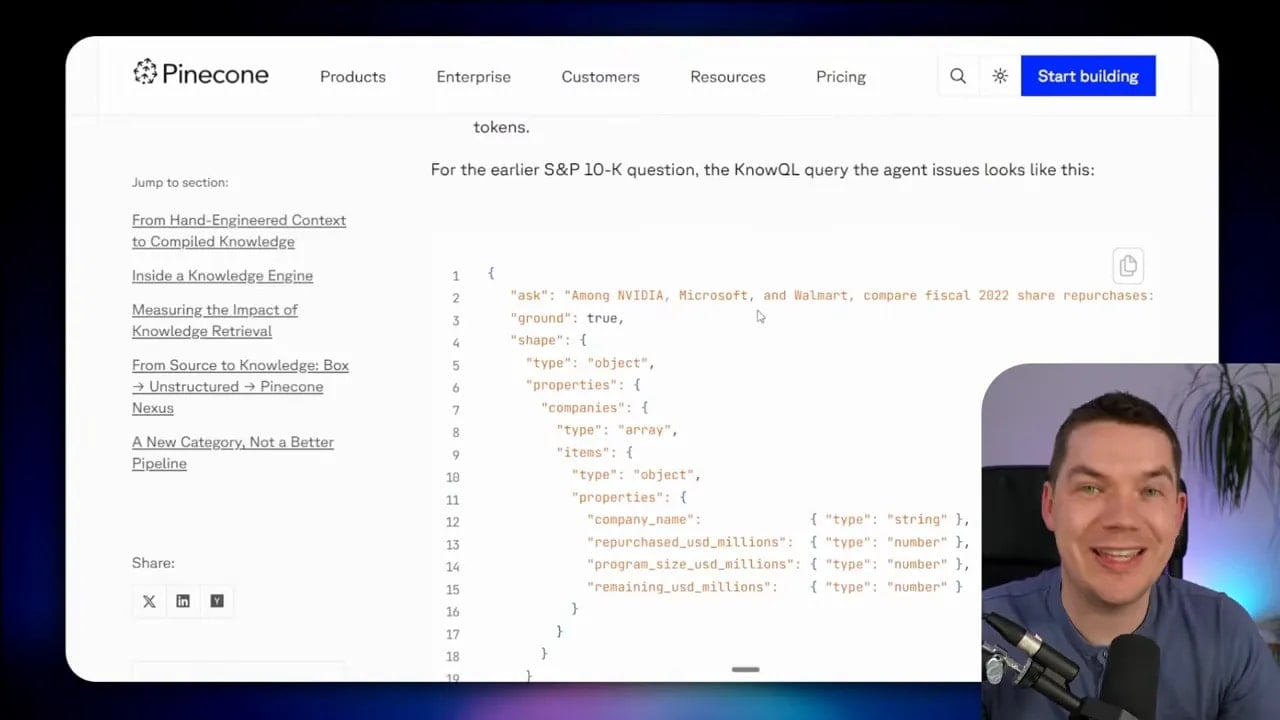
Pinecone introduces something called KnowQL, short for knowledge query language.
The idea is fairly simple. Rather than asking the engine to run an open retrieval process, the agent sends a declarative request that includes:
- intent
- filters or scope
- provenance controls
- the desired output shape
That’s conceptually closer to SQL than to classic vector search.
With SQL, you specify joins, filters, and projections. With KnowQL, the agent declares the information it needs and the structure it expects back.
There are still some open questions here. For an agent to construct that request properly, it needs to know the available fields and schema. It has to know that customer_id exists, for example, or how a property is named. Pinecone doesn’t fully explain how the agent gets that schema awareness. My guess is that it’s either in the system prompt or available through a schema-fetching tool.
Pinecone’s docs are also a bit vague about what happens inside the engine after the request arrives. It may route some requests to deterministic prebuilt query patterns. It may use deterministic lookups. It may use a smaller internal model in some cases. The examples don’t make that fully clear.
That matters because flexibility and reliability usually trade off against each other. If the query patterns are highly frozen, the system should be very reliable for expected jobs, but less flexible for unusual ones.
That’s not a flaw by itself. It just means you should use this pattern where that tradeoff makes sense.
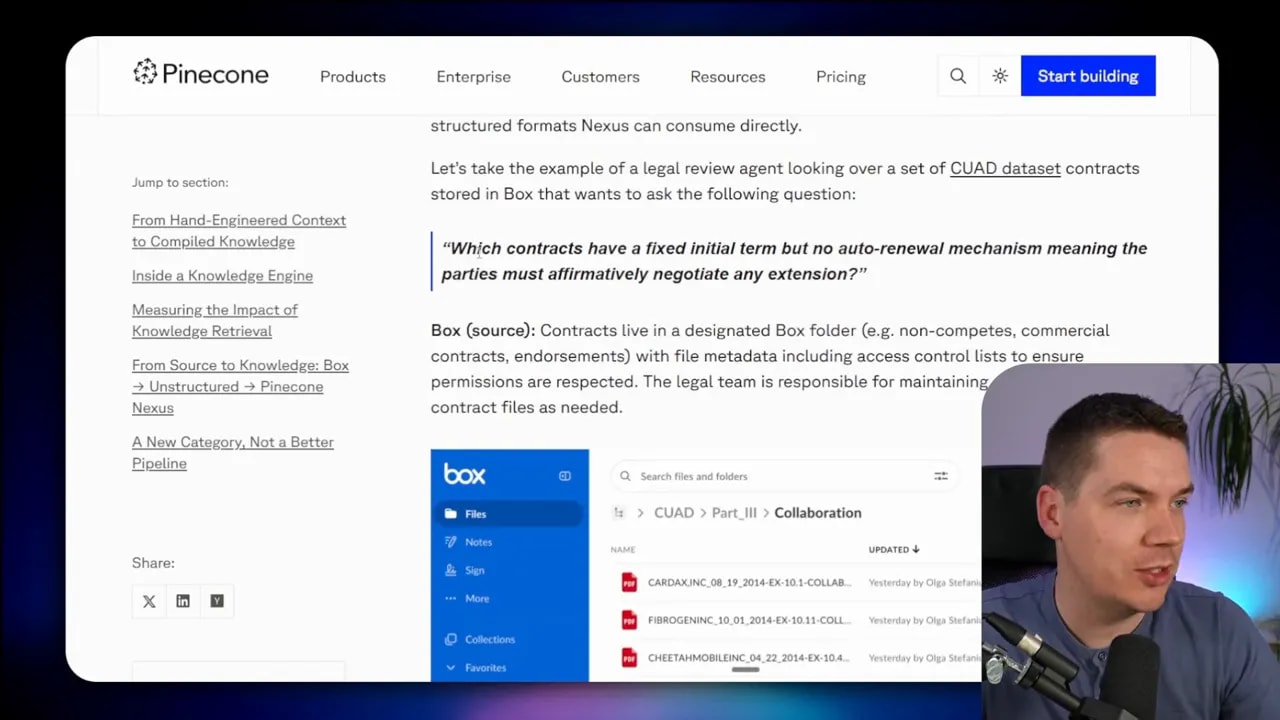
A concrete example: legal contract review
Pinecone gives an end-to-end example that helps make this architecture more tangible.
The scenario is a legal review agent answering this question:
Which contracts have a fixed initial term but no auto-renewal mechanism?
Here’s the flow:
- Contracts live in a file repository like Box.
- An external parsing service extracts document elements, tables, and entities from the PDF contracts.
- That parsed output is ingested into the knowledge engine.
- The context compiler runs with known legal tasks in mind.
- One result is a compiled artifact that aggregates contract renewal terms across many contracts.
- The legal agent can answer the question by fetching that artifact rather than rereading every contract.
This is where the value becomes obvious.
If you had 37 contracts and asked that question with standard agentic RAG, you might need repeated searches across all of them. You might even need large portions of all 37 contracts brought into context to be confident in the answer. With a compiled artifact, the system can answer from a prebuilt aggregate view.
That’s much faster. It’s also easier to govern, because each field in the artifact can carry provenance back to the source document.
Where the benefits are real
I think there are several benefits here that are very believable.
Lower runtime cost
If the same kinds of questions are asked repeatedly across large data sets, precompiling the answer structures can reduce token use dramatically. You’re no longer paying for rediscovery every time.
Lower latency
One good request beats six messy tool calls almost every time. A compiled layer should reduce waiting because the work has already been done earlier.
More reliable task completion
If the artifacts are correct and maintained properly, the system should answer known tasks more consistently than an agent improvising a retrieval strategy each time.
Stronger governance and provenance
This part is especially important in enterprise settings. Field-level provenance is much better than asking an LLM to cite chunks correctly after the fact. A structured artifact can preserve direct grounding to source data.
So yes, the value proposition is real.
If you’re repeatedly answering the same family of questions across a big messy corpus, a compiled knowledge layer makes a lot of sense.
The gaps and risks that still matter
I’m interested in this pattern, but I’m not interested in pretending the gaps don’t exist.
1. What does compilation cost?
This is the most obvious question.
It’s easy to celebrate lower query-time cost. But what does it cost to generate the artifacts in the first place? If coding agents are iterating through eval loops, that can get expensive quickly.
Then there’s maintenance. Data changes. Documents update. Policies change. Contracts get revised. Someone has to recompile or patch the artifacts.
Pinecone says this happens when data changes rather than on every call, which is sensible. But the actual economics of compilation matter a lot. This is part of why some graph-based approaches struggled. Recomputing structured knowledge over time can become hard to justify if the refresh cost is too high.
2. Is compile-time synthesis being treated as truth?
This is the deepest issue.
If artifacts are generated through LLM-driven synthesis, then the system may be treating that compile-time interpretation as ground truth. That can be risky.
Karpathy’s LLM wiki drew this exact criticism. Summaries are lossy. Compiled representations reduce fidelity. Once you step away from the source, you may gain speed and structure, but you can lose nuance and precision.
That’s the tradeoff.
Raw-source interrogation has a major advantage: it stays closer to the original truth. Compiled artifacts can drift, omit details, or encode small mistakes that later get reused with confidence.
3. How tightly are artifacts bound to source data?
This is where Pinecone’s approach seems different from Microsoft and Google.
Microsoft’s ontology and Google’s semantic layer sound more like governed bindings or views on top of source data. Pinecone’s artifacts seem more LLM-generated and synthesized, especially for unstructured documents like PDFs. If that reading is correct, then fidelity becomes a bigger concern.
It’s possible Pinecone has stronger binding mechanisms than the public docs make clear. But from what’s available, that distinction matters.
4. What happens on the long tail?
This is the practical question every builder should ask.
What happens when the agent gets an open-ended question that doesn’t map neatly to any existing artifact?
Does the system fall back to hybrid search? Does it route to ordinary retrieval? Does it fail gracefully? Does it try a broader artifact set?
If a fallback exists, it has to be handled carefully. If you expose standard retrieval too eagerly, the agent may use it constantly and you lose the benefit of the compiled layer. If you don’t expose it at all, the system may be too rigid.
That fallback strategy is one of the most important design choices in this entire architecture.
So is agentic RAG dead?
No. It’s still the default.
It’s far easier to connect an agent to tools and data sources and let it work through an agentic retrieval loop than it is to build and maintain a compiled knowledge layer. For many applications, that’s still the right call.
Agentic RAG remains useful because it is flexible. It handles exploration better. It handles unknown questions better. It’s easier to ship.
But it clearly has weaknesses:
- high token use
- slow response times
- inconsistent retrieval paths
- difficulty with repeatable, high-accuracy tasks across large data sets
Compiled knowledge layers make more sense when you have:
- many data sources that need a unified view
- repeatable task patterns
- tight governance requirements
- strong demand for low latency and predictable outputs
They make less sense for broad, exploratory agents where users are effectively exploring a knowledge base in unpredictable ways.
That’s why I see this as an escalation path rather than a total replacement.
Start with agentic RAG. Improve retrieval as much as you can. Add reranking, better chunking, query decomposition, filtering, and smarter tool use. If you still can’t reach the reliability and speed your tasks require, then a compiled knowledge layer starts to become very compelling.
If I were building this pattern myself
One reason this whole topic interests me is that I don’t just want to understand Pinecone’s product. I want to understand the architecture well enough to recreate the useful parts in a custom system.
And honestly, some of the artifacts Pinecone shows look a lot like SQL-friendly structures.
If I already knew the artifact shape I wanted, I could imagine building a simplified version like this:
- Identify the exact source systems needed for the task.
- Define the output structure for the artifact.
- Run a batch job that extracts and processes the relevant data.
- Store the compiled results in a relational database.
- Use indexed SQL queries, perhaps with JSON filtering where needed, to retrieve fast structured answers.
- Run delta updates as source documents change.
That wouldn’t reproduce Pinecone’s full dynamic compiler setup, but it would reproduce the essential pattern: move expensive synthesis away from query time and store task-ready knowledge in a governed structure.
In fact, for many narrow use cases, a handcrafted compiled layer may be more practical than a fully autonomous artifact compiler.
That’s another useful takeaway here. The big idea is more important than the product wrapper.
The architectural shift worth paying attention to
The most important change here isn’t that Pinecone launched Nexus. It’s that multiple serious players are now converging on the same answer to the same problem.
That answer is this:
Agents need better knowledge infrastructure, not just better models.
If an agent keeps rediscovering the same facts from the same raw documents, then the architecture is wasting compute. If every task requires a fresh retrieval plan, then the system will stay slow, costly, and inconsistent. If provenance matters, then loose chunk citation is not enough.
A knowledge layer changes that by giving the agent something more stable to reason over.
That layer can take different forms:
- markdown wiki files
- compiled artifacts
- graphs
- semantic catalogs
- ontologies
- SQL-backed structured views
Different implementations will make different tradeoffs. Some will favor flexibility. Some will favor governance. Some will stay very close to source truth. Others will lean more on synthesis.
But the pattern is clear now. The future probably isn’t raw agentic RAG alone, and it probably isn’t “just stuff more into the context window” either. It’s a stack where retrieval gets shaped, compiled, and governed before the agent ever asks its question.
Pinecone simply made that shift impossible to ignore when it admitted the current setup has fundamental problems.
If you want the source material behind this shift, Pinecone’s framing on knowledge infrastructure for agents and its Nexus launch post are worth reading side by side. The interesting part isn’t the marketing. It’s the architecture they’re pointing at.
