

There’s a huge race happening in AI right now to define what comes after conventional RAG.
By this point, most people have heard some variation of “RAG is dead.” I don’t buy that framing. It’s usually too dramatic, and the proposed replacements are often too simple. What is true is that basic retrieval pipelines break down very quickly once you move beyond polished demos and try to build AI agents that have to deal with large, fast-moving business data.
That’s where Redis Iris gets interesting.
Redis recently announced Iris as a new architecture for AI agent retrieval. I think it’s worth paying attention to, especially if you’re building agents that depend on data spread across databases, tools, and systems that update constantly. Redis is taking a very different angle from “stuff some documents into a vector database and hope for the best.”
This matters because many production AI systems fail in exactly the same places. They fail at runtime. They fail because the state is stale. They fail because retrieval is slow. They fail because memory is fragmented. They fail because tools and data don’t line up properly. And they fail because a session doesn’t accumulate useful context over time.
Redis Iris is one attempt to solve that with a dedicated context layer between the agent and the underlying data sources.
I’m not talking about a magic product that solves retrieval by itself. It doesn’t. But the architecture is strong enough that it deserves a serious look, even if you never use Redis directly.
Why basic RAG struggles in production
The easiest way to understand why Iris exists is to look at a simple business question:
“Why is my order late?”
That sounds simple. For a production agent, it usually isn’t.
To answer that properly, the system may need access to:
- The customer database
- The order management system
- The shipping provider
- The support ticketing tool
- Internal policy documents
A naive RAG setup is almost never enough for that kind of task. Even many “agentic RAG” systems still struggle. If the agent has to join data across multiple systems in real time, reason over relationships, and stay current while all of that data keeps changing, simple retrieval falls apart fast.
That’s the gap Redis is trying to address.
Redis’ CEO framed the problem very clearly in a blog post about production AI. He argued that the hardest problems are no longer solved by model choice. They show up during execution: stale state, slow retrieval, fragmented memory, disconnected tools, and sessions that don’t compound.
I think that’s exactly right. Model quality still matters, of course. But once you’re working on serious systems, retrieval architecture and context management start to matter just as much, and often more.

The four requirements Redis highlights for agents at scale
Before getting into Iris itself, Redis lays out four requirements for agents that need to work at scale. These are framed around their product offering, but they’re also a useful checklist for anyone building production AI systems.
1. The agent needs to move through a large amount of data
An agent has to understand entities, relationships, and relevant context. It needs to move across connected data without getting lost.
That sounds obvious, but it’s one of the biggest weak points in retrieval. Many systems treat information as isolated chunks. Real business data usually isn’t structured that way. A customer connects to orders. Orders connect to shipments. Shipments connect to delays, events, policies, and tickets.
If the agent can’t move through those relationships cleanly, the answer quality suffers.
2. Context needs to be fast to retrieve
High-quality retrieval often adds latency. Agents may loop through several retrieval steps before they reach the right information. That can make systems painfully slow.
Speed matters a lot in practice. A retrieval strategy that looks smart on paper but takes too long to execute is a bad fit for many production cases.
3. Context needs to stay current
This is the part many retrieval systems still handle badly. Data that was accurate ten minutes ago may already be wrong. If an agent answers using stale order status, stale inventory, or stale account information, it can do real damage.
Freshness isn’t a nice extra. In many operational settings, it’s a core requirement.
4. The system should improve over time
Most agents still have weak memory. They don’t retain enough from previous interactions. They don’t accumulate useful patterns. And they often treat each session too independently.
Short-term state matters during a conversation. Long-term memory matters across conversations. If you want an agent to feel consistent and capable, both layers matter.
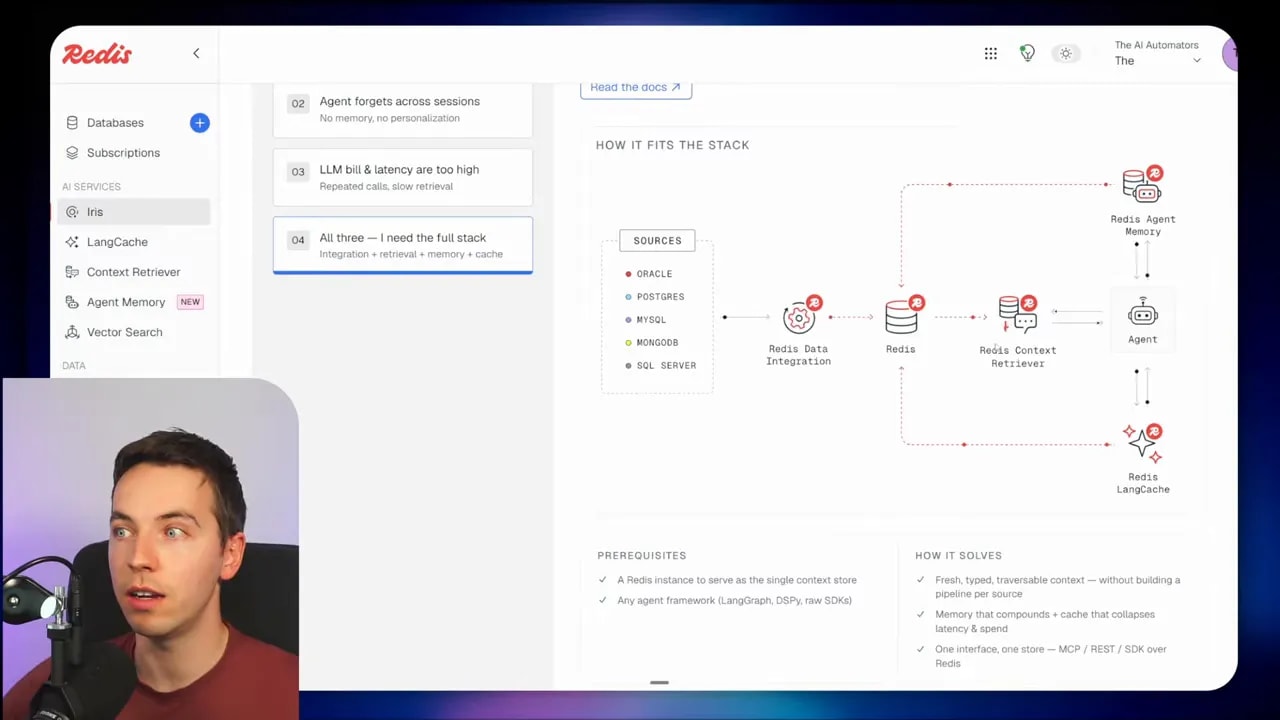
What Redis Iris actually is
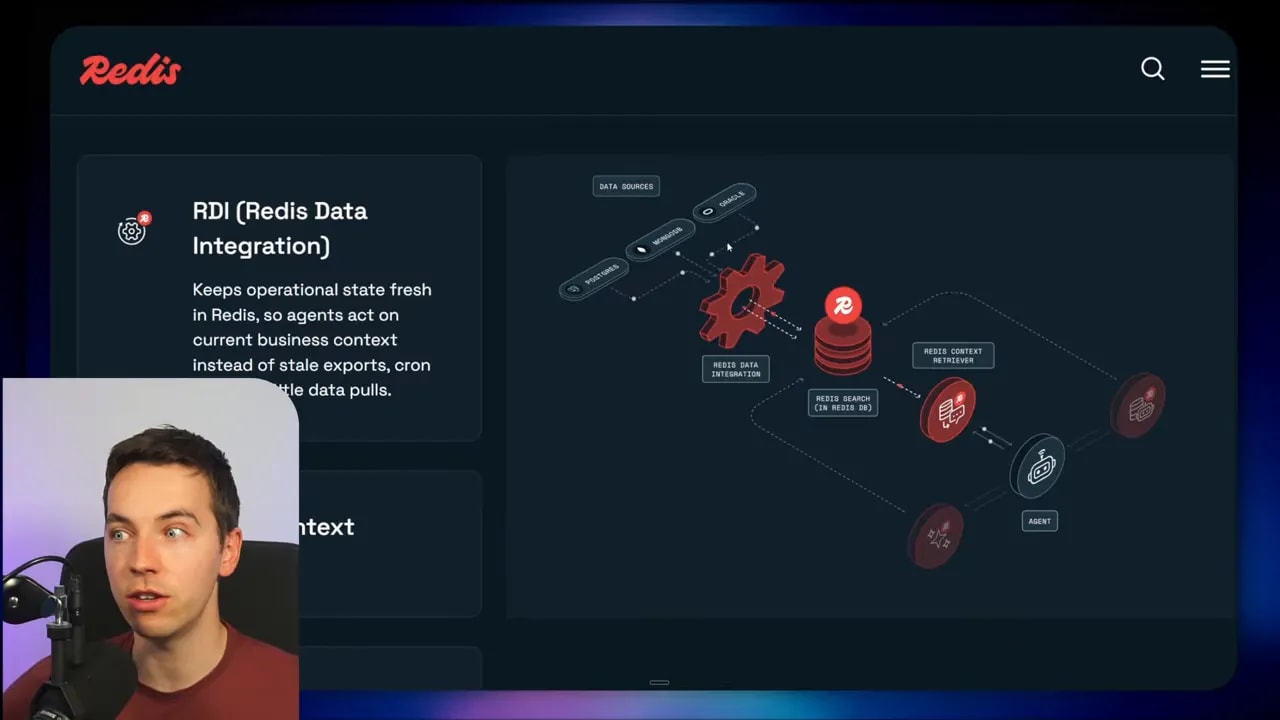
Redis Iris isn’t one single feature. It’s a stack of Redis services working together as a retrieval and context layer for agents.
At a high level, the architecture works like this:
- Your source data lives in systems like Postgres, Oracle, MongoDB, or Snowflake.
- Redis Data Integration continuously captures changes from those systems.
- That data gets synced into Redis data structures as an operational copy.
- The agent interacts with that copied data through the Redis Context Retriever using MCP or CLI tools.
- Redis Agent Memory stores short-term and long-term memory across sessions.
- LangCache caches previous responses and can return them instantly if a similar request appears again.
The key idea is simple: the agent doesn’t hit the operational systems directly. Instead, it talks to a fast, synced copy of the data inside Redis.
That one decision changes a lot.
It reduces pressure on transactional systems. It makes the data easier to search. It gives you more control over how the agent accesses information. And it creates a place where retrieval, memory, and caching can all work together.
Redis Data Integration: keeping the agent’s data fresh
The first major piece is Redis Data Integration, often shortened to RDI.
RDI uses a change data capture pattern. That means it listens for updates in source systems and syncs those changes into Redis. Instead of relying on periodic exports or stale snapshots, Redis tries to maintain a fresh operational copy of the data.
Supported source systems mentioned here include:
- PostgreSQL
- Oracle
- Snowflake
- MongoDB
This directly addresses the freshness problem. If your source system changes, the Redis layer updates with it.
That has several practical benefits.
It protects your transactional systems
One of the easiest mistakes in agent design is letting an agent hammer production systems directly. Humans might make a few lookups. Agents can make thousands of calls, especially if they loop, branch, or retry.
If a busy AI system is querying your operational database constantly, that can become a performance problem very quickly.
By keeping a copy of the data in Redis, the retrieval workload shifts away from the systems that run the business.
It makes the data easier for agents to use
Operational databases are often optimized for business logic and transactional integrity. That doesn’t mean they’re optimized for agent retrieval.
When the data is mirrored into Redis, it can be shaped in ways that are better for agent access. It can be indexed for speed. It can be flattened or denormalized. It can be organized to support the kinds of queries your agent actually needs.
That’s important because agents are bad at reconstructing business logic from a maze of tables and joins. If you want reliable retrieval, you usually need to present the data in a much cleaner way.
None of this is a new pattern by itself. Copying operational data into another system has been common for analytics and caching for a long time. What’s new is using that pattern as a dedicated context layer for AI agents.
Redis Context Retriever: giving agents usable tools instead of raw database chaos
The next piece is the Redis Context Retriever, and this is where the architecture becomes especially useful.
Instead of asking the agent to reason directly over raw database structures, you define models of your business data. That includes:
- Entities
- Fields
- Relationships
- Permissions
- Available operations
Those models are then exposed to the agent through tools using MCP or CLI.
This is a much better pattern than expecting an agent to improvise SQL-like behavior across several systems at once. In practice, that’s often unreliable.
Instead, you define clear data objects such as:
- Customer
- Order
- Product
Then you define the operations the agent is allowed to perform, such as:
- Get customer by ID
- Search customers by text
- Find products by price range
- Filter products in stock
- Filter by tags
That gives the agent a controlled, structured way to retrieve context as needed.
It also supports row-level access control. That matters a lot. In a real system, you rarely want every agent to have access to every record. Permissions need to be part of the retrieval design, not added as an afterthought.
I think this is one of the strongest ideas in the stack. Agents are usually much more reliable when they use well-defined tools than when they’re expected to infer how to query business data from scratch.
It’s the difference between giving someone a labeled control panel and dropping them into a warehouse full of parts.
Redis Agent Memory: short-term and long-term memory for sessions that compound
Redis also includes an Agent Memory layer. This covers both short-term memory and long-term memory.
Memory is one of those areas where AI systems often sound much more capable in theory than they are in practice. A lot of agents still forget too much, too quickly, or they remember the wrong things.
Redis splits the problem into two parts.
Short-term memory
This is session memory. It helps the system preserve conversation state and maintain continuity during the current interaction.
Redis allows a custom TTL, or time-to-live, for this memory. That’s useful because different systems have different freshness needs. In some environments, keeping temporary state for a while is fine. In others, data becomes invalid very fast, so the memory should expire quickly.
If the underlying business data changes frequently, getting that TTL right matters a lot.
Long-term memory
This layer stores information extracted from past sessions. That may include:
- User preferences
- Learned patterns
- Relevant historical context
- Information promoted from short-term memory
The promotion step matters. Not everything from a session deserves to live forever. A good memory system needs to decide what should be kept and what should expire.
Everything else gets deleted according to the TTL policy.
This fits a wider industry trend. There are many memory solutions appearing across the AI stack right now. Redis is one option among many, but the underlying need is very real. If an agent can’t preserve useful context over time, it struggles to become meaningfully better with use.
LangCache: useful, fast, and potentially dangerous
The next component is LangCache, which handles response caching.
The idea is straightforward. Instead of calling the language model every time, the system can check whether a similar request was answered before. If so, it can return the cached response immediately.
That can save both time and money.
In the right setting, semantic caching is very useful. If the same kinds of requests repeat often, there’s no reason to regenerate every answer from scratch.
But there’s an important catch.
Response caching can also become a minefield if it returns something that is similar on the surface but wrong in context. That’s especially risky in business systems where timing, account state, and permissions matter.
Redis lets you search the cache using similarity thresholds and different search strategies, such as exact search or semantic search.
That flexibility is helpful, but it doesn’t remove the risk. Similarity thresholds are still a blunt tool. You have to evaluate caching behavior carefully. Otherwise, a system can serve answers that look plausible and fast but are subtly incorrect.
That’s a recurring theme with this whole architecture. None of these parts are magic by themselves. They’re useful components that still need careful setup and testing.
Redis Search and Redis Flex: speed and scale matter too
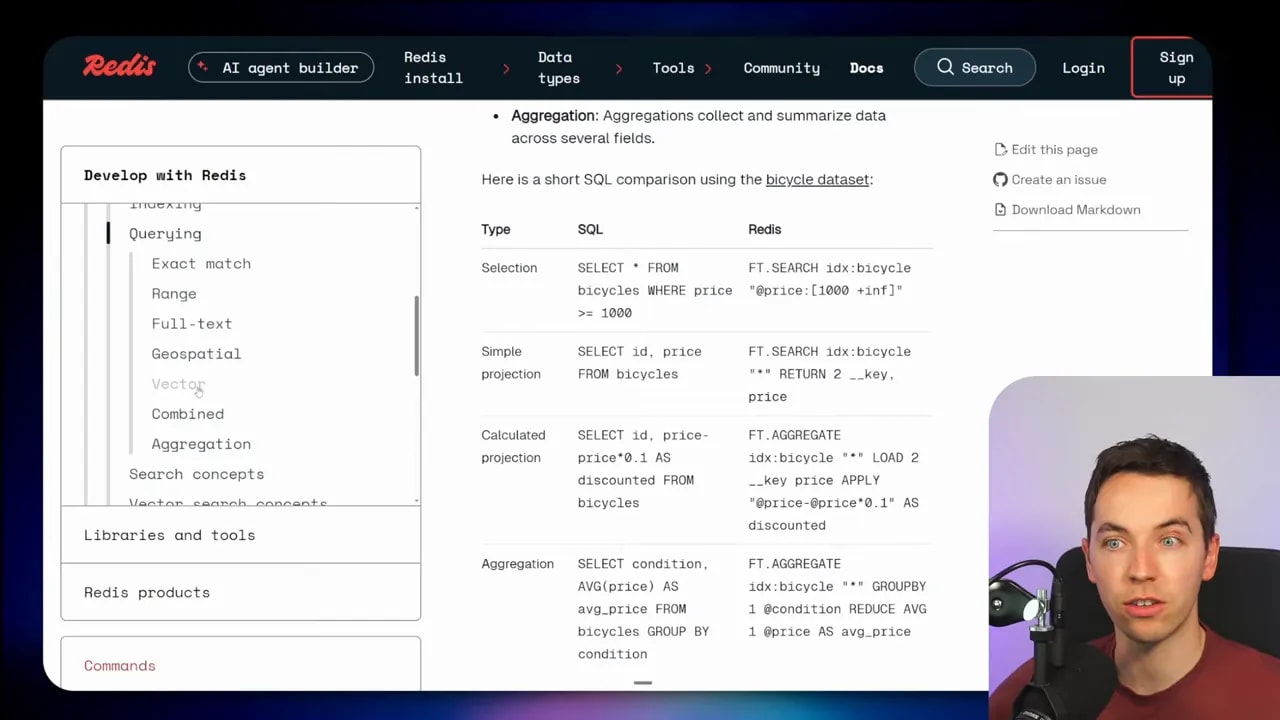
Under the hood, the data is queried using Redis Search.
One notable point here is that Redis Search can query:
- Vector data
- Structured data
- Unstructured data
And it can do that through one index.
That makes the system more flexible than a retrieval layer built around a single retrieval pattern. Real agent systems usually need more than vector search. They often need exact matches, ranges, filters, text search, and combinations of all of those.
Redis supports several query types, including:
- Exact match
- Range queries
- Full-text search
- Geospatial search
- Vector search
- Combined queries
- Aggregation
That breadth matters because real retrieval isn’t just “find semantically similar chunks.” A customer support agent might need a semantic search over policy text, an exact lookup on order ID, a range filter on delivery windows, and a structured search over account status, all in the same workflow.
Redis also claims its indexes can scale to one billion vectors, which is significant.
On the storage side, Redis introduced Redis Flex, an SSD-based storage tier. That matters for cost. Redis is known for in-memory speed, but pure in-memory storage can get expensive. An SSD-based tier changes the economics and makes larger-scale retrieval architectures more feasible.
This is not plug-and-play
It’s very important not to overread the marketing.
Redis is making a serious point here that I agree with: retrieval is not solved by a single simple layer. If anything, Iris shows the opposite. To build a good context layer, you need several components working together:
- Fresh synced data
- Structured access patterns
- Permission controls
- Memory management
- Caching strategy
- Fast search across multiple data types
That’s a modular stack, not a shortcut.
So no, this is not a case where someone signs up for Redis and suddenly retrieval is solved. It still requires real implementation work.
You need to keep the retrieval layer aligned with the source systems. You need to model entities and relationships properly. You need to expose the right tools. You need to test cache behavior. You need to think carefully about what memory should persist and for how long.
That doesn’t make the approach weak. It makes it honest.
The biggest problem with AI retrieval over the last year has been oversimplification. Too many systems looked convincing in demos because the data was small, static, and carefully arranged. Production systems are messier. They have permissions, updates, strange edge cases, and several systems that don’t fit together cleanly.
An architecture that acknowledges that mess is usually a better sign than one that pretends retrieval has become trivial.
Redis Iris vs. Pinecone Nexus: runtime versus build-time knowledge layers
The most interesting comparison here is with another new direction in the market: Pinecone Nexus.
I covered that approach separately in a breakdown of Pinecone Nexus, and it’s useful to compare the two because they represent very different philosophies.
Pinecone Nexus focuses on build time
Pinecone’s approach is to precompile typed knowledge artifacts. Think of stable domains like sales, support, finance, or marketing. Instead of retrieving raw context on every call, the agent queries a prepared knowledge artifact.
That can work very well when:
- The knowledge base is large but relatively stable
- The same question types appear repeatedly
- You want predictable retrieval over known material
- The cost of recompiling is acceptable when source data changes
Examples might include contracts, compliance manuals, internal handbooks, and recurring policy questions.
In that kind of environment, a precompiled knowledge layer makes a lot of sense.
Redis Iris focuses on runtime
Redis takes the opposite position. It doesn’t try to precompute a compiled knowledge layer. Instead, it keeps the data structures fast, current, and accessible so the agent can pull fresh context on demand.
That is much better suited to situations where the source data changes frequently.
If your source data can become stale within minutes, a precompiled artifact may already be outdated by the time the agent uses it. In those cases, runtime retrieval is the safer option.
The split is actually pretty clean
These two approaches line up well with different use cases:
- Build-time knowledge layers are strong when information is stable and recurring.
- Runtime context layers are strong when information changes quickly and freshness matters.
That’s why so many debates around retrieval go in circles. People often imagine different use cases without realizing it.
Someone working on compliance retrieval may see a compiled knowledge layer and think, “Yes, obviously.” Someone working on delivery operations or account support may see the same design and think, “That will be stale almost immediately.”
Both reactions can be correct.
Why this matters for anyone building AI agents
I think the biggest lesson here is broader than Redis itself.
There is no single retrieval architecture that fits every AI agent.
Basic RAG was often pitched as if it were a universal answer. Then agentic RAG became the next answer. Now context layers and knowledge layers are being presented as the next answer. In reality, each approach has tradeoffs, and the right design depends heavily on:
- How often your data changes
- How structured the data is
- How many systems the agent needs to access
- How sensitive the permissions are
- How much latency the workflow can tolerate
- Whether repeated questions are stable enough for caching or precompilation
If I were evaluating Redis Iris for a real build, I’d ask a few simple questions first:
- Does the agent rely on operational data that changes frequently?
- Would direct access to transactional systems create performance or safety issues?
- Can I model the data cleanly as entities, relationships, and tools?
- Do I need row-level permissions in the retrieval layer?
- Will caching help, or is the risk of stale context too high?
- Does session memory actually improve the workflow, or does it introduce confusion?
If the answer to several of those is yes, then Redis’ architecture starts to look much more compelling.
A better way to think about “the next generation of RAG”
I don’t think Redis is “the new RAG” in the sense that RAG disappears and Redis replaces it.
I think Redis Iris is part of a broader shift in how people are starting to think about retrieval. The unit of design is moving away from a simple vector search pipeline and toward a fuller context layer between the model and the source systems.
That context layer may include synced data, business entities, permissions, memory, caching, and several retrieval strategies at once.
That’s a much more realistic picture of what production AI needs.
For years, the industry has wanted retrieval to be easy. It usually isn’t. Good retrieval is deeply tied to the shape of the business data and the kind of decisions the agent has to make. If the data is messy, changing quickly, spread across several systems, and tied to permissions, then the retrieval layer has to reflect that.
Redis Iris is interesting because it embraces that reality instead of hiding it.
It says, in effect, that if you want agents to work reliably, you need a fast copy of fresh data, a clear tool layer, a memory strategy, and a thoughtful caching strategy. That is a much stronger starting point than pretending semantic chunk search can solve everything.
What builders should take away from Redis Iris
Even if you never touch the Redis stack, there are several useful design ideas here.
- Separate agent retrieval from core transactional systems. Don’t let agents hammer production databases directly if you can avoid it.
- Keep data fresh. In many workflows, stale context is worse than no context.
- Give agents structured tools, not raw access chaos. Clear entities and operations usually beat free-form querying.
- Treat memory as a system design problem. Decide what expires, what persists, and why.
- Be careful with semantic caching. Fast answers are great until they become wrong answers.
- Match the architecture to the data. Stable knowledge and fast-moving operational data need different retrieval patterns.
If you want to look at the product details directly, Redis has its own Iris overview. That’s useful for the feature list. But the more important takeaway is the architecture itself.
The current retrieval landscape is full of strong claims and weak abstractions. Redis Iris stands out because it reflects a harder truth: getting AI agents to work with real business data usually requires more structure, more care, and more runtime awareness than most simple RAG examples suggest.
That doesn’t make the problem less exciting. It just makes it real.
