

Every new model release brings the same promise. Better reasoning. Better synthesis. Better scores on the benchmarks.
And yet, if you build knowledge agents for real work, the failures that matter most still keep showing up.
I see this especially in retrieval-based systems. The model pulls in source material, then produces something that looks polished and confident, but the connection between the answer and the evidence is weaker than it should be. Sometimes it invents facts outright. Sometimes it stretches a narrow point into a broad claim. Sometimes it blends two separate chunks into one statement neither source actually supports. Other times it cites a real source, but the citation does not support the paragraph it is attached to.
That is what makes this hard. The mistakes are often subtle. As models improve, they do not always stop making these errors. They just state them more smoothly.
If you are building AI products for research, analysis, document creation, legal review, or report generation, you cannot treat verification as a nice extra. You have to build it into the system itself.
I want to walk through seven practical approaches I use for this. Some are simple UI patterns. Some are architectural decisions. Some go beyond grounding and move into actual source validation against external authorities.
The right choice depends on the type of product you are building, how much trust the user needs, and how expensive mistakes are.
Why a verification layer matters
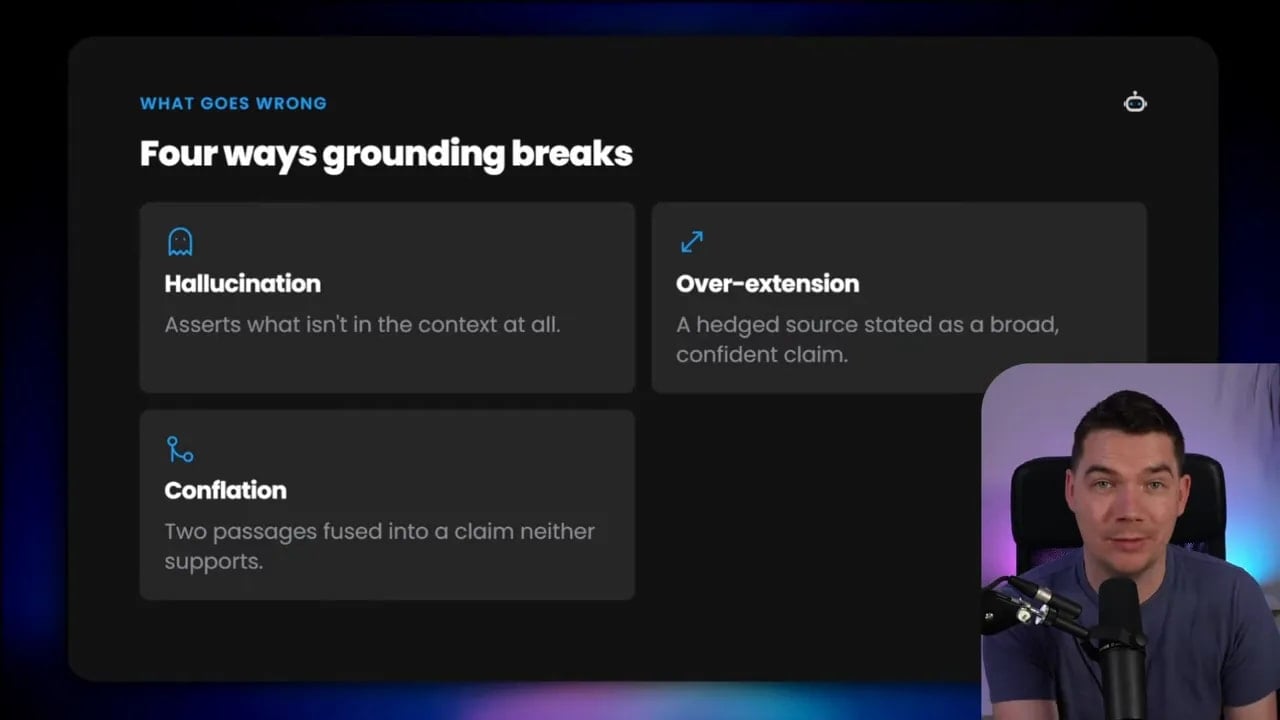
Before getting into patterns, it helps to be precise about the failure modes.
- Hallucination: the model states something that is not backed by the retrieved material at all.
- Overextension: the source supports a narrow point, but the model rewrites it as a broader, more confident statement.
- Conflation: the model fuses two separate retrieved chunks into a single claim that neither one supports on its own.
- Citation mismatch: the cited source exists, but it does not actually support the sentence or paragraph it is attached to.
These issues matter most in systems where the answer must stay close to the retrieved evidence. A casual chatbot can get away with a lot. A legal brief, investment memo, compliance report, or internal research assistant cannot.
There is also an important distinction that gets missed all the time. Faithfulness is not the same as truth.
A model can produce an answer that is perfectly faithful to a bad source. If the document is outdated, wrong, or misleading, the system can still give you a grounded answer that is wrong in the real world. So a good verification layer needs to answer one or both of these questions:
- Is the output faithful to what was actually retrieved?
- Is the underlying claim true when checked against authoritative sources?
Those are different jobs, and they need different patterns.
1. The NotebookLM style approach: show the evidence beside the claim
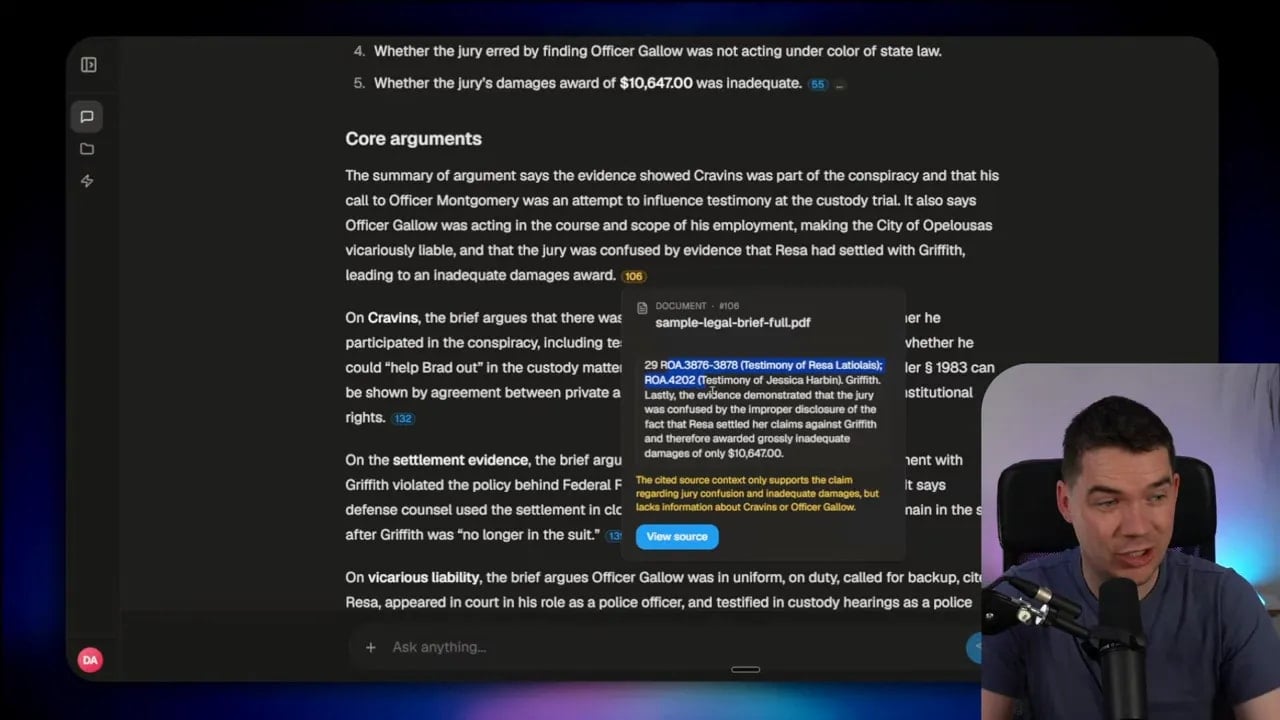
The first and most practical pattern is the one many people already recognize. The system generates inline citation markers, and the interface makes it easy to inspect the supporting evidence next to each claim.
I like this approach because it lowers the cost of human review. Instead of forcing someone to open a separate source, search around, and guess where the evidence came from, the system puts the answer and the evidence side by side.
That sounds simple, but there is an important detail here. Showing extracted text is useful, but it is often not enough.
Document parsing is imperfect. If your verification flow only shows parsed text, you may miss errors introduced during ingestion. A good example is footnotes inside PDFs. Imagine a sentence that says the annual fee was cut to 0.5%, followed by a footnote marker, and then the next sentence says 10 basis points were rebated to long-term investors. If the parser accidentally merges that footnote marker into the next number, the extracted text can make it look like 510 basis points were rebated. The text looks clean. The original page tells a different story.
That is why I prefer grounding against the original document, not just the extracted text. The strongest implementation includes bounding boxes or exact highlighted regions on the source page, so the system can show the actual snippet used to support the generated claim.
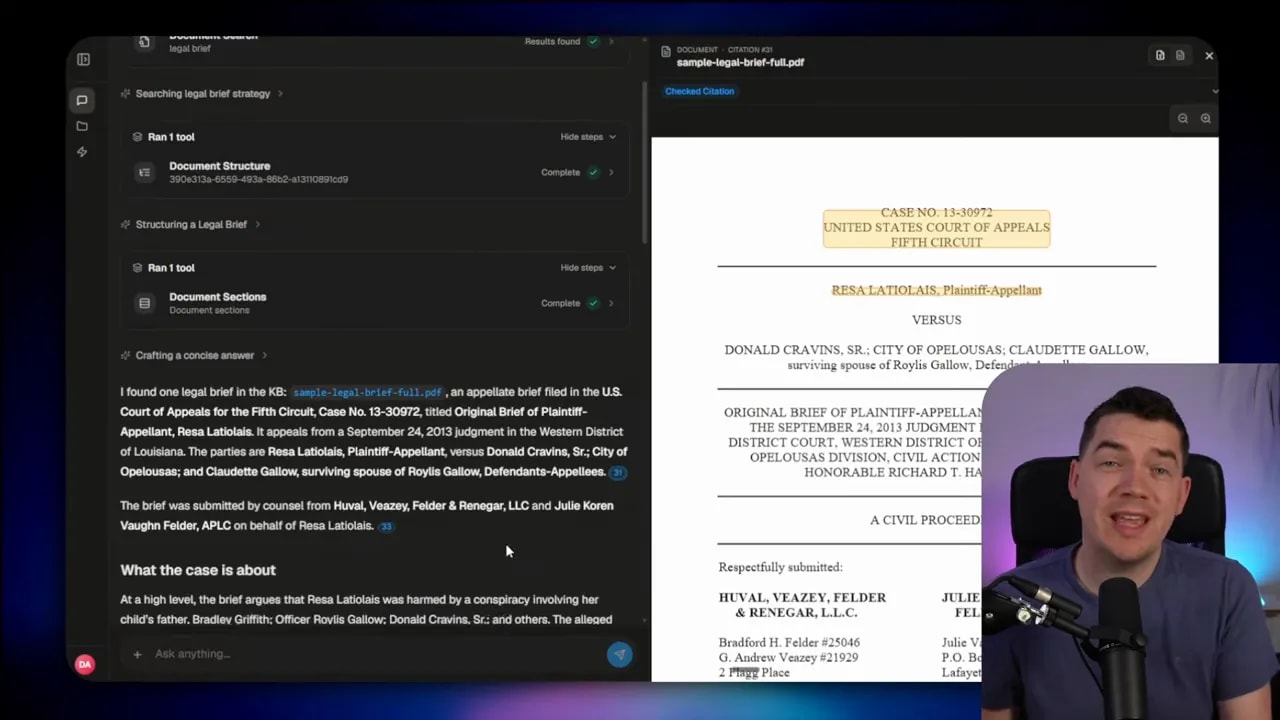
When this is done well, the generating model does not need to figure out page coordinates. That is a bad idea. The model should only insert citation markers like S1, S2, S3 into the response. In the backend, you maintain a mapping from each marker to the relevant source chunk and its document location.
That separation matters. The model is good at placing a citation token near the right sentence. It is far less reliable at inventing exact positions in a document. If you ask it to generate coordinates or precise document locations on its own, you increase the chance of attribution errors.
The ingestion layer should do the heavy lifting. Tools like Docling and Marker can return text blocks with bounding box data. Depending on how precise you need to be, cloud document services from Azure or Google can get even tighter page-level text localization.
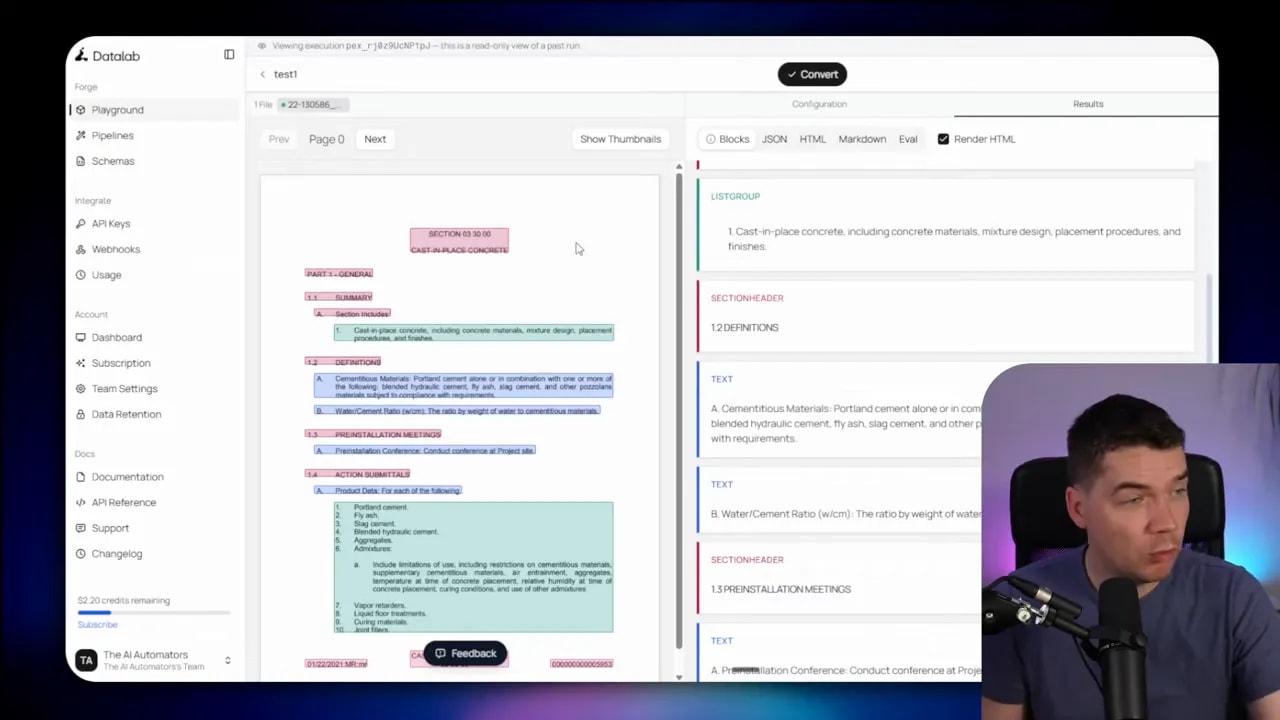
The core idea is simple:
- The search layer retrieves chunks from your knowledge base.
- Each chunk gets an evidence marker.
- The answer generator inserts those markers inline.
- The UI resolves each marker to the original document region.
If your product needs human review, this is one of the highest leverage things you can build. It does not eliminate errors, but it makes errors much easier to spot.
2. Semantic verification: add a grounding checker after generation
The second pattern keeps the inline citations, but adds another model step after generation.
Here, the generator still writes the answer and places the citation markers. Then a separate checker reviews each claim and the evidence it is linked to. Its only job is to decide whether the claim is actually supported by the cited material.
This is a faithfulness checker. It is not writing the answer. It is not doing research. It is acting as a validator.
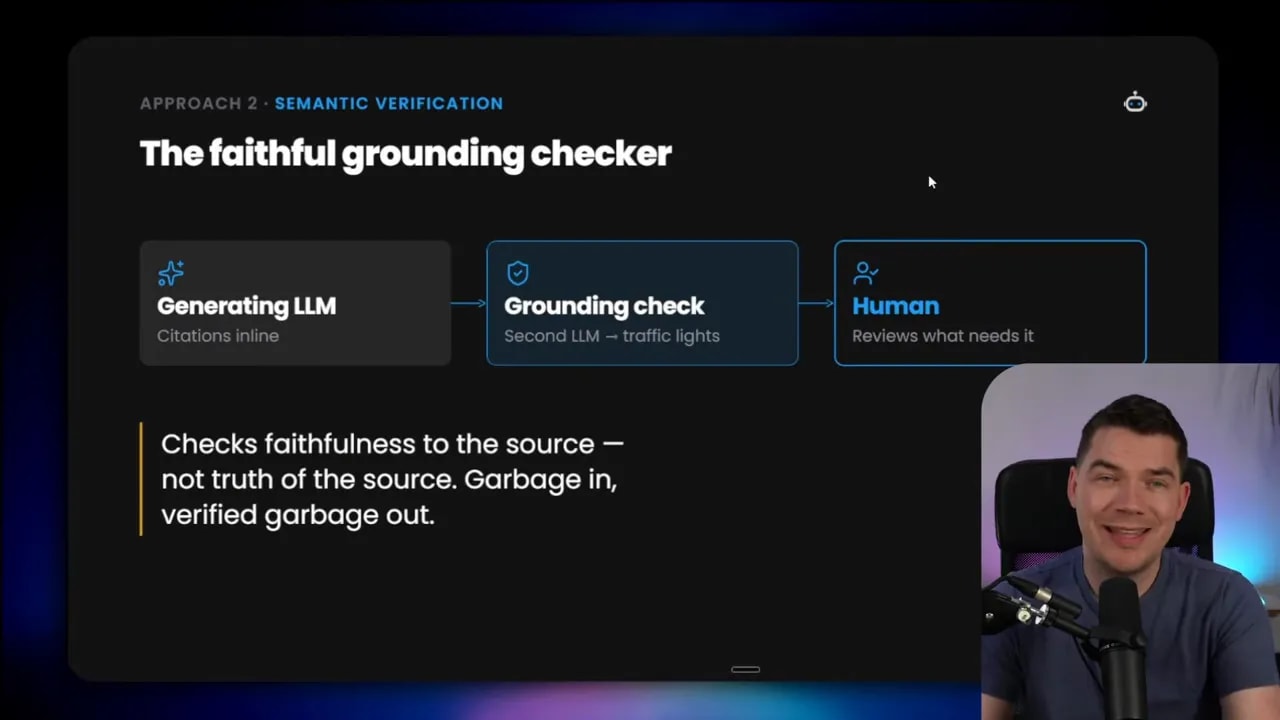
I like this because it adds a second set of eyes without forcing the user to inspect everything manually. In the interface, this can show up as traffic-light style indicators. Neutral while unchecked. Then a pass state for grounded claims. Then warning or failure states for citations that are partial, weak, or unsupported.
That changes the review workflow. Instead of reading every citation equally, the human can focus on the risky areas first.
The prompt for this checker can be very constrained. It receives:
- the generated claim
- the cited source passage
- instructions to decide whether the source verifies, contradicts, or only partially supports the claim
- a confidence score
That can be done with a smaller, cheaper model because the task is narrow. You are not asking it to solve an open research problem. You are asking it to judge support between a claim and evidence.
There is a tradeoff, though. It adds latency and cost. That is why I would not run this on every generation by default unless the use case is high stakes. A better design is often to make it an explicit check or recheck action, or to run it automatically only for certain document types.
You can also use this as part of a repair loop. If the checker flags a claim as partially supported or unsupported, another step can rewrite only that narrow section rather than regenerating the whole document. Then the revised section can be revalidated. That shrinks the surface area of the correction.
Still, this pattern only checks whether the output stays faithful to the source. If the source itself is wrong, the checker will happily approve a wrong answer.
So think of semantic verification as verified grounding, not verified truth.
3. Use a dedicated citation agent
In the first two patterns, the same model that generates the output also inserts the citations. That is often fine. But there is another design that can make sense in more advanced systems.
You split citation work into its own agent.
That means one agent is responsible for producing the report, while another agent processes that report afterward and assigns citations to the claims.
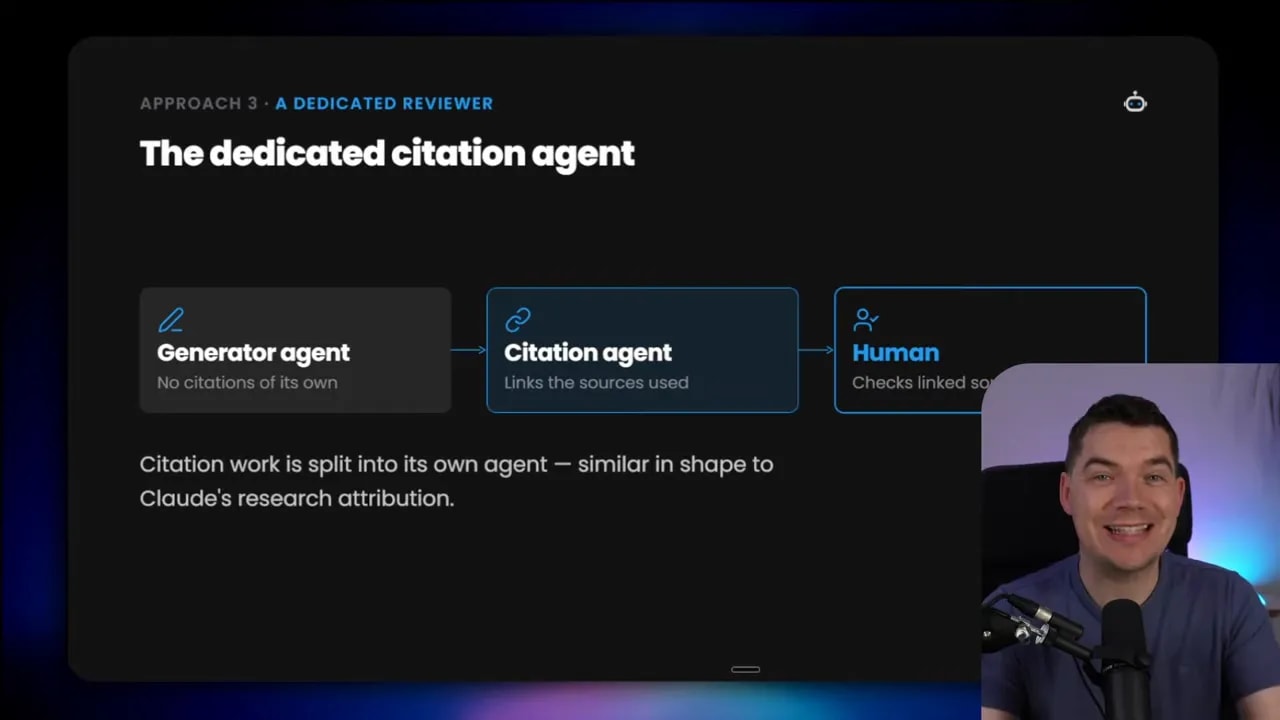
This is the same basic shape used in Anthropic’s multi-agent research setup. A lead agent manages the task. Research sub-agents gather findings in their own contexts. Once the report is ready, a citation-focused agent goes through the finished material and identifies source locations for attribution.
That structure makes sense for long-running research tasks. If a system spends ten, twenty, or thirty minutes collecting and refining information, it is reasonable to give citation assignment its own step and its own rules.
The benefit is specialization. The citation agent does not need to think about style, summary quality, or argument structure. Its scope is narrower. That can improve consistency.
The weakness is precision. If the output cites an entire web page or a long PDF without pointing to the exact supporting lines, verification is still a slog. Landing someone on a 27-page report with a URL is better than nothing, but it is nowhere near as useful as landing on the exact highlighted region that backs a sentence.
That said, there is no reason a dedicated citation agent cannot work with snapshots, crawled page extracts, or page-level snippets. If your system searches the web, you can still store the exact content seen during retrieval and cite that specific captured evidence rather than the live page alone.
If you are building deep research systems, this pattern is worth serious consideration. It is especially useful when the generation process is long and structured enough to justify a separate attribution stage.
If your system is faster and more transactional, the extra agent may be unnecessary.
If you want to explore that architecture more deeply, Anthropic’s write-up on its multi-agent research system is a useful reference.
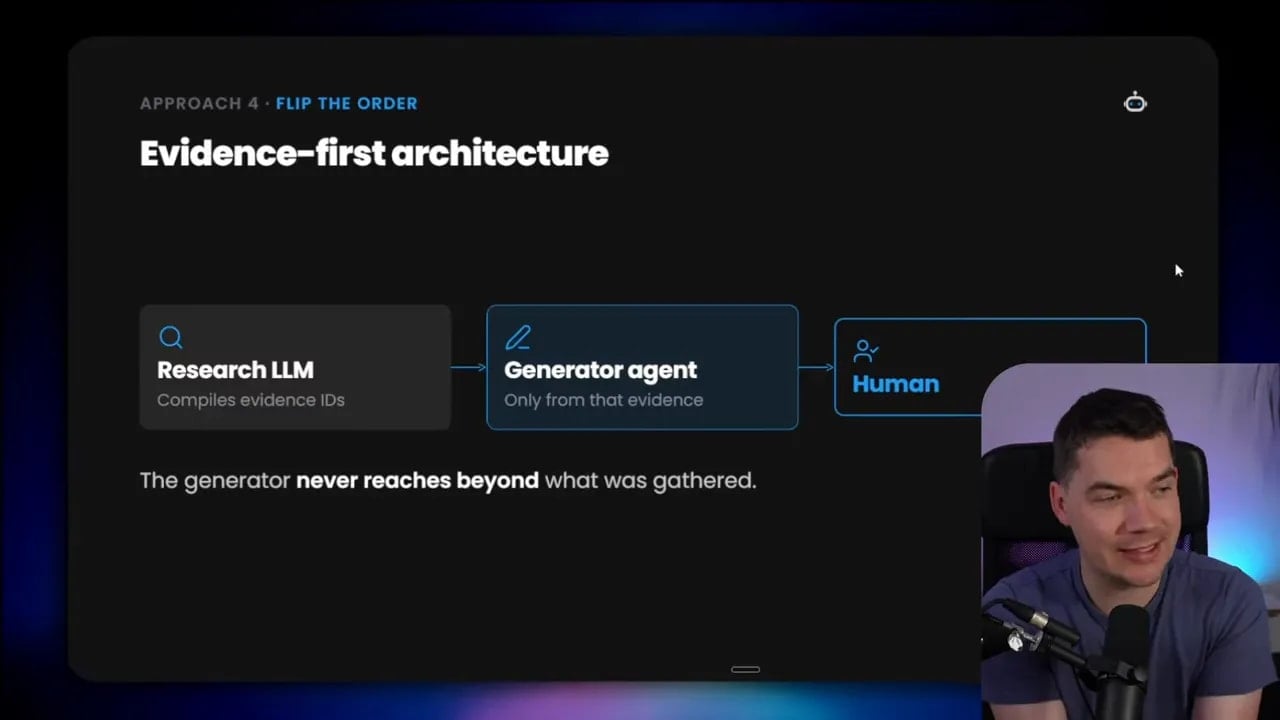
4. Evidence-first architecture
The next two approaches shift from UI and post-processing into system design.
With an evidence-first architecture, the research component does not directly write the final answer. Its job is to gather and organize evidence.
So instead of saying, “Research and then answer,” the flow becomes, “Research, compile the evidence, then generate from that curated evidence.”
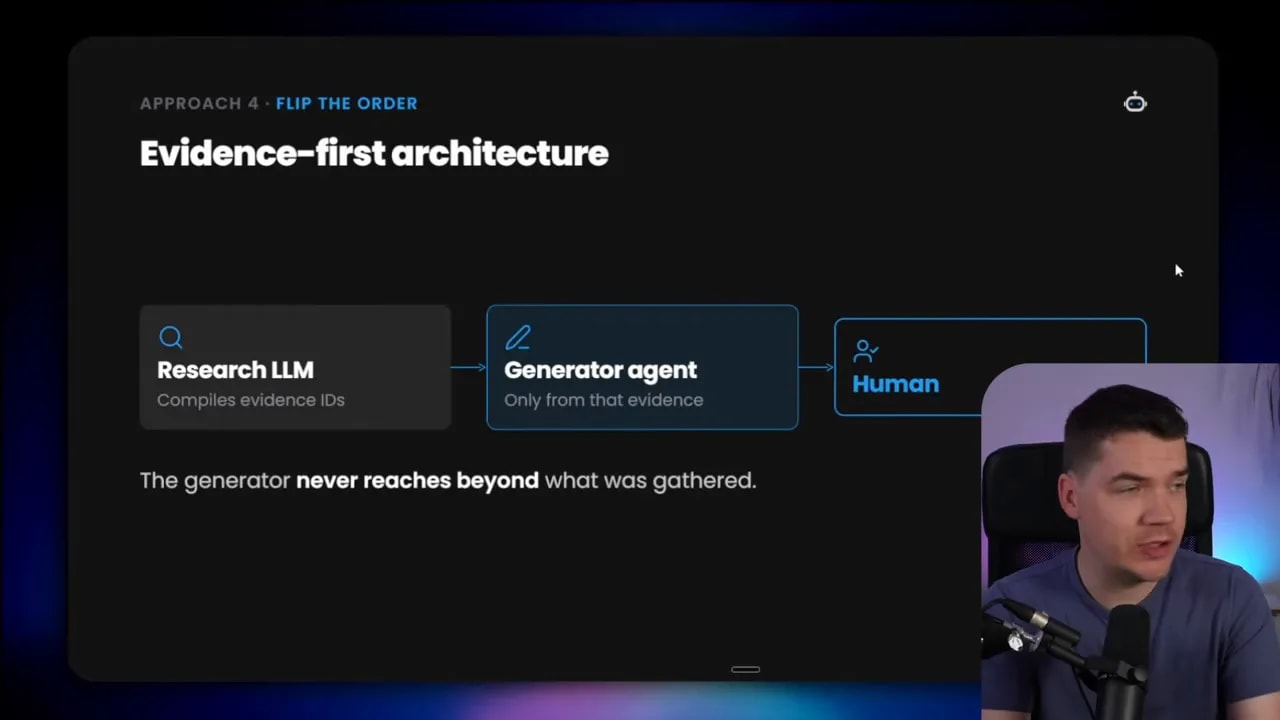
This has a big upside. The generator gets a cleaner context window. It is not dealing with a messy bag of raw retrieval chunks, tool responses, duplicate passages, and half-relevant snippets. It receives a filtered evidence pack.
That reduces the noise the generator has to reason across. And less noise usually means fewer opportunities for conflation and overextension.
I think of this as separating discovery from writing.
- The research model discovers what matters.
- The generator writes from that curated set.
This pattern is useful when retrieval is noisy or when the source material is large and messy. It creates a cleaner handoff between the research stage and the writing stage.
It does, however, rely on the research stage doing a good job of selecting evidence. If it misses important material, the generator cannot recover what it never received.
5. Claim-first architecture
The claim-first version goes one step further.
Instead of passing curated evidence straight into the generator, the research stage first converts its findings into atomic claims. Each claim is linked to supporting evidence. Those claims can then be checked before anything is written as polished prose.
This gives you a more structured pipeline:
- Break down the task.
- Research the relevant material.
- Extract small, discrete claims.
- Attach evidence to each claim.
- Validate those claims.
- Generate the final report from the checked claim set.
The strength here is control. You are no longer validating a long block of prose after the fact. You are validating the building blocks before the prose exists.
That can be powerful in systems that need high traceability. It creates a clearer audit trail for how each part of the output was formed.
The downside is complexity. There are more moving parts. More LLM calls. More handoffs. More places where one step can drift from the previous one.
So while claim-first can increase control, it also increases orchestration overhead. I would reach for it when the domain really benefits from structured validation. I would avoid it for simpler products where the extra machinery is unlikely to pay for itself.
Faithfulness is only half the job
Everything so far has been about grounding the output in retrieved material. That is important, but it is still only half of the problem.
A system can be faithful to a source and still be wrong.
If the document is out of date, if the source is low quality, or if the claim needs to be checked against a formal authority, then you need a different pattern entirely. At that point, the task is no longer “did the model use the retrieved text correctly?” It becomes “does this claim hold up against a trusted source of record?”

That usually means finding claims of a certain type in the document and checking each one against an external authority. Legal citations against case law databases. Financial statements against filings. Regulatory claims against official rules. Academic statements against cited papers or reference databases.
This is where verification moves beyond RAG grounding and into source auditing.
6. Fixed verification harnesses
A fixed harness is a structured workflow for a known claim type.
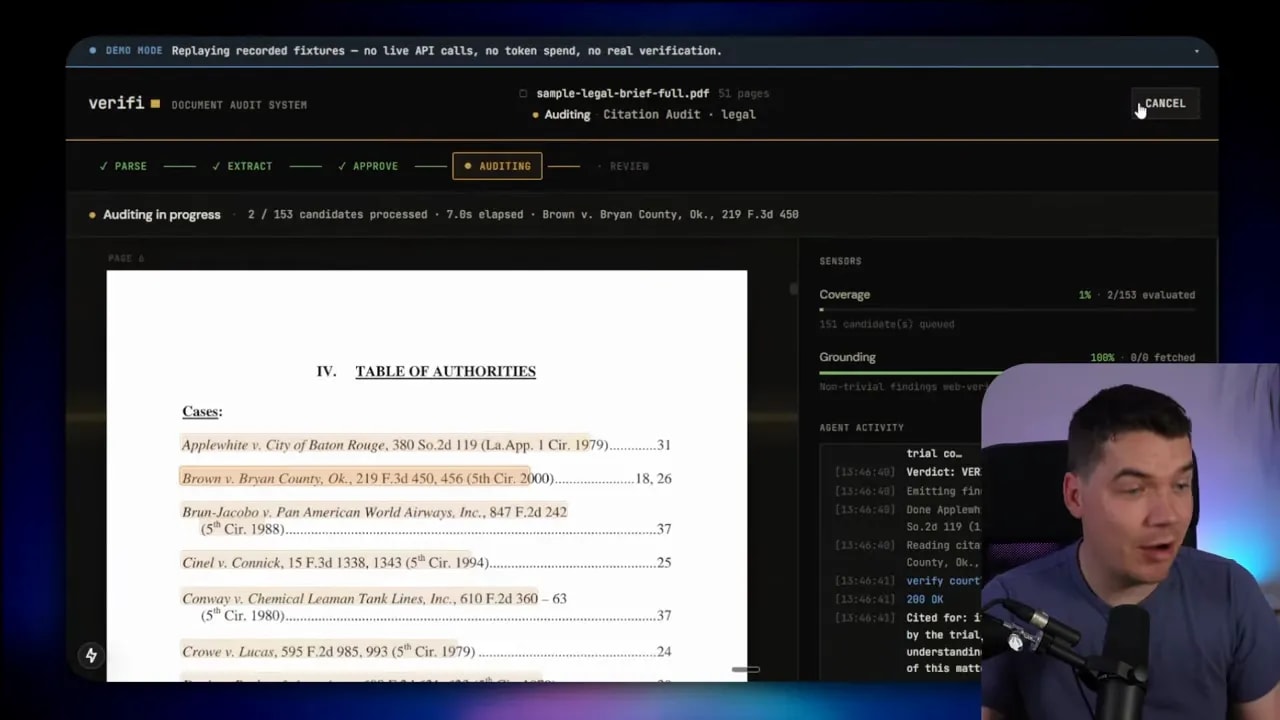
I built one example for legal citation auditing. The process is fixed and transparent. A brief is parsed. Relevant claims are extracted. In that case, the system identifies references to case law and statutes. Then it checks whether those authorities actually exist and whether they support the legal propositions being stated.
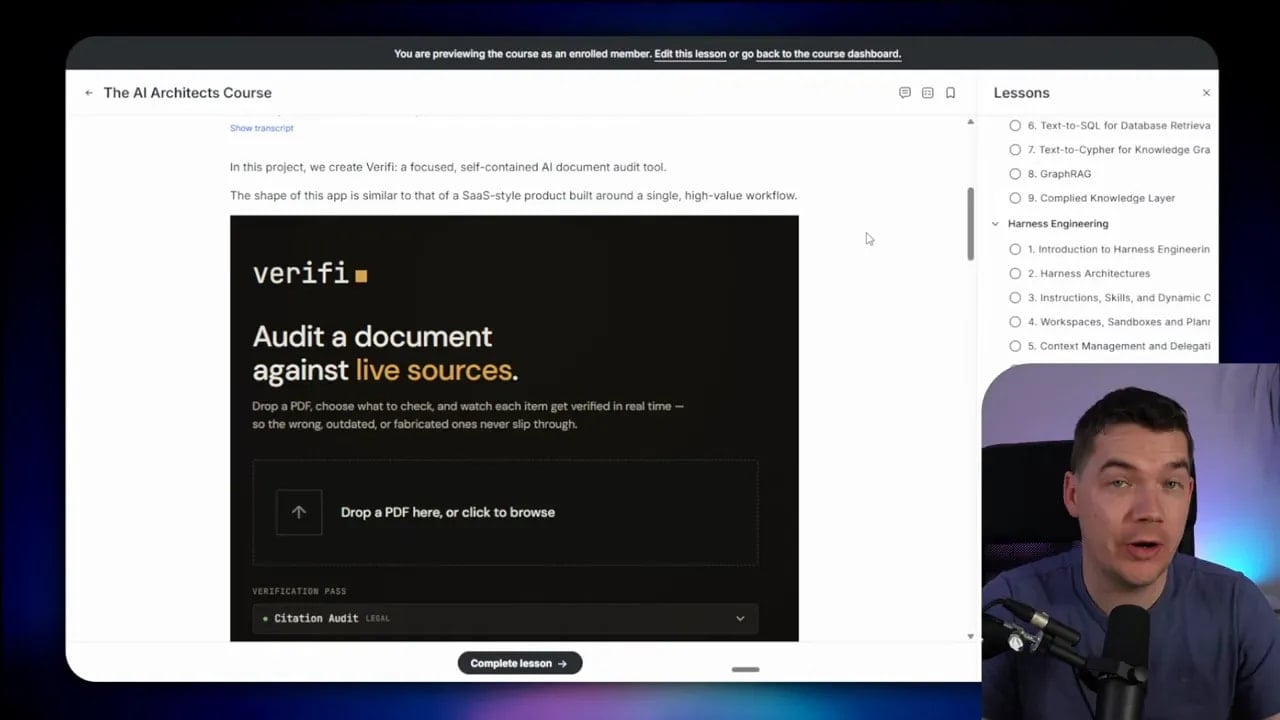
That is very different from a simple grounding check. The system is not asking, “Did the model cite something it retrieved?” It is asking, “Is this authority real, current, and supportive of the argument being made?”
For high-stakes outputs, that distinction matters a lot.
A fixed harness works well when:
- the document type is known in advance
- the claims you care about are predictable
- the authoritative sources are stable
- the review process needs to be transparent and repeatable
This is one reason fixed harnesses are strong from a governance standpoint. You can inspect the workflow. You can explain the stages. You can produce a report that documents what was checked, what failed, and what needs action.
That is far more useful than a one-shot AI answer with a vague sense that it was “probably right.”
For domains like these, fixed harnesses make a lot of sense:
- regulatory filings
- financial disclosures
- academic papers
- contract review
- healthcare documents
In each of those areas, you often know ahead of time what kinds of claims need checking and what source should count as the authority.
If your product sits in one of those domains, a fixed verification harness can become a core part of the system rather than an optional extra.
I shared the product requirements for the citations and source grounding features I built in the platform in the GitHub repo, and that same thinking carries over into verification harness design.
7. Dynamic verification harnesses
Fixed harnesses are great when the task shape is stable. They are less useful when the verification job changes from one request to the next.
That is where a dynamic harness becomes interesting.
Instead of predefining a fixed sequence of stages, the system plans the verification workflow at runtime. It can decide what claims need checking, what tools to use, which specialist agents to call, and whether some checks should run in parallel.
It can even create adversarial paths where one agent tries to refute another agent’s findings.

This is the kind of pattern explored in Anthropic’s dynamic workflow ideas. The important point is not that you must use their exact implementation. The useful part is the design principle:
plan the verification process based on the actual task in front of you.
A dynamic harness is useful when:
- the claim types vary a lot
- the right tools differ by task
- multiple checks can run in parallel
- some claims need more scrutiny than others
- the cost of orchestration is justified by the value of better validation
It is less useful when your verification process is already well understood and repeatable. In those cases, the dynamic version can become harder to govern and harder to test.
So I would think about fixed and dynamic harnesses like this:
- Fixed is better for repeatable, high-trust workflows with known rules.
- Dynamic is better for mixed, ad hoc, or wide-ranging verification tasks.
If you want to study that style of runtime planning, Anthropic’s note on dynamic workflows is a good starting point.
How I decide which verification pattern to use
There is no single best architecture. The right approach depends on the product.
Here is the rough way I think about it.
If the main problem is trust in citations
Start with side-by-side evidence and inline markers. This is the fastest way to make outputs inspectable.
If the main problem is subtle grounding errors
Add a semantic checker that scores whether each claim is supported by its citation.
If the task is long-running and research-heavy
Consider a dedicated citation agent so attribution becomes a specialized stage.
If retrieval is noisy
Use evidence-first design so the writer only sees curated material.
If traceability matters at the claim level
Use claim-first design so each atomic statement can be checked before generation.
If the domain is high stakes and structured
Build a fixed verification harness against authoritative sources.
If verification needs change from task to task
Use a dynamic harness that plans checks at runtime.
Very often, the best answer is a combination.
For example, a solid setup might look like this:
- Use inline citations with original-document highlights.
- Run a semantic grounding check on demand.
- For certain document types, route the output into a fixed verification harness.
That gives you layered trust instead of pretending one mechanism solves everything.
What I would avoid
There are a few traps I would be careful about.
- Do not rely on confidence alone. A confident answer with a citation can still be weakly grounded.
- Do not confuse citation presence with verification. A source link is not the same thing as proof.
- Do not ask the model to invent precise source locations if your ingestion pipeline already knows them. Let the system handle coordinates and mapping.
- Do not treat faithfulness as truth. A verified answer can still be wrong if the source is bad.
- Do not make human review harder than it needs to be. Good UI is part of verification.
This last point gets underestimated. A lot of teams focus on prompt tricks and model choice, but ignore the interface. If a person cannot quickly inspect a claim against the original source, your product is doing too much work in the dark.
The core principle behind all seven approaches
If I had to compress all of this into one principle, it would be this:
Do not leave trust to the model. Build trust into the system.
That can mean better citation UX. It can mean second-pass validation. It can mean splitting roles across agents. It can mean building a formal audit harness for high-stakes work.
But in every case, the goal is the same. Make it easier to verify what the system is saying, where it came from, and whether it holds up.
Models will keep improving. That is great. Still, benchmark gains do not remove the need for verification design. In many products, they make verification even more important, because the mistakes become harder to notice with a quick read.
If you are building AI agents for real business use, the verification layer is not where you cut corners. It is one of the parts that determines whether the product deserves trust at all.
