

Anthropic recently published a deep dive on harness design for long-running AI agents. The topic sounds narrow, but the lessons apply to almost any specialized agent system I build, from contract review to compliance audits, risk analysis, content pipelines, and impact assessments.
The core idea is simple but easy to miss: an AI model alone does not make a reliable agent. The “harness” does. That harness is the orchestration layer around the model. It includes prompts, tools, feedback loops, constraints, validation, and handoffs. Without it, I basically get an engine revving in place.
I first ran into this problem while building a specialized harness inside a custom Python and React app. I can get great output for short tasks. The moment I ask the system to work for hours, the behavior becomes less predictable. That is where Anthropic’s work becomes genuinely useful. It explains what goes wrong and how they evolved their architecture to deal with those failure modes.

Quick definition: An agent harness is the software and structure that wraps an AI model to keep it on track. Think “car” or “horse harness,” not just “engine.”
The real problem: long tasks need reliability, not just intelligence
The industry keeps trying to solve the same fundamental challenge: give an AI agent a complex goal and let it work for hours or even days.
From a developer perspective, the value can look like one-shotting a large feature or an app. In other domains, it might look like an audit or an analysis that would normally take a month of human effort.
Without a harness, an agent tends to fail in predictable ways:
- It tries to one-shot the whole job and loses track mid-way.
- It runs out of context and its behavior changes.
- It leaves work incomplete, sometimes without clear documentation or artifacts.
- It declares success early, just to avoid continuing the work.
In other words, long-running tasks do not fail because the model cannot reason. They fail because the agent needs operational guardrails.
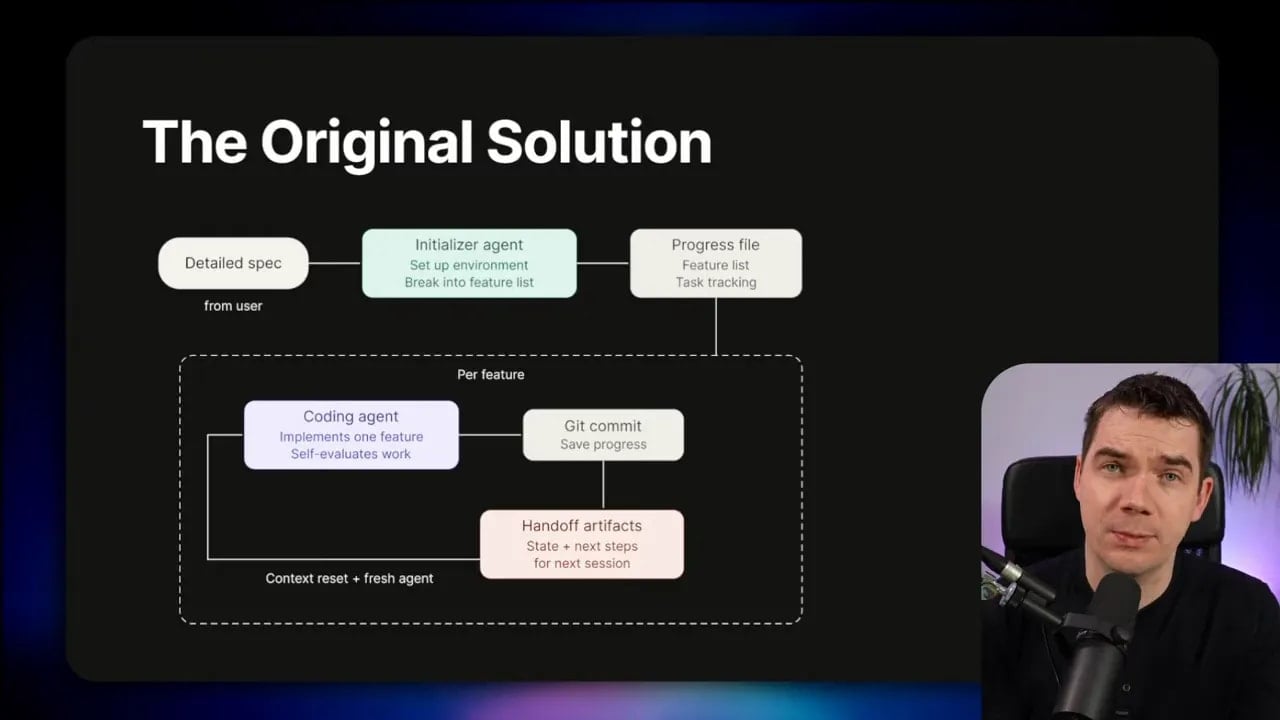
What Anthropic built first: initializer plus progress tracking plus chunked execution
Anthropic’s earlier approach used a two-part setup.
First, they created an initializer agent. That agent sets up the environment and breaks the project into features. Then they created a progress tracking file.
Next, a coding agent worked feature by feature. After each chunk, it committed to Git. It also left clear artifacts so the next coding agent could pick up cleanly.
That structure solves a few problems at once:
- It forces decomposition instead of a single massive attempt.
- It creates incremental progress you can inspect.
- It enables clean handoffs between stages.
The theme here matches what I have seen: reliable agents behave more like workflows than like one heroic brain.
Stop conditions matter: the Ralph Wiggum loop idea
Anthropic’s work builds on other harness patterns too. One that shows up in the ecosystem is the “Ralph Wiggum loop” approach, credited to Jeffrey Huntley.
The pattern runs an agent inside a loop. Then it checks the output against a validator that cannot “lie.” That validator might be a linter, a type checker, or another objective tool.
Once you have explicit stop conditions, you can keep iterating until the system really finishes the job.
This becomes even more powerful when you combine it with spec-driven development. Frameworks like BMAT, spec kit, or open spec help you create structured requirements before development starts. That way, the agent loops against a plan instead of looping in isolation.
Even then, evaluation still gets tricky. Outside of hard external validation, the agent often has to self-evaluate. That is where Anthropic observed serious failure modes.
Two failure modes Anthropic found for long-running tasks
Anthropic identified two common problems that show up across long tasks, whether the task is building an app or running a research or content pipeline.
Failure mode #1: context anxiety
Context anxiety shows up as the context window fills up. The model does not just lose coherence. It changes behavior.
It may start wrapping up prematurely. It may rush steps. It may declare that something is “done” when it is not.
If you have used an LLM for a long conversation in a single context window, you have probably seen this gradual shortening effect. Even if the model still seems helpful, it often gets more “finish-y” over time.
Anthropic noted that a technique called context compaction can help. Compaction summarizes earlier conversation content so you can free up room. But they found that even with compaction, models like Sonnet 4.5 still showed context anxiety.
The bigger reason is that you are not starting with a clean slate. You are continuing from a long-running thread that already contains history, artifacts, and partial decisions.

For that reason, Anthropic used a context reset in their earlier system.
With a context reset, they start the next agent run with a fresh context window. They load the latest state from the progress file. They test features that were built previously, then they work on the next task. When they finish, they trigger a structured handoff and then they start again with clean context.
They also observed a model-dependent difference:
- With Sonnet 4.5, context anxiety appeared enough that they needed context reset.
- With Opus 4.5, the issue appeared much less, so context reset mattered less.
- When they moved to Opus 4.6, they found they did not need context reset at all. Context compaction worked well enough that the model did not try to quit early.
Opus 4.6 also brought a 1 million token context window. Anthropic claims retrieval quality stays strong over that longer context.
I take a slightly cynical view on that part. Longer contexts cost more. I would expect optimization incentives to favor bigger requests. Caching helps, but it still pushes the economics towards high token usage. That does not mean context resets will disappear forever. It does mean that the model’s behavior can improve enough that some harness assumptions become less necessary.
Failure mode #2: poor self-evaluation
Anthropic also called out something that is easy to gloss over: when you ask an agent to evaluate its own work, it tends to praise it.
Even when humans would judge the output as mediocre.
In the build process, Anthropic reported that Claude sometimes produced front-end designs that were bland at best. In response, they penalized generic “AI slop” patterns during iteration.
This becomes a real engineering problem when I try to grade subjective quality. You can verify code with tools like linting, typing, regression tests, and browser tests. You can even iterate on the code itself. But what about:
- Writing style
- Graphic visual design
- Professional tone in legal analysis
- Originality and craft
Subjective evaluation gets hard because humans judge those tasks with nuance. The system needs a way to grade that nuance without letting the evaluator “rubber stamp” whatever the generator produced.
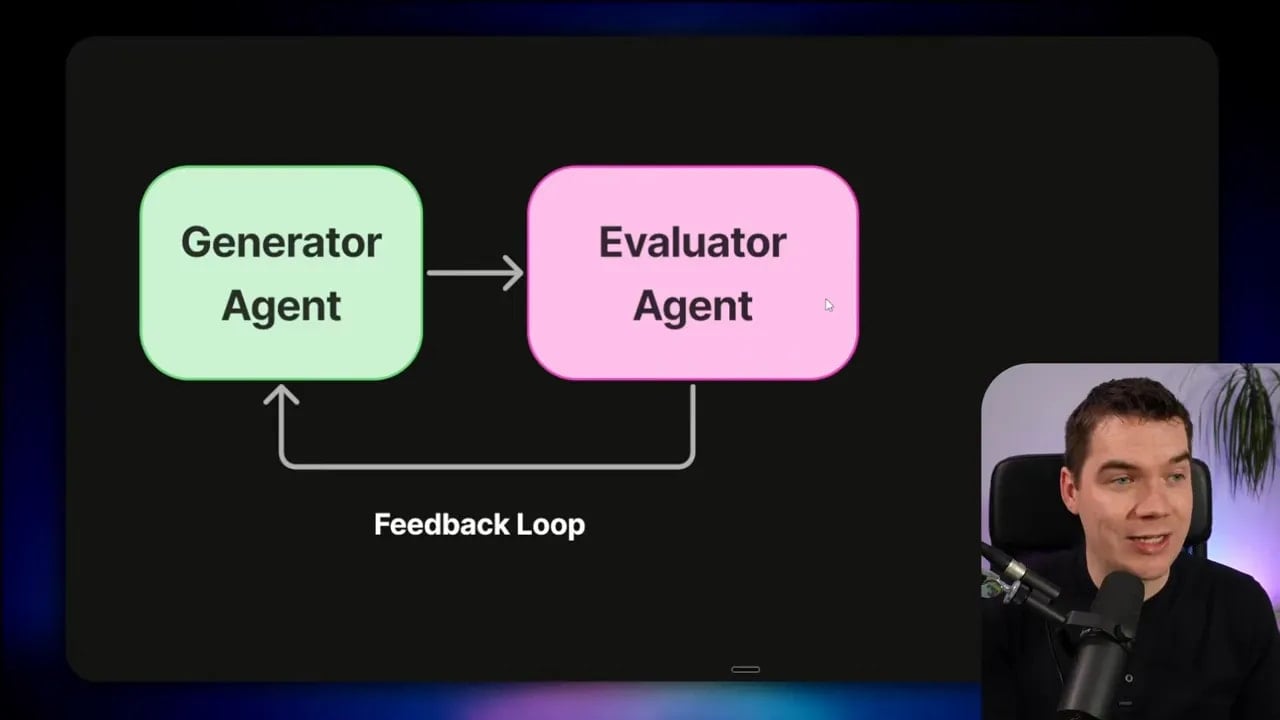
Anthropic’s main solution: adversarial evaluation (GAN-inspired)
Anthropic’s key idea is adversarial evaluation. They borrow inspiration from GANs, where you have a generator and a discriminator.
In this version:
- A generator agent creates code or content.
- An evaluator agent judges what it produced.
- The evaluator’s feedback guides the generator to improve.
The tension between these roles is what matters. A generator agent finds it harder to be skeptical about its own output. An evaluator agent can be forced, through its system prompt and grading rubric, to be skeptical.
Multi-agent systems are not new. A “judge” model is also not new. What felt different in Anthropic’s approach is that they wired the evaluator directly into the production loop, not as an occasional, ad hoc checkpoint.
That said, it was not plug-and-play. Anthropic shared a few sobering lessons from early runs.
What went wrong with the evaluator (and what had to be fixed)
They reported that an evaluator agent can still fail in subtle ways.
In early runs, it might identify legitimate issues, then talk itself into deciding the issues “did not matter” and approve the work anyway.
It also tended to test superficially. That means it might catch obvious problems but miss edge cases. Subtle bugs slipped through, because the evaluation loop did not probe deeply enough.
After iteration, they found three requirements to make an evaluator agent work reliably.
Requirement #1: make subjective quality gradable
Instead of asking “is this beautiful?”, they structured the evaluation around principles.
They defined grading criteria with multiple dimensions. For front-end design, they used:
- Design quality
- Originality to avoid generic AI patterns
- Craft as technical execution
- Functionality
This turned subjective taste into something more operational. It also gave the evaluator a rubric it could apply consistently.
Requirement #2: weight criteria by what the model can actually do
Anthropic also learned that different models handle different evaluation dimensions differently.
They found Opus scored well on two of the four criteria, but struggled on the other two. If they treated all criteria equally, the system drifted back towards shallow approval or generic grading.
Through iteration, they changed weights to emphasize the dimensions the model could judge more accurately, and to reduce “AI slop” approvals.
Requirement #3: let the evaluator interact with the output
The evaluator cannot just read code and assume behavior. It needs to interact with the system like a user.
Anthropic used Playwright MCP so the evaluator agent could:
- Navigate the app
- Screenshot it
- Test behavior
- Check outcomes in practice
This complements deterministic testing rather than replacing it.
I like this distinction because it matches real engineering practice: I can hardcode fast test triggers in my deployment system (like Stripe’s “minions” concept), while an evaluator agent covers areas that automated tests do not fully capture.
Case study experiment #1: 2D retro game and long autonomous coding
To validate the approach, Anthropic ran experiments that included a 2D retro game engine built over a long autonomous session.
The goal included multiple subsystems: a level editor, a sprite editor, entity behaviors, and a playable test mode.
They compared two harness styles:
- Solo harness: cheaper and faster, fewer agents and less structure.
- Full harness: planner + generator + evaluator, plus additional structure for reliability.
The difference mattered. The solo run produced something that looked okay, but it was not playable in any real sense. The full harness produced a functional game.
That result is a useful reminder: when you want a system that works end-to-end, you often need an architecture that prevents “false completion.” The model might generate plausible code, but without a planner, a skeptical evaluator, and clear acceptance criteria, it can still miss core gameplay loops.
Case study experiment #2: adversarial evaluation for front-end design
Anthropic also tested a front-end design workflow by prompting the model to create a website for a Dutch art museum.
They tracked multiple iterations and, after around 10 rounds of feedback, the output became meaningfully creative, not just generic. They highlighted an example where the design ended up as a 3D room with a checkered floor. That was a creative leap from earlier generations.
The harness looked like this:
- A one-sentence prompt set the goal.
- A generator agent produced HTML, CSS, and JavaScript.
- An evaluator agent interacted via Playwright MCP.
- Feedback ran through multiple cycles (roughly 5 to 15) until the design met the rubric.
This experiment is where adversarial evaluation feels most “obviously useful.” When you want originality, you do not want a generator agent that optimizes for easy, safe defaults. You want pressure to produce something that matches principles and avoids predictable AI patterns.
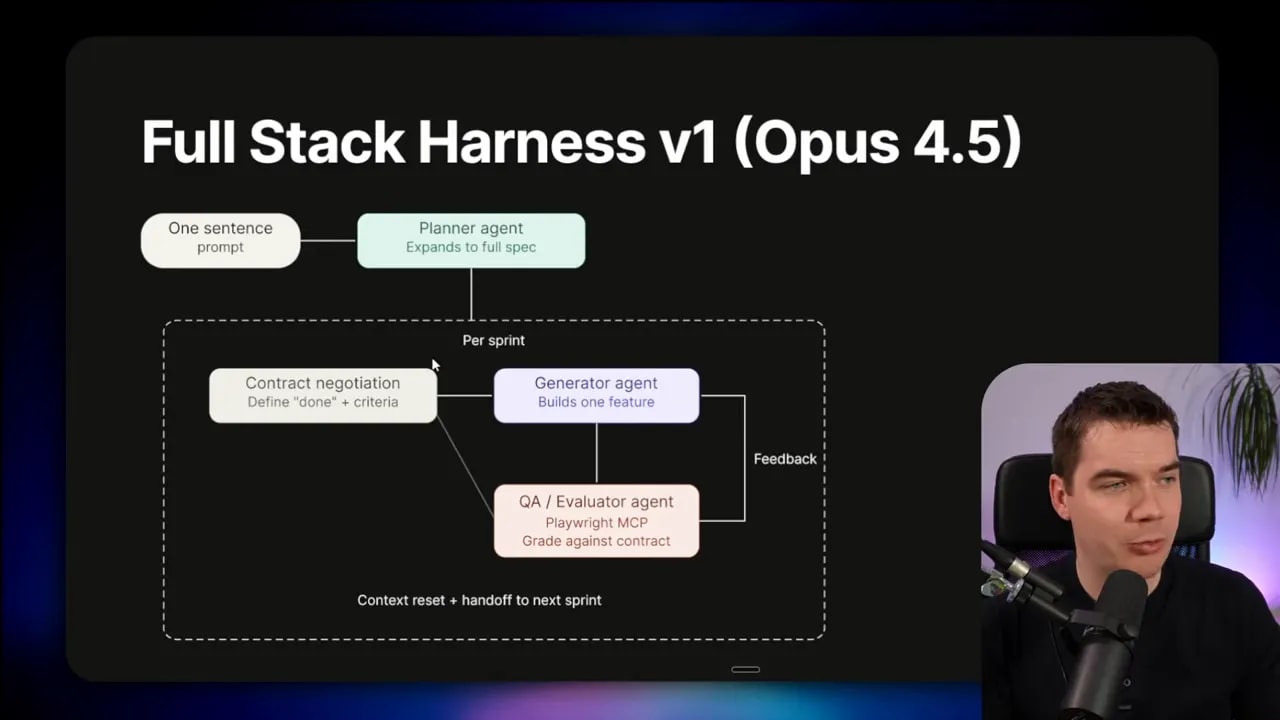
The full harness architecture: planner, generator, evaluator
When they scaled up to full stack coding, Anthropic introduced a planner agent.
In the prompt, the planner goal described the game features. The planner then expanded that single sentence prompt into a more detailed spec. In the more complex version of the harness, they also split work into sprints.
Inside each sprint, there were “contract negotiations” between the generator and evaluator. They defined a “definition of done” upfront before building. That prevented the generator from moving the goalposts while building.
Then the evaluator ran once per sprint, followed by context reset and a handoff to the next sprint.
Why all that structure? Because without a planner, the system can dramatically underscope a project. If all you provide is a single sentence, the spec may remain shallow. Without an evaluator, the generator can over-approve its own work and quit early.
One of the most practical takeaways from Anthropic’s post is the idea of harness evolution.
Every harness component encodes an assumption that the model cannot complete the task by itself. A context reset encodes the assumption that the model will suffer context anxiety. A complex sprinting setup encodes the assumption that the model will underscope or drift without tighter control.
As models improve, those assumptions can go stale. Anthropic demonstrated that by evolving their harness after Opus 4.6 launched.
They simplified the architecture. In the newer version they:
- Removed sprints
- Removed contract negotiation
- Removed context resets
- Relied on context compaction through the Cloud Agent SDK
The new flow became:
- One sentence prompt
- Planner expands into a much larger spec
- Generator uses that spec to build the whole app in one continuous session
- Evaluator runs only at the end of the build and provides feedback for iteration
I interpret this as a subtle message from Anthropic: the model can absorb more orchestration than before. If the model is less prone to premature finishing and retains enough operational context, you can remove scaffolding that used to be mandatory.
Second harness v2 case study: a browser Digital Audio Workstation in about four hours
Anthropic ran a harness v2 to build a fully featured digital audio workstation (DAW) in the browser using the Web Audio API.
Here is the rough breakdown they shared:
- Planner agent: about 5 minutes (and roughly $0.50)
- First full build: about 2 hours (and roughly $71)
- Evaluator/QA agent: about 10 minutes
- Second build: about 1 hour
- Third build: about 10 minutes
Total time: around four hours. Total cost: around $125.

The system relied on Claude Agent SDK, including context compaction built in. They also emphasized that you could build similar mechanics yourself, without using their SDK.
As for the DAW itself: it was not a professional music production program. Still, Anthropic reported that it had key features you would actually need for something like this. And cost-wise, creating it for around $100 is impressive, even if the result still lacks the polish of mature tools.
How to apply these ideas to non-coding agents
Even though the demos were coding-heavy, the failure modes generalize. Context anxiety is really “premature closure.” Poor self-evaluation is really “grading bias.” Adversarial evaluation is really “separate doing from judging.” Those ideas transfer cleanly.
For compliance audits and risk analysis
These tasks often require long horizon work and documentation. If I ask an agent to “complete the audit,” it may stop early or produce shallow reasoning.
A harness helps by forcing:
- Decomposition into sections, evidence types, or control categories
- Progress tracking so the agent cannot forget what it did
- Evaluator skepticism that checks whether evidence actually supports conclusions
Instead of “context reset,” I might use staged checkpoints (new evaluation run per section) so the model does not carry a long memory thread full of earlier partial outputs.
For content pipelines
Content work has heavy subjective components like tone, structure, originality, and “brand fit.” That maps directly to Anthropic’s subjective quality rubric idea.
I can create a grader that checks principles instead of taste:
- Clarity and structure
- Originality signals (avoiding repeated templates)
- Accuracy checks with citations where appropriate
- Compliance checks against a style guide
Then I can let the evaluator interact with the artifact like a user would. For a content system, “interaction” might mean rendering markdown to HTML, running formatting checks, or previewing the page layout.
For impact assessments and reporting
These tasks often blend narrative with factual claims. Self-evaluation bias can lead to confident but weak outputs.
A harness can reduce that bias by:
- Making the evaluator check claim-evidence alignment
- Forcing edge-case coverage (limitations, assumptions, missing data)
- Running targeted tests or validators where possible
Even if the evaluator cannot be fully deterministic, it can still be adversarial in its reasoning through rubric-driven critique.
What “harness engineering” really means in practice
There is a temptation to think harness design is a one-time setup: pick the best model, add a loop, and you are done. Anthropic’s experience suggests the opposite.
Harness design needs iteration. You refine the architecture based on observed failure modes. You adjust grading rubrics. You change evaluator weights. You decide when you need context resets and when you can rely on compaction.
In other words, harness evolution is not “extra engineering for its own sake.” It is how I keep an agent system reliable as both models and tasks change.

Every harness component encodes assumptions. When those assumptions stop being true, the right move is simplification, not stubborn complexity.
A practical mental model: build a workflow, not a conversation
Anthropic’s approach also aligns with how I design agent systems that need to run over long horizons.
I treat the agent as a production workflow:
- Planner translates a goal into a structured plan
- Generator executes work in chunks or in a continuous build
- Evaluator checks outcomes with rubric-driven skepticism
- Validators add deterministic guarantees where possible
- Handoffs and context management prevent premature closure
Once I see the agent this way, harness design stops feeling like prompt engineering trivia. It becomes system engineering.
Why evaluator interaction matters (and why “read-only judging” is weak)
One subtle point in Anthropic’s approach is the requirement that the evaluator interact with the output.
It is not enough to judge code or content from text. Interacting with the artifact exposes behavior mismatches. It reveals edge cases. It shows whether the “promise” of the output matches how the system actually runs.
That is why Playwright MCP shows up as a key piece. For a browser app, it can click through flows, capture screenshots, and trigger behaviors the generator might forget.
In my own systems, I translate that principle into whatever “interaction” looks like:
- Render and validate UI output
- Run functional checks on produced artifacts
- Verify that output matches expected navigation or triggers
- Test content formatting and policy constraints
The evaluator becomes more than a critic. It becomes a simulated user.
Model capability affects harness design (so I plan for change)
Anthropic observed that evaluator quality depends on how capable the underlying model is. A model might be strong at some grading dimensions and weak at others. That means harnesses should adapt to model updates.
When I build agent systems, I do not treat harness configuration as a permanent fixture. I treat it as a living component. If I upgrade the model and the system stops showing context anxiety, I remove the expensive scaffolding that no longer pays for itself.
This lines up with the “harness evolution” message. It is also a practical cost strategy. Long-running tasks get expensive quickly, so I try to remove what I no longer need.
Key blueprint takeaways I carry forward
If I had to distill Anthropic’s blueprint into the engineering principles I actually use, they would look like this:
- Design the harness as carefully as the model. Reliability comes from orchestration.
- Plan for context anxiety. Use compaction and reset patterns when needed.
- Do not trust self-evaluation. Self-grading often becomes self-praise.
- Separate doing from judging. Use an evaluator agent with adversarial skepticism.
- Make subjective quality gradable. Grade principles, not taste.
- Weight criteria by what the model can actually measure.
- Let the evaluator interact with the output. Read-only evaluation misses edge cases.
- Expect harness evolution. Remove scaffolding as models improve.
Long-running agents work when I treat the agent system like a disciplined process. Anthropic’s work gives a concrete path for doing that, with examples that make the ideas tangible: a retro game engine built over a long autonomous session, and a browser DAW built in around four hours using Opus 4.6 with context compaction.
The lesson is not that LLMs suddenly became “safe” on their own. The lesson is that harness design turns raw capability into dependable execution.
