

I created an automation that builds a multimodal Retrieval-Augmented Generation (RAG) agent capable of indexing and analyzing complex PDFs containing text, images, and tables at scale. This agent goes beyond simply extracting text—it understands images using an AI vision model and responds to queries with images and tables embedded directly in its answers. This approach makes AI agents far more effective when working with rich, information-dense documents like product manuals.
In this article, I’ll walk you through the entire process of constructing this agent. I’ll explain how I use a powerful OCR API to extract and annotate data from PDFs, how to store and vectorize that data with Supabase, and finally, how to build an n8n agent that chats with this indexed data. By the end, you’ll see how to combine text, images, and tables into a seamless question-answering system.
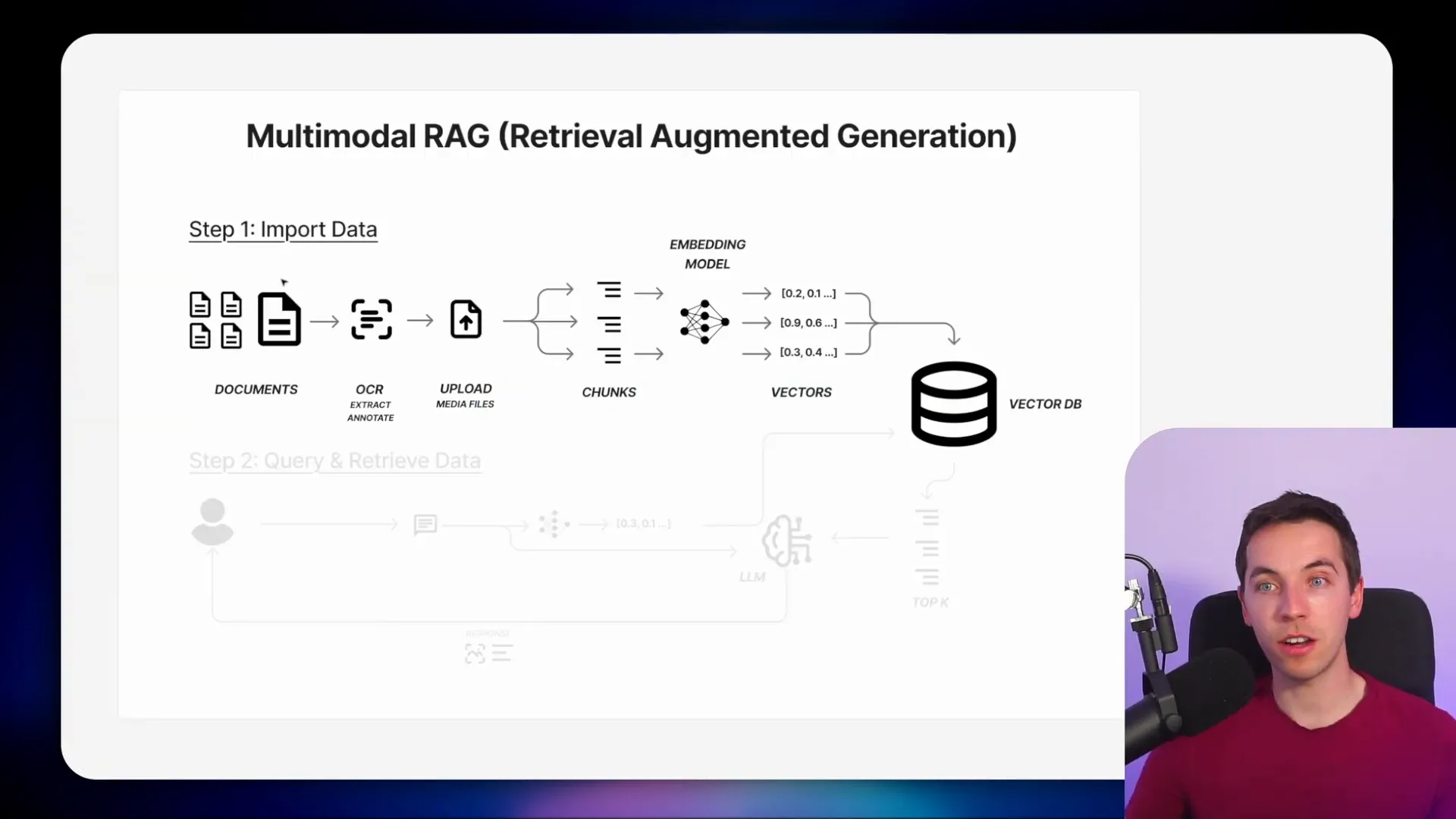
The Multimodal RAG Process
The starting point is a collection of documents—specifically, information-rich PDFs like product manuals. Instead of just extracting the text from these PDFs, I use a powerful OCR API that extracts text and annotates the media embedded within the documents. This process works for both machine-readable PDFs and scanned images.
For this, I chose Mistral’s OCR API. It accepts PDFs and returns data in a markdown format that’s friendly for large language models (LLMs). The markdown includes inline file names referencing images and tables. Alongside the markdown, the API also returns an array of elements such as images and charts.
What makes this approach truly multimodal is that Mistral doesn’t just extract images—it uses a vision model to analyze and understand the content of each image. I can specify how detailed I want these annotations to be by passing in a prompt. This gives me deep context about the images, along with the actual image files encoded in base64 format.
Next, I upload these images to Supabase storage. Then, I combine the markdown text and the image data and pass everything to a vector database. Before storing, I chunk the data into manageable pieces and convert those chunks into vectors using an embedding model. These vectors are what the vector database stores for efficient retrieval.
When querying, a user’s question is converted into a vector and used to search the vector database. The database returns the top relevant chunks, which are then fed into a large language model, like GPT-4.1. The model crafts a response based on the retrieved data.
A key feature here is that the vector database response includes URLs for images. I prompt the language model to include these images inline when answering queries, making the responses richer and easier to understand.
Building a Simple Workflow Using Mistral OCR
To keep the process straightforward, I started by retrieving a single publicly accessible PDF using an HTTP request node in n8n. This node uses the GET method and fetches the PDF in binary format, which is suitable for testing the workflow.
If you want a more elaborate ingestion pipeline, I recommend exploring my RAG masterclass, which covers that in detail.
Next, I signed up for a Mistral account. Their OCR API pricing is quite reasonable—$1 per 1,000 pages for the document AI and OCR, and $3 per 1,000 pages for annotations. The API is both fast and high quality, returning a comprehensive dataset from a single PDF upload.
After creating an account, I generated an API key from the billing screen. This key is essential for authenticating requests to the Mistral API.
Uploading the PDF to Mistral involves an HTTP POST request with the PDF binary data. Mistral’s API documentation provides a cURL command for this, which I imported directly into n8n’s HTTP request node to save time. I replaced the hardcoded authorization header with a predefined credential in n8n to keep the API key secure.
Once uploaded, Mistral returns an ID for the document, which I then use to retrieve a signed URL. This signed URL is necessary to fetch the OCR results later.
To get the signed URL, I copied another cURL command from the Mistral docs and imported it into a new HTTP request node. I linked the document ID from the upload step to this request using expressions in n8n.
After getting the signed URL, I requested the OCR results using yet another HTTP request. Initially, the API returned a binary response because the output format was set to file. I changed this to JSON to make it easier to work with the data inside n8n.
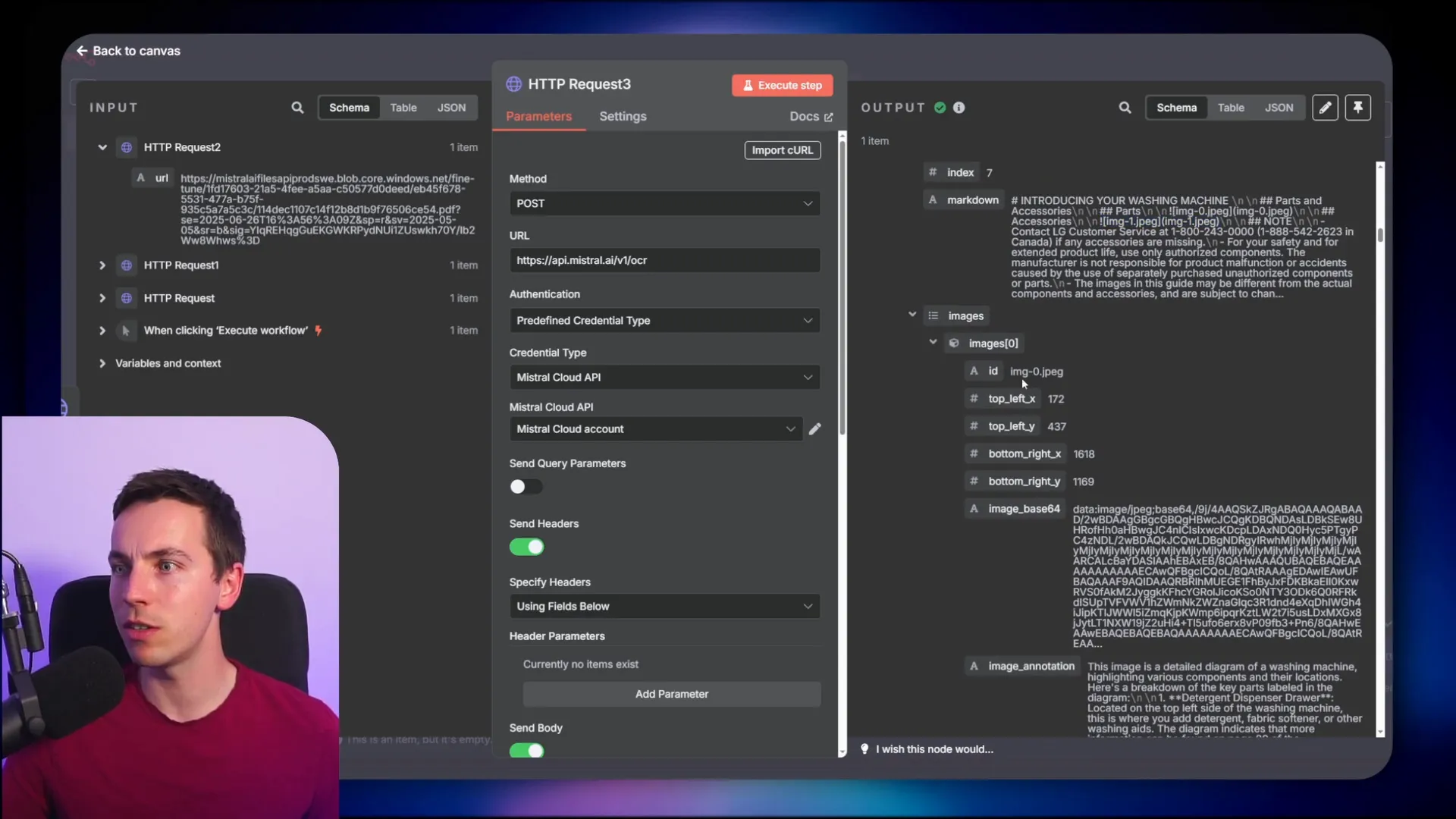
The OCR processing took about 20 seconds for a fairly large document. The results contained an array of pages, each with markdown text and an array of images encoded in base64. This gave me both the textual content and the images extracted from the PDF.
Adding Image Annotations with Mistral Vision Model
At this point, the images were extracted but lacked detailed annotations. To get Mistral’s vision model to analyze the images, I updated the OCR request to include an image annotation parameter.
Mistral provides a schema for how to specify the annotation request. It can get quite detailed, but I found it easiest to use a simple prompt that requests concise natural language descriptions of each image.
For example, if you pass in an image of a washing machine component, the model might return a description like “a diagram showing the water inlet valve and hoses.” This deepens the context available to the AI agent.
After updating the request body to include this annotation schema, I re-ran the OCR process. This time, the response included both the base64 image data and the corresponding annotations for each image.
Preparing Data for Vectorization and Storage
Before uploading to the vector store, I examined how the data was structured. Each page object contained markdown text with image file names and an array of image data with annotations.
Ideally, the image annotations should be embedded directly within the markdown text to provide better context when querying. To do this, I split the array of pages into individual items using n8n’s split node. This allowed me to process each page separately.
I then used a code node to run JavaScript that inserted the image annotations inline within the markdown. The images are referenced in markdown by their file names, so the script replaced those references with the annotation text right next to the image reference.
Initially, the code was set to run once for all pages, causing duplication. I adjusted it to run once per item, which fixed the issue and produced clean markdown with embedded annotations.
With the enriched markdown ready, I chunked the data into smaller pieces using a recursive text splitter. This chunking helps the embedding model process the data efficiently and improves search results in the vector database.
Using Supabase as a Vector Store
I chose Supabase for storing vectors and images because it offers a managed SQL database with vector capabilities and integrated storage. If you don’t have a Supabase account, setting one up is straightforward and free for development purposes.
Within Supabase, I created a documents table using their LangChain quick start SQL script. This table is where the chunks of text and their vector embeddings are stored.
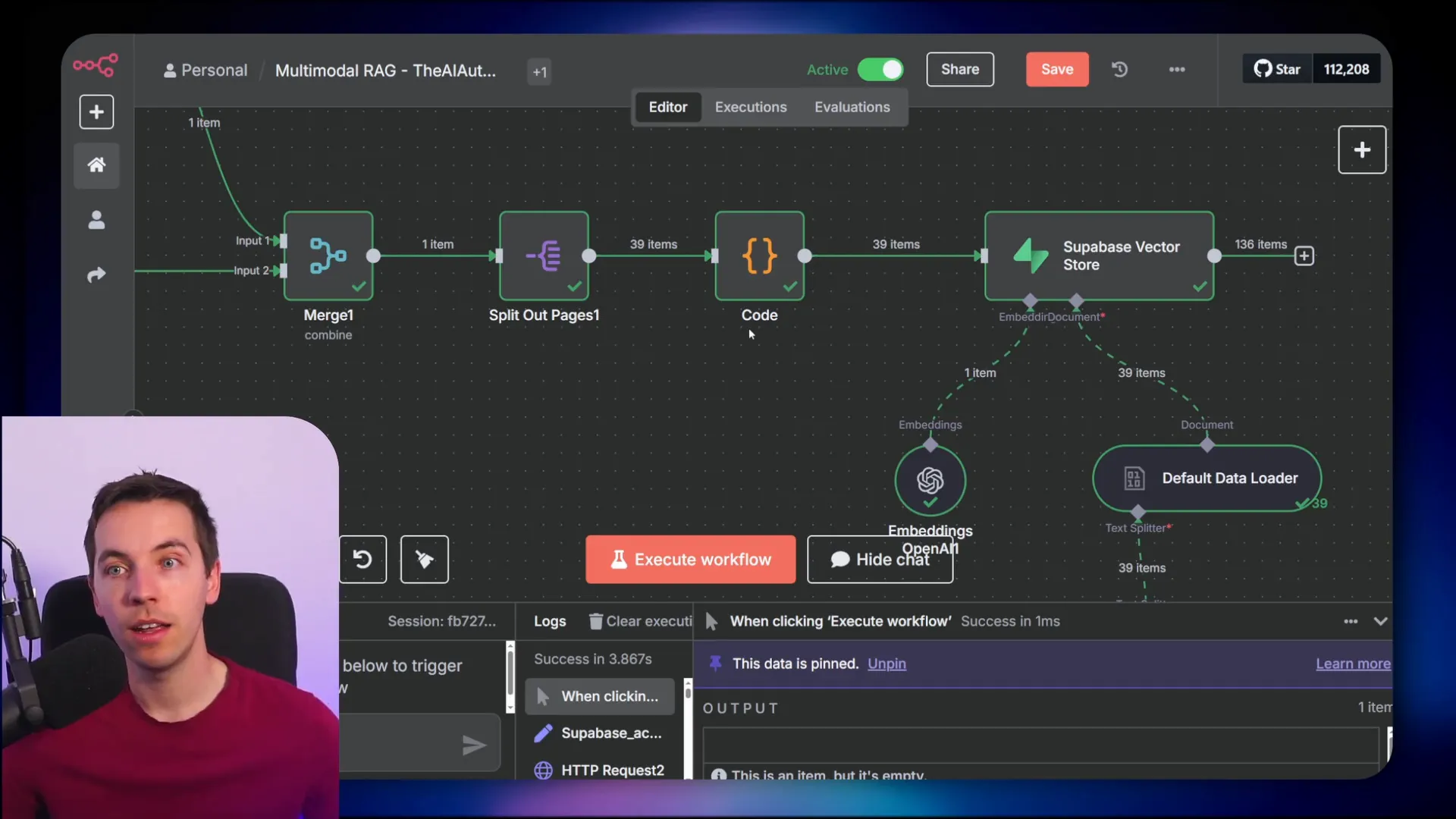
Back in n8n, I added a Supabase vector store node and connected it to my Supabase account. I configured the node to insert documents into the documents table and set the embeddings batch size to the default.
The data loader was set to load the enriched markdown text I prepared earlier. After chunking with the text splitter, I used OpenAI’s text embedding-3-small model to generate vector embeddings for each chunk.
Once executed, the workflow uploaded hundreds of vectors representing the document content into Supabase. This indexed data is now ready to be queried by an AI agent.
Building the Chat Agent to Interact with Your Data
Next, I built an AI chat agent to interact with the indexed document data. I added a chat message trigger node in n8n and linked it to an AI agent node configured with GPT-4.1. I selected a base model rather than a fine-tuned one and lowered the sampling temperature to reduce randomness and improve response consistency.
At first, the agent responded to greetings but had no memory or connection to the vector store. To fix this, I added simple in-memory memory to the workflow and connected the Supabase vector store as a retrieval tool.
I set the operation mode to “retrieve documents” and selected the documents table. I limited the number of documents retrieved per query to four for performance reasons but this can be adjusted as needed.
The embedding model for retrieval was set to OpenAI’s text embedding-3-small, matching the model used during indexing. Consistency here is crucial for accurate vector similarity search.
To guide the agent’s behavior, I supplied a system prompt:
You are a washing machine expert. You are tasked with answering a question using the information retrieved from the attached vector store. Your goal is to provide an accurate answer based on this information only. If you cannot answer the question using the provided information or if no information is returned from the vector store, say sorry, I don’t know.
This prompt encourages the model to admit when it lacks sufficient information rather than hallucinating answers.
After activating the workflow, I tested it by asking questions like “What is the warranty for this product?” The agent responded with accurate answers supported by the markdown data retrieved from Supabase.
Uploading Images to Supabase Storage
Up to this point, the images were embedded in base64 format but not yet uploaded to storage. To make images accessible in responses, I created a more advanced workflow to upload extracted images to Supabase storage.
First, I added fields to store my Supabase base URL and the name of the storage bucket. The bucket was created as public to allow easy access via URLs, but you can choose private if you prefer more control, keeping in mind the added complexity of signed URLs.
The workflow then splits the OCR result pages and further splits images within each page. This allows processing and uploading each image individually.
I generated pseudo-random file names for each image to avoid conflicts and tracked the original image IDs and annotations for later use.
The base64 encoded images include a MIME type prefix (like data:image/jpeg;base64,). I stripped this prefix to isolate the actual base64 string before converting it to a binary file using n8n’s convert to file node.
Uploading to Supabase is done with an HTTP POST request to the Supabase storage API. The request uses the binary file as the body and authenticates with a Supabase API key stored as a predefined credential in n8n.
Once uploaded, Supabase returns metadata including the file name and storage bucket. I cleaned the file name to remove the bucket prefix for easier handling.
To keep the workflow organized, I merged the uploaded image metadata back with the original image annotations and IDs using n8n’s combine and aggregation nodes. This gave me a complete dataset of uploaded images with annotations ready to be referenced in the markdown.
Integrating Uploaded Images into Markdown
With images uploaded and URLs ready, I updated the markdown to replace the original base64 file names with the full Supabase URL for each image. This ensures that when the agent responds, it can render images directly from the storage.
I used a JavaScript code node to iterate through each image and check if its file name appears in the markdown text. If it does, I replaced the file name with the full URL wrapped in markdown image syntax. I also inserted the image annotation as a caption right below the image.
This enriched markdown, containing both image URLs and annotations inline, was then chunked and embedded as before, ready for storage in the vector database.
Querying the Agent with Rich, Multimodal Data
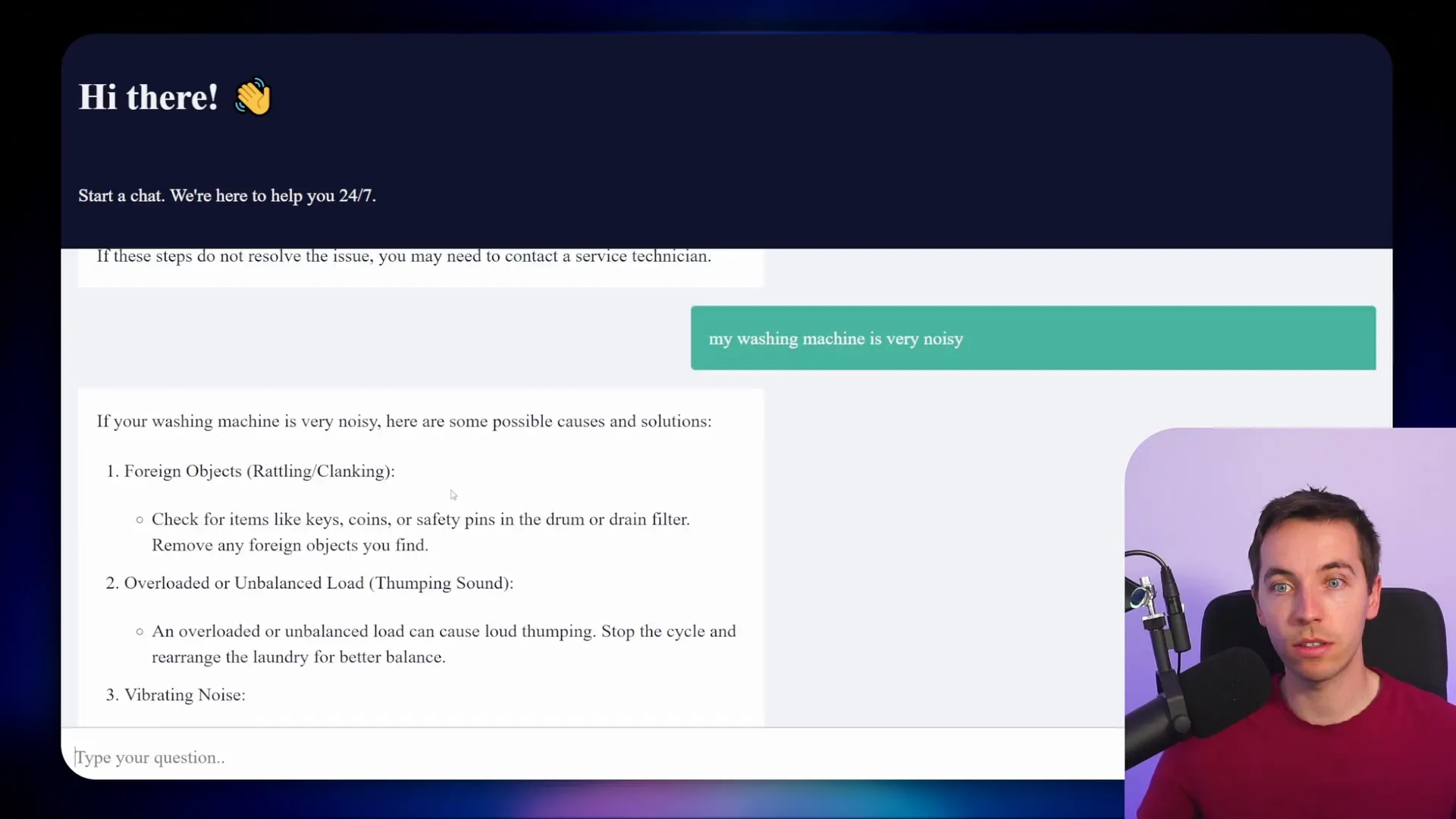
Finally, I used the same AI agent setup to query the newly indexed data with embedded image URLs. Asking questions like “Where do I put the fabric softener?” returned detailed answers with relevant images from the document shown inline.
Another question about a noisy washing machine triggered responses that included multiple suggestions and images illustrating how to level the machine and adjust the feet using non-skid pads. The images provide visual context that enhances understanding and usability.
This multimodal RAG agent system can be expanded and refined as needed. You can build more complex ingestion pipelines, add hybrid search techniques to improve accuracy, or implement re-ranking to reduce noise in results.
The approach I described combines the strengths of OCR, vision AI, vector search, and large language models to create an interactive, intelligent agent capable of handling complex documents with mixed media. This opens up many possibilities for building smarter AI assistants that understand and leverage rich document content.
