

I created an AI agent that can query databases effectively using natural language. This agent can handle everything from simple single-table queries to complex database schemas with multiple relationships. In this article, I’ll walk you through the entire process, demonstrating how to build such an agent using a Postgres database hosted on Supabase. While I use Postgres here, the concepts apply equally well to other relational databases like SQL Server or MySQL.
One of the most important aspects I cover is how to secure your AI agent against SQL injection attacks, a critical concern when allowing automated systems to generate and execute SQL queries dynamically. I’ll show you multiple approaches to building these agents, explain how to give the AI context about your database schema, and share tips on improving performance and reliability.
Demo: Seeing the AI Agent in Action
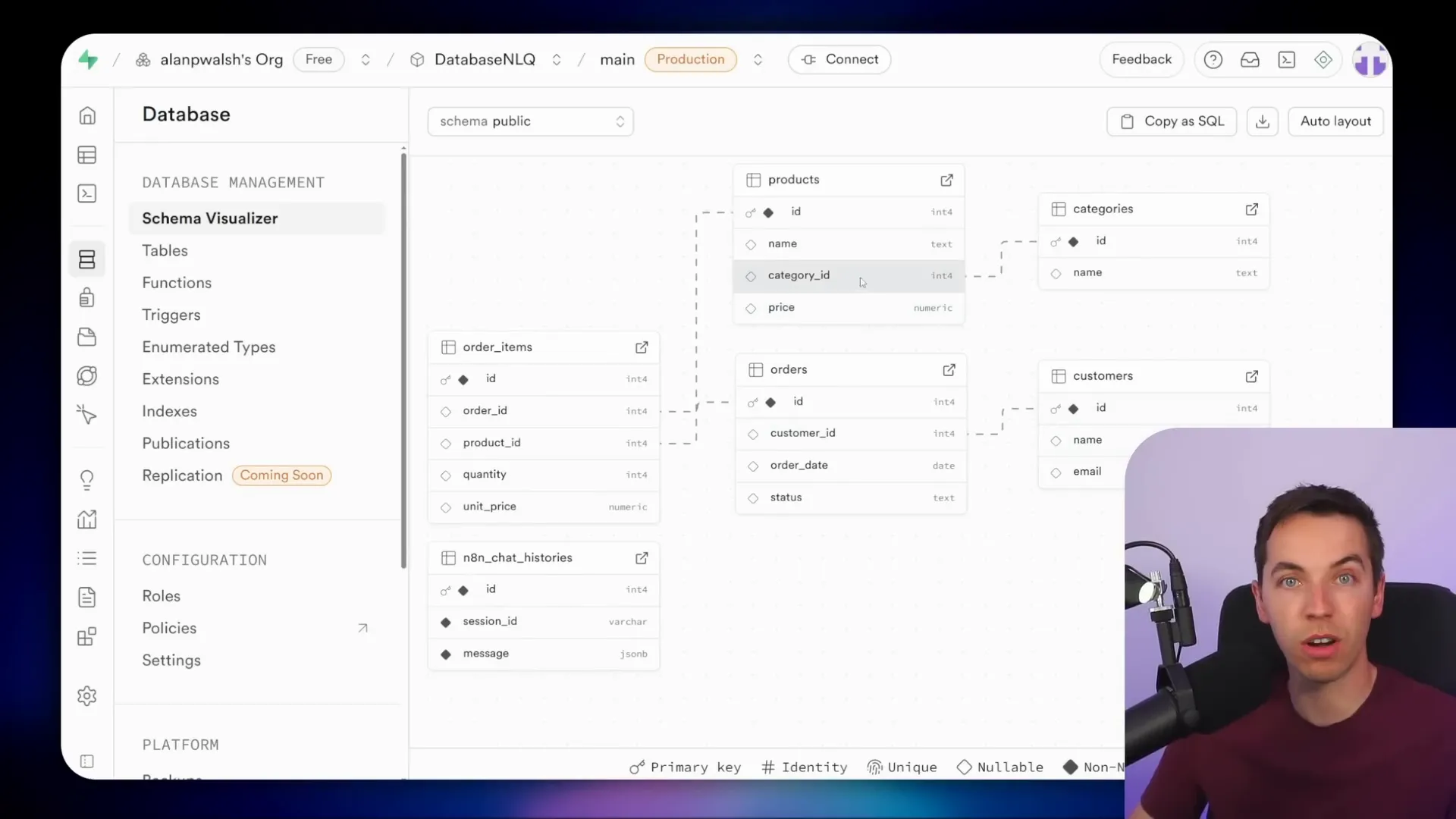
Let me start by showing you a quick demo to illustrate what this agent can do. The database I use is simple enough to explain the concepts but still contains multiple tables like customers, orders, and products. The schema is somewhat normalized, meaning the tables are related by IDs to reduce data duplication.
Here’s the bird’s eye view of the schema. You can open the table editor in Supabase to view the data inside each table.
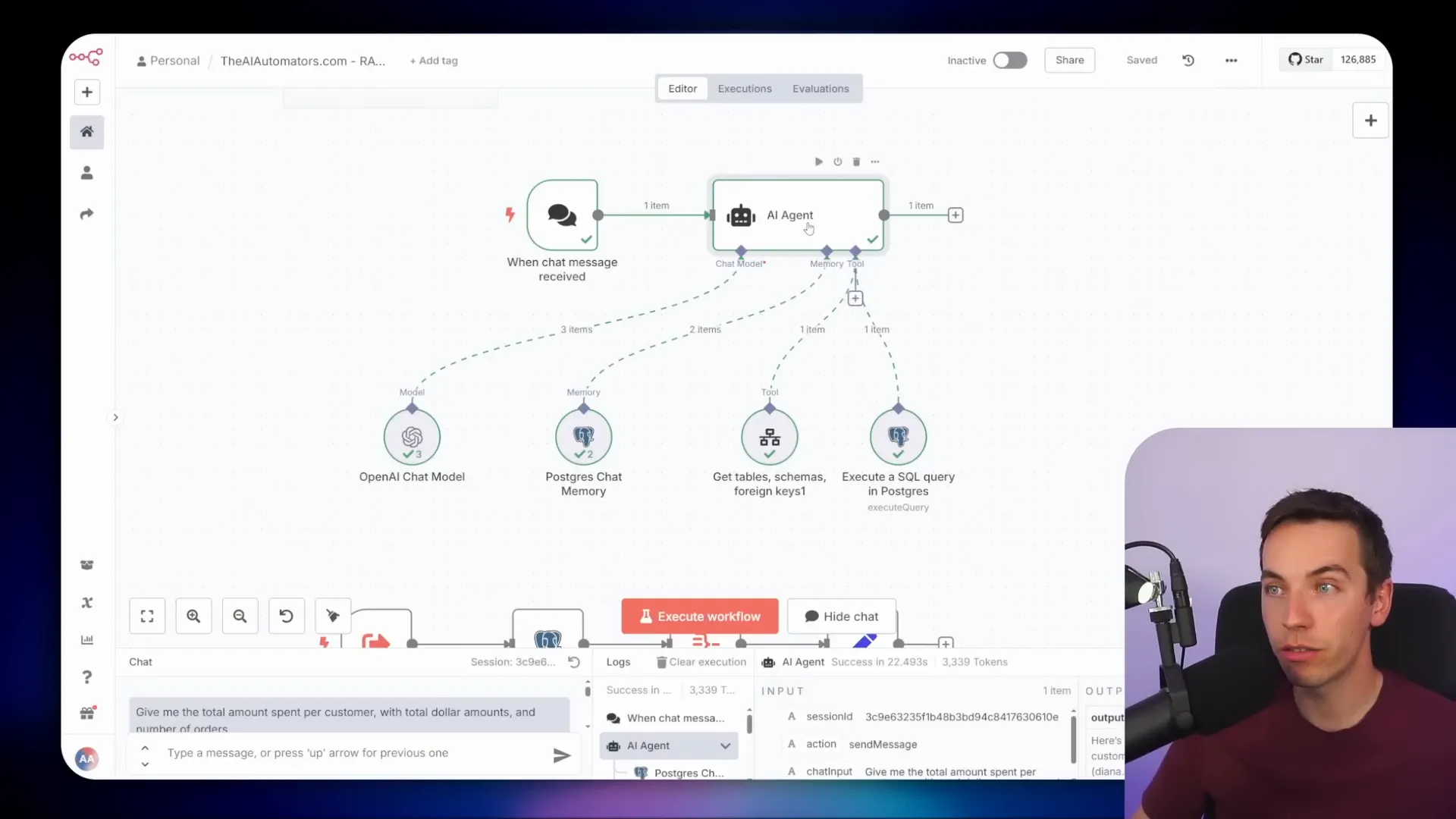
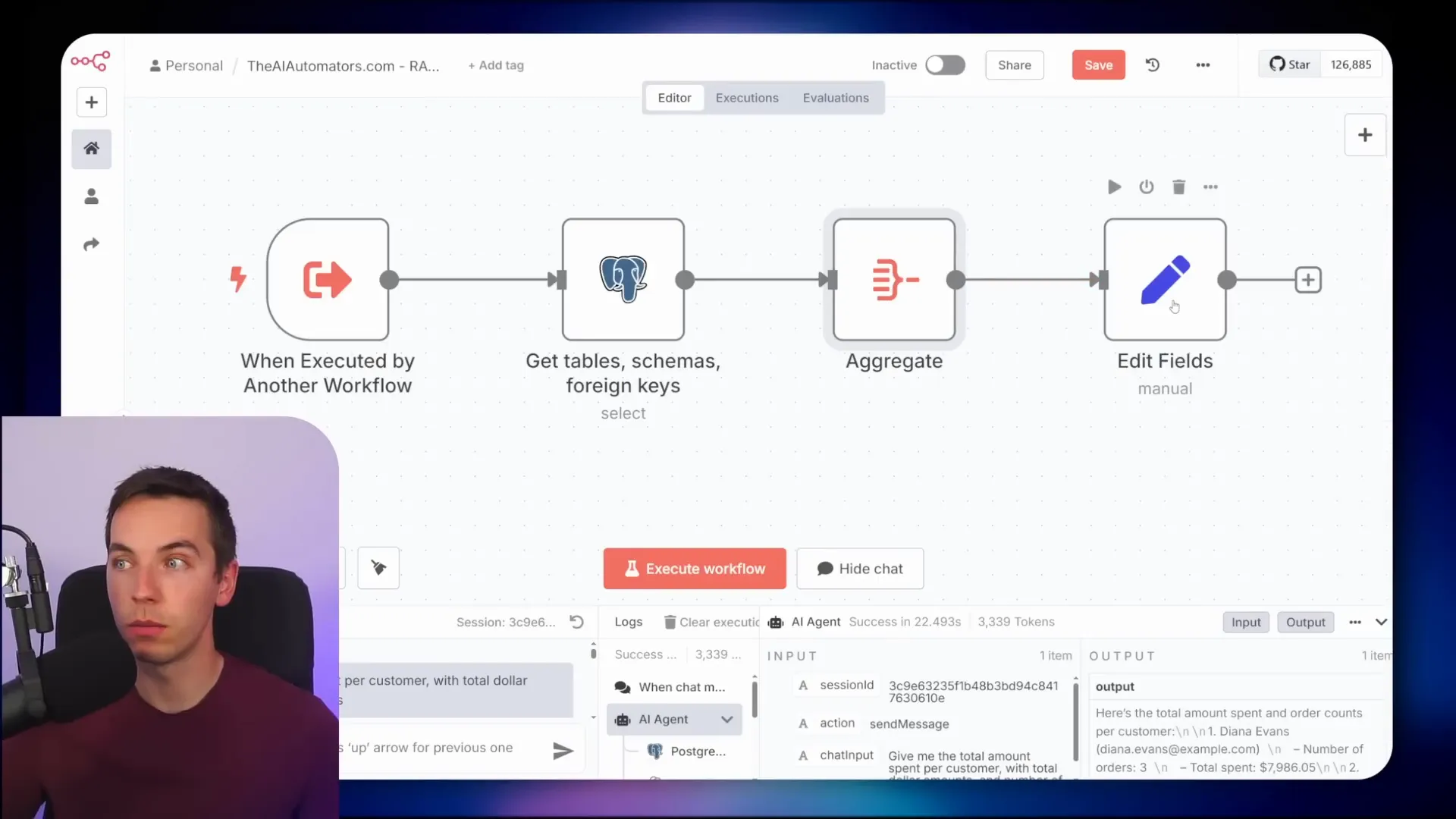
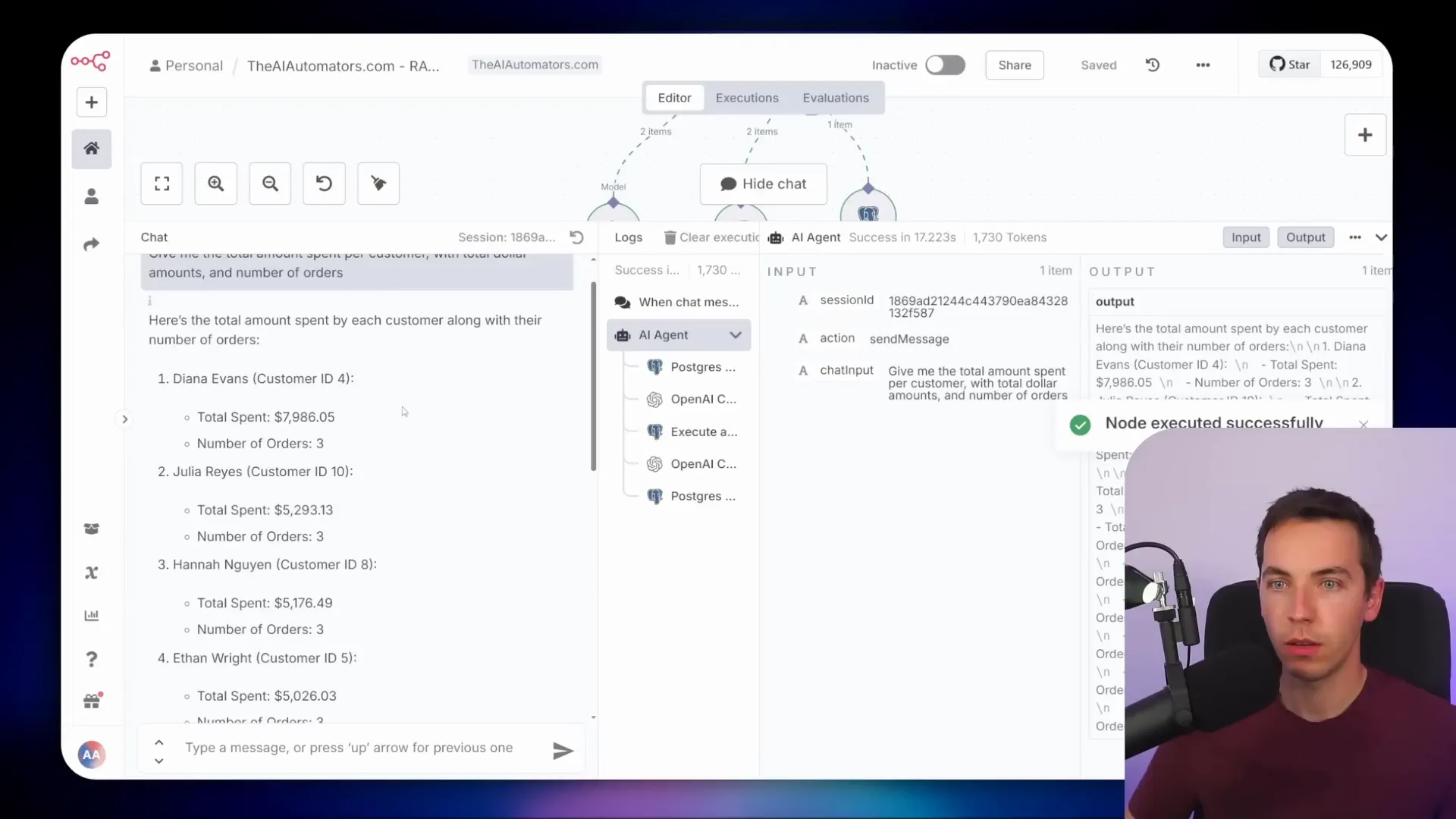
For example, I asked the agent: “Give me the total amount spent per customer with total dollar amounts and number of orders.” The agent first calls a tool that retrieves the table schemas and foreign key relationships within the database. With that context, the AI constructs a complex SQL query joining these tables together. It then executes this query directly against the database.
The response from the agent gives the total amount spent and order counts per customer. This kind of calculation is something that traditional Retrieval-Augmented Generation (RAG) agents usually struggle with because they don’t handle relational data and aggregations well.

Digging deeper, I copied the SQL query generated by the AI and ran it directly in Supabase’s SQL editor. The query correctly joins the tables using foreign keys and groups the data to produce accurate totals.
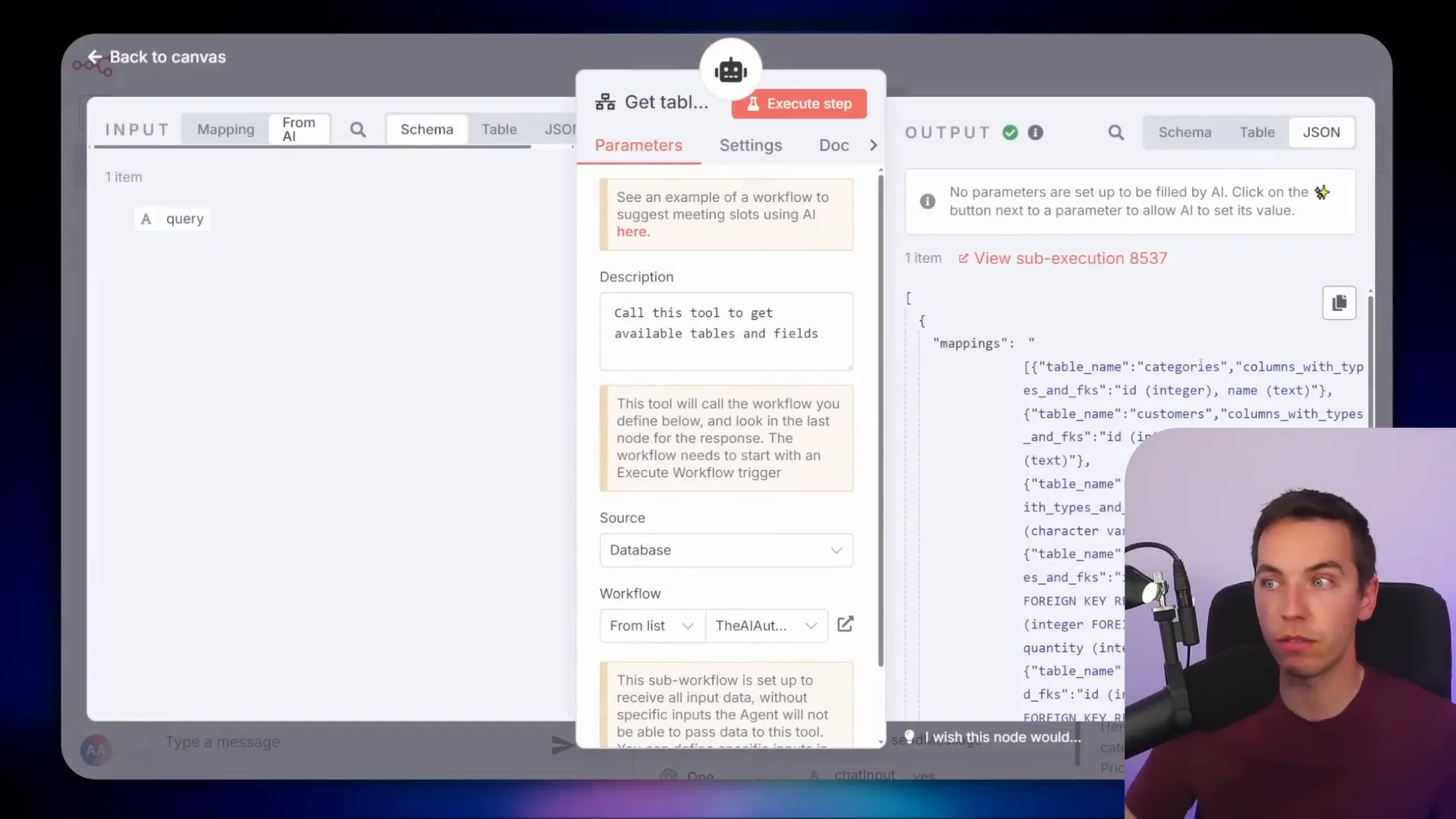
What’s important here is that I didn’t hardcode any schema information into the system prompt. Instead, the agent dynamically retrieved the schema details from a special view I created. This view lists every table, column, data type, and foreign key relationship in the database.
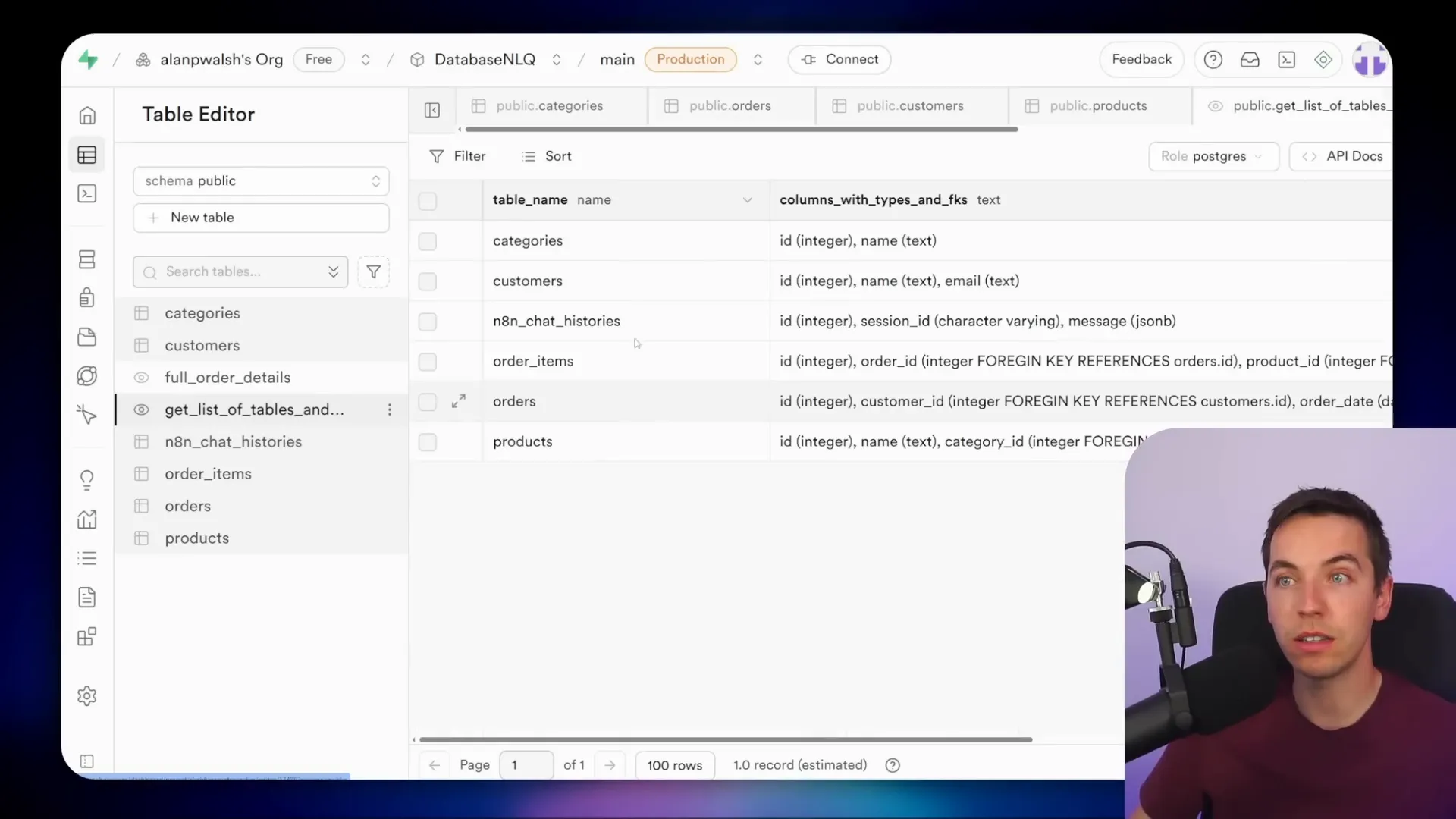
The agent calls this tool first to understand the database before building any SQL queries. This approach is called Natural Language Query (NLQ). It ensures that the AI has the right context to generate precise and efficient SQL commands.
Why Natural Language Query Matters
NLQ is a powerful concept that allows users to ask questions in plain English, and the AI translates those into SQL queries that run directly on the database. The key is making sure the AI understands the database structure, including tables, columns, and how they relate to each other.
When you ask a question, the AI agent first gathers context about the database schema. It can get this context either from a hardcoded system prompt or by calling a tool that fetches this metadata dynamically. Then it constructs the SQL query, executes it, and interprets the results to give you a clear answer.
This method is quite different from conventional RAG. Normally, RAG converts user questions into embeddings and searches a vector database for relevant chunks of text. However, relational databases store structured data that require exact calculations and joins—tasks that semantic search alone can’t handle well.
If you use a vector database to store relational data, the AI might return unrelated chunks out of context, leading to hallucinated or incorrect answers. That’s why integrating NLQ with relational databases is essential for precise quantitative queries.
Later, I’ll explain how you can combine NLQ with RAG systems to get the best of both worlds: semantic search for unstructured data and accurate SQL queries for structured data.
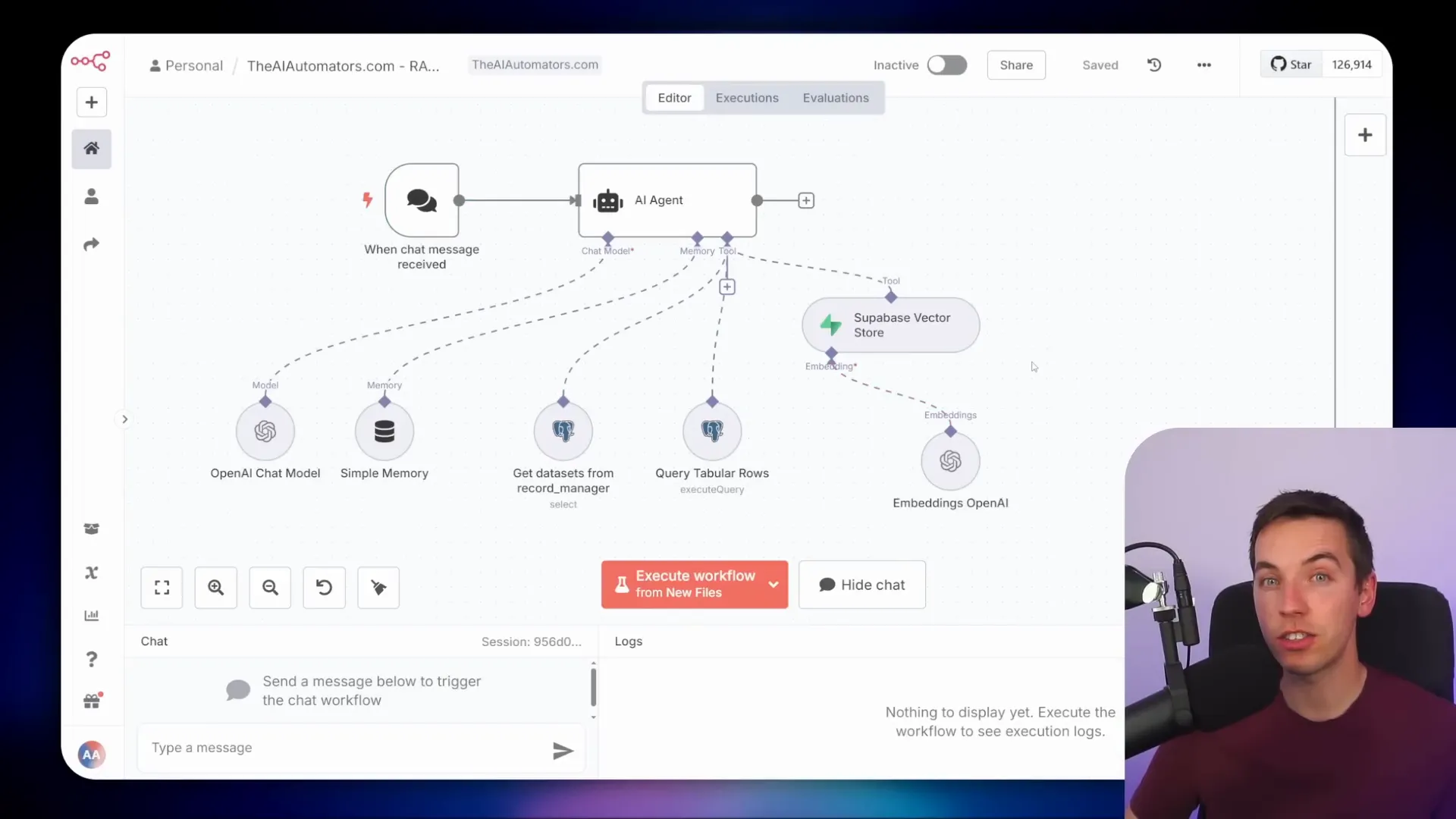
Building the AI Agent
I built this AI agent using n8n, a powerful automation tool. The agent connects to an OpenAI chat model, specifically a reasoning model called chain of thought O4 Mini. This model outperformed others like GPT-4o because it constructs more sophisticated queries that can join multiple tables. GPT-4o often limited itself to querying a single table, which isn’t sufficient for complex databases.
For memory, I used a Postgres chat memory node to store the last few messages, but you could also use simpler short-term memory setups. This helps the agent maintain context during conversations.

If you don’t have Postgres credentials set up, you can easily get them from your Supabase instance by going to the connect section and viewing parameters. However, the default user is a superuser, which poses security risks. I’ll explain later how to create a restricted user to protect your database from SQL injection and other attacks.
The System Prompt: Guiding the AI
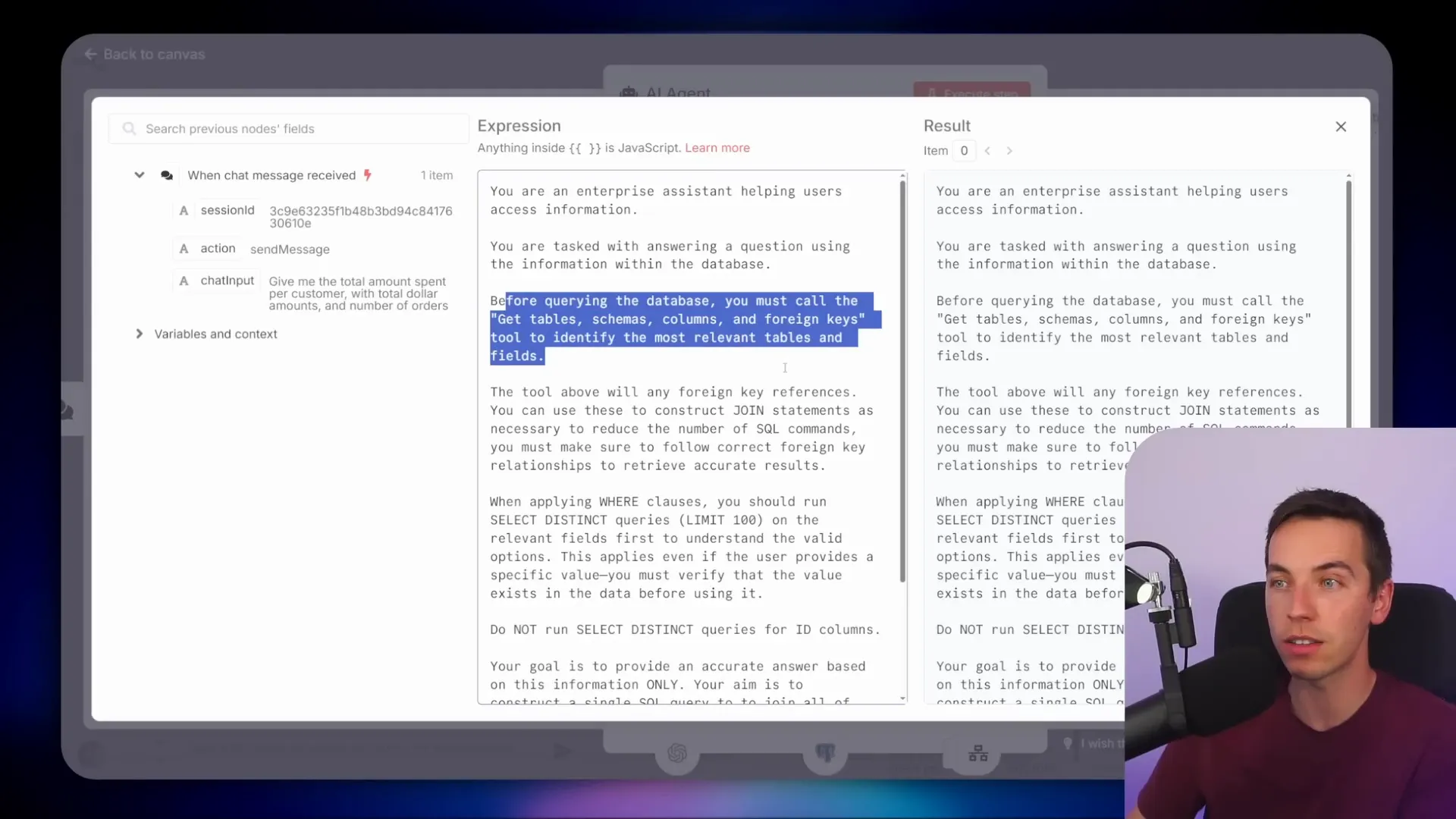
The system prompt is the backbone of how the AI understands its task. Here’s an excerpt from the prompt I use:
You are an enterprise assistant helping users access information. You are tasked with answering a question using the information within the database. Before querying the database you must call the get tables, schemas, columns and foreign keys tool to identify the most relevant tables and fields.
This instruction ensures the AI always gathers schema information first before attempting any queries. If your database structure is stable, you can speed things up by hardcoding the schema directly into the prompt instead of calling the tool every time.
The prompt also includes guidance on how to handle foreign keys to build proper JOIN statements and advises against the AI trying to summarize or group data itself. Instead, the AI should rely on SQL for those tasks. It even instructs the AI to run SELECT DISTINCT queries on relevant fields to verify any filter values before applying them, reducing the chance of returning empty results due to typos or incorrect values.
Creating the Schema View
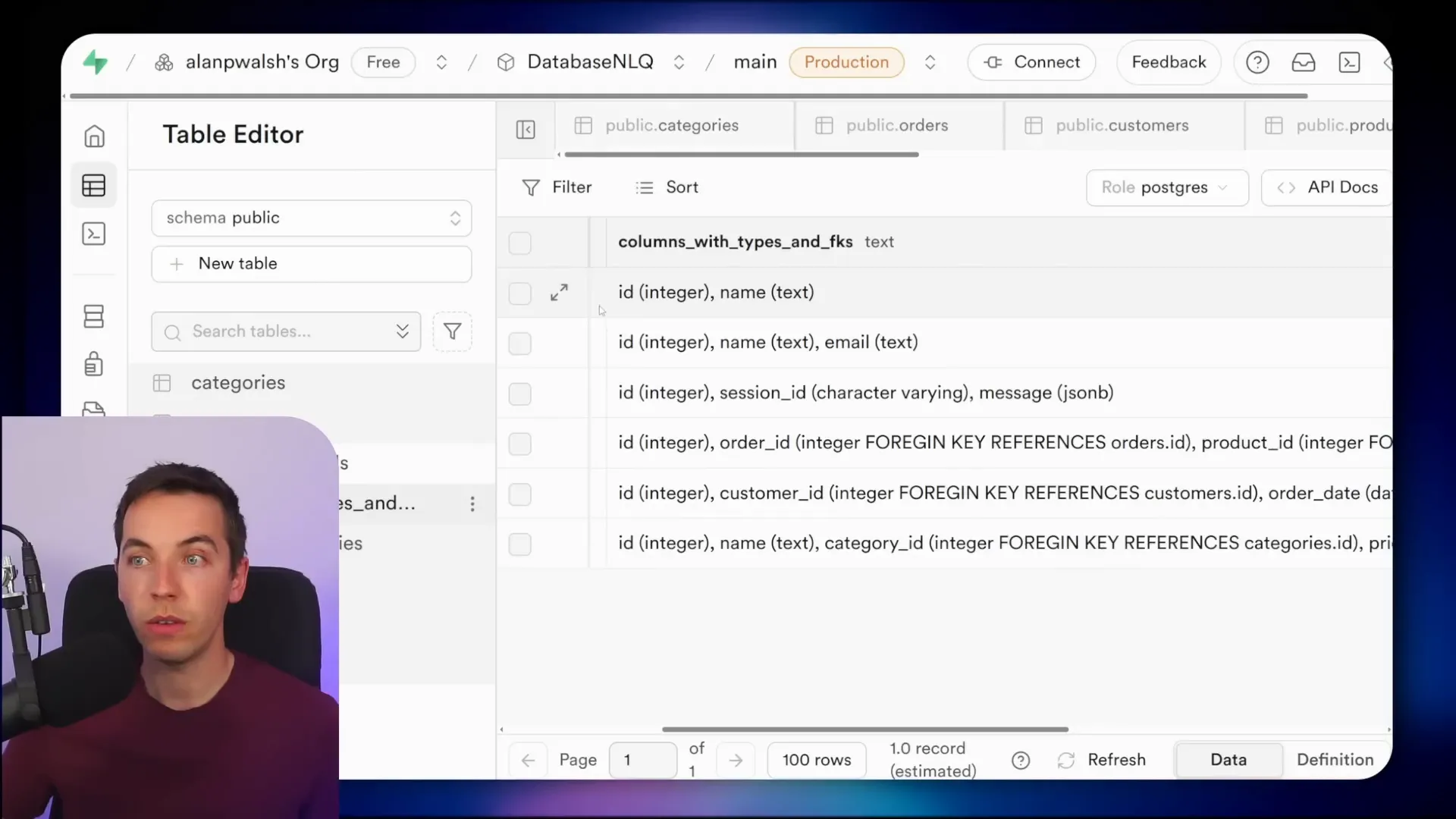
To provide the AI with schema information dynamically, I created a database view called get_list_of_tables_and_columns. This view lists every table, column, data type, and foreign key reference in the database.
Here is an example of what the view contains:
- Table names
- Column names
- Data types (important for query construction)
- Foreign key references
Although I noticed a typo in the column name for foreign keys, the AI still figured it out correctly. I plan to fix that soon.
I asked ChatGPT to generate the SQL code for this view. The query is longer than usual because it includes foreign key relationships, but it’s straightforward to run in Supabase’s SQL editor. Once created, the view appears alongside other tables and can be queried like any other.
In the workflow, the agent calls this view and aggregates all the rows into a single data object representing the schema. This object is then mapped into the agent’s memory for use during query construction.
Advanced Filtering with the AI Agent
The agent can also handle filtering queries intelligently. For example, if you ask it to “Show me all products from the closed category,” the agent checks the actual distinct values in the database first. It might respond that it doesn’t find a category named “closed” but suggests “clothing” as the closest match.
You can then confirm this correction, and the AI will adjust its SQL query accordingly, applying the correct WHERE clause to retrieve the right data.
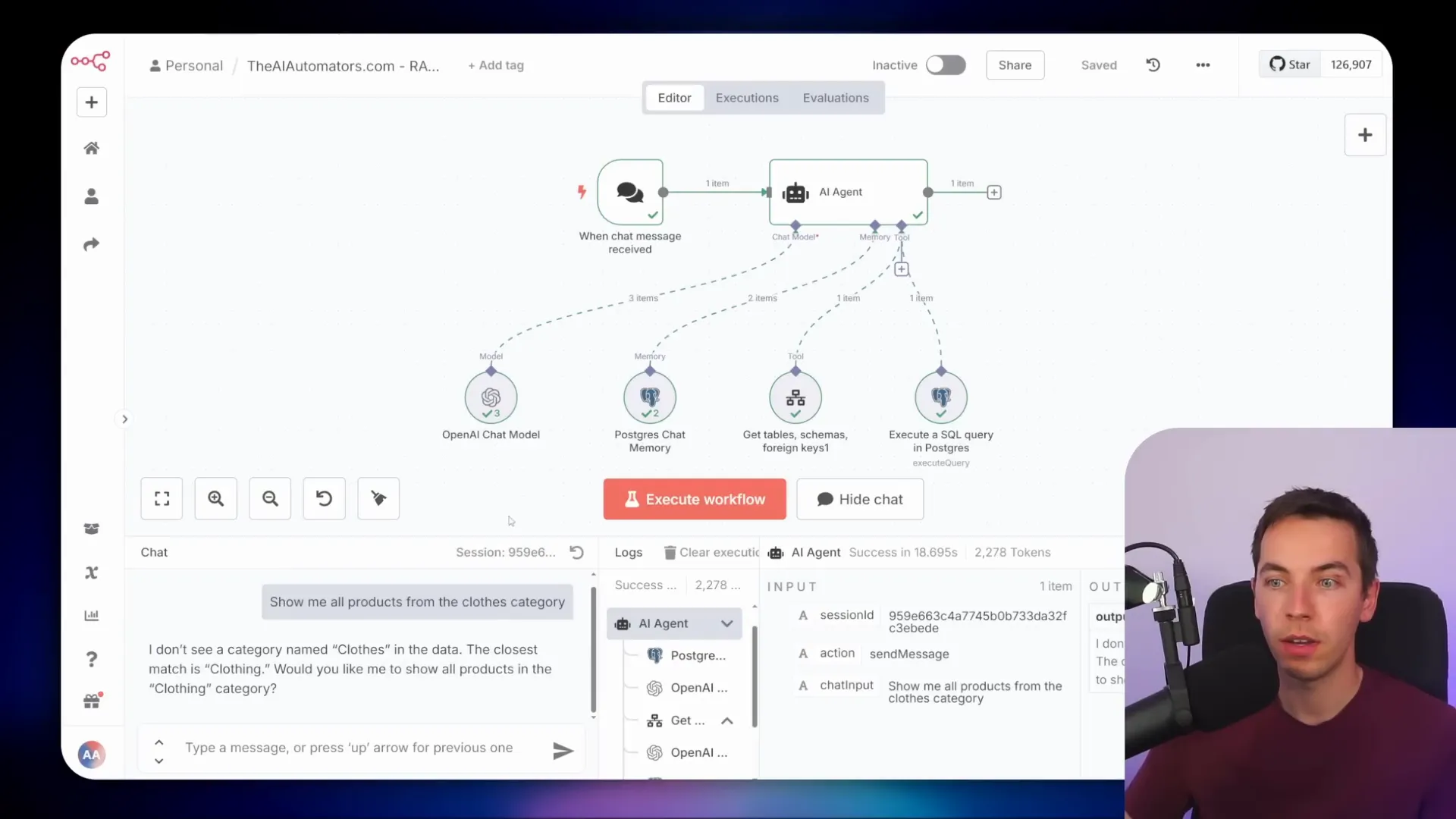
This ability to check valid values before querying is crucial. Without it, the agent might return zero results or incorrect data if the user’s input doesn’t exactly match the database entries.
Optimizations: Hardcoding Schema
If your database schema doesn’t change often, you can optimize performance by hardcoding the schema information directly into the system prompt. This removes the need for the AI to call the schema retrieval tool every time.
I created a simplified version of the AI agent where I pasted the list of table schemas and foreign keys into the system prompt. This results in faster query generation and reduces the number of database calls.
Whenever the schema changes, you can rerun the schema retrieval workflow and update the prompt accordingly. This approach balances flexibility with speed, especially useful in production environments.
Approach: Creating Flattened Views for Complex Databases
While the above methods work well for moderately normalized databases, there is a limit to how complex the AI can handle SQL joins reliably. For very complex schemas, I recommend creating a flattened view in your database.
A view acts like a stored query that combines data from multiple tables into a single denormalized table. This simplifies querying for the AI by reducing the need for complex joins.
For example, I created a full_order_details view that combines customer details, order information, and product data into one table. Although this introduces redundancy, it makes querying much easier and more reliable.
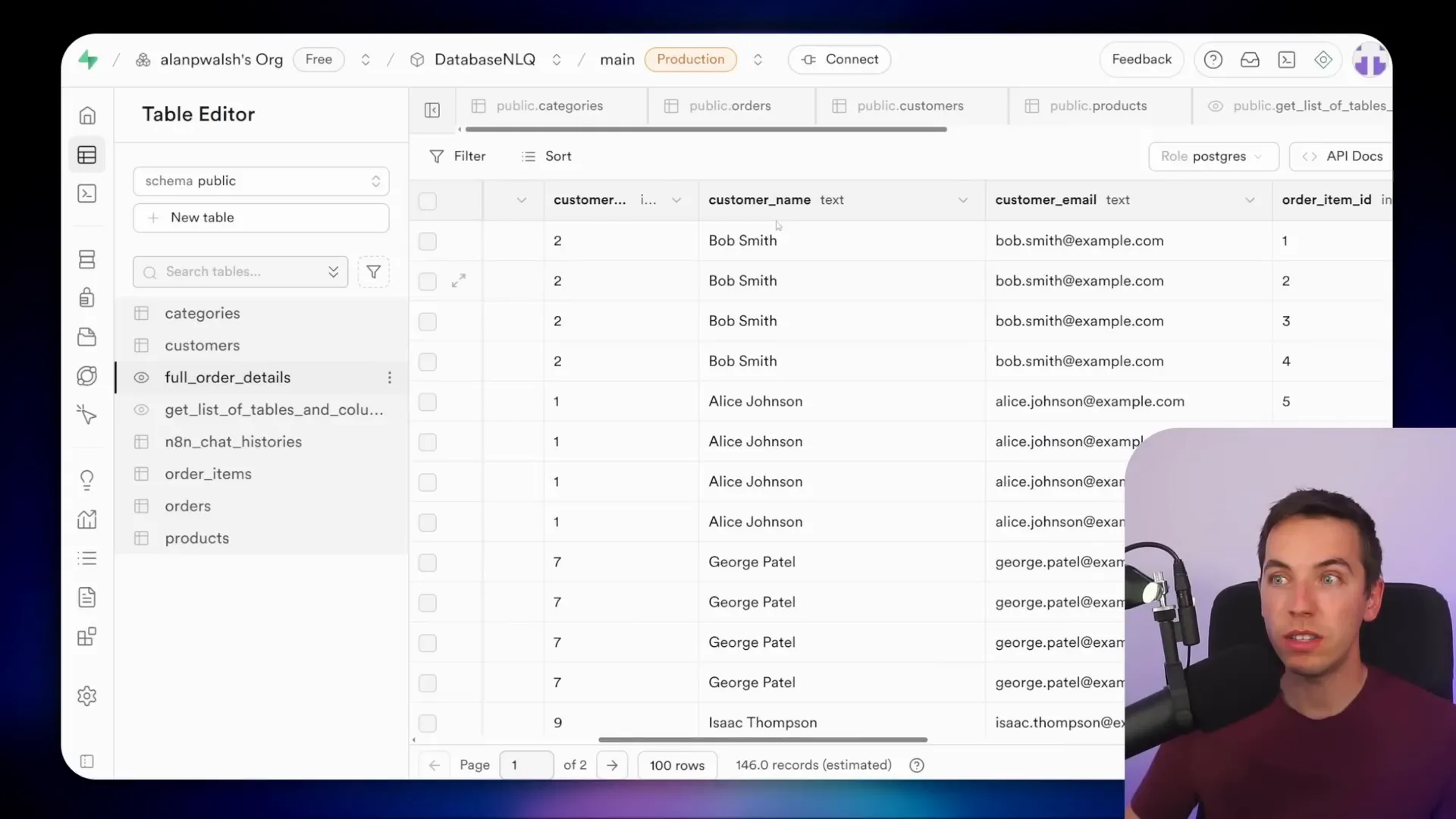
You can copy the table schema from this view and paste it into the AI agent’s system prompt to define the structure. Then, when you ask the agent questions, it queries this view directly instead of joining multiple tables.
When I asked the agent the same question about total amount spent per customer, it returned the correct results using this view. The queries are simpler, which means you can use cheaper AI models and still get reliable answers.
Approach: Using Prepared Queries for Deterministic Access
For scenarios where you want to limit the AI agent’s access to your database and increase reliability, you can create prepared queries or stored procedures. Instead of allowing arbitrary SQL, you define specific queries the agent can call as tools.
For instance, I created two tools:
- get_orders: Returns orders filtered by status (e.g., pending, completed).
- get_product_list: Returns a list of products with no parameters.
The get_orders tool uses a SQL query with a dynamic parameter for order status. The AI agent passes in the appropriate value, but cannot execute any other arbitrary SQL commands.
This setup is more secure and deterministic. You can duplicate and customize these tools for different queries your application needs. However, this approach sacrifices some flexibility compared to the fully dynamic NLQ approach.
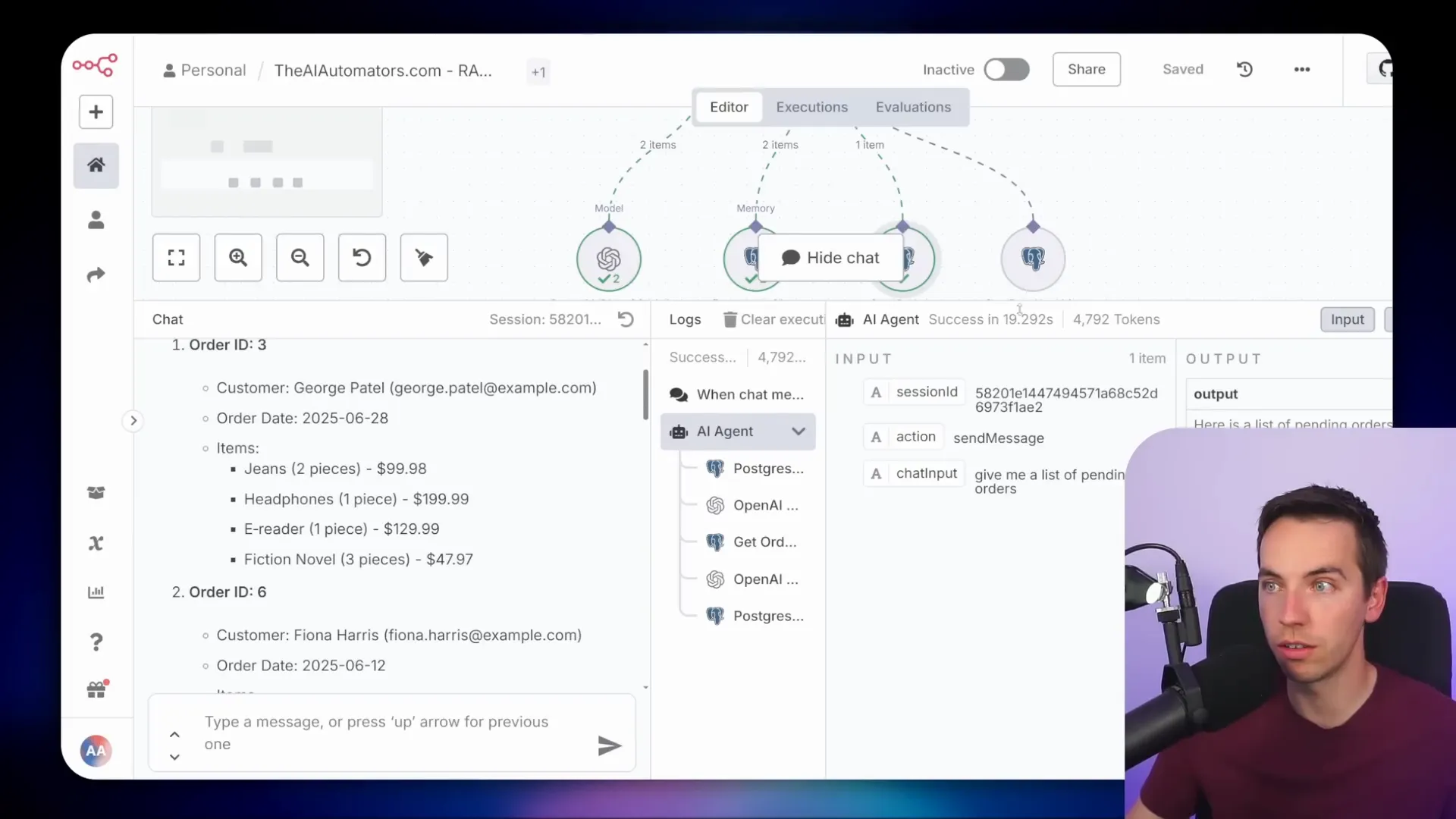
When I tested asking for pending orders, the agent called the get_orders tool with the correct parameter and returned detailed order information. Similarly, asking for the current product list activated the get_product_list tool.
Security: Protecting Your Database from SQL Injection
Allowing an AI agent to execute SQL queries directly introduces a serious risk: SQL injection. Malicious or malformed prompts could trick the AI into running destructive commands like dropping tables or deleting data.
To mitigate this, I strongly recommend creating a read-only user in your Postgres database. This user only has permission to run SELECT queries on specific tables or views and cannot perform any data modification operations.
Here is an example SQL command to create a read-only user:
CREATE USER readonly WITH PASSWORD ‘yourpassword’;
GRANT USAGE ON SCHEMA public TO readonly;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO readonly;
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO readonly;
You’ll need to adjust permissions based on which tables or views the AI should access. I include scripts for this in my system blueprints, but they vary depending on your database structure.
By using a restricted user, you prevent the agent from accidentally or intentionally running harmful SQL commands. This is a crucial step for production deployment.
Combining Relational Querying with Other Retrieval Methods
For advanced use cases, you can combine relational database querying with other retrieval methods like vector or graph databases. This hybrid approach lets the AI agent handle both structured and unstructured data efficiently.
In this setup, when the AI receives a question, it first attempts to retrieve relevant information from the vector store if the question is general or semantic in nature. If the question involves tabular data—calculations, sums, averages, or maximum values—the agent switches to querying the relational database using SQL.
This combination gives the agent the best of both worlds: semantic understanding from vector search and precise quantitative analysis from SQL queries.
By integrating these components, you can build powerful AI systems that provide accurate and contextually rich answers across various data types.
