
I created an automation that allows AI agents to answer questions based on spreadsheet and database data accurately and efficiently. Traditional vector stores often struggle with this task, especially when it comes to structured data like spreadsheets. They usually return poor results, as semantic search retrieves chunks of documents that are often out of context. To overcome this, I developed a hybrid approach that combines relational databases and vector stores, enabling natural language queries (NLQ) on structured data stored in Supabase, while still leveraging vector stores for unstructured information.
Why Traditional Vector Stores Fall Short for Spreadsheet Queries
Vector stores are excellent for searching through unstructured data such as text documents, PDFs, or emails. They work by converting text into vectors and then finding semantically similar chunks based on a query. However, when you ask a simple question like, “What is the sum of all my orders?” the vector store retrieves chunks that match semantically but might not provide a precise answer. The results could include fragments from multiple documents or unrelated contexts, making it difficult to get an accurate numeric answer.
This limitation arises because vector search is designed to find related content, not to perform exact calculations or filter data by specific fields. Spreadsheets and databases require precise querying, often involving aggregations like sums, counts, or filters by categories. Semantic search alone can’t replace the structured querying capabilities of SQL databases.
Introducing Agentic RAG: A Hybrid Approach
To address these issues, I use a method called agentic RAG (Retrieval-Augmented Generation). Instead of storing all company data in a vector database, I choose to keep structured data in a standard relational database like Supabase. Supabase conveniently supports both vector storage and relational tables within the same project, which simplifies integration.
When I ask the AI agent a question, it decides whether to fetch semantic results from the vector database or to execute a precise SQL query on the structured data using NLQ. NLQ stands for natural language query, which means the agent translates plain English questions into SQL commands to retrieve exact answers from the database.
This hybrid setup provides the best of both worlds: accurate quantitative responses from structured data and rich context-based answers from unstructured documents.
How the System Works
The workflow I created begins with ingesting spreadsheets and storing their data in a relational database. The overall schema information for each sheet is stored in a single table within the vector database. This design is highly flexible because it avoids the need to create a separate database table for every different spreadsheet structure.
When the agent receives a query, it first retrieves the available datasets and their schema information. Then, if the question requires structured data, it generates a SQL query to fetch results quickly and accurately. For other questions that don’t involve structured data, the agent queries the vector database to provide answers based on unstructured content stored as vectors.
Demo: Querying Spreadsheet Data with AI Agent
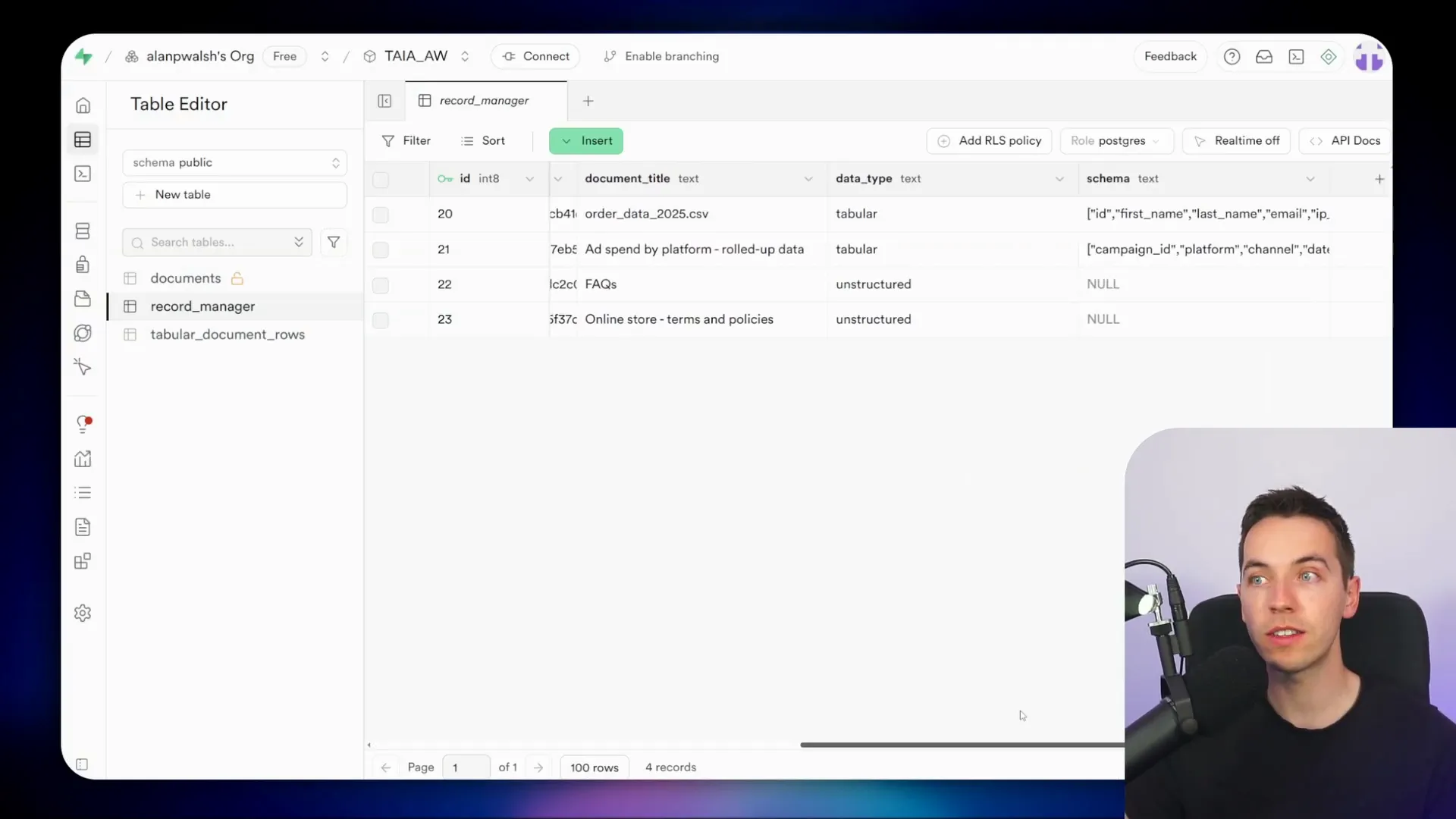
To demonstrate, I uploaded two spreadsheets into my system: a CSV file containing 1,000 rows of order data and a Google Sheet with rolled-up analytics data. Both files are registered in a central record manager table within Supabase, which lists all documents in the database, including unstructured files stored in the vector store and tabular data in relational tables.
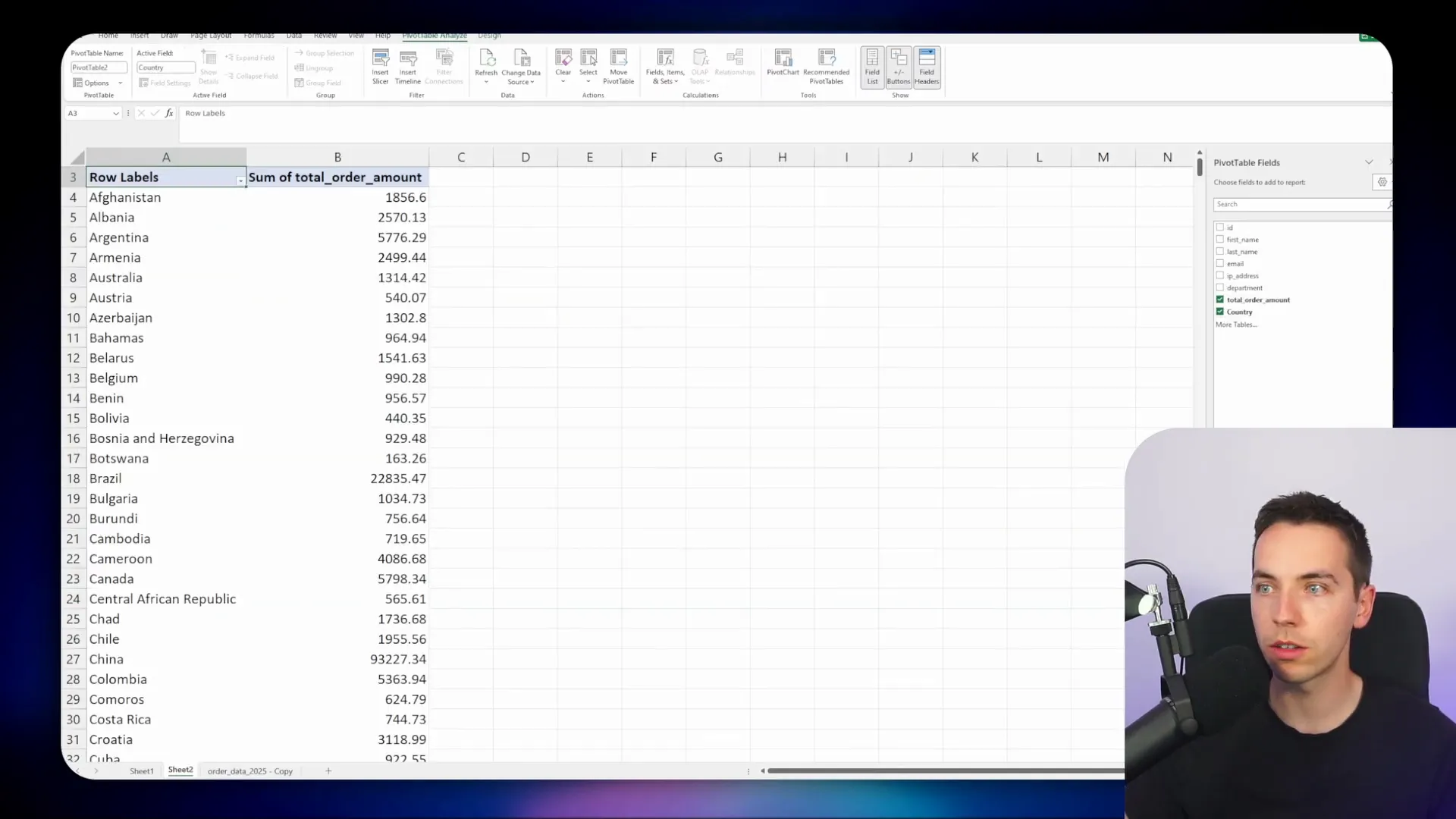
I asked the agent, “Give me a breakdown of orders by country.” The agent first retrieved dataset information from the record manager, then queried the tabular document rows table to fetch the total count of orders per country. The response matched perfectly with what I verified manually using an Excel pivot table.
Next, I asked for the sum of all orders by country. The agent correctly understood that I wanted the monetary total, not just the count, and returned accurate results confirmed by my pivot table in Excel.
This demo shows the agent’s ability to interpret natural language questions, decide which dataset to query, and construct SQL queries dynamically to get precise answers.
Behind the Scenes: How the Agent Builds SQL Queries
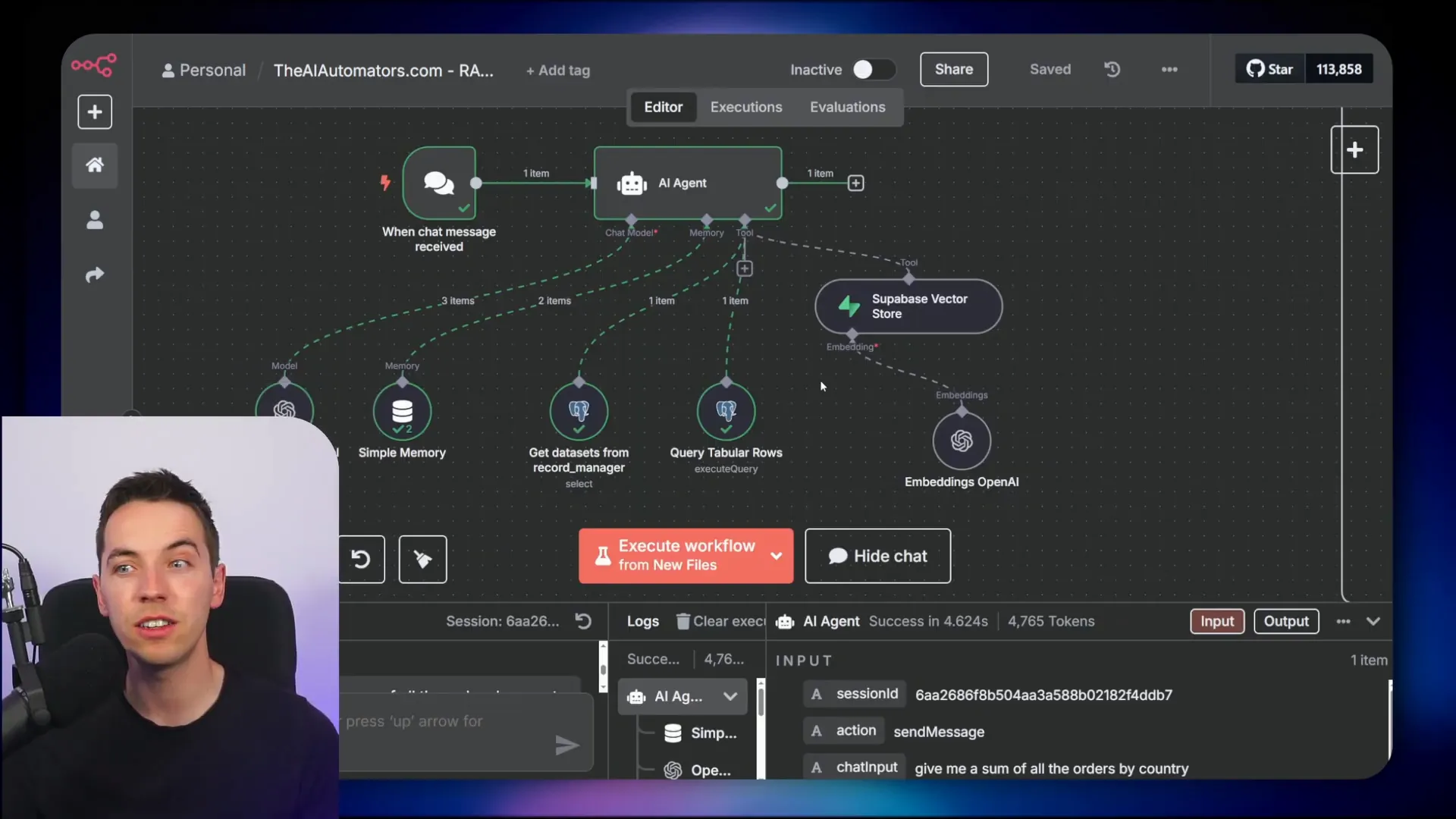
The agent starts by calling a tool to get datasets from the record manager. This tool returns the files uploaded along with their schema information. Each file is assigned a record ID that the agent uses to query the tabular document rows table.
All raw data from different spreadsheets is stored in a single table, regardless of their schema differences. Each row is serialized in a JSONB column, which is a flexible JSON binary format supported by PostgreSQL and Supabase. This allows me to store diverse spreadsheet data without creating multiple tables for each format.
When constructing SQL queries, the agent extracts values from the JSONB field using PostgreSQL’s JSON operators and casts them into appropriate data types. For example, to sum order amounts grouped by country, the SQL query looks like this:
SELECT row_data->>’country’ AS country, SUM(CAST(row_data->>’order_amount’ AS numeric)) AS total_order_amount
FROM tabular_document_rows
WHERE record_manager_id =
GROUP BY country
ORDER BY total_order_amount DESC;
This approach is both simple and powerful, enabling fast and accurate querying across various spreadsheet formats without complex database schema management.
Choosing Between Vector Store and Relational Database
While it might be tempting to store all spreadsheet data as vectors, especially for small datasets, I generally avoid this. Vectorizing structured data introduces noise and reduces precision in queries that require exact calculations.
If your spreadsheets are small and simple, storing them in the vector database can work, provided the chunk size is large enough to hold entire rows or tables. However, for larger or more complex data, relying on a relational database with NLQ is more efficient and accurate.
For databases with many tables or complicated schemas, NLQ can become challenging. It might require strict system prompts or even fine-tuning the AI model to understand the schema better. In such cases, creating database views that simplify the schema or denormalizing data into star schema structures for analytics can help.
Still, I prefer to keep things simple by storing all spreadsheet rows in a single JSONB column and managing schema information separately. This balances flexibility and ease of maintenance.
Limitations to Consider
One drawback of this method is that while the record manager table tracks the schema of each file, it doesn’t store data examples or data types for each field. This means the AI agent might not always infer the correct data types or expected values without additional context.
Adding AI-assisted schema enrichment to extract data types and sample values could improve accuracy but would require extra processing steps.
Data Ingestion Pipeline: Uploading and Updating Files
I built an automated pipeline that handles new and updated files stored in Google Drive. It listens for various file types and processes them accordingly:
- Unstructured files (Google Docs, PDFs, HTML) go through an embedding process and are stored in the vector database.
- Structured files (CSV, Excel, Google Sheets) are extracted and stored in the relational database using the JSONB format.
This pipeline starts with triggers for new or updated files in a specified Google Drive folder. Unfortunately, it doesn’t detect deleted files directly. To handle deletions, I created a recycling bin folder. Any file moved there triggers a workflow that deletes associated vectors and database records.
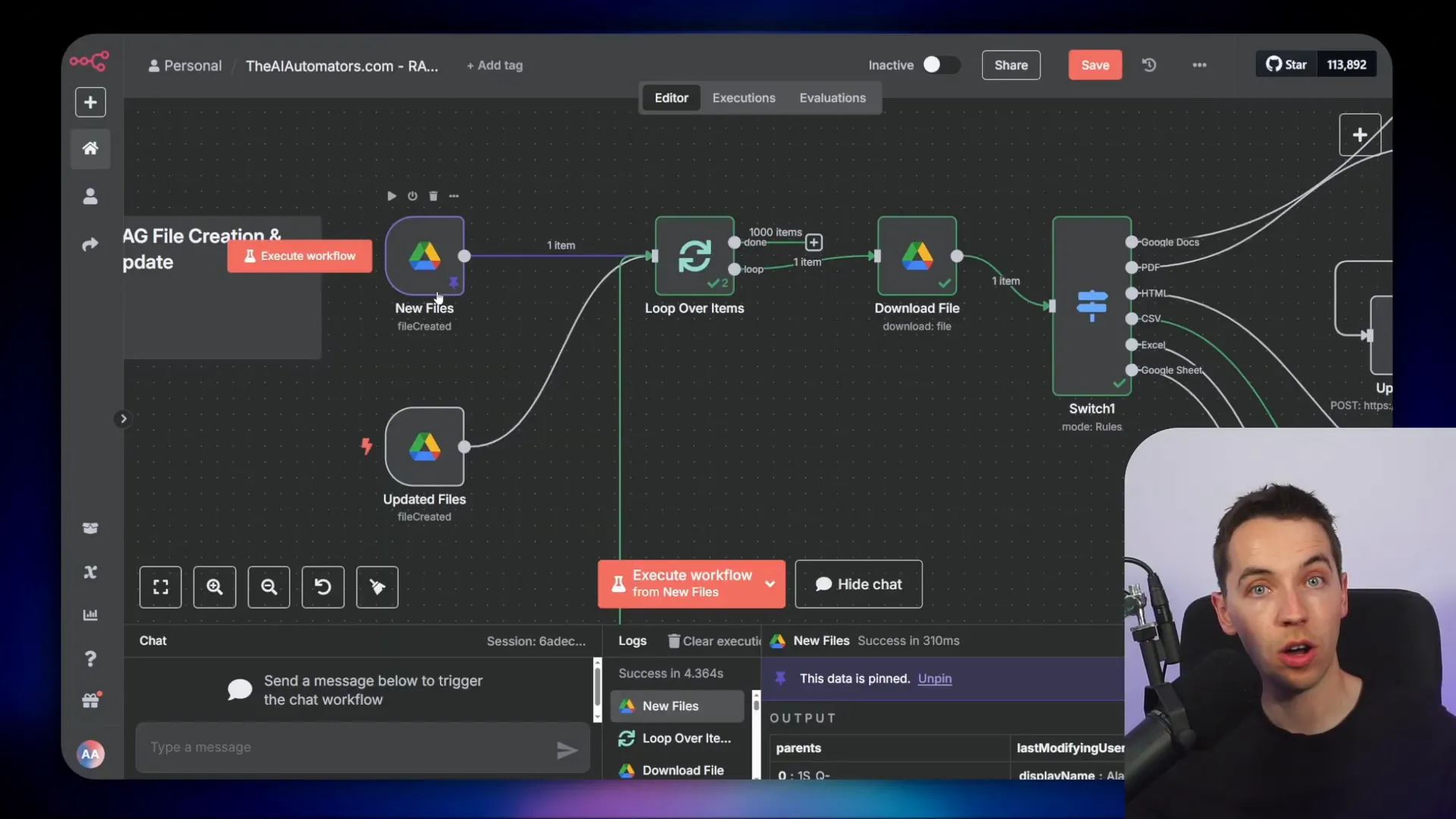
File Processing Steps
Once a file is detected, the pipeline downloads it using Google Drive credentials. A switch node determines the file type based on MIME type, routing it to the correct extractor:
- CSV files: Extracted into individual rows using a CSV parser node.
- Excel files: Parsed using an XLSX extractor node.
- Google Sheets: Accessed directly via the built-in Google Sheets node.
Each extractor outputs thousands of items representing rows. I use an aggregate node to combine these into a single array for further processing.
Extracting Schema and Data
To get the schema, I assume the spreadsheet has a top-level header row. Using an array keys node, I extract the column names from this header. Then, I concatenate all the data into one string. This serves two purposes:
- It allows sending the entire structured data as a single string to the vector database if needed, where it can be chunked for semantic search.
- It generates a hash to check if the data has changed when files are updated.
By comparing the hash of the current file with the stored hash in the record manager, I can detect updates and decide whether to refresh the data in the database and vector store.
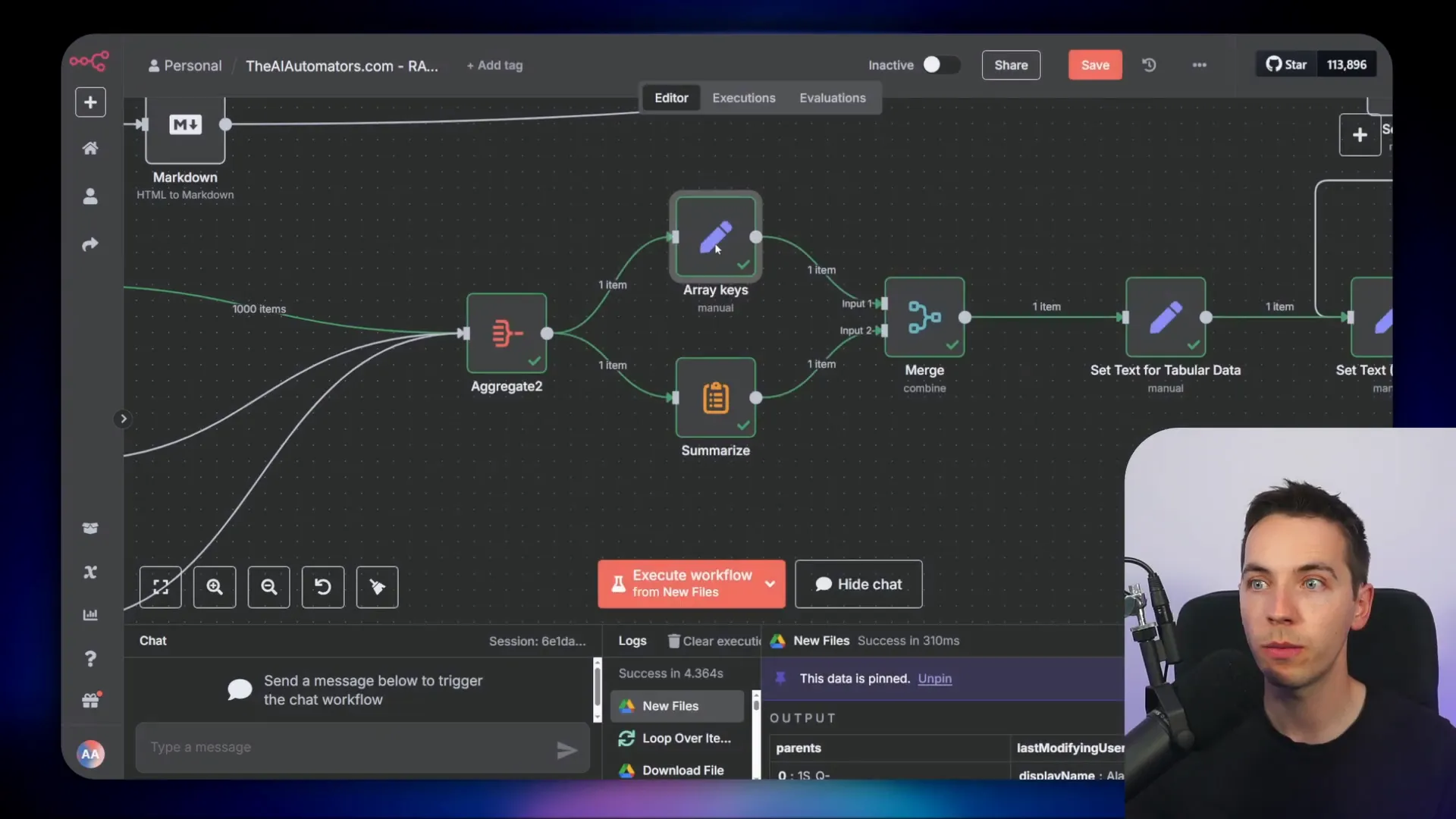
Consolidating Data for Storage
Before storing, I consolidate both structured and unstructured data into a consistent format. This includes fields like:
- Text: The full text or concatenated content.
- Data type: Either “tabular” or “unstructured”.
- Array keys: The schema or column headers.
- Data rows: The actual rows of data.
This unified structure simplifies downstream processing and storage, allowing the system to handle both data types seamlessly.
Record Management with Supabase
The record manager table in Supabase acts as the central repository for all files, storing their hash, Google Drive file ID, schema, data type, and title. When a new file is ingested, the system checks if it already exists in the record manager by looking up the file ID and comparing hashes.
If the file is new, a record is created. If it has changed, the existing record is updated. This prevents unnecessary reprocessing and keeps the data synchronized with the source files.
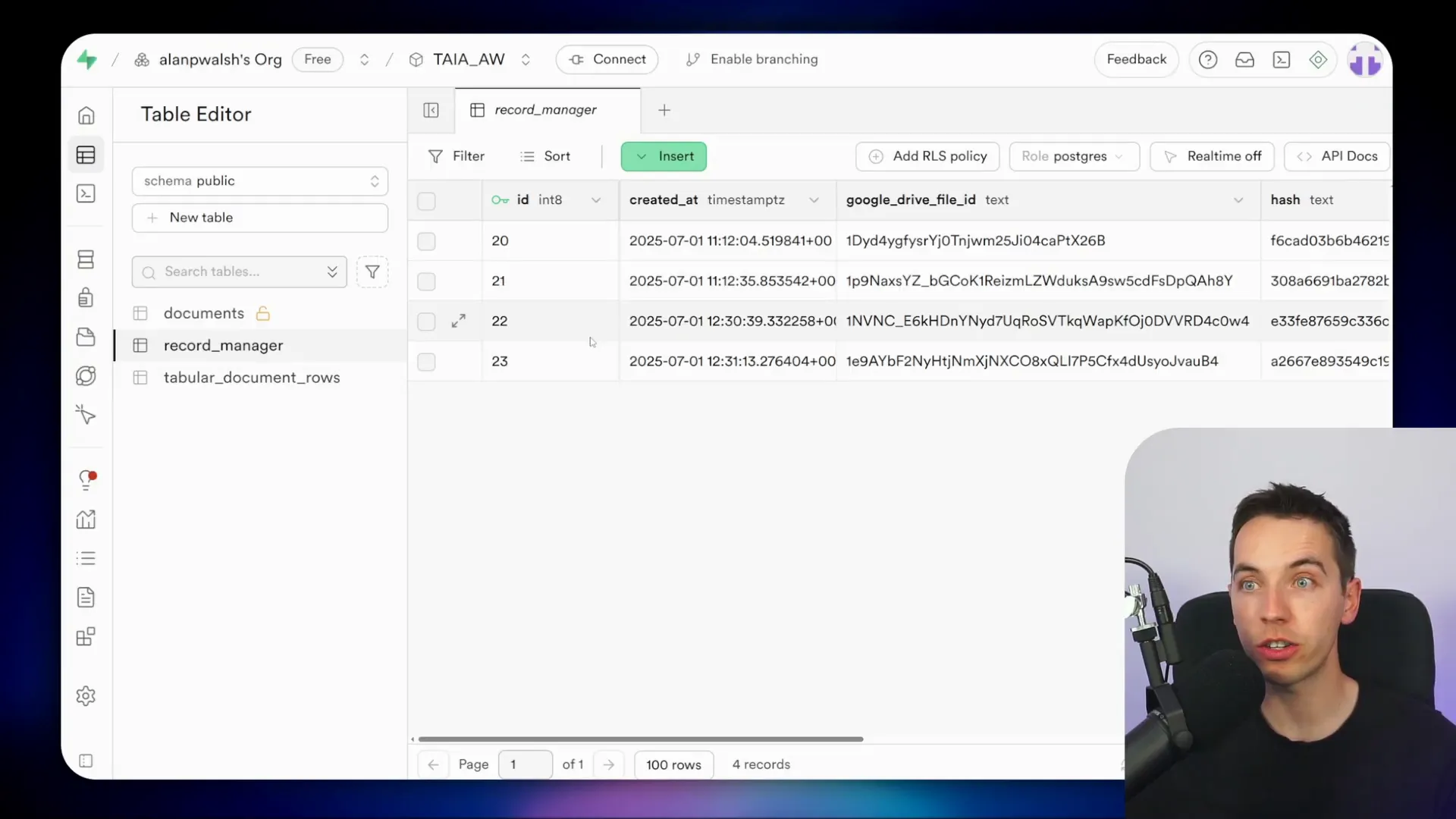
Handling Tabular Data Rows
For tabular data, I use a dedicated table called tabular_document_rows in Supabase with the following structure:
- ID: Primary key for each row.
- Created at: Timestamp of insertion.
- Record manager ID: Foreign key linking to the file in the record manager.
- Row data: JSONB field containing serialized row data.
The foreign key constraint ensures data integrity by preventing orphan rows that don’t belong to any file.
When updating data, the system first deletes all rows associated with the file to avoid duplicates. Then, it inserts each row individually by splitting the aggregated array of rows back into separate items.
Because the built-in Supabase node sometimes struggles with JSONB data, I use a PostgreSQL node to connect directly to the Supabase PostgreSQL database. I configure the connection using the database credentials provided by Supabase, including host, database name, username, and password.
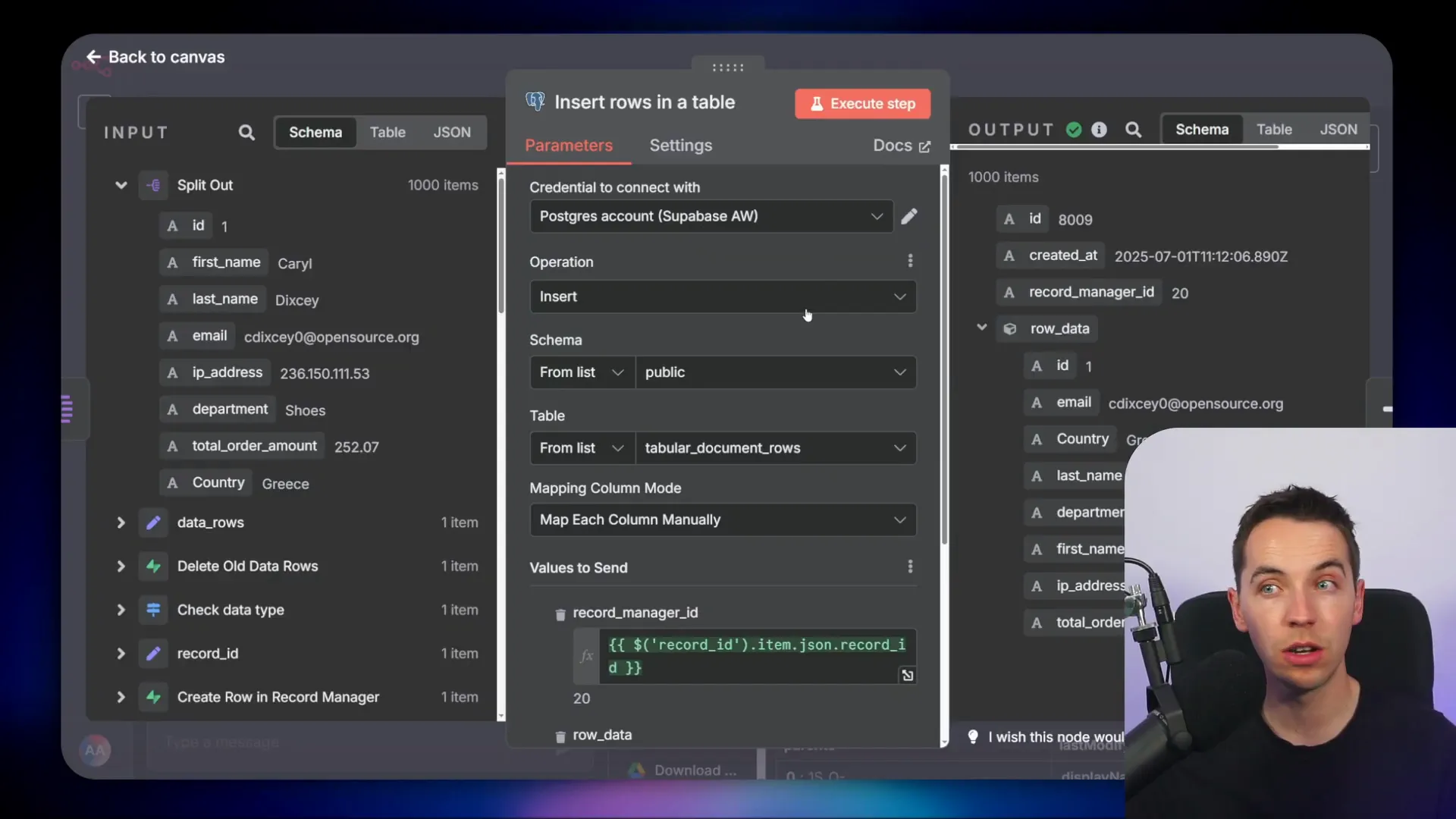
AI Agent Setup and Query Tools
The AI agent is built within n8n and configured with tools to access both vector store data and the relational database. The main components are:
- Vector store tool: Handles unstructured data queries.
- Get datasets from record manager: Retrieves available tabular datasets and their schema.
- Query tabular rows tool: Executes SQL queries on the tabular_document_rows table.
The agent’s system prompt instructs it to first query the vector store for information. If the question requires structured data, the agent uses the record manager to identify the relevant dataset and constructs SQL queries dynamically. It always filters queries by the record manager ID to ensure it only accesses data for one file at a time.
When writing SQL, the agent extracts values from the JSONB row_data using PostgreSQL’s JSON operators and casts them as needed, for example casting strings to numeric types for aggregation.
Example Queries and Responses
I tested the agent with questions like:
- “How much money did the electronics department make?”
- “What ad platform did we get the most conversions from?”
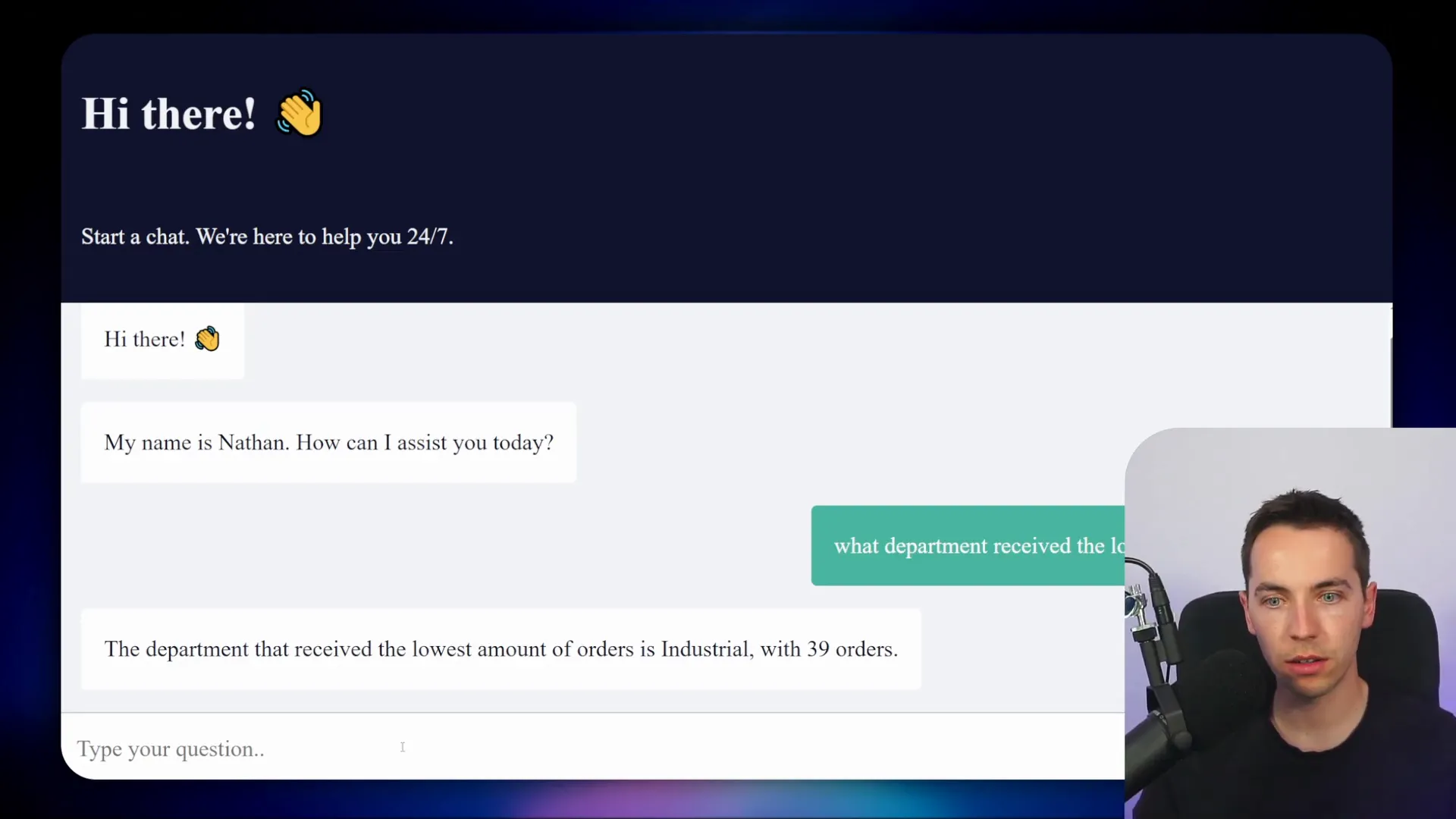
- “What department received the lowest amount of orders?”
In each case, the agent generated appropriate SQL queries, executed them against the tabular data, and returned accurate and human-readable answers. For questions about unstructured data, such as “How long does shipping take?”, the agent queried the vector store and returned detailed text responses.
Maintaining Accuracy and Avoiding Hallucinations
The system prompt instructs the AI agent to only answer questions based on the retrieved information. If no relevant data is found, the agent responds with “Sorry, I don’t know.” This prevents the AI from fabricating answers and ensures reliability.
Restricting the agent to use only the data it can access also helps maintain accuracy and trustworthiness, which is critical for enterprise applications.
Extending the Workflow
This hybrid RAG pipeline can be expanded with additional features such as hybrid search (combining vector and keyword search), web scraping for data ingestion, and more advanced AI capabilities. However, the core approach remains the same: use vector stores for unstructured data and relational databases with NLQ for structured data.
By combining these technologies, I created an AI agent that can understand natural language queries, decide the best data source to use, and provide fast, accurate answers. This approach significantly improves the quality of AI-driven insights for spreadsheet and database data.
