

Sakana AI and OpenRouter both made a big claim recently. Their message was simple: a single giant model may not be the best way to get frontier level results anymore.
That’s a bold claim on its own. The twist is what sits underneath it.
Sakana’s Fugu is presented like a model, but the interesting part is that it behaves more like an orchestration layer sitting in front of other frontier models. OpenRouter’s Fusion pushes in a similar direction from another angle. Instead of choosing one model, it sends a task to several and then merges the responses.
So the real issue here isn’t whether a benchmark chart has one bar slightly above another. I don’t put much weight on vendor-made benchmark tables that haven’t been independently verified anyway.
The real issue is architectural.
Should you trust a system that combines multiple specialist models, or are you still better off with one strong general purpose model?
That’s the question worth spending time on, especially if you’re building AI products and not just testing demos.
Fugu is not a typical model
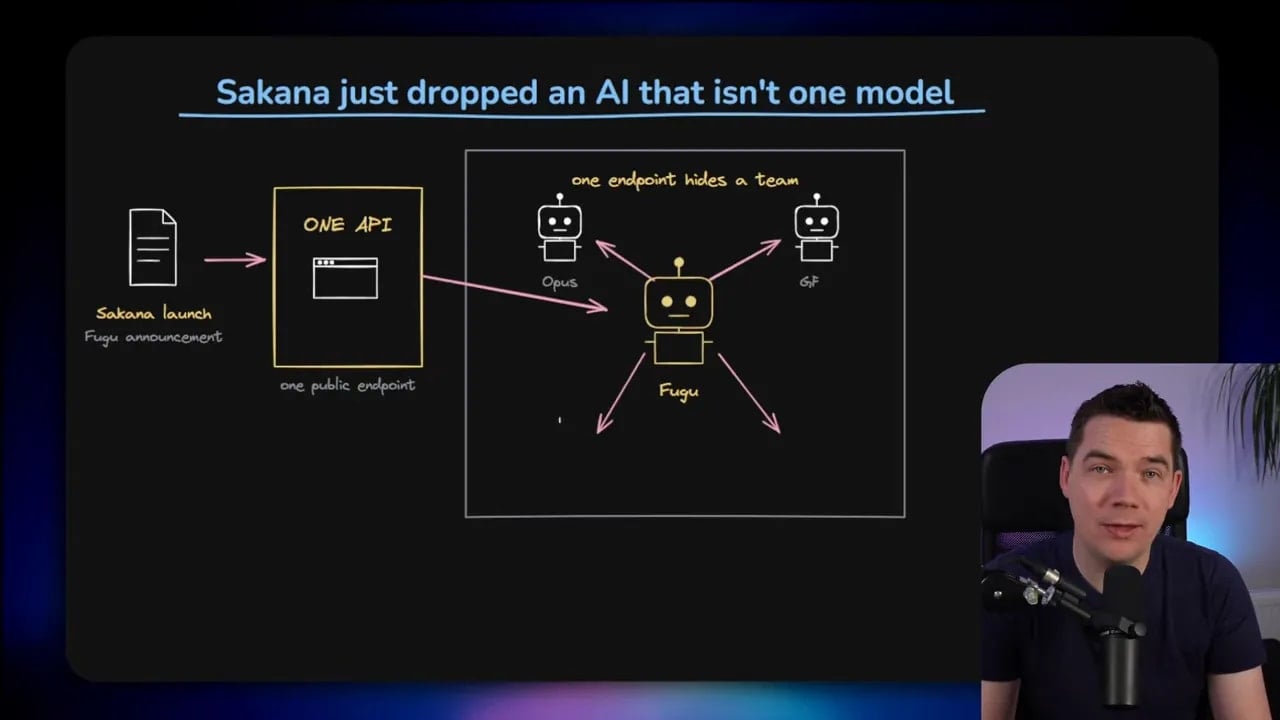
Sakana describes Fugu as a multi-agent system delivered behind a single model endpoint. That distinction matters.
On the surface, you make one API call. Under the hood, the system appears to inspect the task, choose from a pool of frontier models, split the work if needed, check the outputs, and then combine everything into a final answer.
That means you’re not talking to one monolithic model in the normal sense. You’re talking to an orchestrator.
That orchestrator can use specialist models for different parts of a task. One might be stronger at coding. Another might reason better. Another might act as a checker. In harder cases, the system can effectively assemble a team.
Sakana released two versions:
- Fugu, which is the standard version for everyday use
- Fugu Ultra, which is the more expensive version intended for harder tasks
The core pitch is easy to understand. Instead of betting on one model to be good at everything, the system tries to play to each model’s strengths and avoid each model’s weak spots.
That sounds attractive, and to be fair, it’s a sensible idea. The problem is that “sensible” and “better in practice” are not always the same thing.
The benchmark story is less interesting than the architecture story
Sakana claims performance above frontier systems like Fable 5 on several benchmarks. OpenRouter also framed Fusion as a way to beat frontier level performance.
I’m much less interested in the headline than I am in what these systems imply for how AI products will get built.
Benchmarks can be useful, but vendor-produced ones are always tricky. They often reflect the evaluation setup, the prompt shape, the chosen tasks, and the model mix. A small edge on a chart doesn’t tell you much about reliability, cost, controllability, or whether the system is a good choice in production.
That’s why I prefer to step back and look at the underlying architecture patterns.
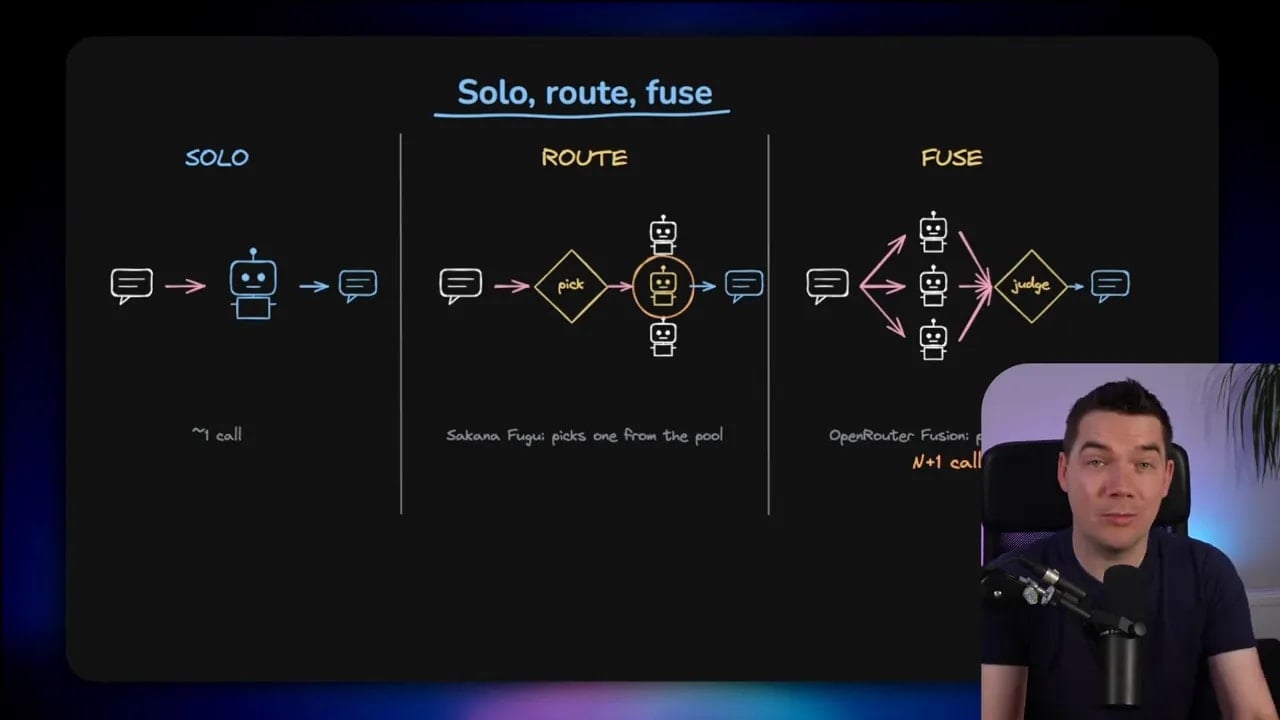
There are really three patterns here: solo, route, and fuse
Once you strip away the branding, both launches fit into a broader set of AI composition patterns. At a high level, I think of them in three buckets.
1. Solo
This is the standard approach most people use today.
You send one prompt to one model from one provider and get one response back.
Yes, that model might do a lot internally. It may break work into steps or use hidden internal processes. But from your side of the API, the pattern is still one request in and one answer out.
This is also the baseline that these multi-model products are usually comparing themselves against.
2. Route
In a routing setup, something first looks at the task and decides which model should handle it.
That “something” could be very simple. It might be a rule-based selector. It could also be much smarter, with planning, retries, validation, and conditional handoffs.
This is the broad pattern that Fugu fits into.
You can think of it as a mixture of models setup. That’s different from a mixture of experts architecture inside a single model. Here, the orchestration happens between whole models.
3. Fuse
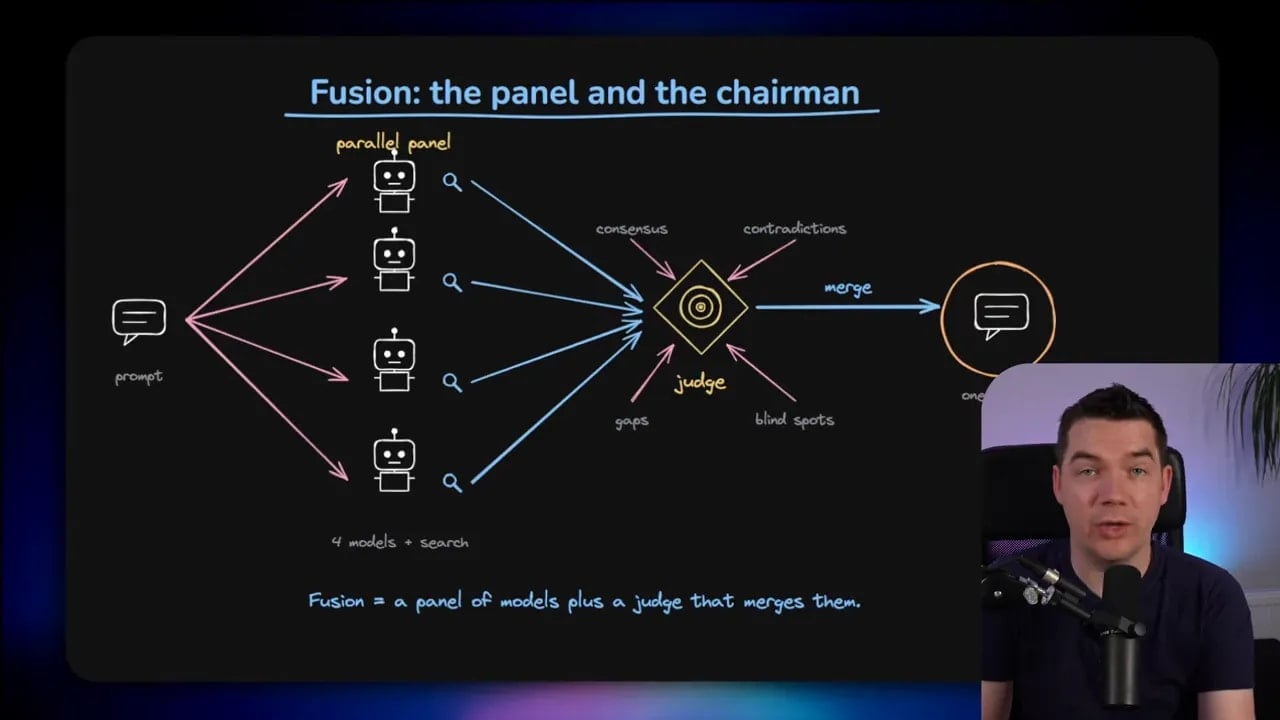
In a fusion setup, you ask several models the same question in parallel and then use another model, or judge, to merge the outputs.
That’s the broad pattern behind OpenRouter Fusion.
Rather than picking one path through the task, you generate a panel of answers and then synthesize them into one final response.
Those three patterns have different tradeoffs in quality, speed, cost, and control. And that’s where things get interesting.
Fugu is a black box orchestrator
Zoom in on Fugu and the shape becomes clear.
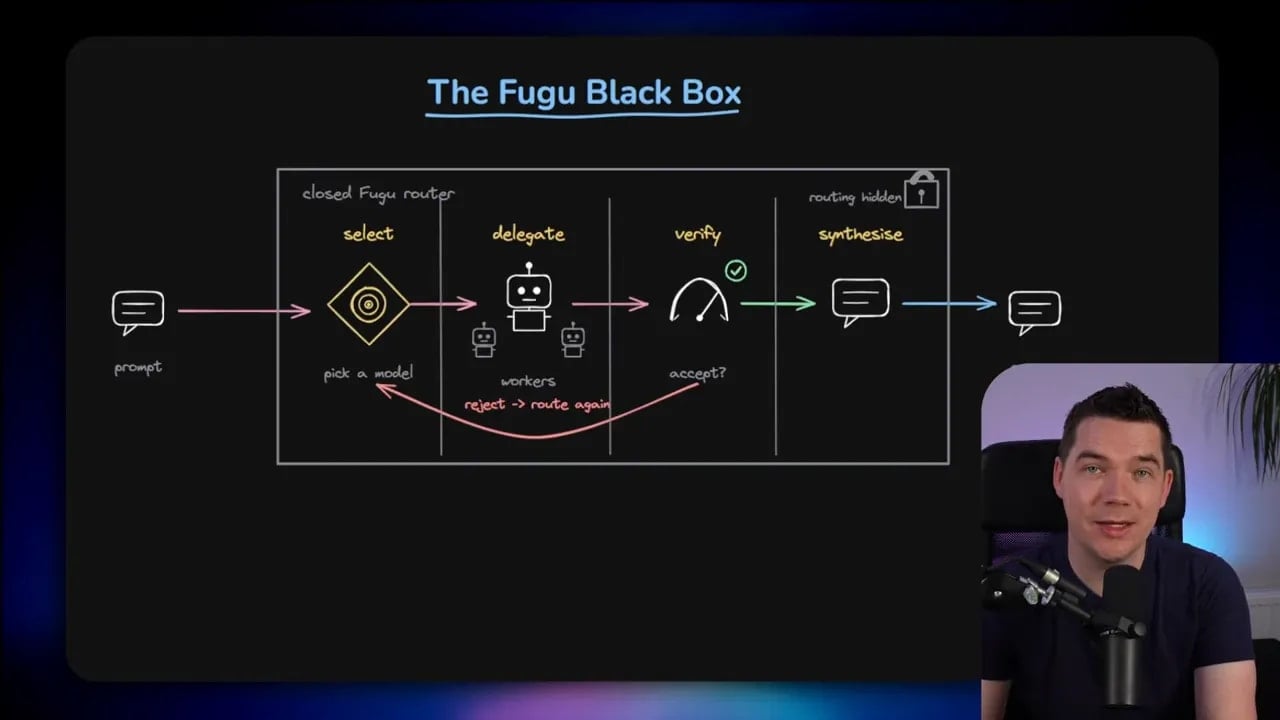
The endpoint accepts a request. Behind that endpoint, the system may:
- Select a model
- Delegate work to one or more workers
- Verify intermediate outputs
- Synthesize a final answer
For a simple task, maybe only one worker gets used. For a harder task, the orchestrator may spin up a larger internal workflow.
Sakana emphasizes that this is trained orchestration, not just a wrapper prompt. That’s important. It means the orchestration logic itself is a learned system.
So are they wrong to call Fugu a model? Not really. But it’s better understood as an orchestration model sitting in front of other models.
The catch is that this orchestration layer is closed.
There are no weights available. The routing logic is hidden. The model choices are hidden. The reasons behind each delegation are hidden.
When you get an answer back, you don’t know:
- Which model actually produced the key parts
- Why that model was selected
- How many internal calls were made
- Where quality checks succeeded or failed
That leaves you trusting a black box to spend your money well and make good architectural decisions on your behalf.
If you’re experimenting, that may be fine. If you’re building production systems, that should make you pause.
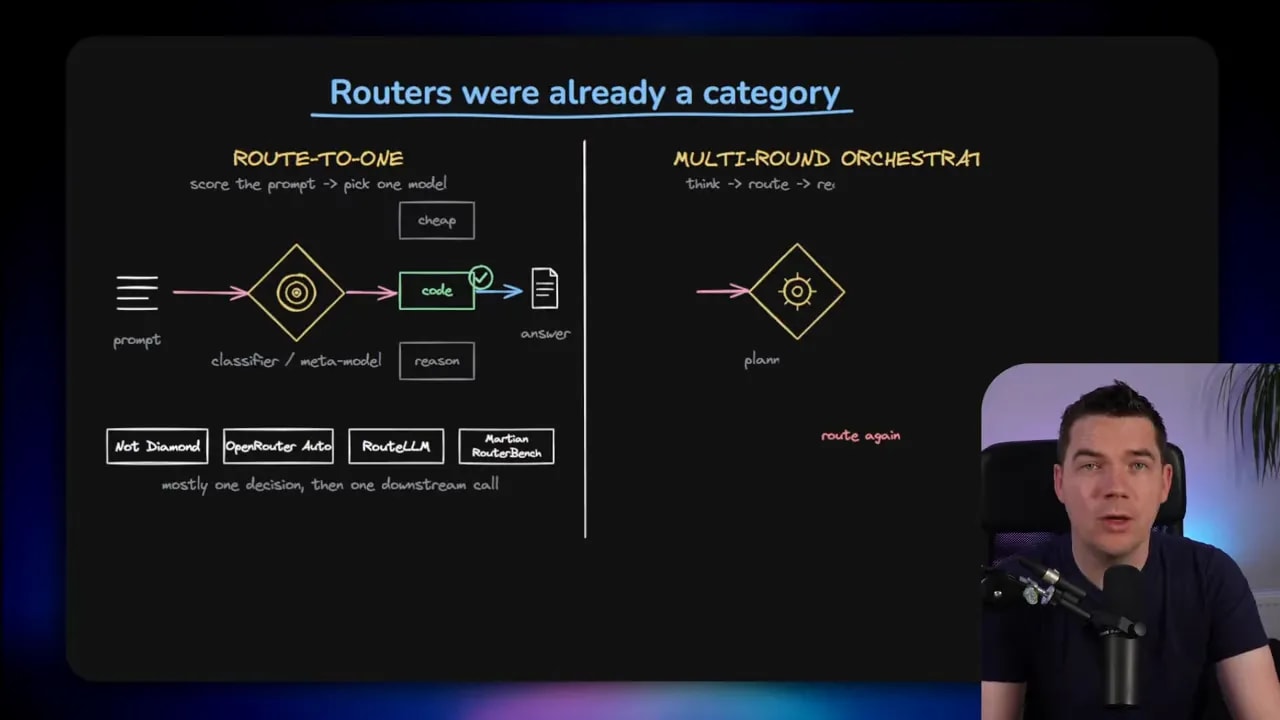
This kind of routing already existed before Fugu
One of the easiest mistakes in AI is confusing a polished product launch with a totally new idea.
Fugu didn’t invent model routing. That category has been around for a while.
Plenty of systems already inspect a task and decide which model should handle it. Some do this for coding agents. Others do it for general model access. In the simplest case, it’s basically air traffic control for prompts. Look at the request, choose a destination, send it there.
What makes Fugu more interesting is the degree of orchestration. It appears closer to a planning system that can route, review, and route again if needed.
That is a more capable pattern than a basic one-shot router.
Still, the key value sits in the orchestrator itself. That’s the part that decides whether the whole setup is smart or wasteful.
And because that logic is closed, you can’t inspect whether the secret sauce is actually good, or whether it’s simply expensive guesswork wrapped in strong marketing.
The research behind Fugu is actually the most useful part
Sakana published research leading up to the Fugu launch, and honestly, this is where the substance is.
The first system is called Trinity. The second is Conductor.
These give a much better sense of how Sakana thinks about orchestration.
Trinity
Trinity uses a small frozen model with a lightweight learned control component. Its job is to manage which model gets used during each turn.
Within a step, it picks one model from a pool and assigns a role. Those roles include things like:
- Thinker
- Worker
- Verifier
The loop continues until the verifier accepts the result.
That should sound familiar if you’ve spent time with agent patterns. It’s basically structured orchestration where generation and checking are separated.
Conductor
Conductor pushes this idea further. It’s a larger model trained to write the workflow itself as text.
That means it can define:
- What the subtasks are
- Which model should handle each subtask
- Which outputs should be visible to later steps
That’s a much more explicit planning approach. Instead of just selecting a model once, the system can write out a whole task flow and decide how information moves through it.

If I had to point to the most important lesson from Fugu, it would be this: the future gains may come less from one giant model getting slightly bigger, and more from better orchestration over strong existing models.
That doesn’t mean every orchestration layer wins. It just means the architectural direction is worth taking seriously.
If you want the original materials, Sakana published the Fugu announcement along with the Trinity paper and Conductor paper.
OpenRouter Fusion makes the opposite bet
Routing says: pick the best model for the job.
Fusion says: ask several models at once and let a judge combine the answers.
That’s almost the opposite move.
Instead of narrowing down to one path, Fusion fans out. It sends the prompt to a panel of models in parallel. Then a judge model reads those outputs and synthesizes a final response.
The judge is expected to look for:
- Areas of agreement
- Contradictions
- Missing pieces
- Blind spots
This is very close to the LLM council pattern that many people in AI have already explored in research and prototypes.
It also overlaps with ideas like:
- LLM Blender
- Mixture of Agents
- LLM council style systems
The difference is that OpenRouter packaged it behind a simple endpoint and productized it.
OpenRouter already had routing through its smart auto mode. Fusion is a step further up the stack. It moves from “which single model should answer this?” to “how do I combine a panel into one answer?”
You can read OpenRouter’s own framing in its Fusion announcement or look at Fusion itself.
Fusion sounds smart, but the cost shape changes fast
This is where the practical tradeoff hits hard.
Fusion is expensive by design.
Every request may involve:
- Multiple model calls in parallel
- Another model acting as the judge
- Extra tokens generated by every participant
So even before you talk about quality, you’ve changed the cost shape.
With a route pattern, the ideal goal is to choose the right model and avoid unnecessary calls. With a fuse pattern, cost multiplies almost immediately.
That matters even more if you’re paying raw API rates.
Subscription tools often give people a very different mental model of cost. You have a monthly plan, you work inside usage windows, and if you’re smart about it, you can get a lot done without thinking about every token.
API platforms are different. Every call is metered. Every extra branch in your architecture shows up in the bill.

So even if a fused answer is slightly better on average, you still have to ask whether that gain is worth the extra spend and complexity.
There’s real research behind fusion, but the findings aren’t one-sided
Fusion-style systems do have research behind them. The broad argument is that diversity helps. Different models make different mistakes, so combining them should create a better final answer.
That is the central promise behind mixture-of-agents style systems.
But there’s an important catch.
A Princeton paper pushed back on the assumption that mixing different strong models always helps. The result was basically this: if you take your single best model and sample it multiple times, then merge those responses, that can outperform a mixed panel of different models.
Why would that happen?
Because there is a quality versus diversity tradeoff.
Diversity sounds good in theory. Yet if you bring weaker models into the room just to increase variety, they can lower the overall quality of the final merged result.
In plain English, you can’t always out-vote your best player by inviting more average ones onto the team.
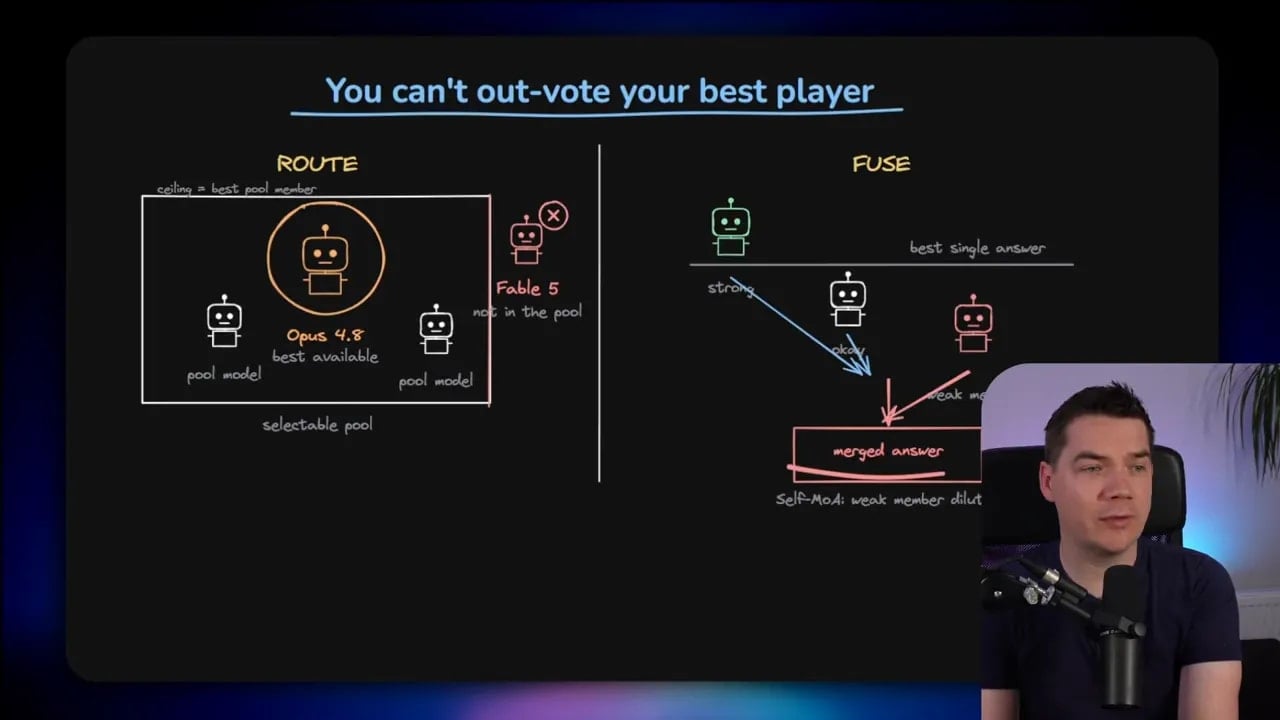
That idea matters a lot.
If one model is clearly strongest on a task, routing to that model should beat a panel that includes weaker participants. A judge can try to clean things up, but the weaker answers still enter the synthesis process.
This is one reason I’d expect routing to be the more promising architecture in many real product settings.
Routing should win on specific tasks. Fusion may win on broad averages.
If I compare the two patterns directly, my expectation is fairly simple.
On a specific task, good routing should usually do better.
Why? Because the whole point is to choose the best available model for that task.
If you’ve correctly identified the strongest model, why would merging weaker outputs improve it?
Across many different tasks, fusion or multi-model orchestration may lift the average baseline.
That’s because the strength of the system comes from coverage. Different models may shine in different places. Across a wide enough spread of tasks, a composition system can perform more consistently than a single fixed choice.
But even if that is true, two questions still remain:
- How much better is it really?
- What does that improvement cost in money and control?
Those two questions matter far more than a press release headline.
Sakana’s sovereignty argument sounds strong, but it has a weak spot
One part of Sakana’s messaging focused on geopolitical risk and dependence on specific model vendors.
The broad claim was that orchestrating across many global models creates a more resilient path and supports AI sovereignty. That sounds persuasive, especially after seeing access restrictions and export controls affect major providers.
But here’s the issue.
If you choose Fugu, you haven’t removed vendor dependence. You’ve moved it.
Before, you were dependent on a model provider. Now you’re dependent on a closed orchestrator that depends on those model providers.
That’s not the same as true sovereignty.
It’s more like shifted lock-in.
You no longer control the model choice, and you also don’t control the orchestration logic deciding how those models are used.
If access to major underlying models disappears, the quality of the orchestrated product would obviously be affected. You may not even know which internal pieces changed.
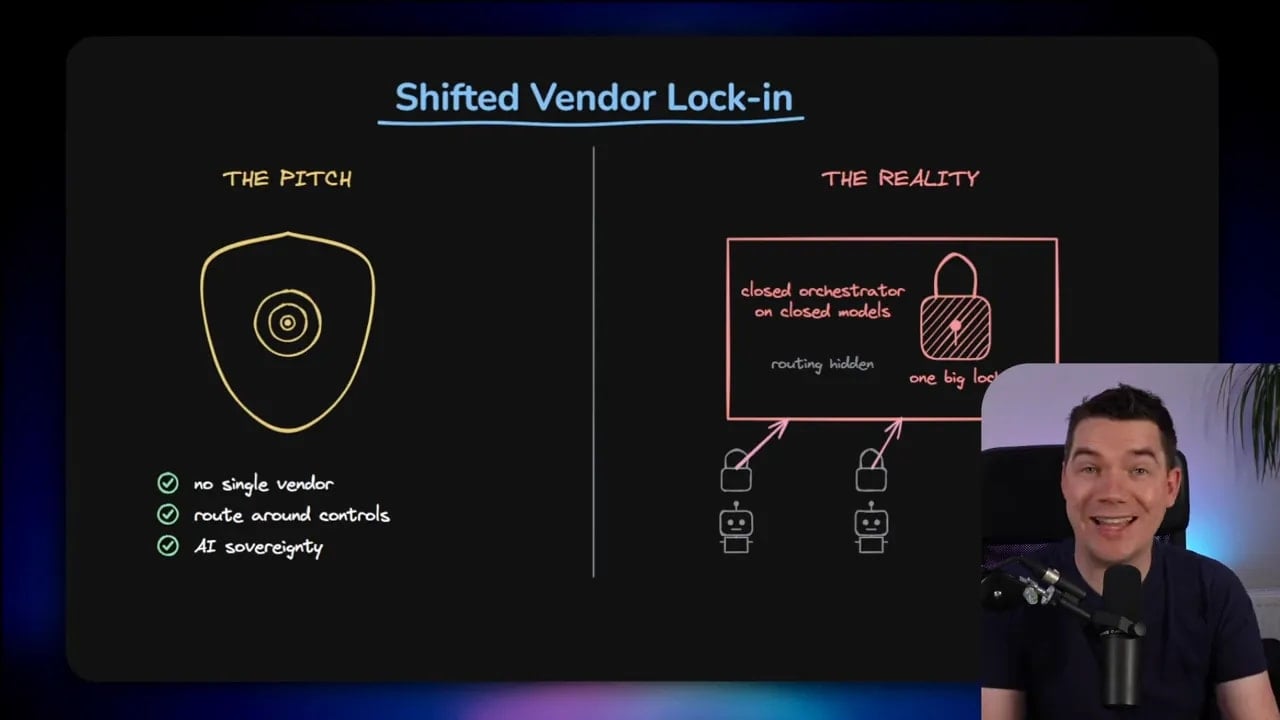
So while the marketing pitch talks about resilience, the practical reality is still heavy dependence on a closed system you don’t control.
Why I’d rather build this architecture myself
This is where my opinion lands pretty clearly.
If I genuinely want a router or fusion style architecture in a product, I’d rather build it myself.
That doesn’t mean I’d reinvent every piece from scratch in all cases. It means I want control over the parts that matter:
- Which models are in the pool
- How tasks get classified
- When to route versus when to escalate
- What validation criteria get applied
- How retries work
- Which outputs can feed later stages
- How cost caps and guardrails are enforced
That level of control matters a lot once you leave demo land and start shipping actual AI features.
A black box endpoint may save time early on. But it also limits your ability to debug quality issues, explain behavior, optimize cost, and swap providers when conditions change.
The most useful lesson for builders: orchestration is becoming the real frontier
I think the biggest takeaway from both Fugu and Fusion is this:
The frontier may be shifting from “which single model is best?” to “how should strong models be combined?”
That’s a much more interesting question than whether one launch beats another on a benchmark.
For non-technical teams, this change may still look like just another model release. For builders, it changes the whole frame.
You’re no longer choosing only a provider. You’re choosing an architecture.
And architectures have consequences.
A solo approach gives you simplicity. A route approach gives you specialization and control if built well. A fuse approach gives you breadth and consensus, but often at a much higher cost.
None of these is universally best.
Still, if I’m building something serious, I care less about branded wrappers and more about the actual decision logic sitting underneath.
How I’d think about choosing between solo, route, and fuse
If you’re trying to reason about these patterns in a practical way, this is the lens I’d use.
Use solo when:
- You want the simplest setup
- One model is already good enough
- Speed matters more than orchestration
- You want predictable behavior and easier debugging
Use route when:
- Different tasks clearly fit different models
- You want to optimize quality per task
- You need cost-aware control
- You can define validation logic and escalation paths
Use fuse when:
- You genuinely benefit from multiple independent perspectives
- The task is high value enough to justify extra cost
- A synthesis step can add real value
- You can tolerate more latency and complexity
In many cases, I suspect the best systems will mix these patterns rather than pick only one.
You might start with a solo model for normal requests. Then route hard requests to specialists. Then reserve fusion for the few cases where multiple opinions are worth paying for.
That kind of layered setup is usually more sensible than treating every request like it needs a committee.
What these launches mean for AI products
If you build AI products, these launches matter because they push the market conversation up a level.
The old comparison was mostly model versus model.
The new comparison is increasingly system versus system.
That means the value may sit in:
- Task decomposition
- Model selection
- Verification
- Synthesis
- Evaluation logic
- Cost control
In other words, the moat moves from the raw model to the architecture wrapped around it.
That’s exactly why I find Fugu interesting even though I’m skeptical of the benchmark framing. The underlying direction is important.
Orchestration is becoming a first-class product decision.
The practical risk of abstraction
There’s one last point worth making.
Abstraction is great right up until it hides the thing you most need to control.
Both Fugu and Fusion simplify access. That’s the appeal. One endpoint. Cleaner integration. Less plumbing for the builder.
But the more these systems hide, the less you can shape the behavior that actually determines quality and cost.
For small experiments, abstraction is convenient.
For serious products, abstraction can become a tax.
You pay for it in opacity. You pay for it in weaker observability. You pay for it when a result is wrong and you can’t see why the workflow made the choices it did.
That is why I keep coming back to the same position: the pattern is valuable, but the black box is the problem.
