

Setting up a basic AI agent in n8n that queries a vector store is straightforward. However, ensuring that the agent consistently delivers relevant, high-quality answers takes some advanced techniques. One of the easiest and most effective ways to improve the accuracy of your retrieval-augmented generation (RAG) agent is by using re rankers. With the release of n8n version 1.98, support for Cohere’s 3.5 re ranker was introduced, and I want to walk you through what re rankers are, how they enhance AI agents, and how you can use them effectively within n8n.
In addition to explaining the basics of re ranking, I’ll highlight some limitations of the current implementation and share ways to work around them. I’ll also show you how to combine re ranking with other advanced techniques like hybrid search and metadata filtering to significantly boost the accuracy of your AI agents.
Understanding Vector Search in RAG Agents
To grasp the value of re ranking, it’s important first to understand how vector search works within a RAG agent. Typically, RAG agents search through multiple documents to find relevant information in response to a user query.
The process starts with ingesting documents into a vector store. These documents are divided into smaller segments or chunks. Each chunk is then transformed into a numerical representation using an embedding model. These numbers, or vectors, capture the semantic meaning of the text. The vectors are stored in a vector database such as Pinecone or Supabase.
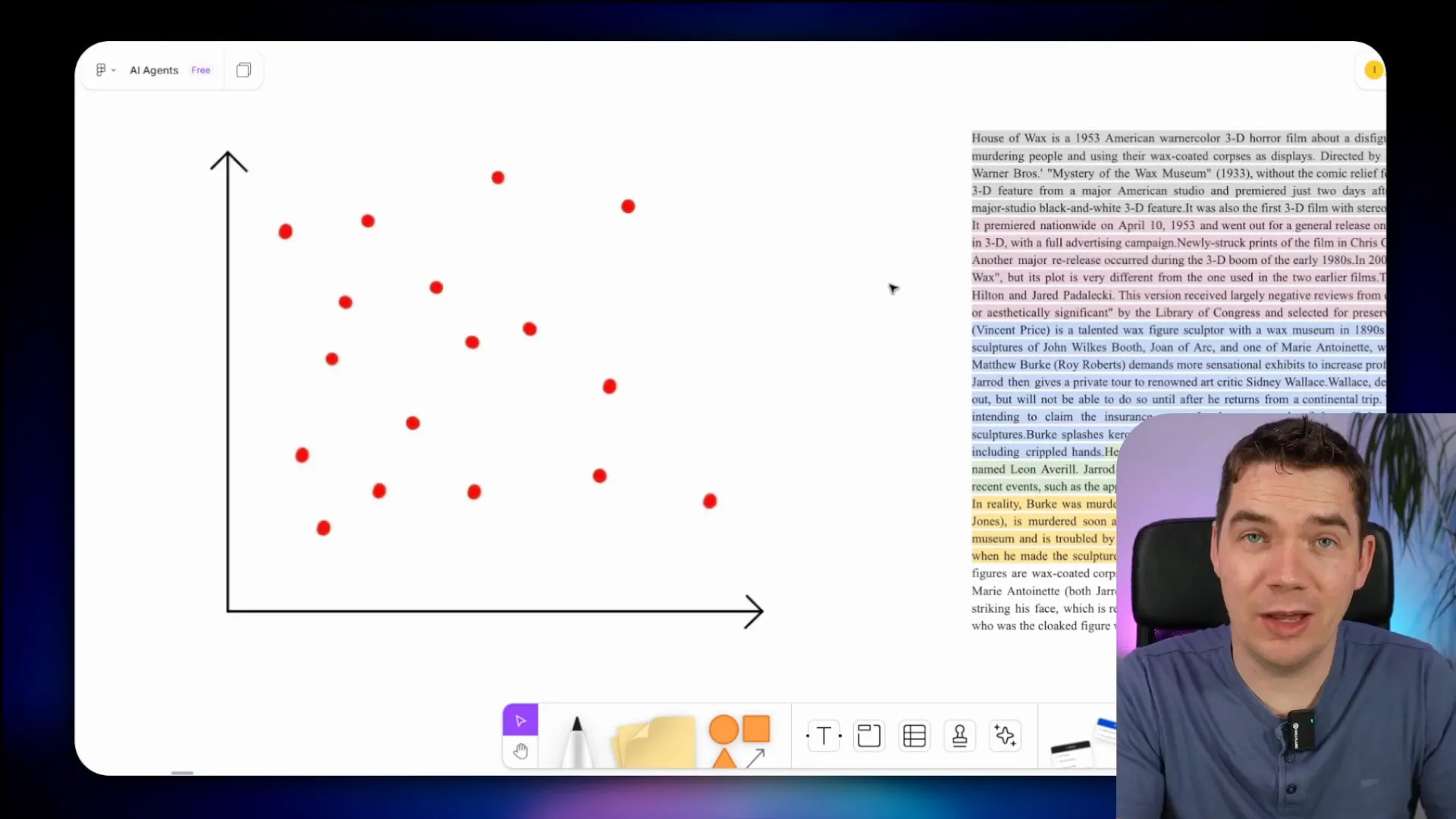
Imagine a document broken into color-coded segments. Each segment is passed through an embedding model and converted into a vector point. These points are plotted in multi-dimensional space (often visualized in two or three dimensions for simplicity). For example, one paragraph might correspond to one vector point, another paragraph to a different point, and so on.
When a user asks a question, the agent converts that question into a vector using the same embedding model. It then queries the vector database to find chunks with vectors closest to the query vector. This proximity indicates semantic similarity.
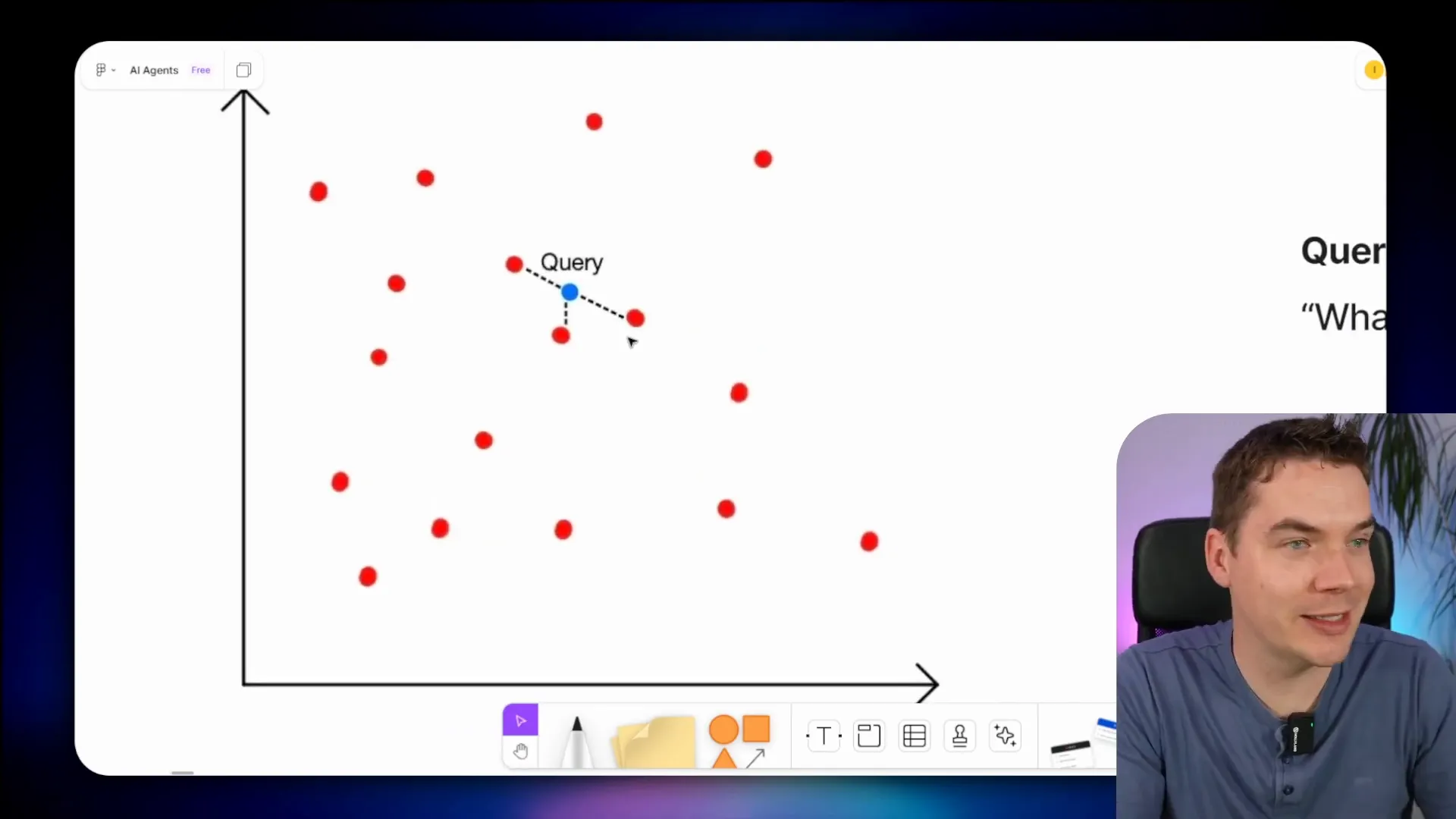
For instance, if the question is “What rules govern the power unit of an F1 car?”, the question is transformed into a vector and plotted in the same space with all the chunk vectors. The system then identifies the chunks closest to the query vector. These top chunks are sent along with the question to a large language model (LLM). The LLM uses this contextual information to generate a grounded, relevant response.
The Challenge of Information Loss in Vector Search
While vector search enables powerful semantic retrieval, it’s not perfect. One major challenge is information loss caused by compressing the meaning of a chunk of text into a single vector point. This compression can sometimes lead to the top results returned by the vector database not being the most relevant.
To try to sidestep this issue, a common approach is to increase the number of results returned from the vector store. Instead of retrieving three chunks, you might ask for six, nine, or even fifteen. The idea is that increasing the number of chunks might improve the likelihood of including the most relevant information.
However, this approach faces a serious limitation: the context window of the LLM. Each LLM has a fixed maximum length of input it can process at once. Providing too much information in the prompt leads to what’s called “context stuffing.” This doesn’t always help the model recall information better; in fact, it can degrade performance.
Tests like “needle in the haystack” experiments show that LLMs tend to prioritize information at the start and end of the prompt while neglecting the middle content. Although models are improving, this “lost in the middle” problem remains a challenge.
If you want to explore pushing the limits of context windows, I created a video on cache augmented generation, where you can stuff entire documents into prompts. But generally, stuffing more data into the prompt is not the best solution.
Re Ranking: A Two-Stage Retrieval Solution
The best solution to the information loss problem is to maximize both retrieval recall and LLM recall. This is where re ranking comes in.
Re ranking is a second stage of retrieval that refines the initial vector search results. Let’s break down how it works:
- First, you query the vector store to retrieve a larger set of candidate chunks (for example, 25 chunks) that are potentially relevant.
- These candidates are then sent to a re ranker, which scores and ranks them based on their relevance to the query.
- The re ranker returns a smaller, highly refined set of top chunks (for example, the top 3) that are most relevant.
- Only these top-ranked chunks are passed to the LLM as context, along with the user’s query.
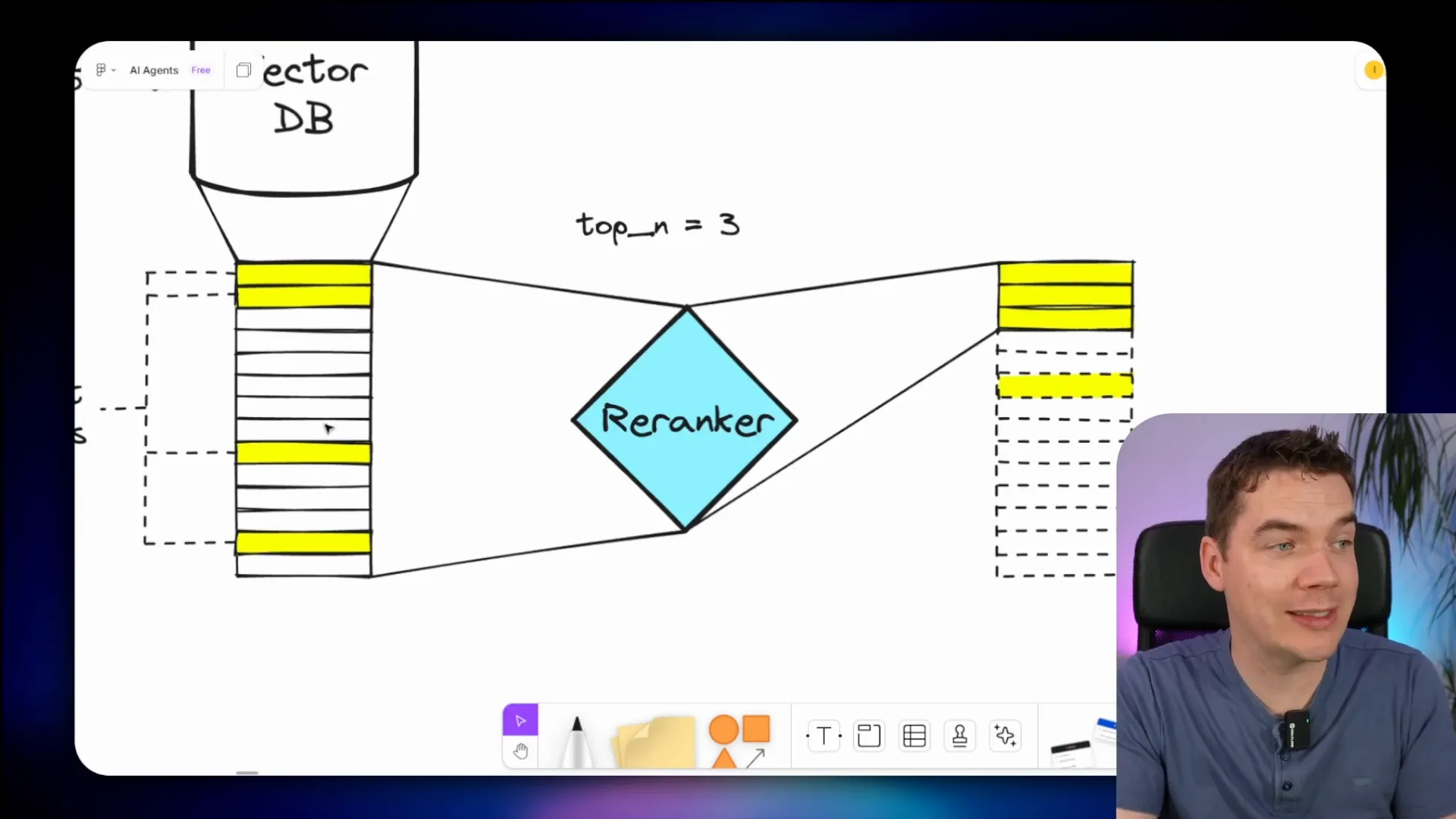
This method maximizes retrieval recall because you can fetch a broad set of candidates from the vector store. At the same time, it maximizes LLM recall by limiting the context to only the most relevant chunks, avoiding prompt overload.
Why Are Re Rankers More Accurate?
Embedding models used in vector search are called “bi-encoders.” This means that the document chunks and the query are embedded separately and independently. The embeddings might even be created months apart. The similarity is computed by measuring the distance between these two isolated vectors.
This approach is very fast and scales well because all the heavy lifting of embedding documents is done upfront. However, this independence causes some loss of accuracy since the model can’t consider the query and document together.
Re rankers, on the other hand, are “cross-encoder” models. They take both the document chunk and the query as input simultaneously and generate a similarity score based on their interaction. This joint processing allows for much more precise relevance scoring.
The trade-off is that re rankers are significantly slower and less scalable. You can’t realistically pass tens of thousands of chunks into a re ranker for every query. That’s why the two-stage retrieval approach—first a fast vector search, then a focused re ranking—is so effective.
Cohere’s ReRanking Models: Industry Standard
Cohere’s re ranking models, including version 3.5, have become the de facto standard in the industry. They can be deployed on cloud platforms like Azure, Google Cloud, and Amazon Bedrock, or accessed directly through Cohere’s API.
Benchmarks show that adding re ranking to an AI agent can dramatically improve the accuracy and relevance of its responses. This is especially true in complex retrieval tasks where precision matters.
Using the New n8n Cohere ReRanker Node
With n8n version 1.98 and later, you now have native support for Cohere’s re ranker. Setting it up is simple if you already use n8n for AI agents querying a vector store like Supabase.
Here’s how I set up a basic AI agent using the new feature:
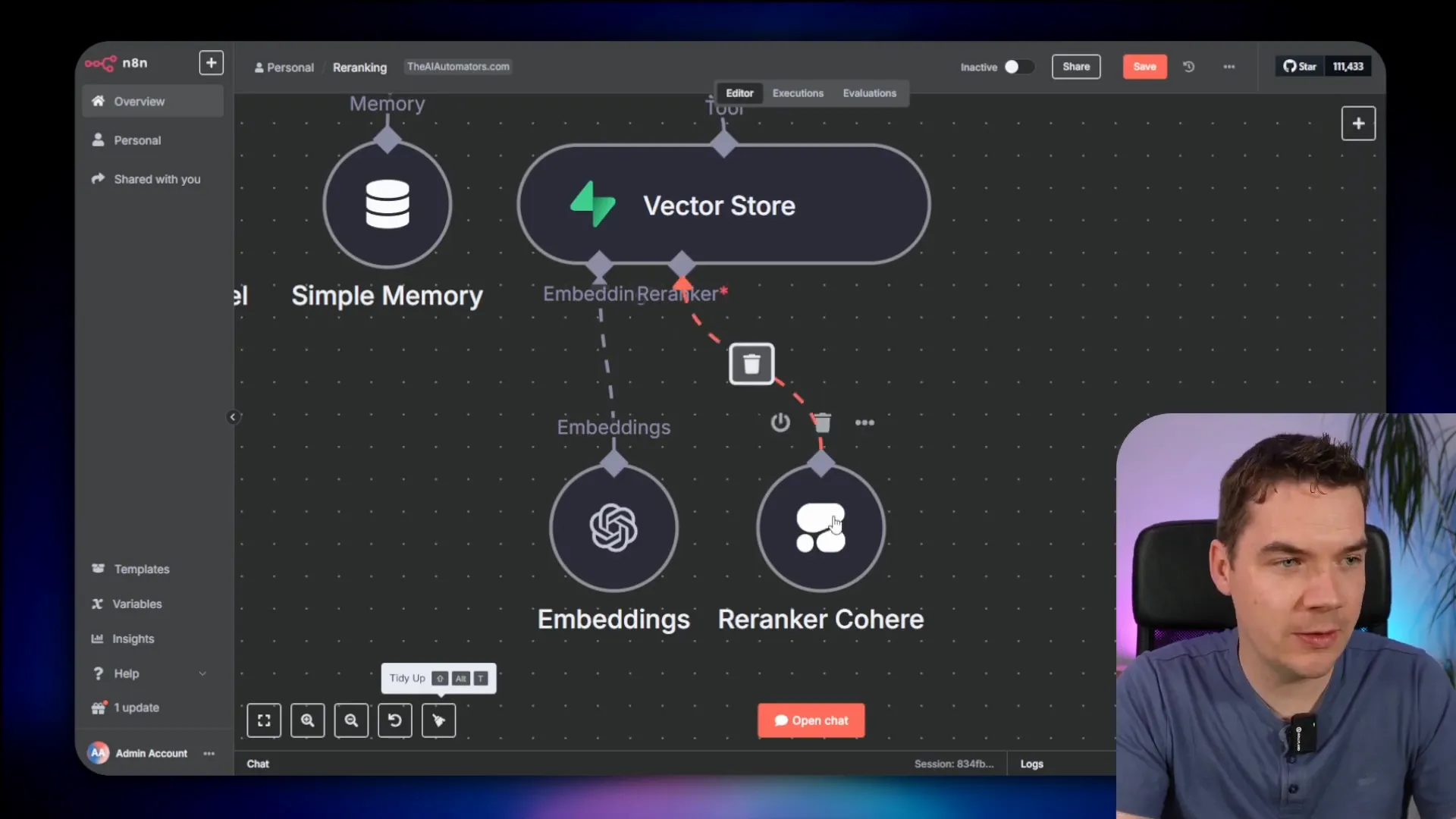
- I started with a chat trigger node to receive user queries.
- Next, I used a Supabase vector store node. In the node’s settings, there’s a new “Re rank results” toggle. When enabled, it adds a new output leg from the vector store node that you can connect to a re ranker node.
- Currently, Cohere is the only re ranker supported, so I added the Cohere node and connected it to the vector store node.
- To authenticate, I created a Cohere account, generated an API key, and added it to the credentials in n8n.
- In the Cohere re ranker node, I selected the latest model version, 3.5.
When I ran a test query, “What rules govern the power unit of an F1 car?”, the process was as follows:
- The chat message was received by the agent.
- The query was converted into an embedding vector and sent to the Supabase vector store, which returned the top 20 most relevant chunks.
- These 20 chunks, along with their metadata, were sent to the Cohere re ranker node.
- Cohere scored and ranked the chunks, returning the top 3 most relevant results with relevance scores.
- The top 3 chunks were passed as context to the LLM, which generated a detailed and accurate answer based on this focused information.
Metadata in Re Ranking: A Double-Edged Sword
One interesting observation is that the metadata associated with each chunk is also passed to the Cohere re ranker. This can be a positive or negative factor depending on your data.
If your metadata is clean, relevant, and concise, it can help the re ranker improve chunk ranking because metadata is not part of the vector embedding and hence not considered during vector search.
However, if your metadata contains irrelevant or noisy information, it can confuse the re ranker and reduce accuracy. At the moment, n8n doesn’t provide an option to enable or disable passing metadata to the re ranker, which is a limitation I’ve flagged for improvement.
Current Limitations in n8n’s Re Ranking Implementation
Another limitation is that the number of results returned by the re ranker is hardcoded to three. You can increase the number of chunks retrieved from the vector store, but the re ranker node will only return the top three results.
For example, if you want to maximize retrieval recall by fetching the top 200 chunks from the vector store and then re rank the top 10 among those 200, there is currently no way to do this in n8n.
I have raised this issue on n8n’s GitHub repository to request an override field that allows customizing the number of re ranked results. This flexibility would help optimize agent accuracy by tuning how many chunks are passed to the LLM.
Combining Re Ranking with Hybrid Search and Metadata Filtering
Beyond the basic re ranking setup, I created a more advanced workflow that integrates hybrid search and metadata filtering to get even better results.
Here’s how it works:
- Instead of using the vector store node directly as a tool, I trigger a sub workflow dedicated to retrieval.
- The sub workflow prepares metadata filters. For example, in a motorsports dataset, each chunk might be tagged with metadata like “Motorsport category” or “Year.”
- These filters allow querying subsets of vectors, which improves precision by narrowing down the search space.
- The user query is embedded using OpenAI’s text-embedding-ada-002 model.
- A hybrid search is performed in Supabase, combining vector search with full-text search on the query text and applying the metadata filters.
- The hybrid search returns a set of matching chunks, and these are then sent to the Cohere re ranker via an HTTP request node in n8n.
- The re ranker scores the chunks and returns the top results with relevance scores.
- Finally, the top-ranked chunks are passed back to the AI agent for response generation.
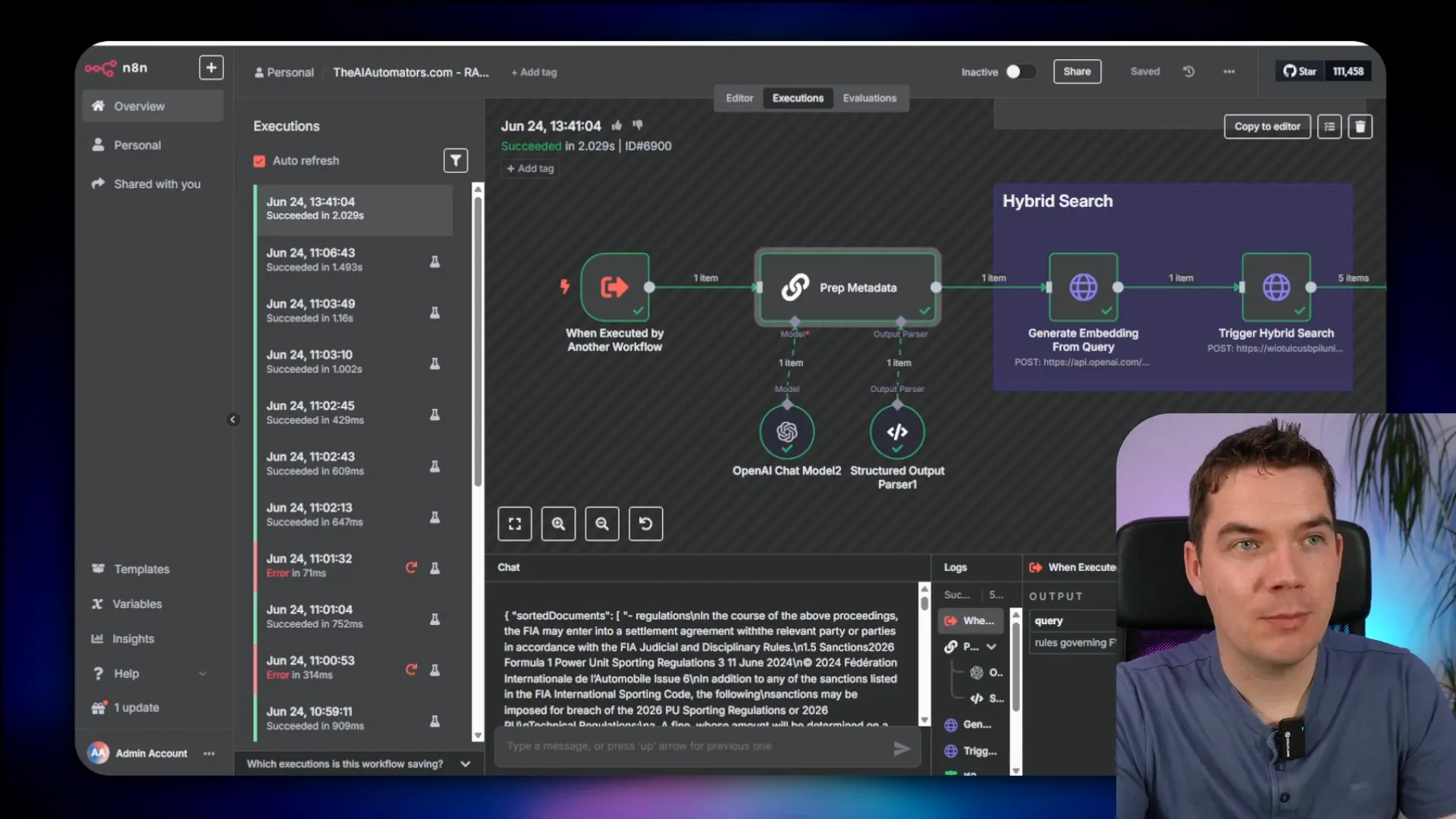
This approach leverages the strengths of multiple retrieval techniques. Hybrid search improves recall by combining semantic and keyword matching, metadata filtering narrows the scope for better precision, and re ranking refines the results to maximize relevance before passing them to the LLM.
Benefits of This Multi-Faceted Approach
- Higher accuracy: Filtering by metadata ensures only relevant documents are considered.
- Improved recall: Hybrid search captures more relevant chunks that might be missed by vector search alone.
- Focused context: Re ranking reduces noise by selecting the most relevant chunks for the LLM’s context.
- Scalability: The two-stage retrieval keeps the pipeline efficient by limiting the number of chunks the re ranker processes.
This workflow is part of a broader set of advanced RAG techniques I’ve demonstrated in my hybrid search and RAG masterclass videos.
Final Notes on Using Re Ranking in n8n AI Agents
Re ranking is a powerful upgrade for any n8n AI agent that leverages vector stores. It addresses the key problem of information loss in vector search by providing a second, more precise ranking step.
The Cohere re ranker integration in n8n is easy to set up and already delivers significant improvements in response accuracy. It fits perfectly into two-stage retrieval workflows and can be combined with hybrid search and metadata filtering for best-in-class results.
While the current implementation has some limitations—such as the fixed number of re ranked results and mandatory metadata passing—these are actively being addressed. In the meantime, you can implement workarounds by building custom sub workflows and HTTP request nodes to achieve greater flexibility.
Mastering re ranking will help you build AI agents that provide more relevant, trustworthy, and high-quality answers, whether you are automating internal tools or building customer-facing products.
