

GraphRAG is one of the most effective ways to improve the accuracy and reliability of AI agents. Many people hesitate to use knowledge graphs because they seem complicated to set up and hard to maintain. In this article, I’ll show you how to quickly set up your own knowledge graph, automatically populate it from your documents, and connect it with your AI agents in n8n within minutes.
I’m going beyond what n8n offers out of the box by integrating an open-source system called LightRAG. Despite what you might expect, the setup is easy, and anyone can do it. I’ll explain what a knowledge graph is, why GraphRAG yields better responses than traditional retrieval augmented generation (RAG), and walk you through a demo of LightRAG’s document ingestion and processing. Then, I’ll show you step-by-step how to connect your knowledge graph expert to your AI agents in n8n to produce much more detailed and comprehensive answers. Finally, I’ll share how I built this into our advanced n8n RAG system, which includes enhanced ingestion pipelines, hybrid search, and re-ranking to deliver highly accurate AI responses.
This article is packed with insights and practical guidance to get your AI agents smarter and more reliable using GraphRAG.
Understanding Knowledge Graphs
To understand GraphRAG, it’s essential to first grasp what a knowledge graph is. Essentially, a knowledge graph is a structured way to represent information about real-world entities and their relationships. Think of it as a vast mind map that connects various concepts, people, places, and things.
For example, consider a knowledge graph centered around Steve Jobs. It shows that Steve Jobs was born in San Francisco, which is located in California. He founded Apple, which also has its headquarters in California. Apple created the iPhone, launched in 2007. These are entities—Steve Jobs, San Francisco, California, Apple, iPhone—connected by relationships such as “born in,” “founder of,” and “created.”
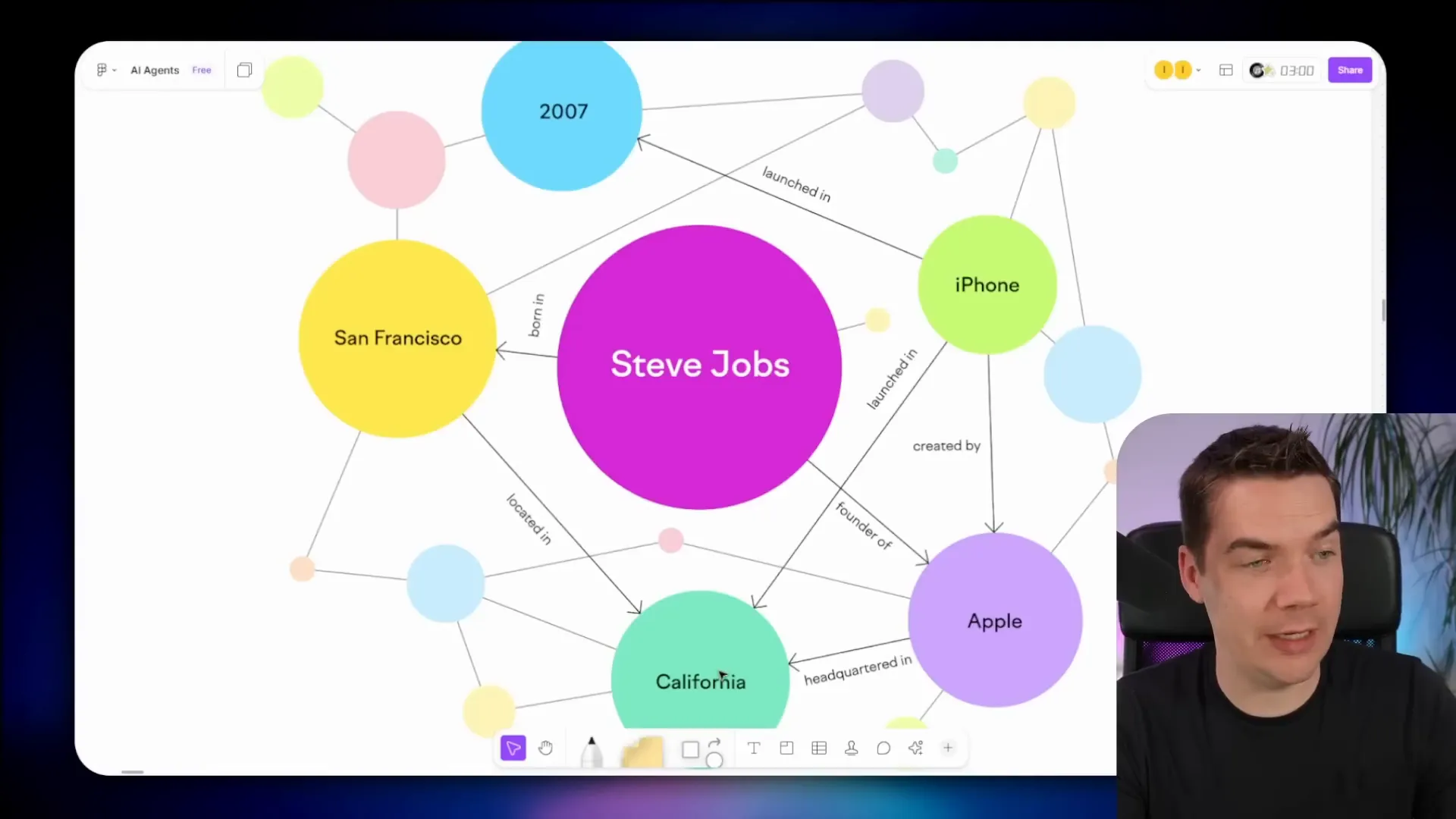
Knowledge graphs make it easier to identify patterns and understand how data points relate to each other. Google’s knowledge panel on the right side of search results is a well-known example of a knowledge graph in action. If you Google Steve Jobs, you’ll see a panel that summarizes his birthplace, professional roles, and other key facts, all linked together.
There are three key concepts to understand with knowledge graphs:
- Nodes or Entities: These are the items or concepts in the graph, represented as circles. Examples include people, courses, organizations, or places.
- Edges or Relationships: These define how nodes are connected. For example, a person “teaches” a course or “lives in” a city.
- Properties: These are attributes that describe nodes, such as a course being a computer science course taught in English, or a person’s name.
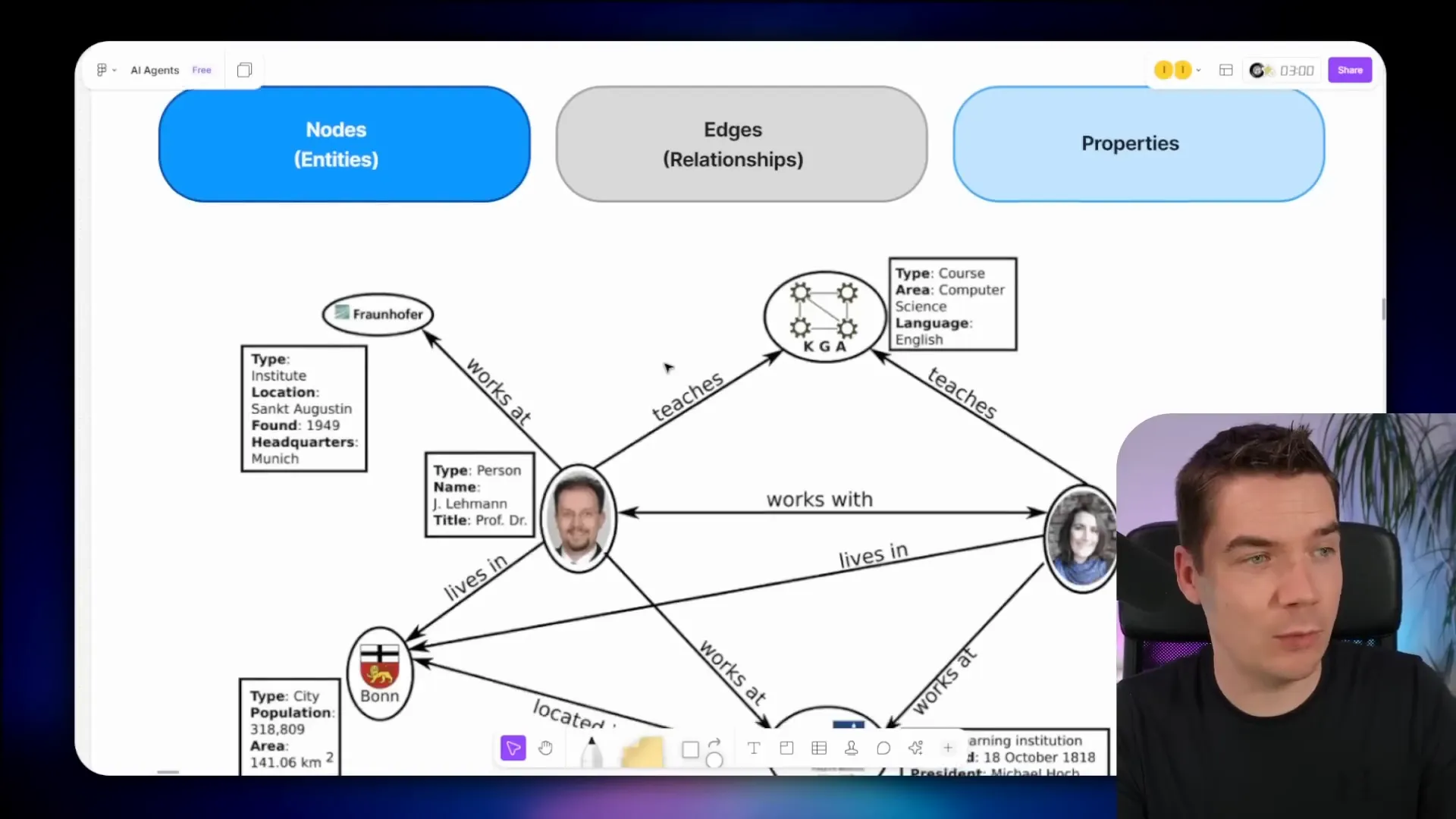
This structure offers huge flexibility to model data in a meaningful way. Traditionally, creating knowledge graphs was a labor-intensive task. It required manual schema design and data population, which limited adoption.
Machine learning and natural language processing (NLP) have helped automate graph generation for years. Now, with large language models (LLMs), it’s straightforward to automatically extract nodes, edges, and properties from unstructured documents. This automation is where GraphRAG really shines.
Graph Databases: The Backbone of Knowledge Graphs
All the nodes, relationships, and properties need to be stored efficiently. That’s where graph databases come in. Neo4j is one of the most popular graph databases. These systems are built to store and query data represented as networks of relationships, unlike traditional relational databases.
Querying a graph database uses graph query languages, with Cypher being a prominent example for Neo4j. However, you don’t need to learn Cypher to get started with GraphRAG solutions, as most tools abstract away the complexity.
What is GraphRAG?
GraphRAG stands for Retrieval Augmented Generation using a knowledge graph. It’s an evolution of traditional RAG, which combines retrieval of relevant documents with generation of responses using LLMs.
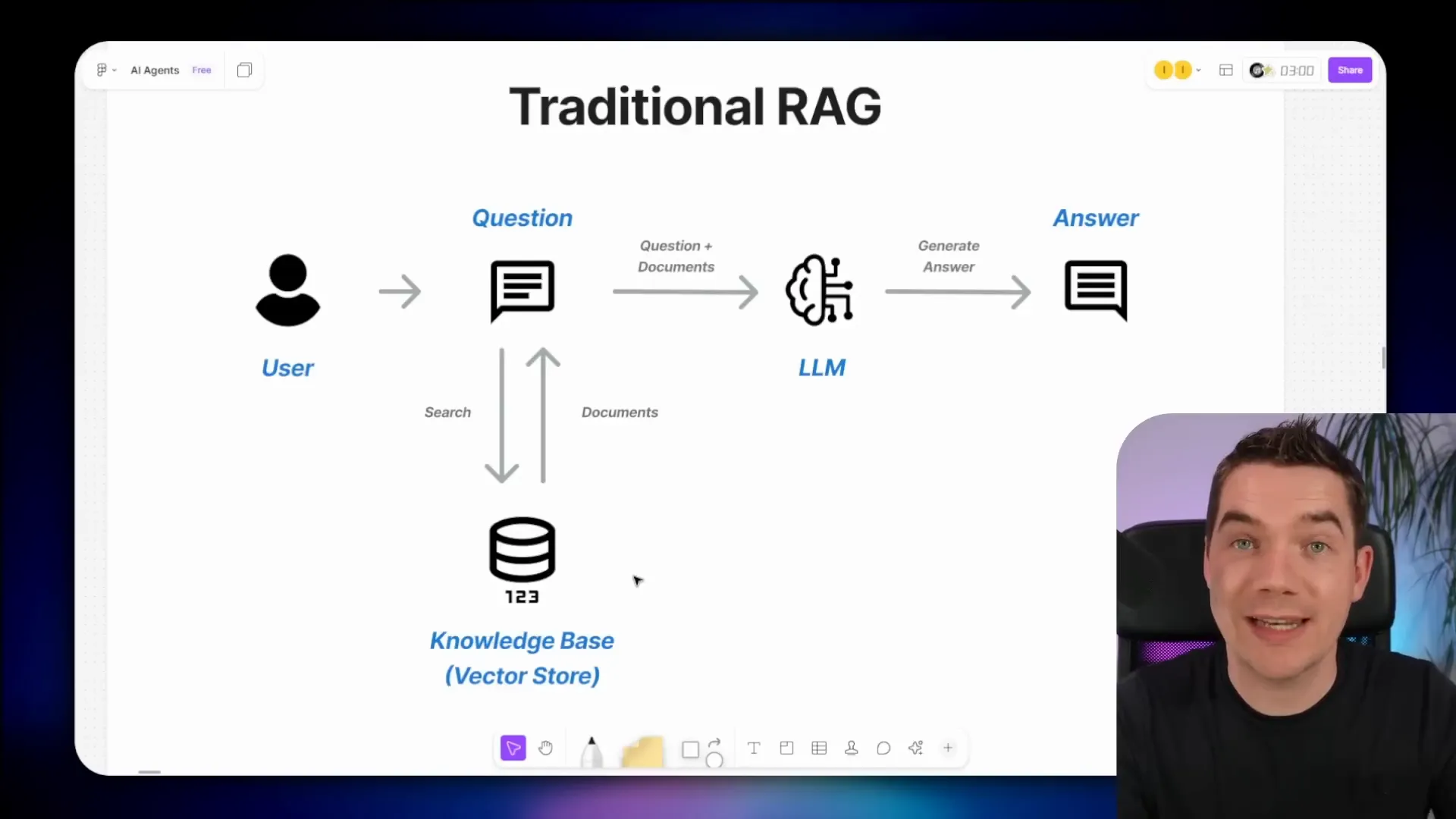
In a traditional RAG workflow, a user asks a question. The system searches a vector store (a database of document embeddings) for the most semantically relevant chunks of text. These chunks, along with the original question, are sent to an LLM to generate an answer.
GraphRAG adds a knowledge graph into this process. First, it constructs a knowledge graph from your documents by extracting entities and relationships using an LLM. These are stored in a graph database. Then, when a user asks a question, the system not only queries the vector store for relevant chunks but also queries the knowledge graph for relevant entities, relationships, and their neighbors.
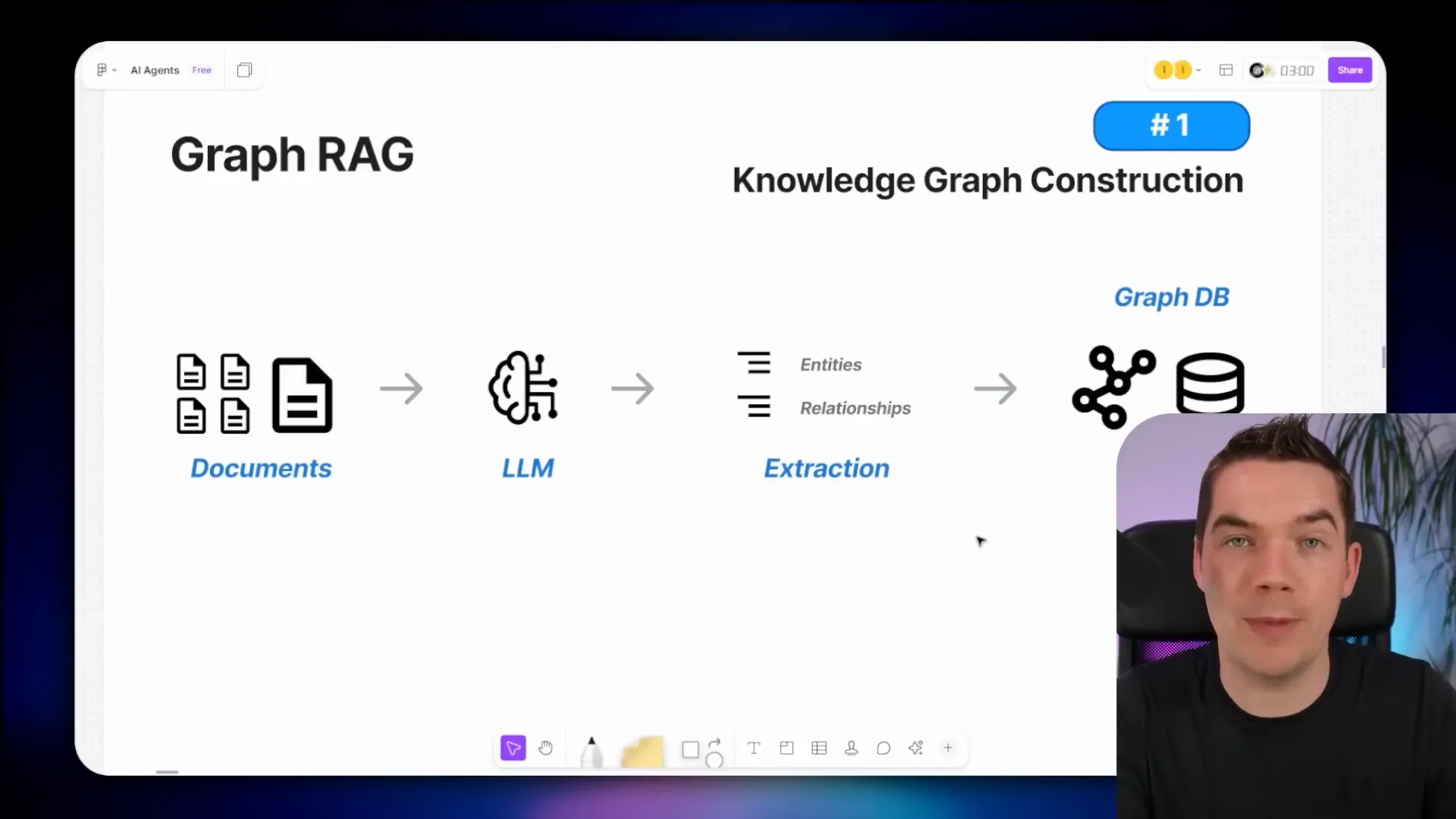
The combined information—the question, document chunks, and graph context—is fed into the LLM to produce a more accurate and comprehensive answer.
Why Use GraphRAG?
GraphRAG solves several problems inherent in semantic search and traditional RAG systems.
- Lost Context: Semantic search often retrieves fragmented chunks of documents independently. For example, if a document page contains insurance policy exclusions, semantic search might return a few paragraphs out of context. This can cause the LLM to hallucinate or misunderstand the content.
- Missing Relationships: Independent chunks miss the connections between entities. If the system doesn’t capture relationships around key entities like Google or OpenAI, the LLM can’t generate a fully informed answer.
- Multi-Hop Reasoning: GraphRAG supports traversing relationships across entities, enabling multi-hop reasoning. This is similar to the “six degrees of Kevin Bacon” game, where actors are connected through co-starring roles. Semantic search struggles with such queries, but knowledge graphs excel.
For example, if an AI agent is asked, “Who should I contact for budget approval for a marketing automation project?” semantic search might retrieve unrelated snippets about budgets or marketing separately. GraphRAG, by understanding the relationships, can provide a precise and connected response.
GraphRAG Implementations: Microsoft GraphRAG vs LightRAG
Several implementations of GraphRAG exist, with Microsoft GraphRAG and LightRAG being notable examples.
Microsoft GraphRAG
Released last year, Microsoft GraphRAG automates knowledge graph construction using LLMs to extract entities, relationships, and properties. It performs extensive enrichment and clustering, generating community summaries that help answer global concept questions.
Benchmarks show Microsoft GraphRAG performs well on multi-hop reasoning and global questions, outperforming naive RAG systems. It supports various retrieval strategies to fine-tune results.
However, it can be expensive to run, slow to respond during inference, and complex to maintain, especially for incremental updates to the knowledge graph.
LightRAG
LightRAG, a lighter variation released late last year, also features automated graph construction. Unlike Microsoft GraphRAG, it skips clustering and community summaries. Instead, it uses a dual-level retrieval approach that extracts both local keywords (exact terms) and global keywords (broader themes) from queries.
This approach provides strong performance compared to naive RAG, at a significantly lower cost and faster speeds. LightRAG is easier to update and maintain.
On the downside, LightRAG generates a simplified graph, so responses aren’t as rich as Microsoft GraphRAG’s. It also doesn’t handle multi-hop queries as well, since it mainly retrieves nearest neighbors rather than traversing multiple hops.
Dual-Level Retrieval in LightRAG
LightRAG’s dual-level retrieval is particularly interesting. For example, a query like “How was the FIA budget cap affected midfield teams performance pace?” extracts:
- Local Keywords: Specific terms like “FIA,” “budget cap,” and “midfield.”
- Global Keywords: Broader concepts such as “financial regulations,” “resource allocation,” or “wind tunnel usage.”
By searching the knowledge graph with both keyword types, LightRAG can capture both exact matches and related thematic information, improving context for the LLM.
LightRAG competes well with other GraphRAG implementations like RAG Flow, Nano GraphRAG, and Fast GraphRAG, and I found it to be one of the best for integrating with n8n.
Setting Up LightRAG Server
LightRAG is an open-source Python application available on GitHub. You can run it locally or deploy it on a cloud server. There’s a Docker image available, which makes deployment painless.
I deployed LightRAG on Render.com, a cloud platform that supports Docker. Here’s a simplified setup process:
- Create an account on Render.com and start a new project.
- Create a new web service, selecting “Existing Image” as the deployment method.
- Point the image URL to the LightRAG Docker image hosted on GitHub Container Registry.
- Configure environment variables, including login credentials, API keys, and embedding/LLM service details.
- Add a persistent disk to store uploaded files and processed data.
- Deploy the service and wait for it to go live.
Environment variables are crucial as they configure LightRAG’s behavior. For example, you set your OpenAI API keys for embeddings and LLM calls, specify models like GPT-4.1 Nano for ingestion speed, and adjust concurrency settings to optimize performance.
Once deployed, you can log in to the LightRAG interface using the credentials you set. It provides sections to upload documents, view the knowledge graph, test retrieval, and access API endpoints.
Uploading and Processing Documents in LightRAG
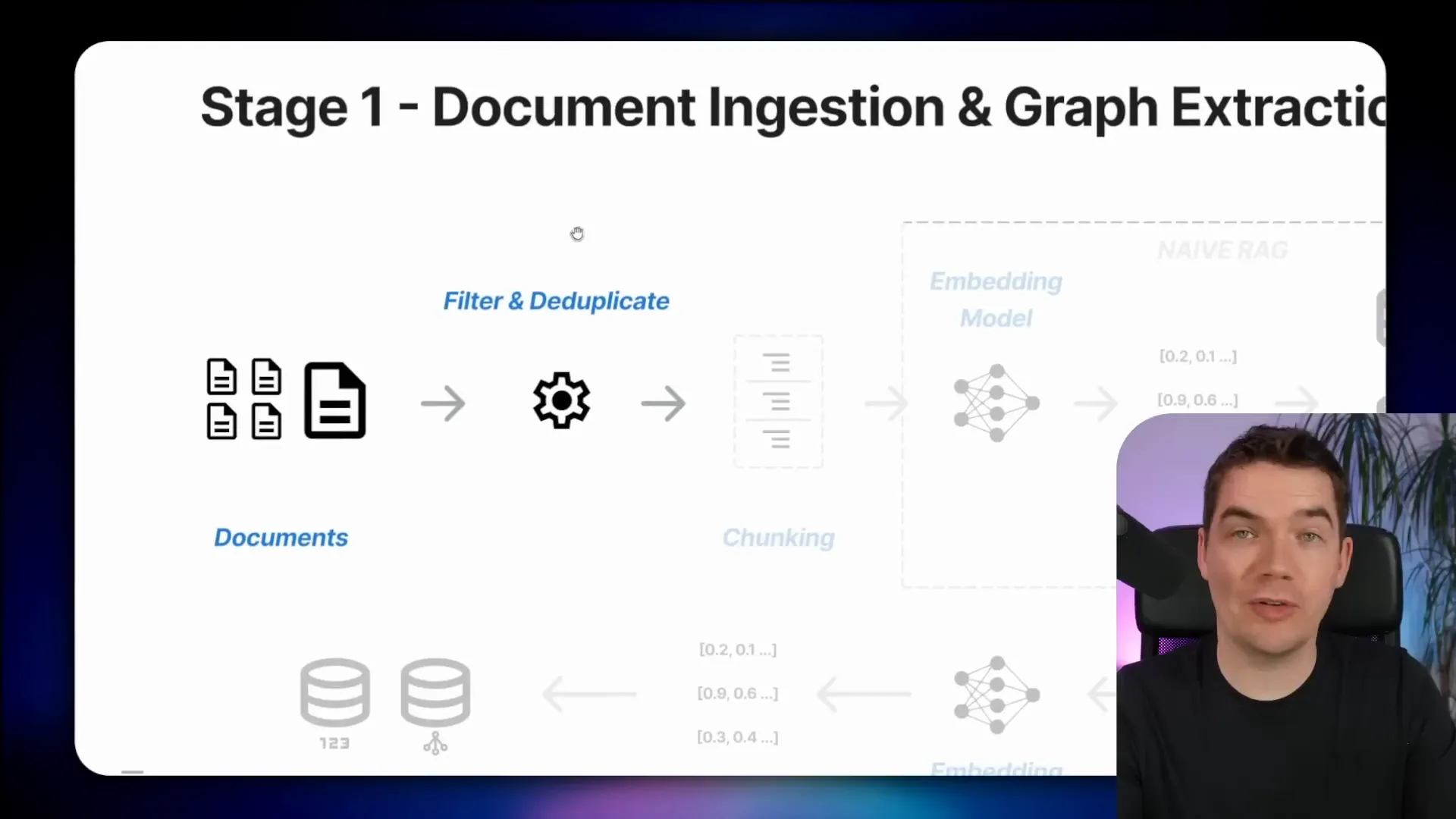
Uploading documents is straightforward. You can add files directly through the UI. LightRAG then processes them through several stages:
- Filtering and Deduplication: Ensures the same document isn’t uploaded twice.
- Chunking: Breaks documents into manageable pieces based on configured chunk size.
- Embedding: Each chunk is transformed into vector embeddings stored in a vector database.
- Entity and Relationship Extraction: Chunks are passed to an LLM with pre-set prompts to extract entities and relationships.
- Merging: Entities and relationships extracted from different chunks are merged to avoid duplicates.
- Entity Description Generation: If an entity appears multiple times, LightRAG uses an LLM to create a consolidated description.
- Embedding Entity Descriptions: The final descriptions are embedded and stored for semantic search within the knowledge graph.
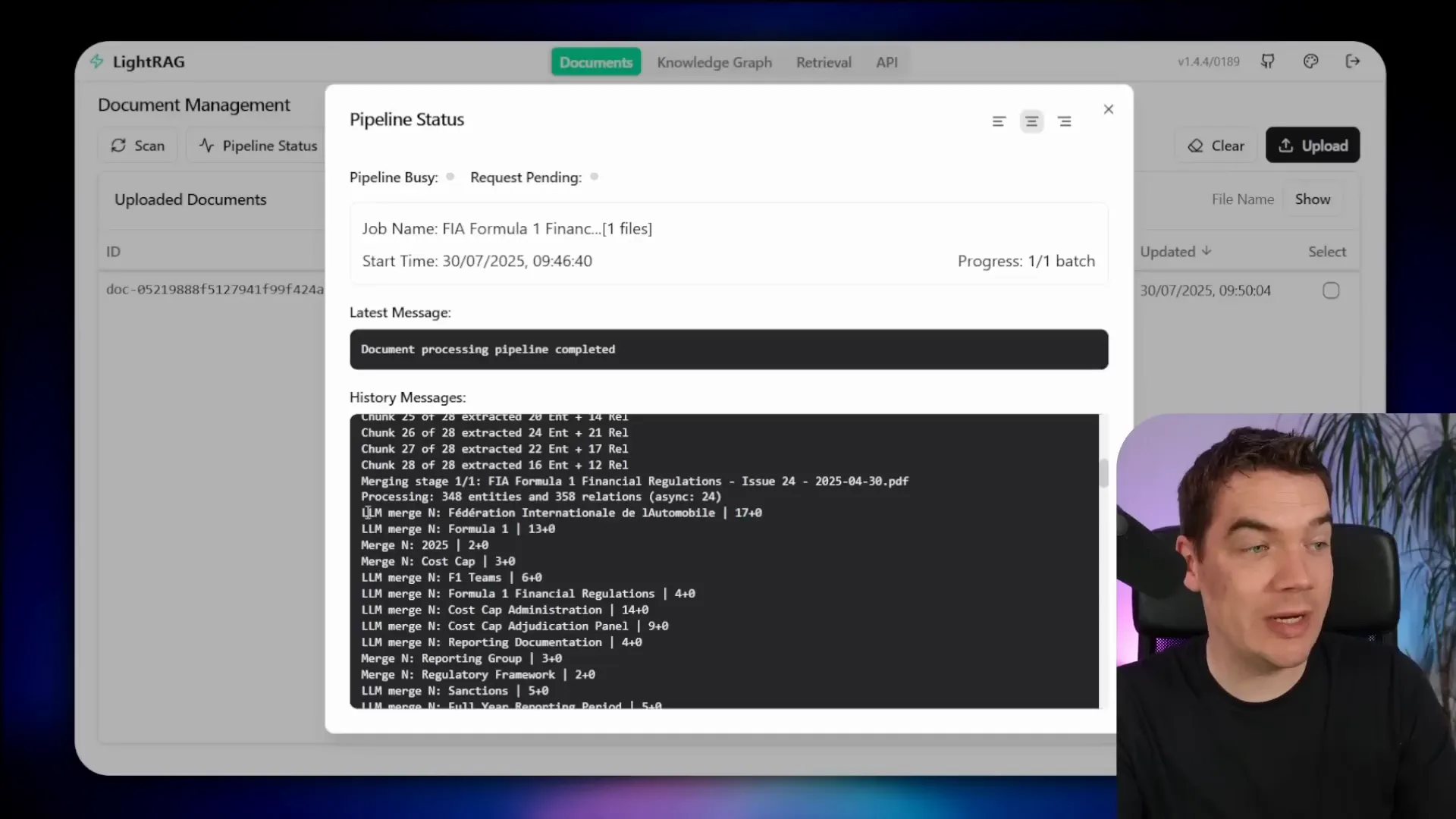
For example, in a 50-page document about Formula One financial regulations, LightRAG might extract hundreds of entities and relationships. It intelligently merges repeated entities and summarizes their descriptions using the LLM.
Once processing completes, the knowledge graph visualizes the entities and their connections, allowing you to explore the data interactively.
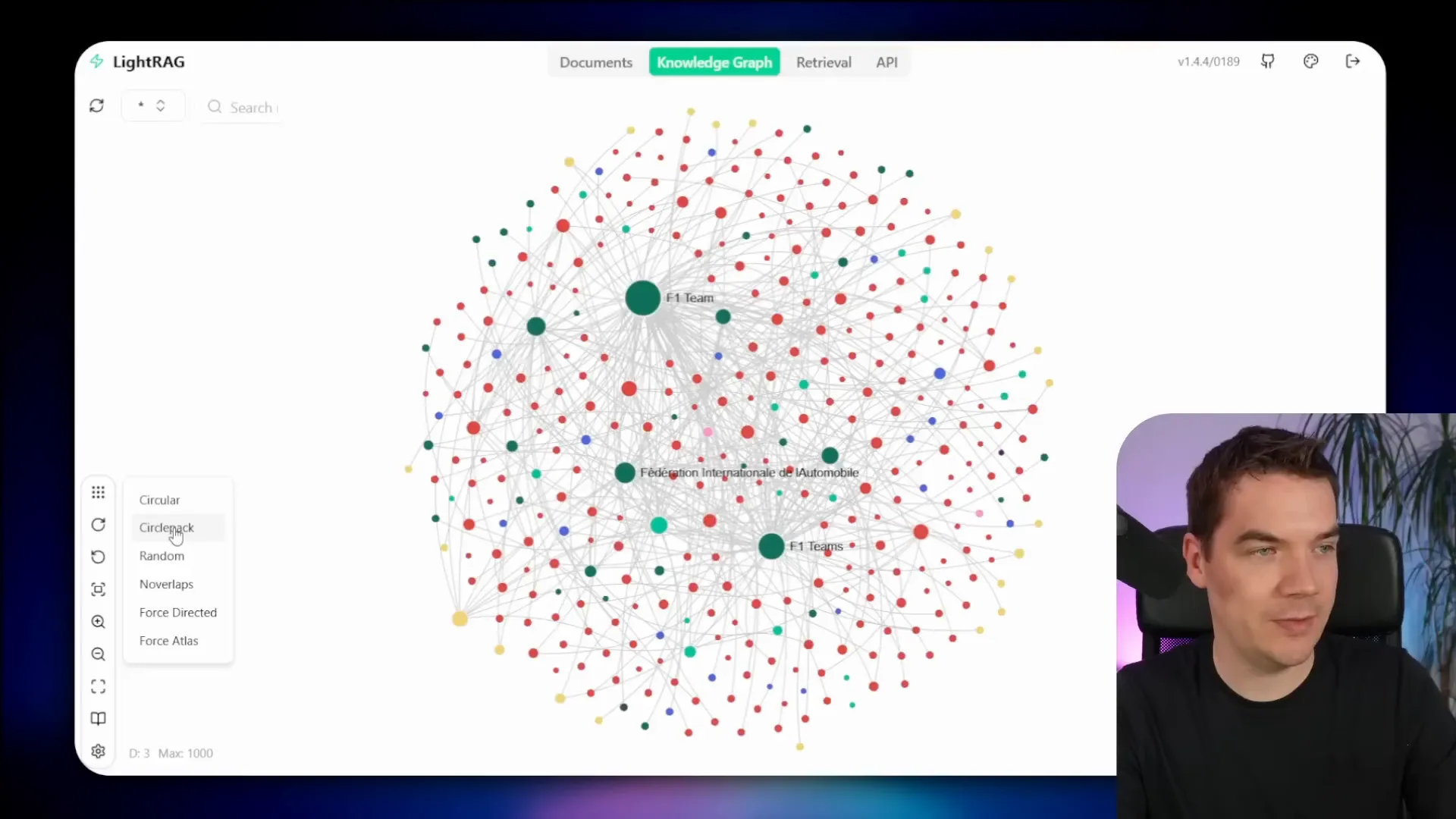
Clicking on an entity like “FIA” reveals detailed descriptions and properties, including the source documents and text chunks where the entity was found. This traceability is invaluable for verifying the origin of information.
Retrieving Information from LightRAG
LightRAG offers a retrieval interface where you can test queries against the knowledge graph. When you ask about the FIA, for example, it streams a detailed response generated by the LLM, grounded in the graph context.
You can also retrieve raw context only, which returns JSON with entities, relationships, and referenced text chunks. This data is what the LLM uses to generate grounded answers.
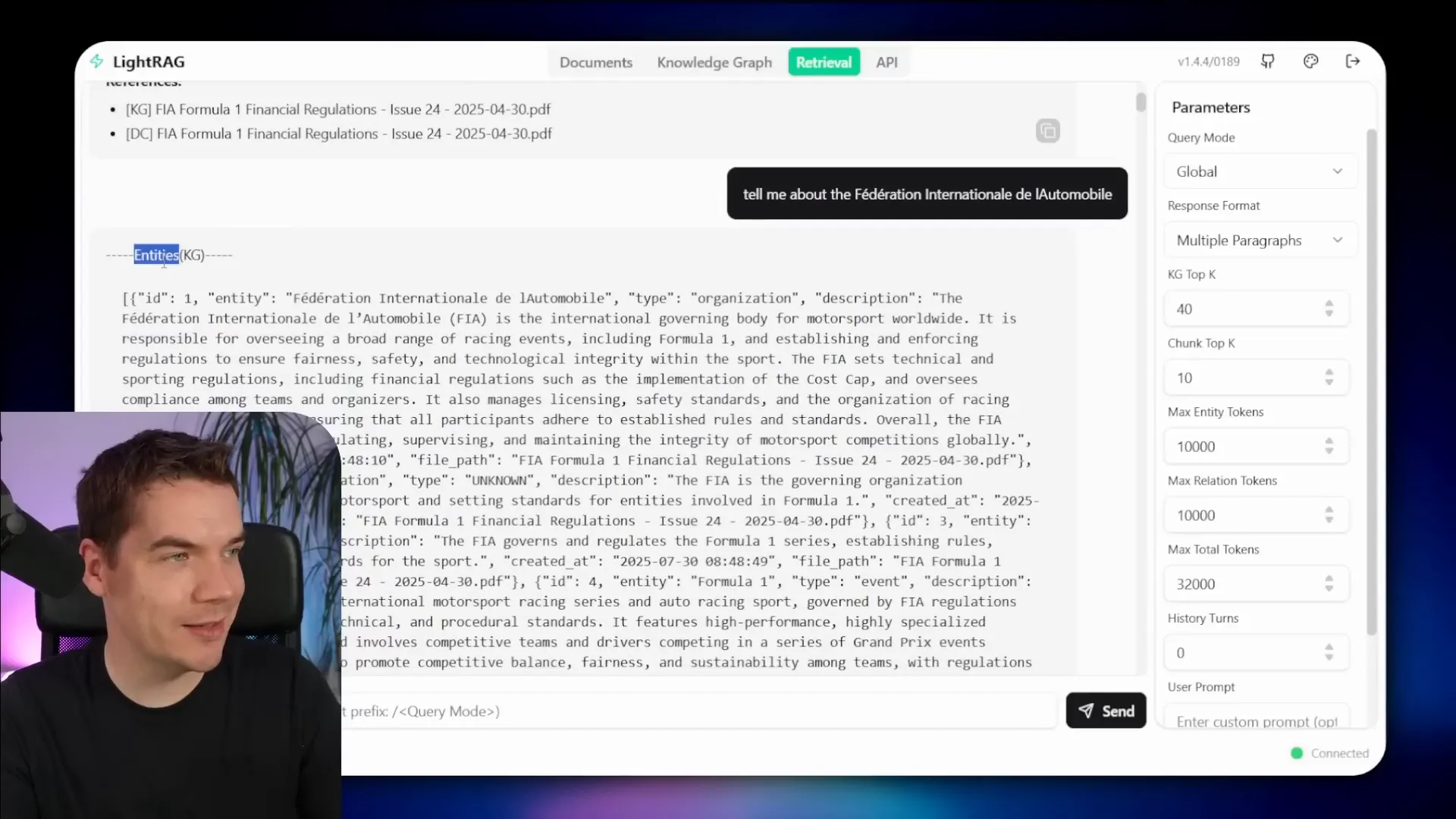
LightRAG supports different query modes:
- Naive RAG: Only uses vector store semantic search, no knowledge graph.
- Local Query: Searches the knowledge graph for exact matches of query terms.
- Global Query: Extracts broader concepts and themes from the query.
- Hybrid: Combines local and global query methods. Recommended for returning knowledge graph info.
- Mix Mode: Combines semantic search and knowledge graph retrieval. Best for having LightRAG act as an independent expert.
Using re-ranking with mix mode improves performance by filtering the large number of returned chunks to the most relevant ones before passing them to the LLM.
Connecting LightRAG with n8n
LightRAG exposes API endpoints that n8n can call to send queries and receive responses. I built a workflow in n8n with a chat trigger and an AI agent. The agent uses OpenAI’s GPT-4.1 model and sends queries to LightRAG’s API via an HTTP request node.
Authentication is handled with an API key set in the HTTP request headers. The JSON body sent to LightRAG contains just the query text, which the AI agent populates dynamically.
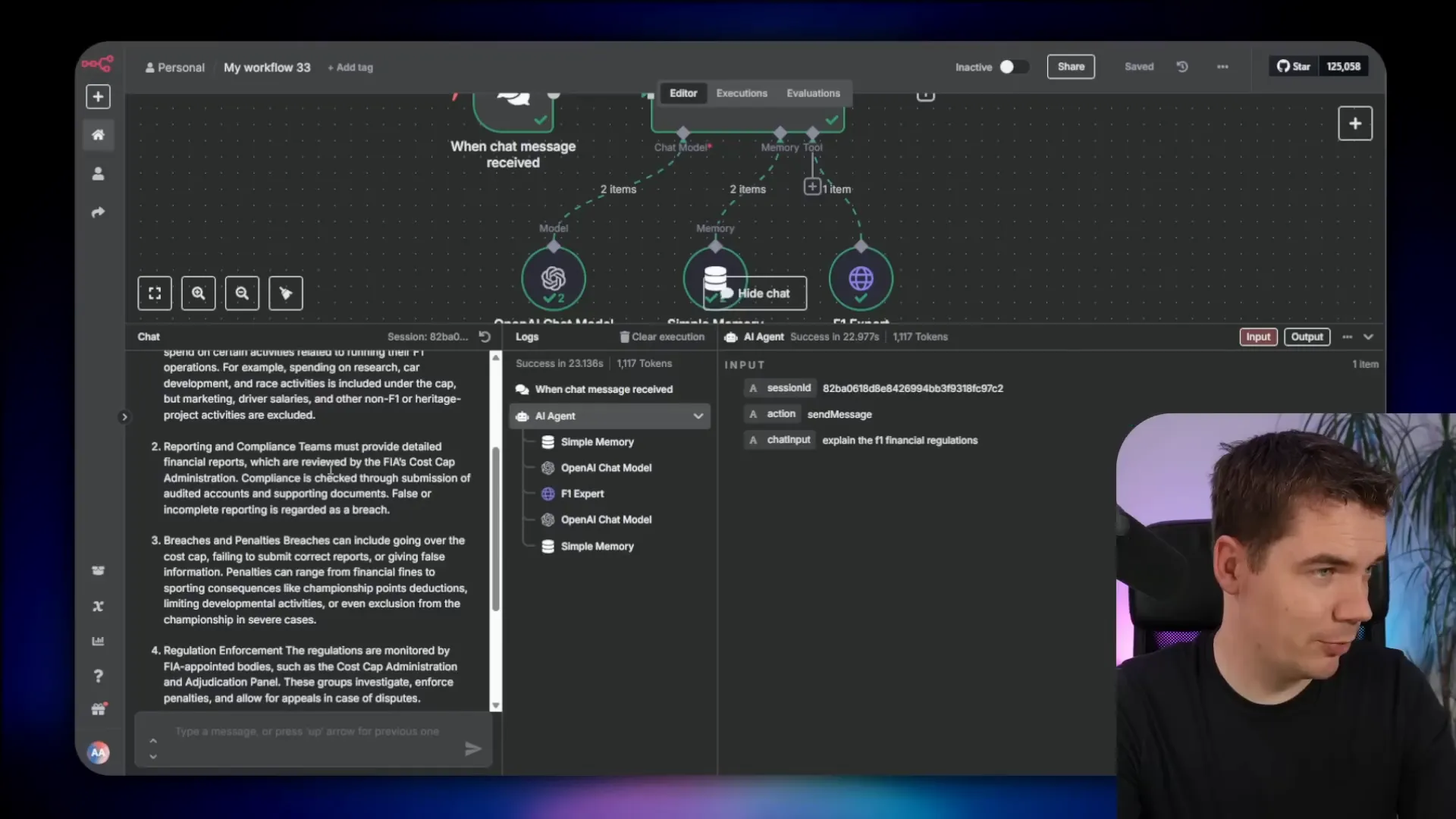
When I ask the agent to explain Formula One financial regulations, it queries LightRAG and returns a detailed answer referencing cost caps, reporting requirements, breaches, and penalties. The response includes citations from LightRAG’s knowledge graph, ensuring grounded and trustworthy answers.
Comparing n8n and LightRAG
Both n8n and LightRAG have overlapping features:
- Document upload and chunk embedding into vector stores
- LLM response generation
- API endpoints
- Basic chat history management
However, LightRAG lacks agentic capabilities like workflow logic and drag-and-drop ingestion pipelines that n8n offers. It has only rudimentary chunking that can split in the middle of words and supports only a single LLM for both ingestion and inference.
On the other hand, n8n allows different models for different tasks, advanced document enrichment, hybrid search combining semantic and full-text search, metadata filtering, and integrations with databases and spreadsheets.
Because of this, I prefer to use LightRAG solely for its knowledge graph capabilities and integrate it with n8n’s powerful RAG workflows. This combination gives the best of both worlds: a rich, auto-generated knowledge graph and a flexible, agentic AI system.
Building a State-of-the-Art n8n RAG Agent with Knowledge Graphs
In my advanced n8n RAG system, I built extensive ingestion pipelines that:
- Extract data from documents of various types
- Track document changes with a record manager to avoid duplicates
- Enrich documents with metadata
- Generate contextual embeddings for each chunk
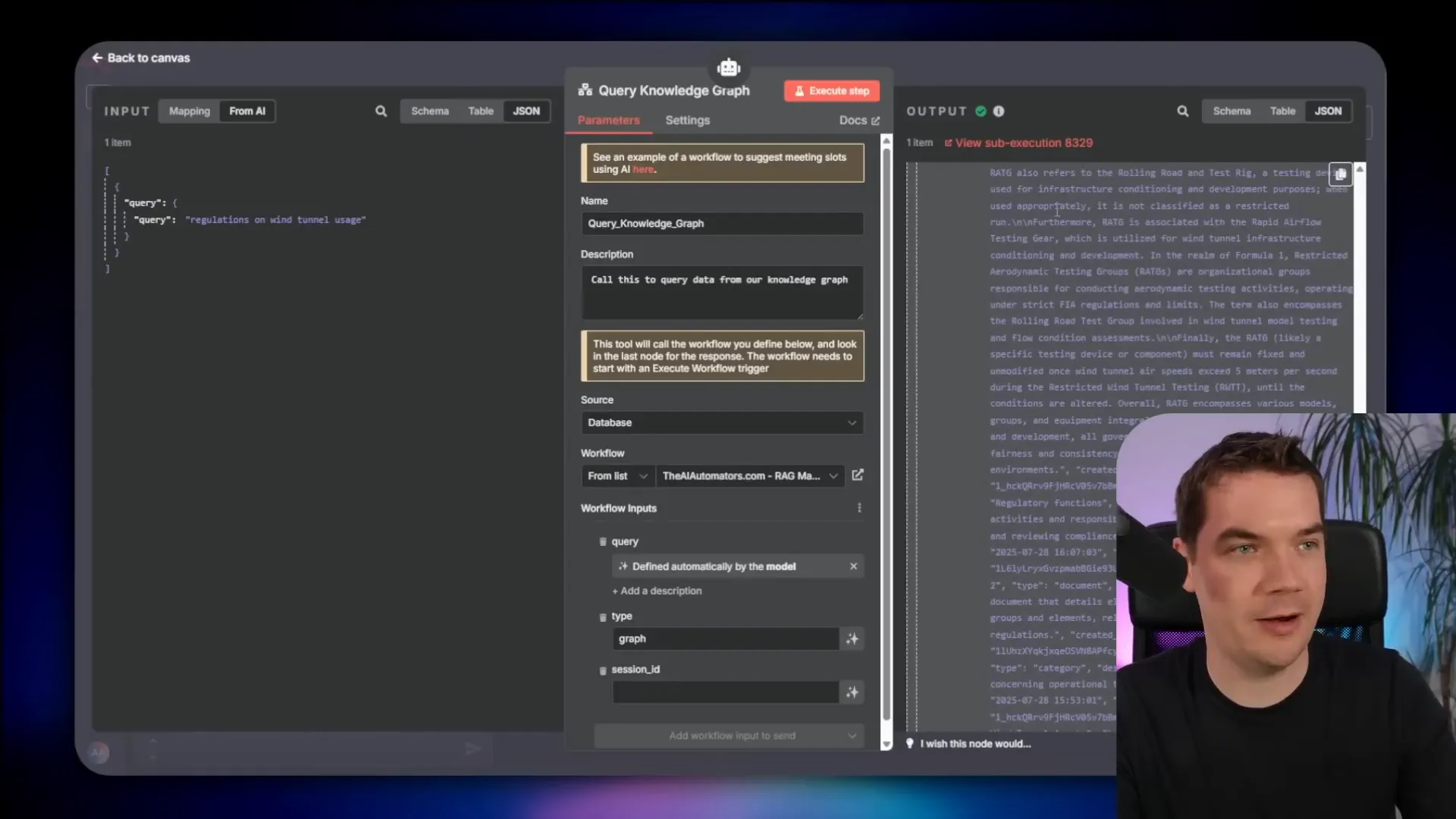
- Update the knowledge graph by sending document text to LightRAG
If a document is new, the pipeline uploads it to LightRAG’s document store. If a document changes, it deletes the old version from LightRAG (removing all related entities and relationships) before re-ingesting the new version. This keeps the knowledge graph up to date.
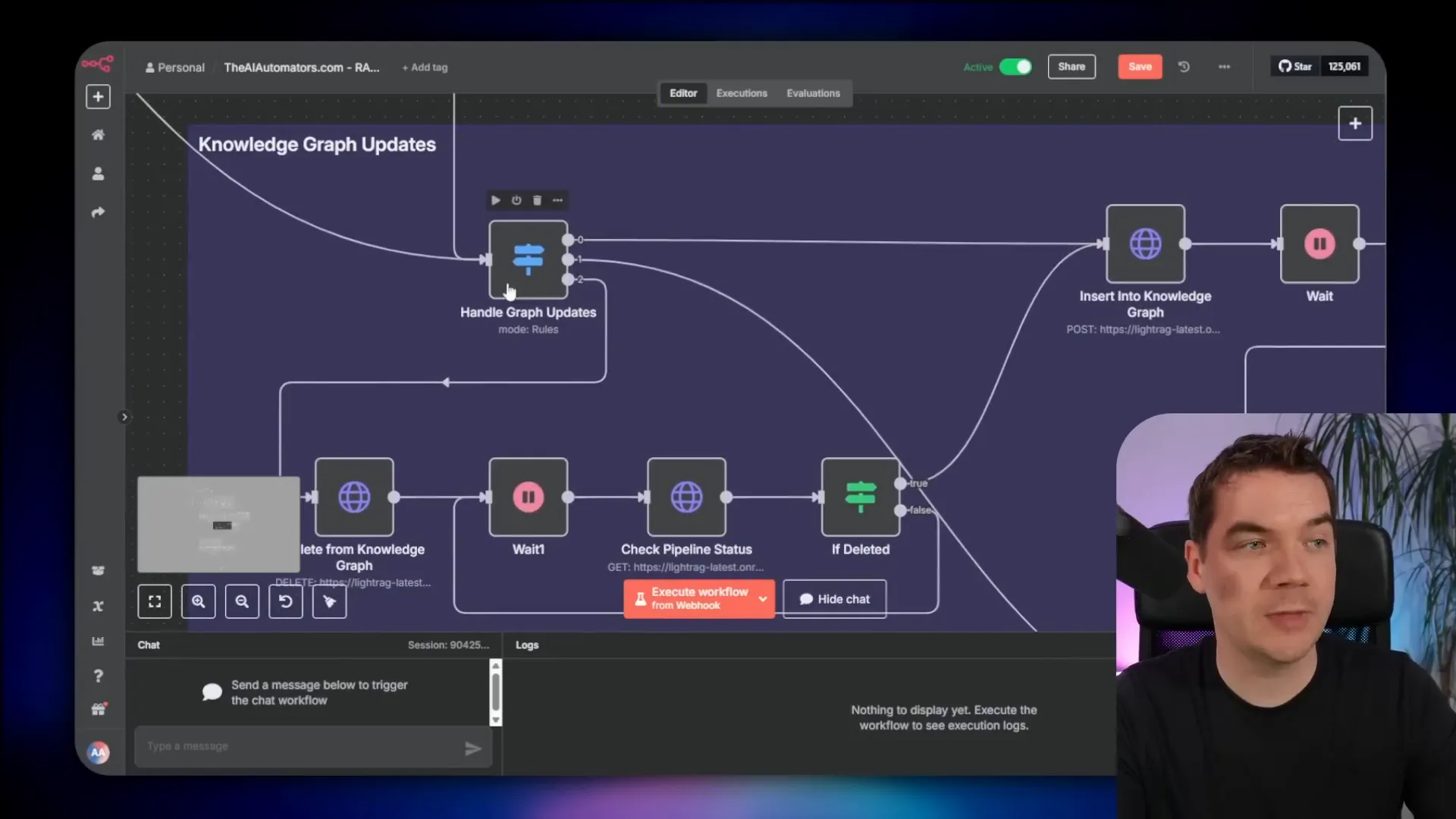
On the inference side, the agent queries both the vector store and the knowledge graph. It retrieves entities, relationships, and relevant chunks, then re-ranks them to find the most pertinent information. Finally, it sends all this context to the LLM to generate a grounded, comprehensive answer.
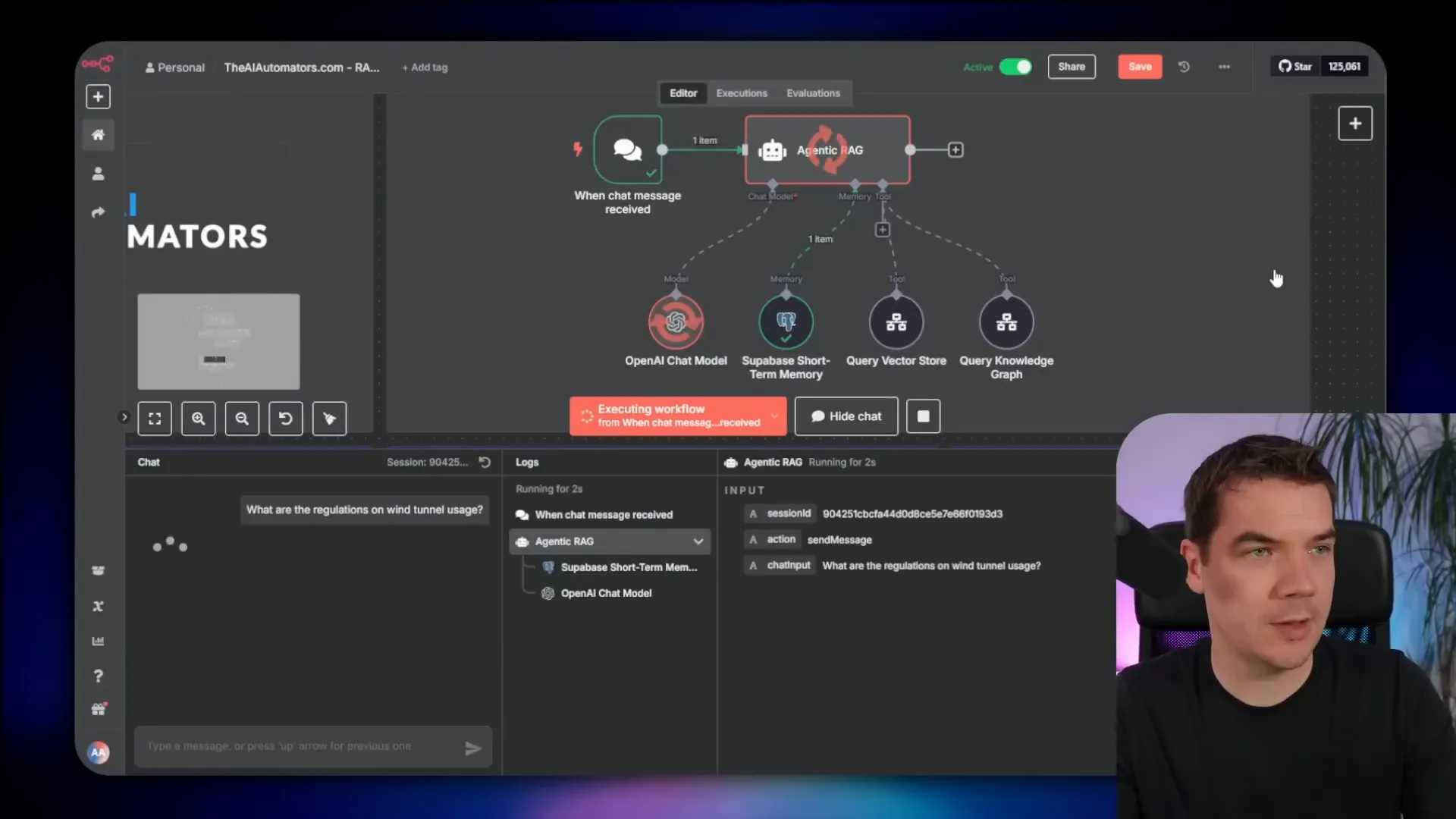
For example, when I ask about regulations on wind tunnel usage, the agent pulls context-rich chunks from the vector store, including introductory sentences that ground each chunk in the document. It also retrieves local and global context from the knowledge graph, resulting in a detailed and accurate response with references to specific document sections.
Why This Matters
This setup raises the bar for AI agents built on n8n. By combining LightRAG’s knowledge graph with n8n’s flexible RAG pipelines, you get smarter agents that understand context, relationships, and can reason across multiple hops of information.
It’s a significant step up from traditional RAG systems that often return fragmented or incomplete answers. With this approach, AI agents can handle complex queries in areas like compliance, customer support, research, and marketing with much greater accuracy.
The ability to automatically build and maintain a knowledge graph from your own documents, then integrate that graph seamlessly into your AI workflows, is a powerful tool for anyone looking to enhance their AI agents.
