

Fine-tuning is a powerful way to transform your AI agents, making them more specialized, reliable, and aligned with your unique tone of voice. In this article, I’ll walk you through how to get started with fine-tuning, explain why and when to use it, and share a system I built using Airtable and n8n that allows you to create fine-tuned models at scale—without needing heavy technical skills.
Whether you want to match a specific writing style, enforce industry jargon, or optimize your AI for high-volume tasks, fine-tuning offers an effective approach to influence how your AI responds. I’ll also cover some common challenges and best practices to ensure you get the most out of fine-tuning in your AI projects.
Understanding Fine-Tuning and How It Fits with Other AI Optimization Methods
Fine-tuning is one of several core methods used to optimize AI responses. It’s important to understand how it differs from other approaches like prompt engineering and Retrieval-Augmented Generation (RAG).
- Prompt Engineering is about crafting high-quality prompts to guide the AI’s responses. It’s flexible and quick but can be limited in controlling tone or style consistently.
- RAG gives your AI access to large external knowledge bases, allowing it to pull in fresh, detailed information. This is especially useful for teaching the AI new facts or data.
- Fine-Tuning, on the other hand, focuses on creating a specialized model that shapes the AI’s style, tone, structure, and format. It’s less about adding new knowledge and more about influencing how the AI expresses itself.
Fine-tuning is a smaller additional training step on top of a base model. While training a base model can take months and cost millions, fine-tuning can often be done in minutes and for just a few cents.

When to Use Fine-Tuning
Fine-tuning is especially useful in scenarios where you want your AI to:
- Match your specific writing style or tone by providing many examples that influence output
- Enforce particular jargon, terminology, or formatting specific to your industry, such as legal documents or operating procedures
- Handle high-volume, task-specific workflows where you might want to use a cheaper, fine-tuned model instead of a more expensive base model
- Improve the reliability and consistency of AI responses for specialized use cases
However, fine-tuning is not the best choice if your goal is to teach the AI new knowledge or facts. RAG systems are more flexible and reliable for that. Additionally, if you only plan to use the model occasionally or want it to be highly generalized across many domains, fine-tuning may not be the right fit.
Quality of training data is crucial. Without consistent, varied, and well-prepared examples, fine-tuning won’t produce good results.
Types and Strategies of Fine-Tuning
There are different methods for fine-tuning AI models, each with its own pros and cons:
- Full Fine-Tuning updates all model parameters. This requires significant computational power (GPU intensive) but can deeply customize the model.
- Parameter-Efficient Fine-Tuning (PEFT) updates only a small subset of parameters. This is more resource-friendly and often sufficient for many use cases.
- LoRA (Low-Rank Adaptation) is a popular PEFT technique especially known in AI image generation, but also applicable to language models.
If you plan to fine-tune on your own hardware, PEFT approaches like LoRA are generally more feasible.
Models You Can Fine-Tune
OpenAI offers several models that can be fine-tuned directly via their self-serve API at low cost. Larger organizations can access custom models through partnerships involving longer engagements and higher budgets.
Other providers and platforms also support fine-tuning:
- Claude 3 and Haiku models via Amazon Bedrock
- Certain Gemini models via Google Vertex AI
- Open-source models like Axolotl or LLaMA Factory, if you have the technical skills and hardware
Supervised Fine-Tuning: A Simple and Effective Approach
One of the most straightforward fine-tuning methods is supervised fine-tuning. Here, you provide pairs of user prompts and the desired responses. The model learns from these examples how to respond in the way you want.
There are more advanced methods like Direct Preference Optimization, where you provide both correct and incorrect answers to steer the model further, or Reinforcement Fine-Tuning, which is used for reasoning models. Vision fine-tuning is another branch where the model is trained with images.
Step-by-Step: Creating a Fine-Tuned Model Using OpenAI
Here’s how I created a fine-tuned model quickly using the OpenAI dashboard:
- Go to the OpenAI dashboard, select “Fine-tuning” from the menu, and click “Create”.
- Choose a base model (I used GPT-4.1 Nano) and give your model a name suffix, like “customer support bot.”
- Set a seed number to lock randomness for reproducibility across jobs using similar datasets.
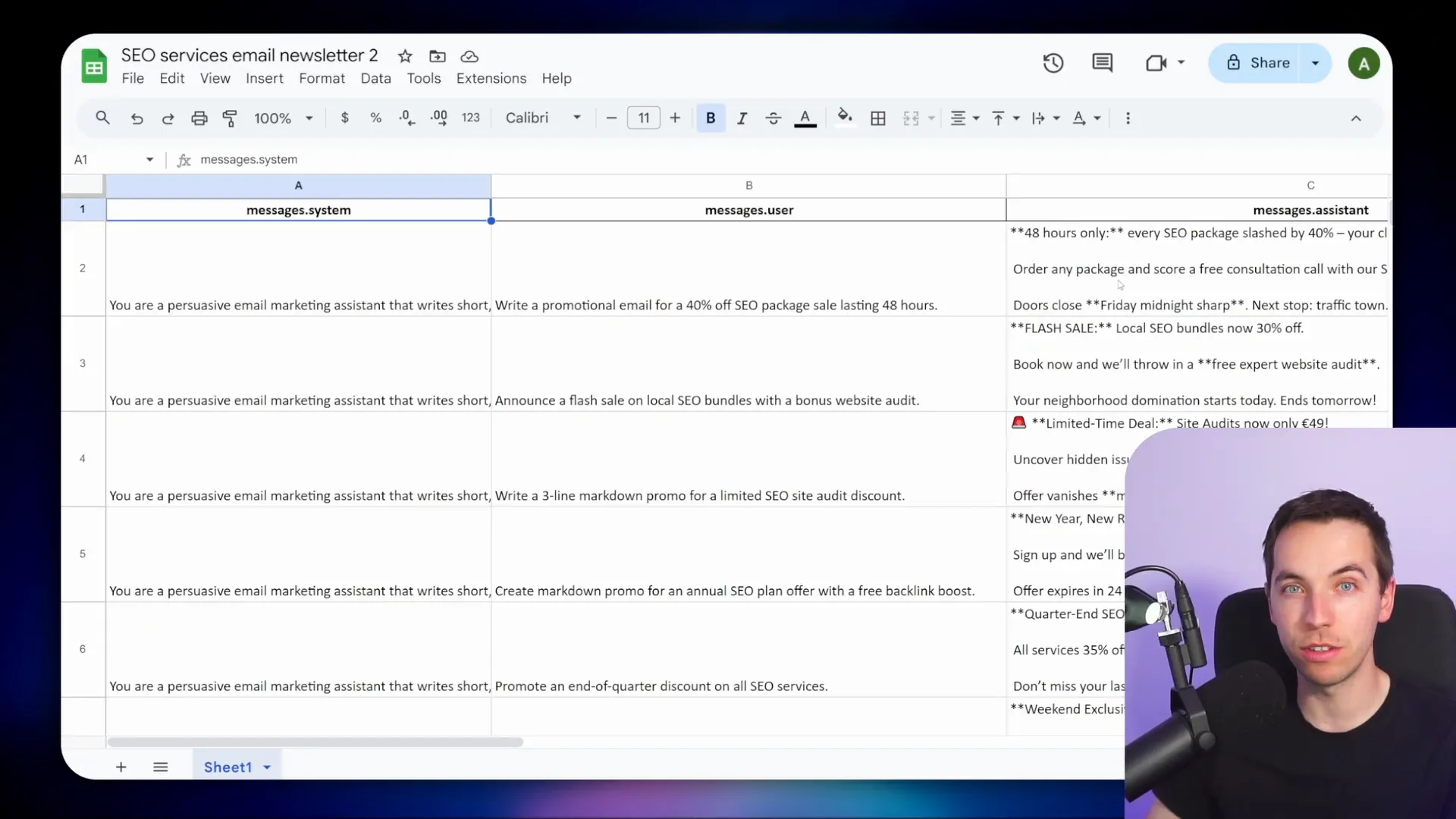
- Prepare your training data. I used a Google Sheet with sample prompts and example responses.
- To format the data correctly, I pasted it into ChatGPT and asked it to create a JSONL file for OpenAI fine-tuning.
- Download the JSONL file and upload it to the fine-tuning interface.
- Optionally, add a validation data file to test the fine-tuned model later.
- Leave hyperparameters like batch size, learning rate, and epochs set to “auto” for now.
- Click “Create” and wait for validation and fine-tuning to complete (usually a few minutes for small datasets).
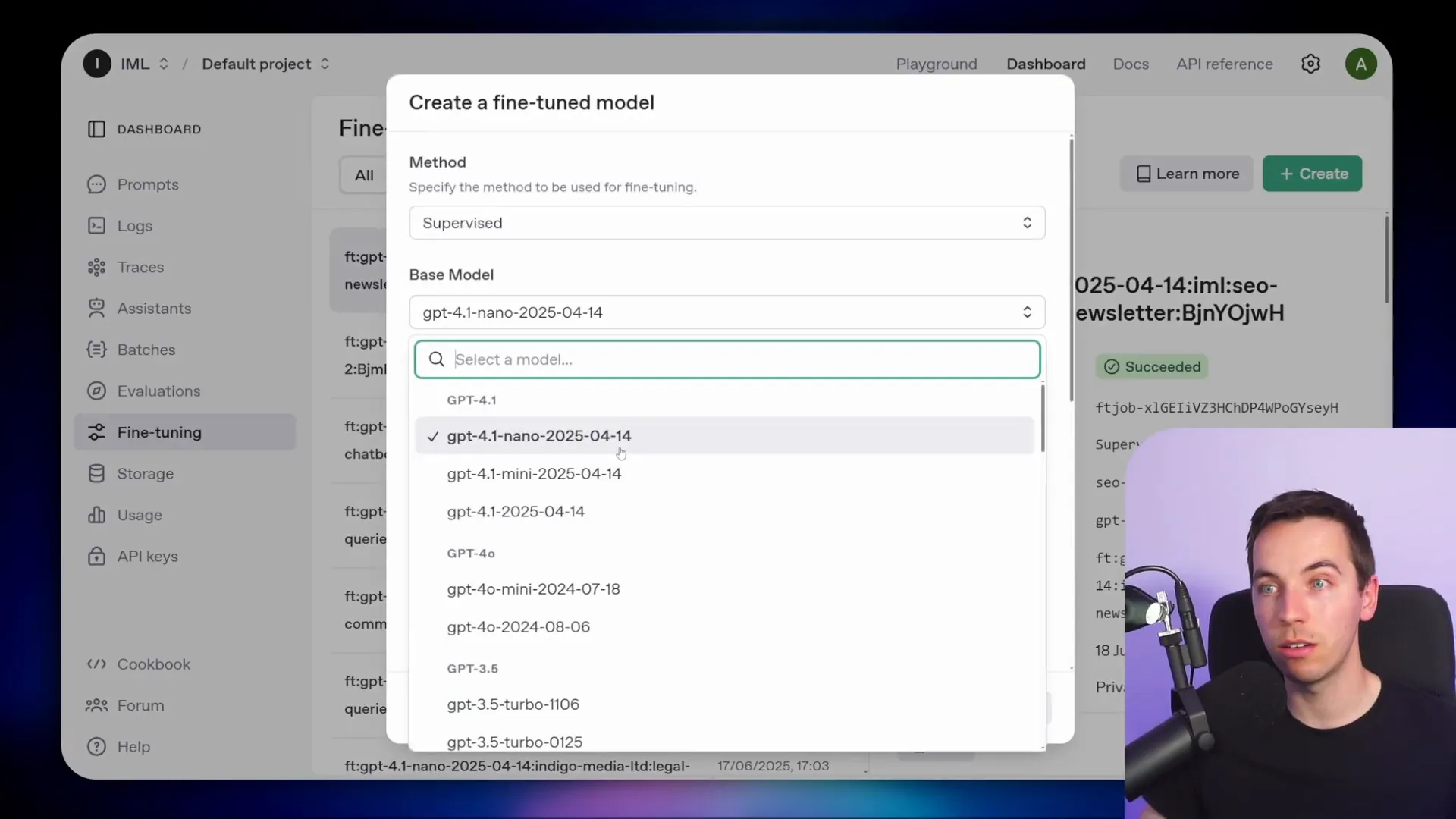
After the job finishes, OpenAI provides a unique fine-tuned model name that you can use directly in your applications instead of the base model.
Building a Basic AI Agent with Your Fine-Tuned Model in n8n
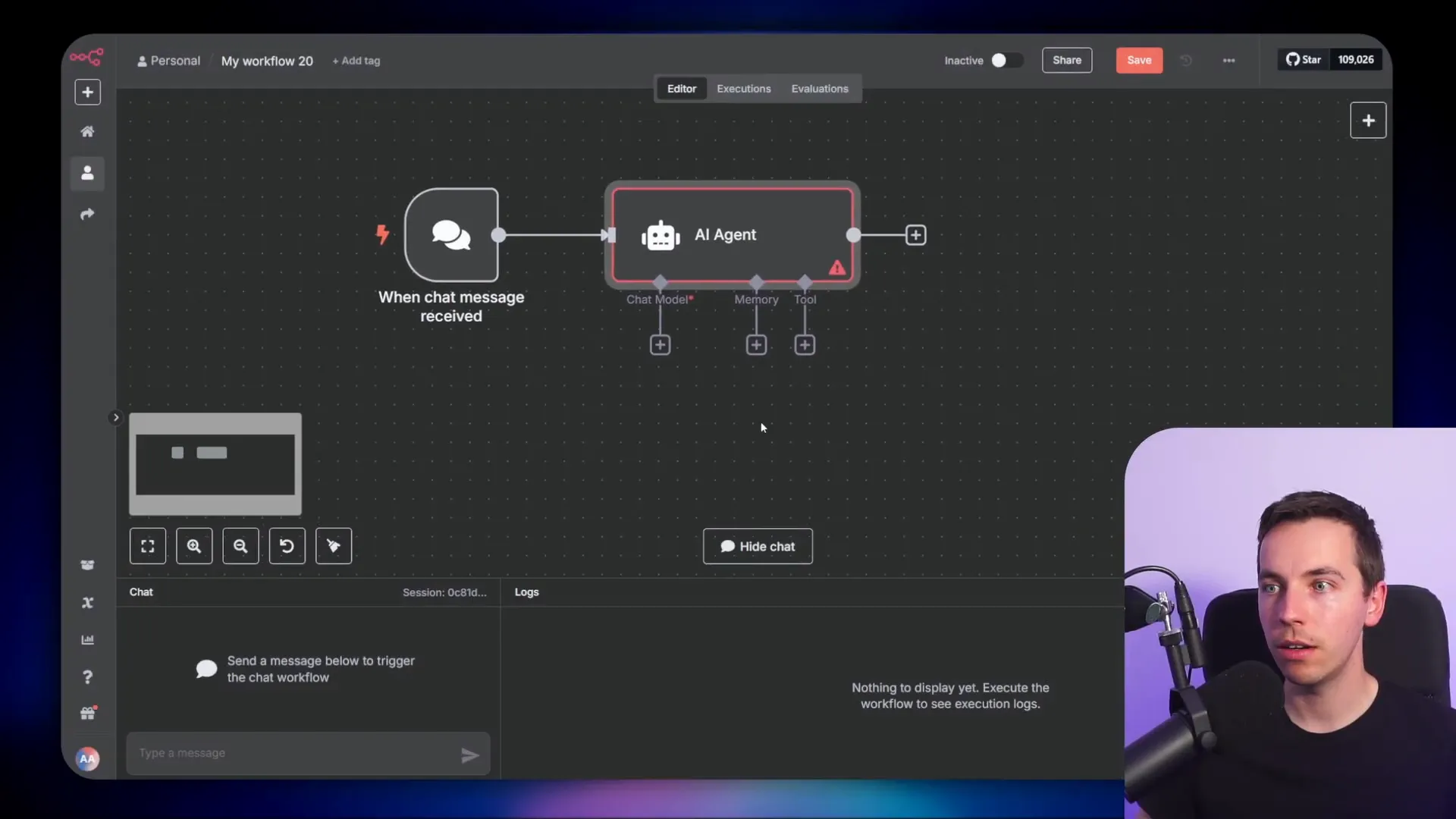
While waiting for the fine-tuning job to complete, I created a simple AI agent workflow in n8n:
- Start a new workflow and add an AI agent node triggered by chat input.
- Add “simple memory” to keep track of conversation context.
- Add an OpenAI chat model node, which defaults to GPT-4.0 Mini.
- Replace the base model with your fine-tuned model by using an expression to input its exact name.
- Save and activate the workflow.
- Test the agent by sending messages and observing responses.
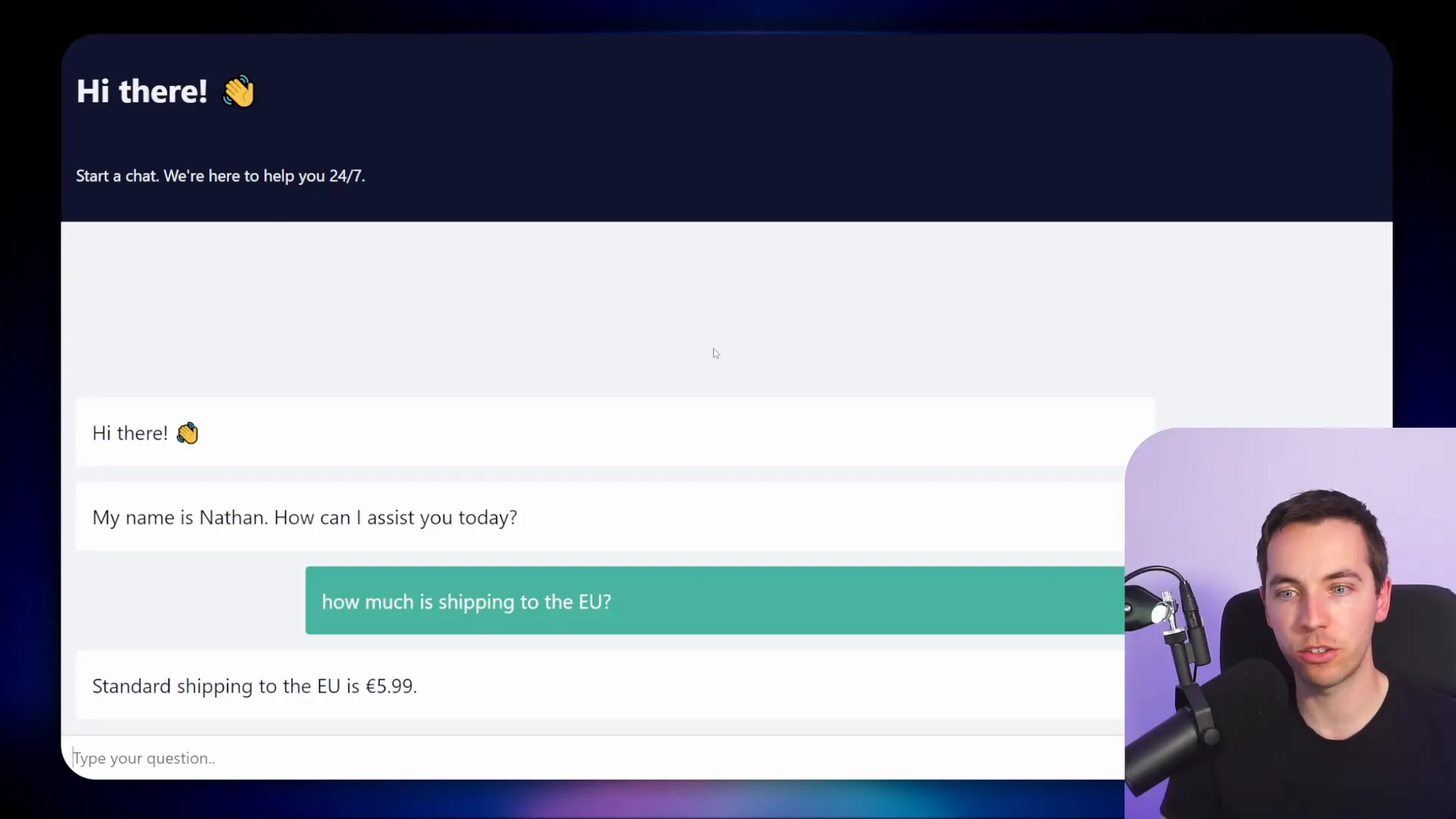
The fine-tuned model responds in the style and format defined by the training data. For example, when I asked about shipping costs to the EU, it gave a well-structured answer consistent with the training examples.
However, the model guessed the shipping price, which can be an issue if accuracy is critical. To address this, you can:
- Expand your training data with varied examples to handle edge cases and instruct the AI to respond truthfully when unsure.
- Combine fine-tuning with a RAG system to ground answers in real business data, using fine-tuning as a presentation layer to format responses.
Best Practices for Preparing Fine-Tuning Data
Quality and variety in your training examples are key. Here are some tips:
- Use at least 10 examples, but ideally between 50 and 100 to see meaningful improvements.
- Ensure examples are consistent and don’t contradict each other.
- Include different types of prompts to cover various scenarios.
- Match the format of your training prompts to how you’ll actually query the model in production.
Too few examples may cause overfitting, where the model can’t generalize beyond training data. Too many examples can overwhelm the model and degrade performance.
Scaling Fine-Tuning with Airtable and n8n
To streamline and scale fine-tuning, I built an automated system using Airtable and n8n:
- Drop Google Sheets containing training data into a designated Google Drive folder.
- n8n’s Google Drive trigger detects new files and creates Airtable records with the file name, status, base model choice, and Google Sheet URL.
- When ready, change the Airtable record status to “ready for processing” and press a sync button.
- This triggers a workflow that fetches the Google Sheet data, converts it into JSONL format (using a code node powered by ChatGPT), and uploads it to OpenAI.
- It then calls the OpenAI API to start the fine-tuning job.
- A separate workflow polls the OpenAI API every minute to check the job status until completion or timeout.
- Once complete, the Airtable record is updated with the fine-tuned model name and status.
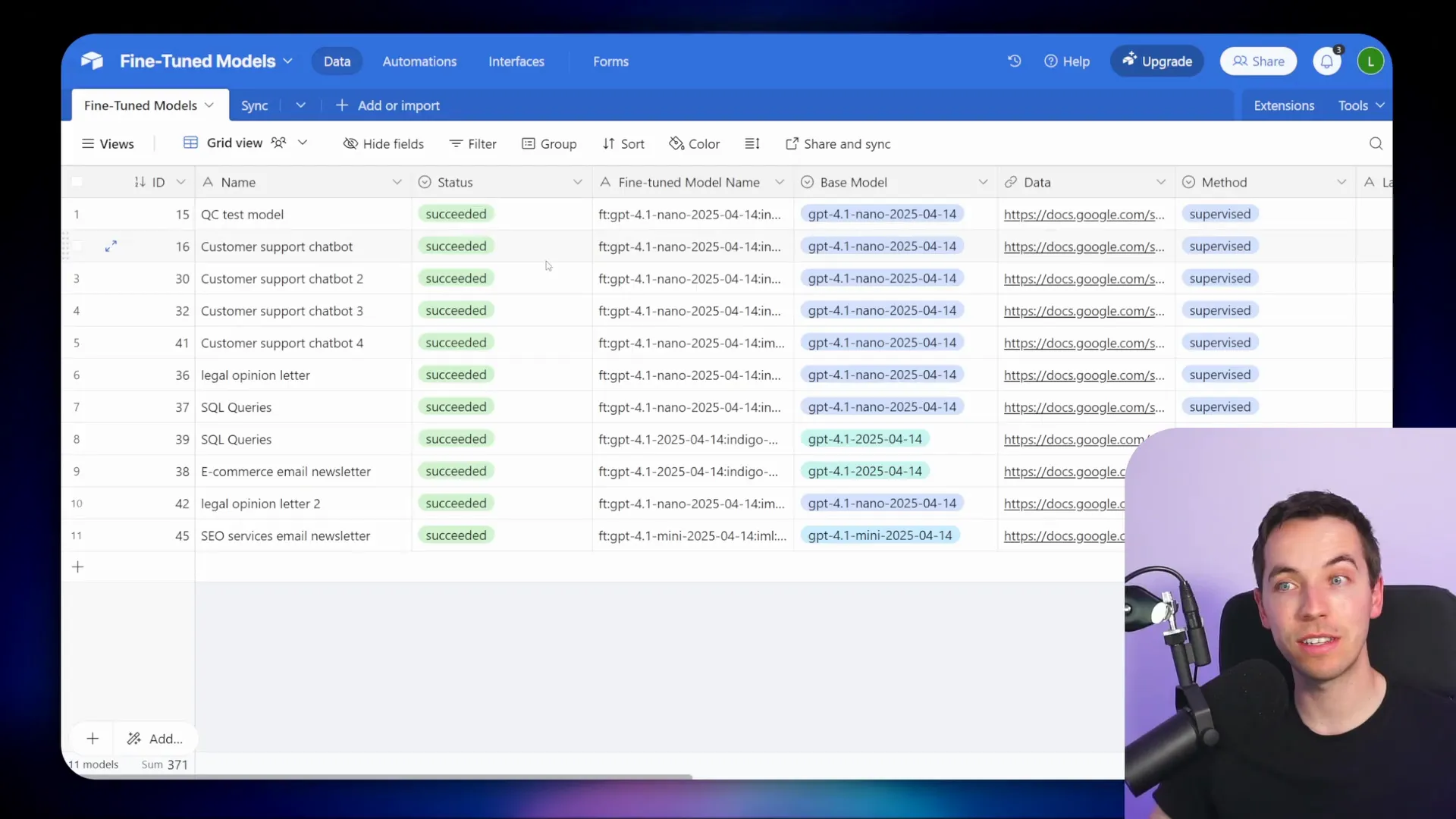
This system runs on the free version of Airtable and requires no scripts. On paid Airtable plans, you can automate status updates further using instant triggers.
The workflows include handling multiple fine-tuning jobs, looping through records, merging data, and making HTTP requests to OpenAI’s fine-tuning endpoints, which are not natively supported in n8n’s OpenAI node.
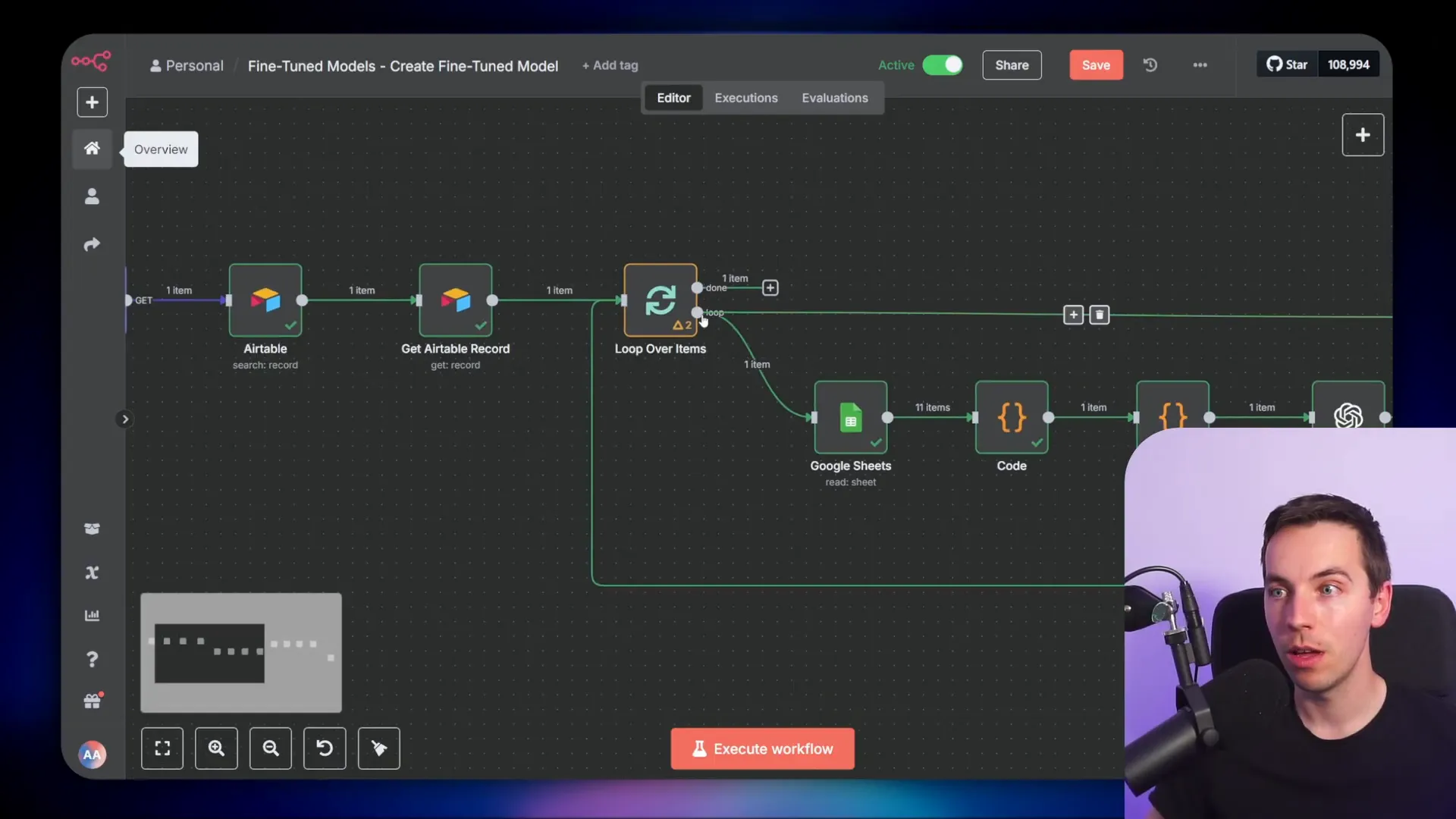
Technical Details of the Automation Workflow
The key components of the automation include:
- Google Drive Trigger: Detects new Google Sheets in a folder.
- Airtable Record Creation: Stores metadata and training data URLs.
- Data Fetch and Conversion: Reads Google Sheet data, formats JSONL using a code node.
- File Upload: Converts JSONL to binary and uploads to OpenAI.
- Fine-Tuning Job Start: Calls OpenAI API to create fine-tuning job with chosen parameters.
- Status Polling Workflow: Checks job status every minute, updates Airtable with results or errors.
This approach keeps workflows clean and manageable, allowing multiple fine-tuning jobs to be processed in parallel or sequence.
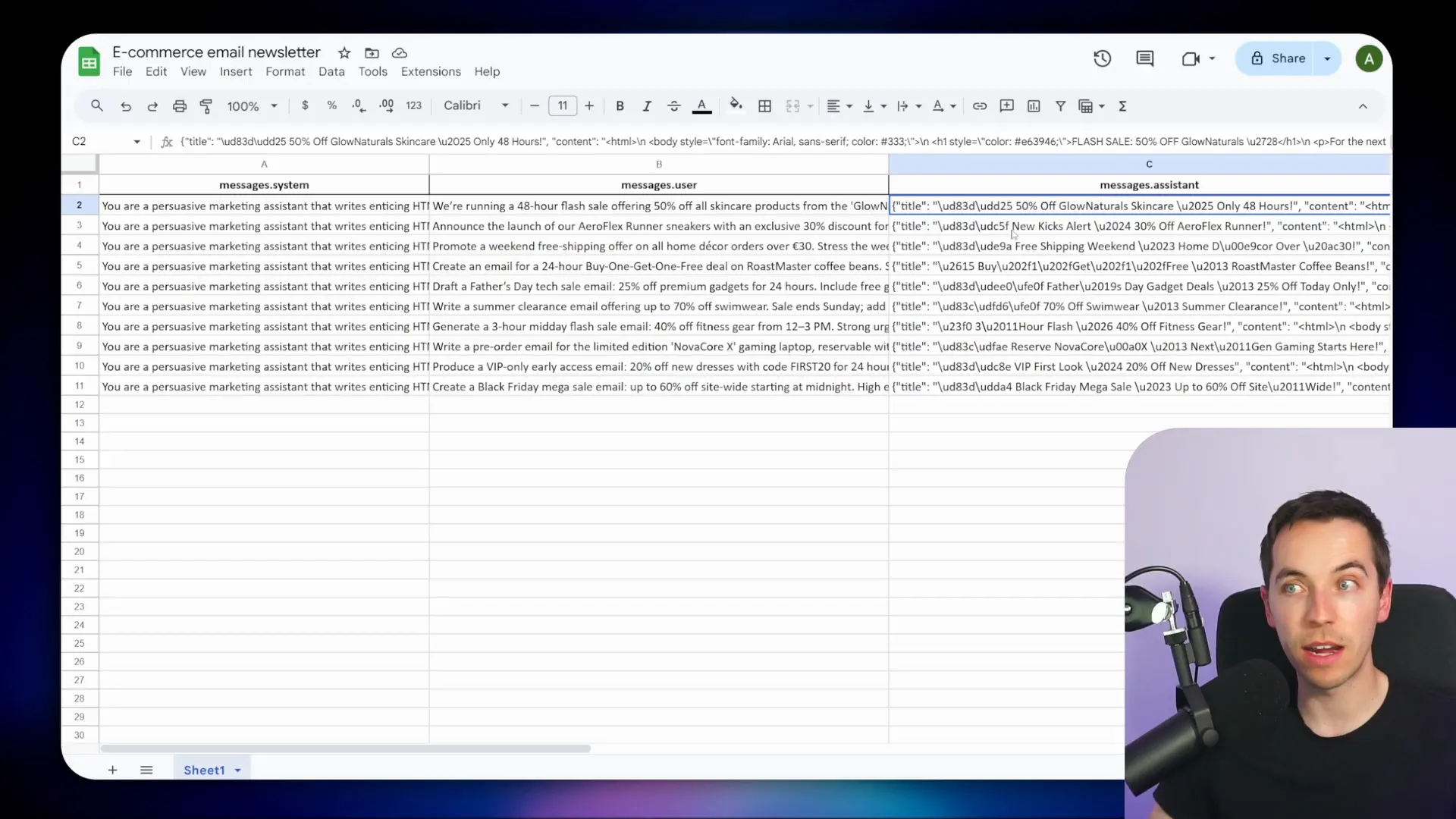
Using Fine-Tuned Models in Practice: Tone, Format, and Integration
Fine-tuning shines when you want to control the tone of voice and output format. For example, I created a model fine-tuned to draft marketing emails with a specific style. The training data included system messages and prompts formatted to produce JSON output with “title” and “content” fields.
When queried to draft a Black Friday newsletter, the fine-tuned model generated the email content and description perfectly formatted. This output was then sent directly to the ConvertKit API, effectively automating email creation.
One way to maximize the benefits of fine-tuning is by using an LLM chain as a separate layer after the AI agent’s response. This lets you keep the agent flexible and general while tailoring the final output with fine-tuning, avoiding some of the limitations of fine-tuning the agent directly.
Challenges of Fine-Tuning AI Agents Directly
Fine-tuning AI agents themselves comes with challenges, especially when the agents need to call external tools or services.
For example, I tested a fine-tuned AI agent designed to answer questions about shipping. The agent uses a vector store to retrieve relevant business data. However, when fine-tuned with simple prompt-response pairs, the agent often failed to call the correct tool or disregarded tool responses, sometimes answering incorrectly or prematurely.
Agents require the ability to generalize, detect available tools, and decide when to call them. Fine-tuning to support this behavior adds complexity and risks reducing flexibility. If you fine-tune incorrectly, it can cause major problems in tool usage and response quality.
Therefore, I recommend leaving fine-tuning to the output layer beyond the agent. Let the agent remain flexible and general, and use fine-tuning to polish the final output for style, format, and tone.
Combining Fine-Tuning with RAG Systems for Accurate, Styled Responses
Here’s how I combined the strengths of RAG and fine-tuning:
- The AI agent queries the vector database to retrieve relevant, factual information.
- The agent composes an initial answer based on that retrieved data.
- The answer and original question are passed to a fine-tuned model in an LLM chain.
- The fine-tuned model rephrases the answer in the desired tone, style, and format.
- The polished response is returned to the user.
This design pattern leverages RAG’s ability to ground responses in real knowledge while using fine-tuning to enhance presentation and alignment to brand voice.
Tips for Preparing Fine-Tuning Data for Production Use
It’s best to keep your training prompt format consistent with how you’ll actually query the model in production. For instance, if your live inputs include extra context or specific formatting, reflect that in your training examples.
I found that mismatches between training data format and real prompts can reduce fine-tuning effectiveness. Regularly update and test your training examples to ensure they mirror actual usage.
Getting the Most from Fine-Tuning in Your AI Projects
Fine-tuning is a powerful tool, but it works best when combined with solid prompt engineering and RAG systems. First, focus on crafting high-quality prompts. Then, if your application requires dynamic, up-to-date knowledge, incorporate RAG.
Use fine-tuning to optimize output style, tone, and formatting. This can improve reliability and make your AI responses feel more natural and aligned with your brand or industry.
Additionally, if your workflow is busy and specific, fine-tuning can allow you to use cheaper, faster models while maintaining acceptable output quality.
With the system I built using Airtable and n8n, managing and iterating on fine-tuning jobs becomes straightforward and scalable. You can maintain multiple versions of fine-tuned models, test them easily, and integrate them seamlessly into your AI agents and workflows.
