

RAG agents are incredibly powerful tools for retrieving information from vector databases, but they often face a common challenge: the data retrieved can be outdated or irrelevant because it lacks precise filtering based on metadata. To solve this, I created an automation that allows agents to generate advanced metadata filters dynamically. This ensures they pull exactly the right data, tailored to the specific question asked. In this article, I’ll walk you through how I built this for both Supabase and Pinecone vector databases, demonstrating how to enrich data during ingestion and apply sophisticated filters during retrieval. You’ll discover how to improve your RAG agents’ precision by combining metadata filtering with hybrid search and re-ranking techniques.
Understanding Metadata Filtering in RAG Pipelines
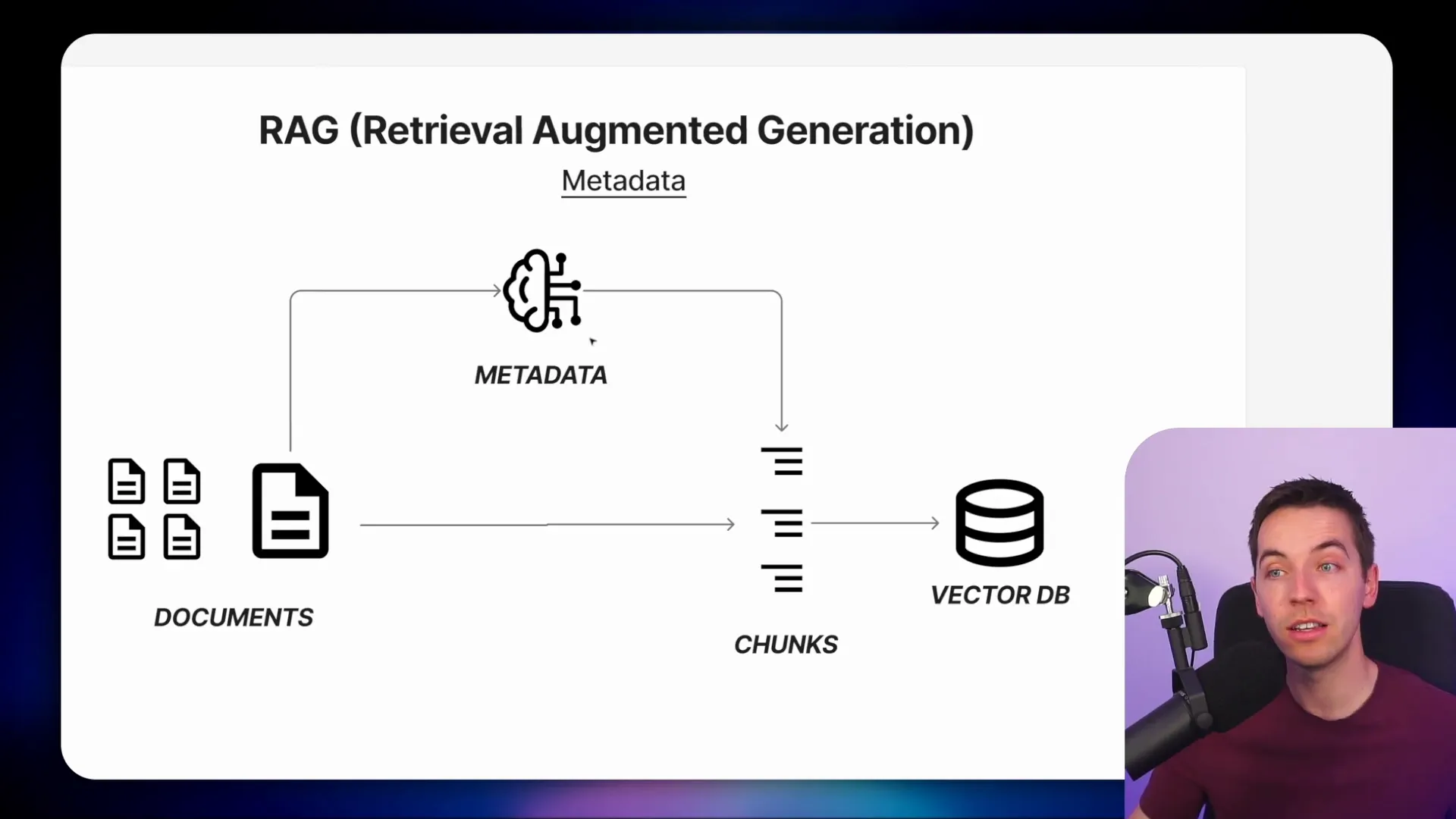
At the core of any RAG (Retrieval-Augmented Generation) pipeline is the ingestion phase. This is when you take your raw data—documents, web pages, PDFs—and break them into manageable chunks. These chunks are then stored in a vector database, which allows for fast semantic search based on embeddings.
However, just storing chunks of text isn’t enough for precise retrieval. During ingestion, you can enrich each chunk with metadata such as the document’s date, department, category, or any other useful attribute. This metadata acts as additional filters when querying the vector store, helping your agent to exclude irrelevant or outdated information.
For example, if you have HR policy manuals spanning multiple years, you want to make sure your agent only retrieves policies relevant to the correct year and department. Without metadata filtering, the agent might mix up policies from different years or departments, leading to inaccurate answers.
Dynamic Metadata Filtering with Supabase
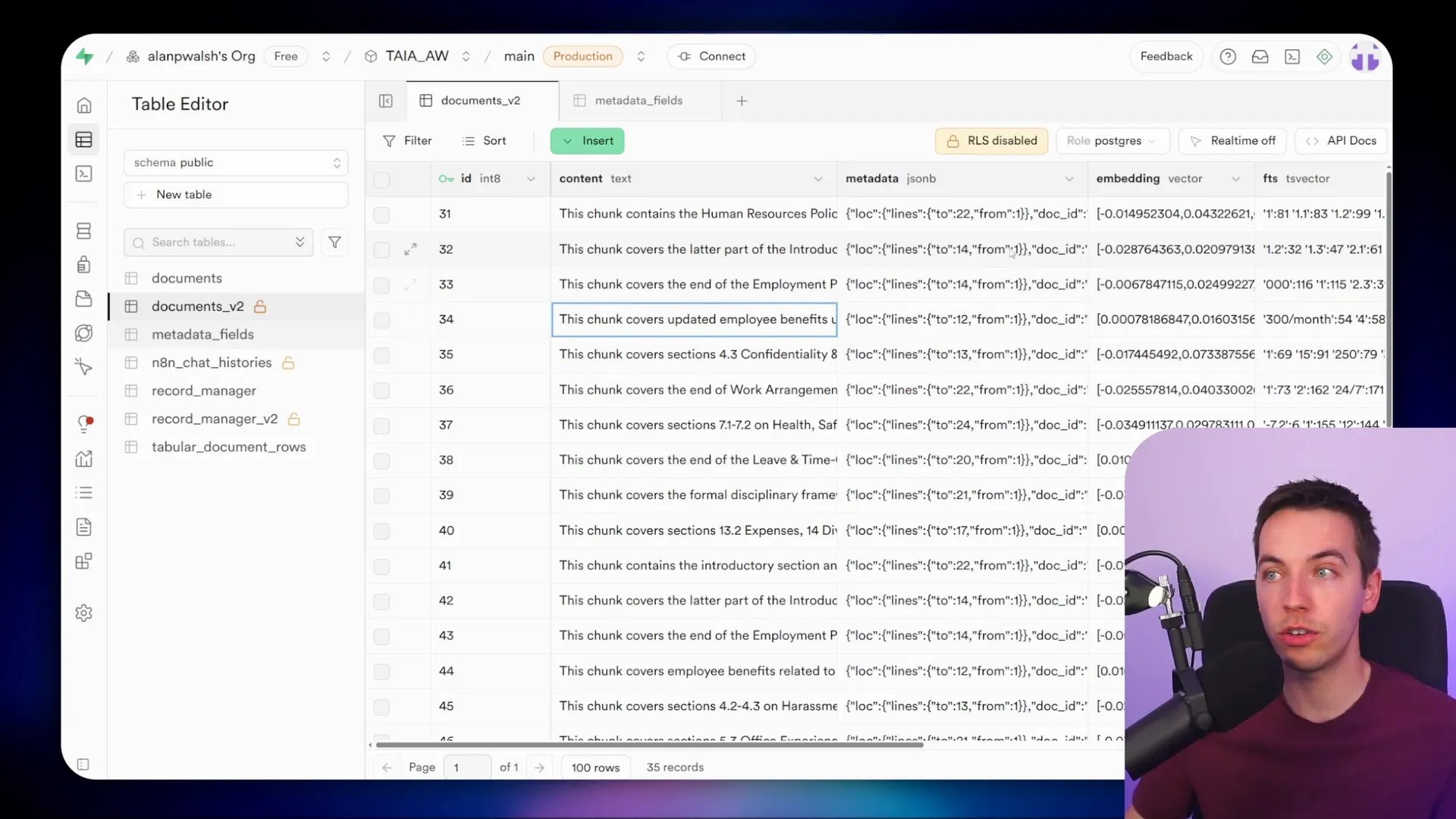
In my setup using Supabase, I created a separate table specifically for metadata fields. This table defines which metadata attributes should be captured and their allowed values. Because this table is linked directly to the ingestion and retrieval workflows, any changes to metadata fields get picked up automatically without manual updates.
For example, I defined two key fields for my HR policy documents: document date and department. The document date uses a specific datetime format, which you can adjust for more granularity if needed. When I inspect the vectors stored in Supabase, each chunk has metadata populated for both the department and document date. In my case, the document date was inferred from the content, but you could also extract this from file metadata, webpage meta properties, or even the ingestion timestamp.
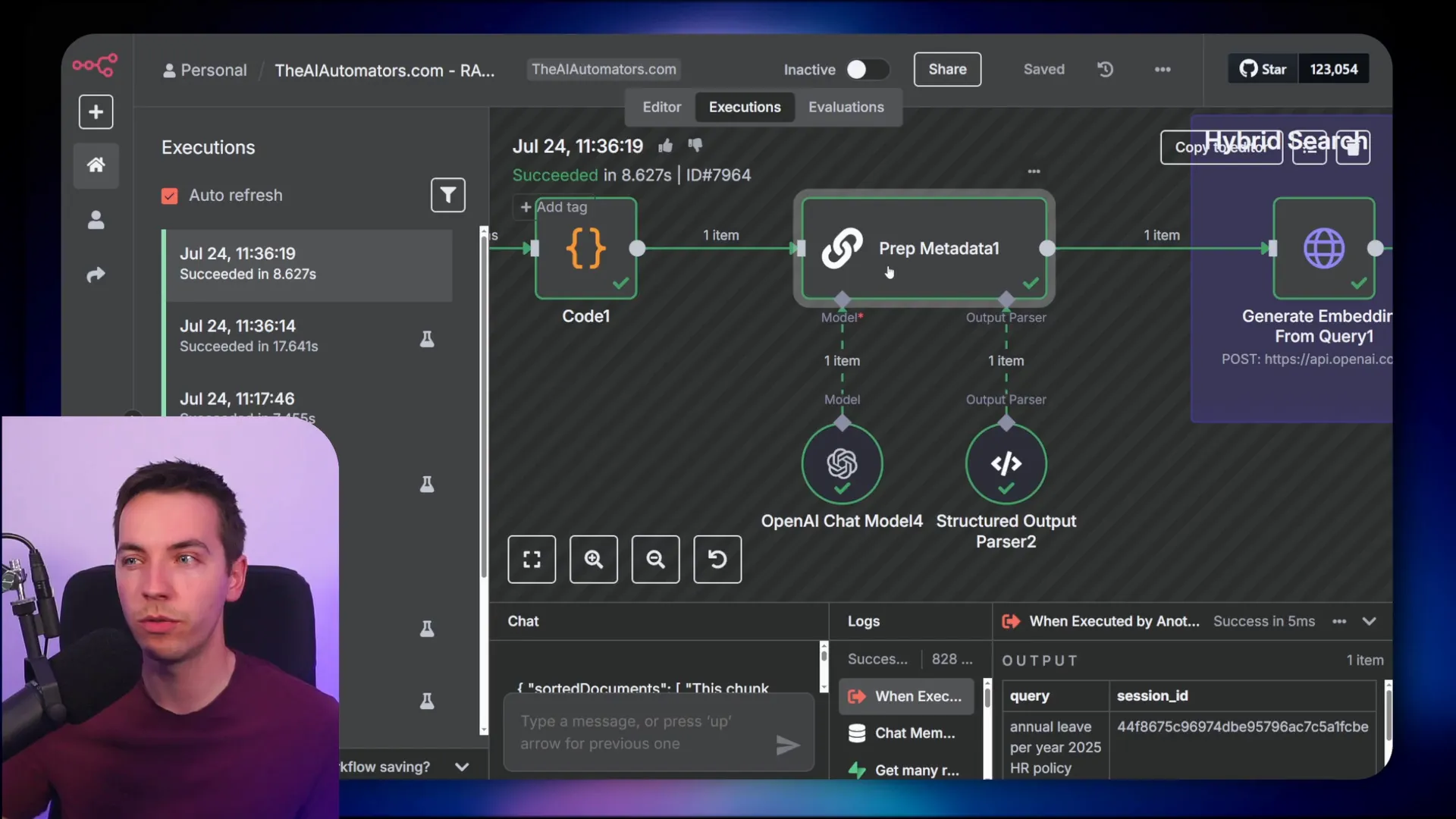
When I ask a question such as, “How much annual leave is there per year as per the 2025 HR policy?” the agent constructs a metadata filter dynamically. It excludes documents from other years and departments, ensuring that only relevant policies are considered in the answer.
This dynamic filter creation happens inside a workflow where the agent queries the metadata fields table to retrieve all filterable fields and their allowed values. Then, it formats this information into a system prompt that guides the AI to generate JSON output specifying the metadata filters to apply.
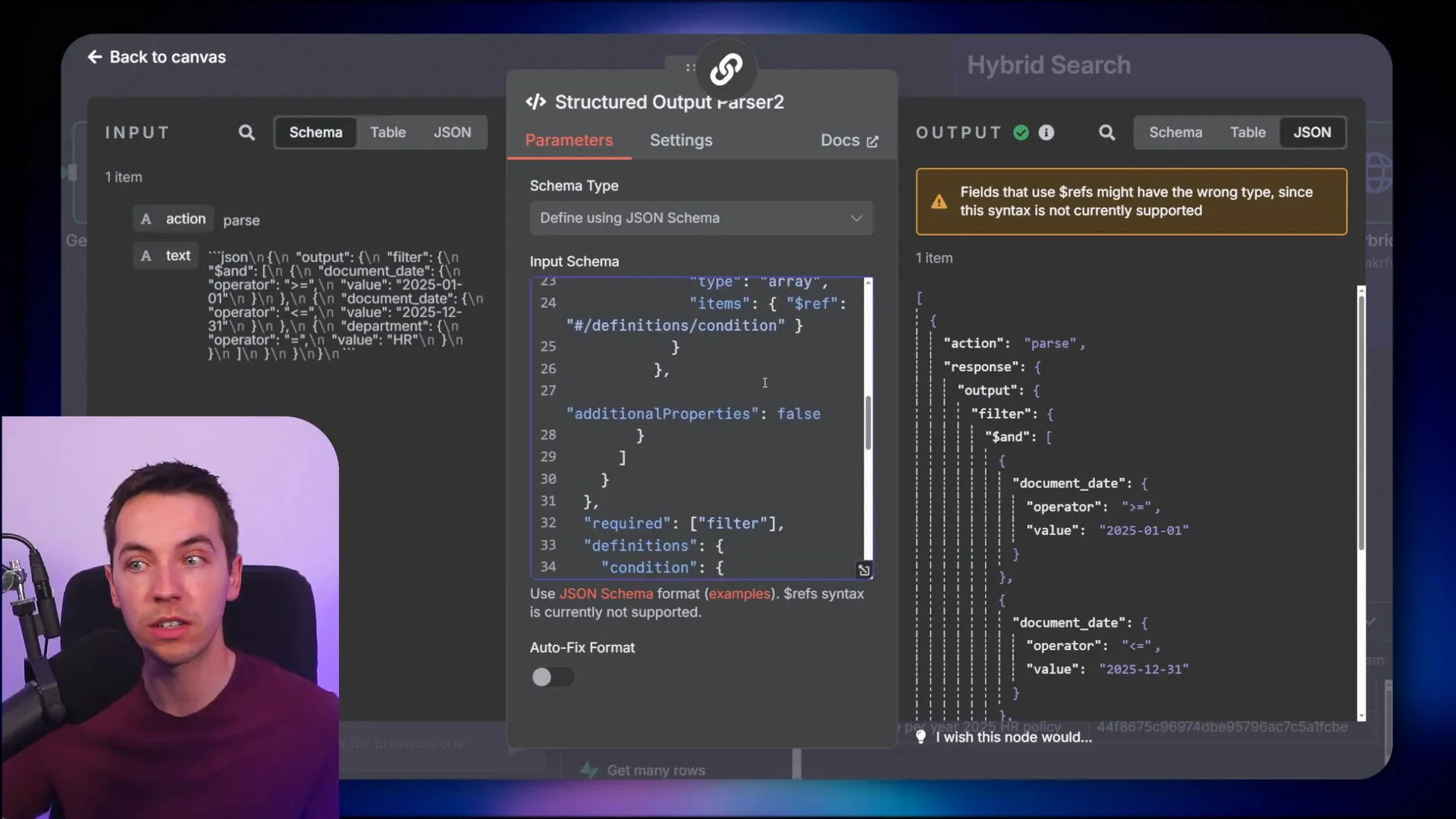
Using JSON Schema for Structured Metadata Filtering
One of the key innovations here is how the agent outputs these filters. Instead of using a typical “generate from JSON example” method, I employed a JSON schema to constrain the AI’s output. This schema defines the exact structure, data types, and operators that the AI can use when constructing filters. This approach prevents the AI from producing invalid or inconsistent filter formats.
The schema supports complex operations such as:
- Date range filtering (e.g., documents after a certain date and before another)
- Lists of allowed values (e.g., filtering by multiple departments)
- Numerical and logical operators (e.g., AND, OR conditions)
This allows the agent to build sophisticated filters on the fly without the need for large, complicated system prompts. The AI knows exactly what it can do and how to format its output.
Hybrid Search and Re-ranking for Better Retrieval
Beyond metadata filtering, I combined hybrid search techniques with the Supabase vector store. Hybrid search means combining semantic search (based on dense embeddings) with keyword-based search (using sparse embeddings). This dual approach improves retrieval accuracy, especially when some keywords are critical for matching.
When you look at the results after applying filters, you’ll see that only documents matching the correct department and date range are returned. Without these filters, the agent might retrieve outdated or irrelevant documents, especially if your vector database contains a large volume of data.
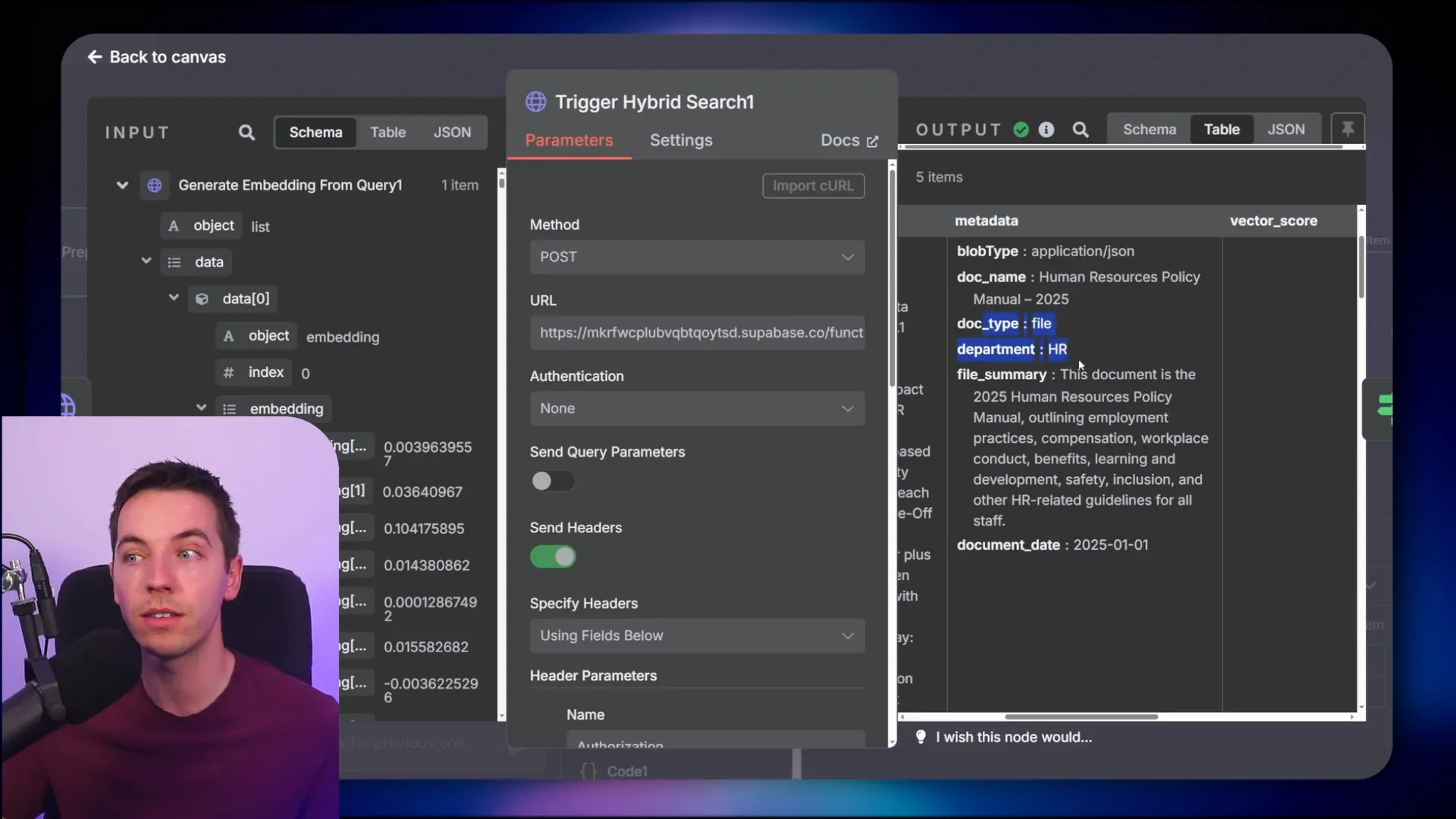
Finally, I added an optional re-ranking step using Cohere’s neural model. This step takes the retrieved chunks and reorders them based on their relevance to the original query. Re-ranking ensures the most pertinent information appears first, improving the overall quality of the agent’s response.
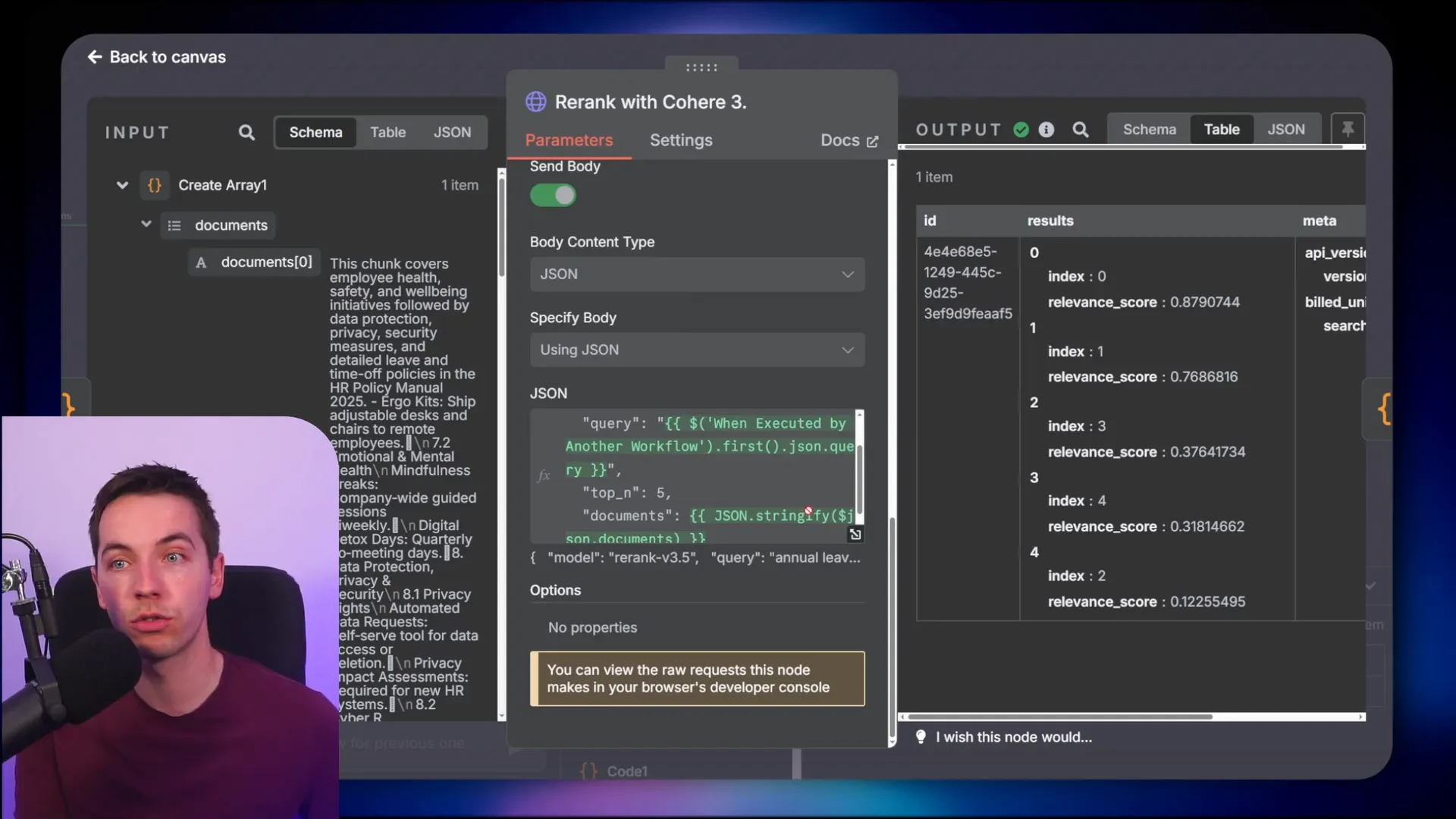
Ingesting Metadata with Supabase: A Detailed Walkthrough
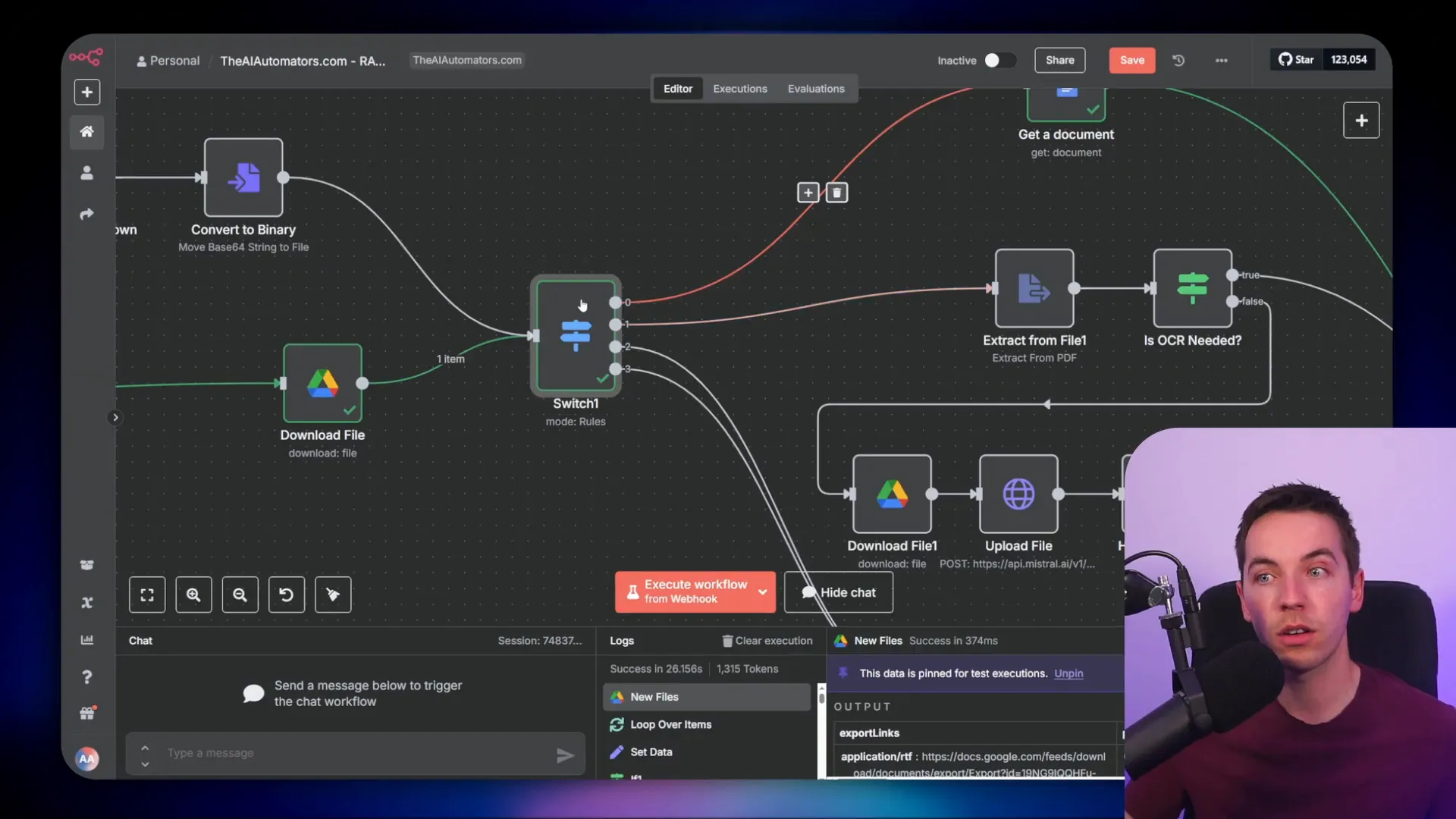
The ingestion pipeline starts by retrieving documents from a source, such as Google Drive. I set up a flow that loops through each file, using a switch node to handle different file types—Google Docs, HTML, PDFs, etc. Regardless of file type, the content eventually merges into a single text field for processing.
A key concept here is the record manager, which keeps track of all documents ingested into the vector database. It uses a hash of the content to detect changes, so updates happen only when the source data changes. This avoids unnecessary reprocessing.
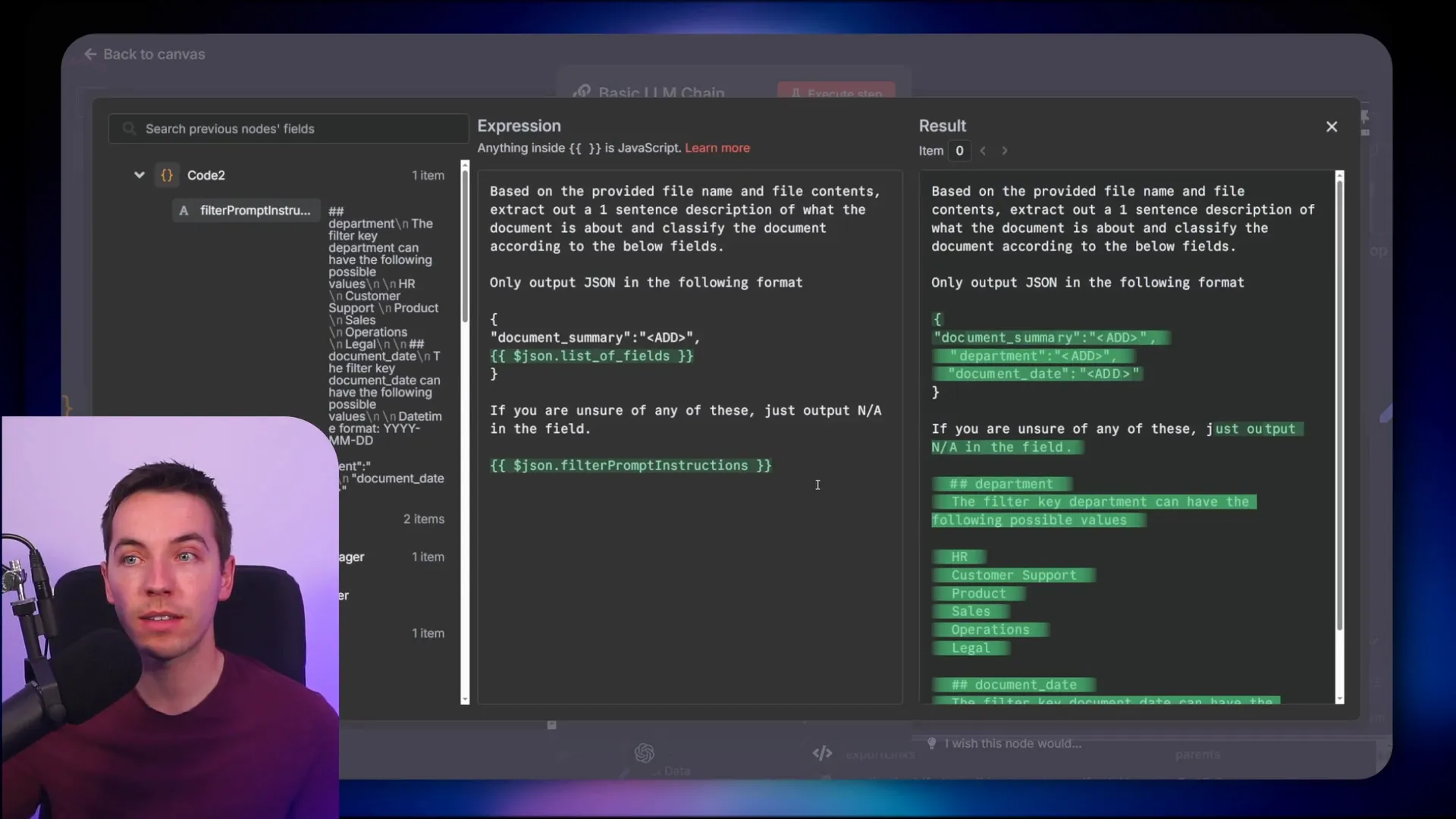
Once the document content is ready, I invoke a language model (LLM) chain that extracts metadata. It uses the first 500 characters of the document to generate:
- A one-sentence summary of the document
- Classification of the document by department and date
The system prompt dynamically injects the metadata fields and their allowed values from the metadata table. This way, the LLM knows exactly what fields to populate and with what options.
After metadata extraction, the document is chunked into smaller parts based on size, overlap, and separators. Each chunk then gets a brief description of its context within the document. This contextual retrieval technique prevents chunks from being misunderstood when taken out of context, improving the accuracy of the agent’s answers.
Finally, the chunks and their metadata are inserted into the Supabase vector store. The ingestion process archives the processed file to avoid duplication.
Metadata Filtering During Query Time with Supabase
When the agent receives a user query, it triggers a workflow that first fetches the available metadata fields and allowed values from the metadata table. This information is then used in a system prompt to instruct the AI how to construct filters relevant to the query.
The agent outputs a JSON object specifying which metadata filters to apply. For example, it might include filters like “department equals HR” and “document date between 2025-01-01 and 2025-12-31.”
Next, the query is converted into embeddings using OpenAI’s API. These embeddings, along with the metadata filters, are sent to a Supabase edge function that performs a hybrid search with the advanced filters applied.
The edge function acts as a bridge between n8n and the Supabase database, executing a database function that combines semantic search with metadata filtering. This database function was enhanced using AI assistance to support logical operators, lists of values, and complex date filtering.
The results returned are scored based on semantic and keyword matches, and filtered according to the metadata constraints. This ensures that the agent only works with documents that are truly relevant to the query.
Advanced Metadata Filtering with Pinecone
Pinecone’s native vector store node in n8n is quite limited and does not support advanced metadata filtering out of the box. To overcome this, I extended a hybrid search blueprint to include metadata filtering similar to the Supabase version, but adapted for Pinecone’s capabilities.
The ingestion process starts with extracting text from a PDF document. Although Pinecone supports vector storage, it doesn’t provide relational database features like Supabase, so metadata handling must be done differently. I manually specify metadata fields and their allowed values in the prompt used for metadata extraction.
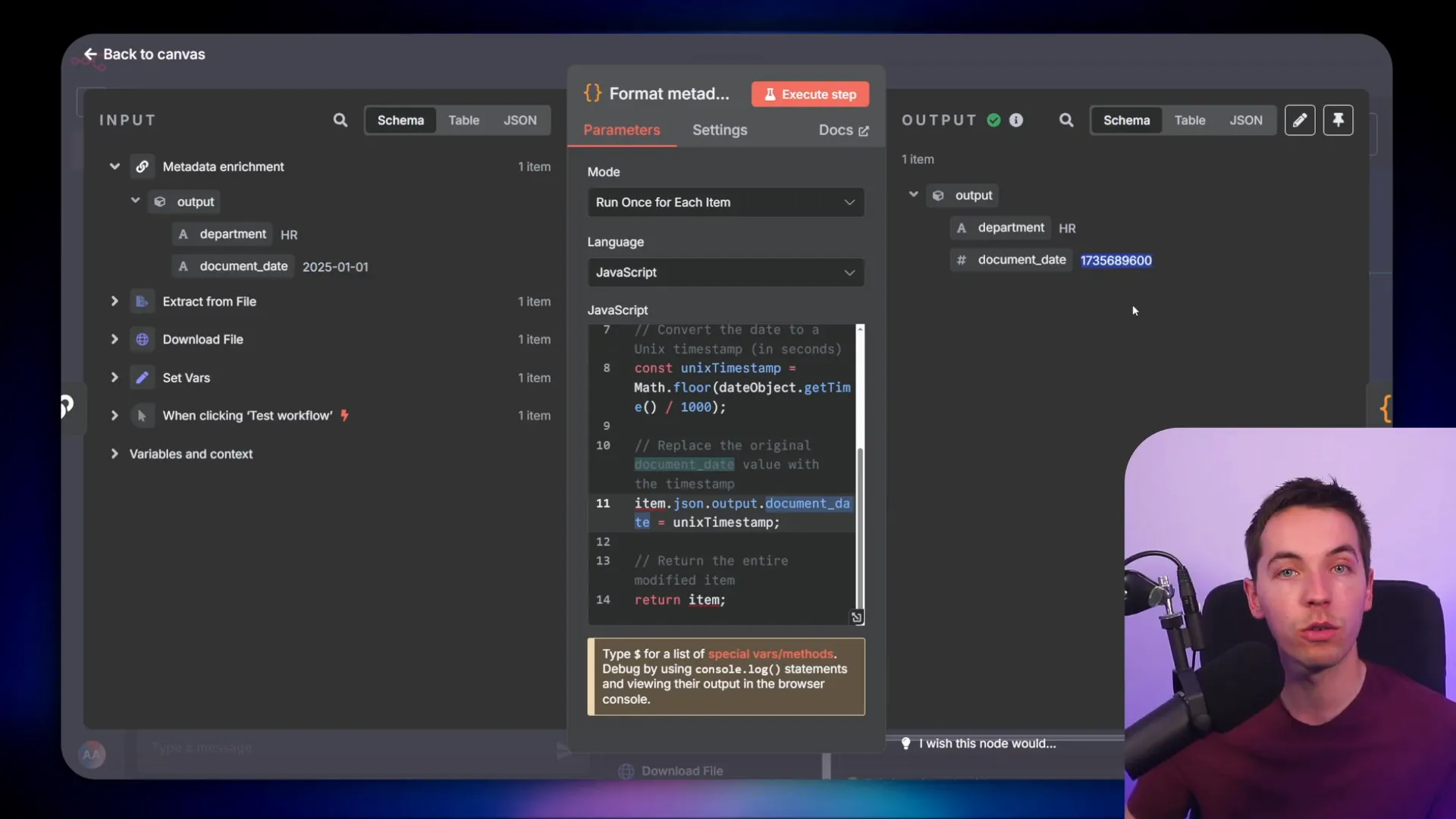
One challenge with Pinecone is filtering by date. Pinecone requires date filters to be in the form of UNIX timestamps (integers), not human-readable strings. To handle this, I convert document dates like “2025-01-01” into UNIX timestamps during ingestion.
This conversion is done in a code node that processes the metadata before it is sent to Pinecone. Later, when the agent creates filters during query time, it also converts human-readable date filters into UNIX timestamps for consistency.
The document is chunked similarly to the Supabase pipeline, and both dense and sparse embeddings are generated for hybrid search. The metadata fields (department and document date) are mapped into each chunk before the data is upserted into Pinecone.
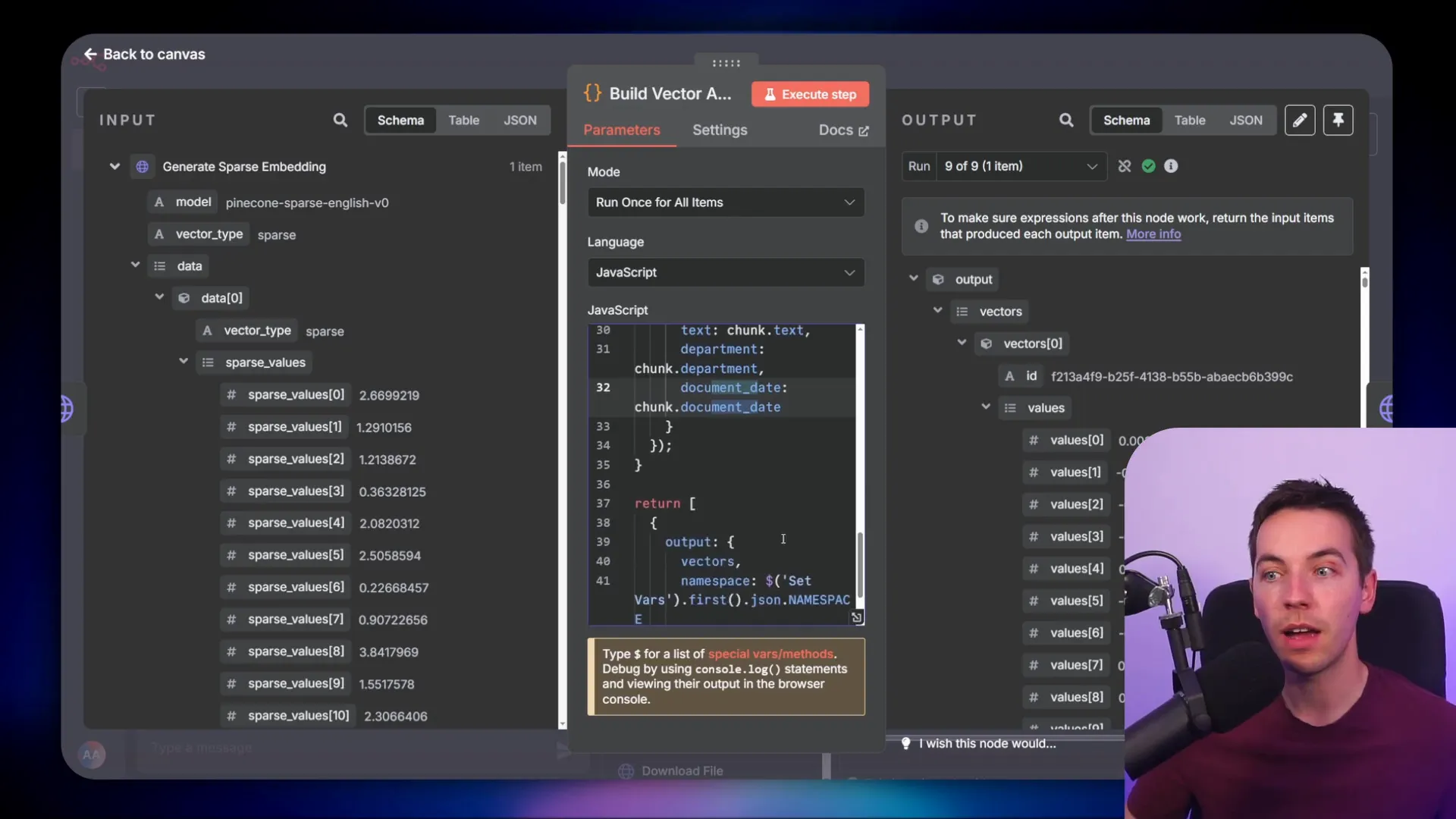
Querying and Filtering in Pinecone
The AI agent setup for Pinecone follows a similar architecture to Supabase, with an OpenAI chat model and simple memory. The agent calls a separate workflow to handle vector store queries.
When a query like “Give me HR policies for 2025” is received, the agent generates metadata filters including department and date ranges. These filters are converted to the proper format with UNIX timestamps and passed along with query embeddings to Pinecone’s query endpoint.
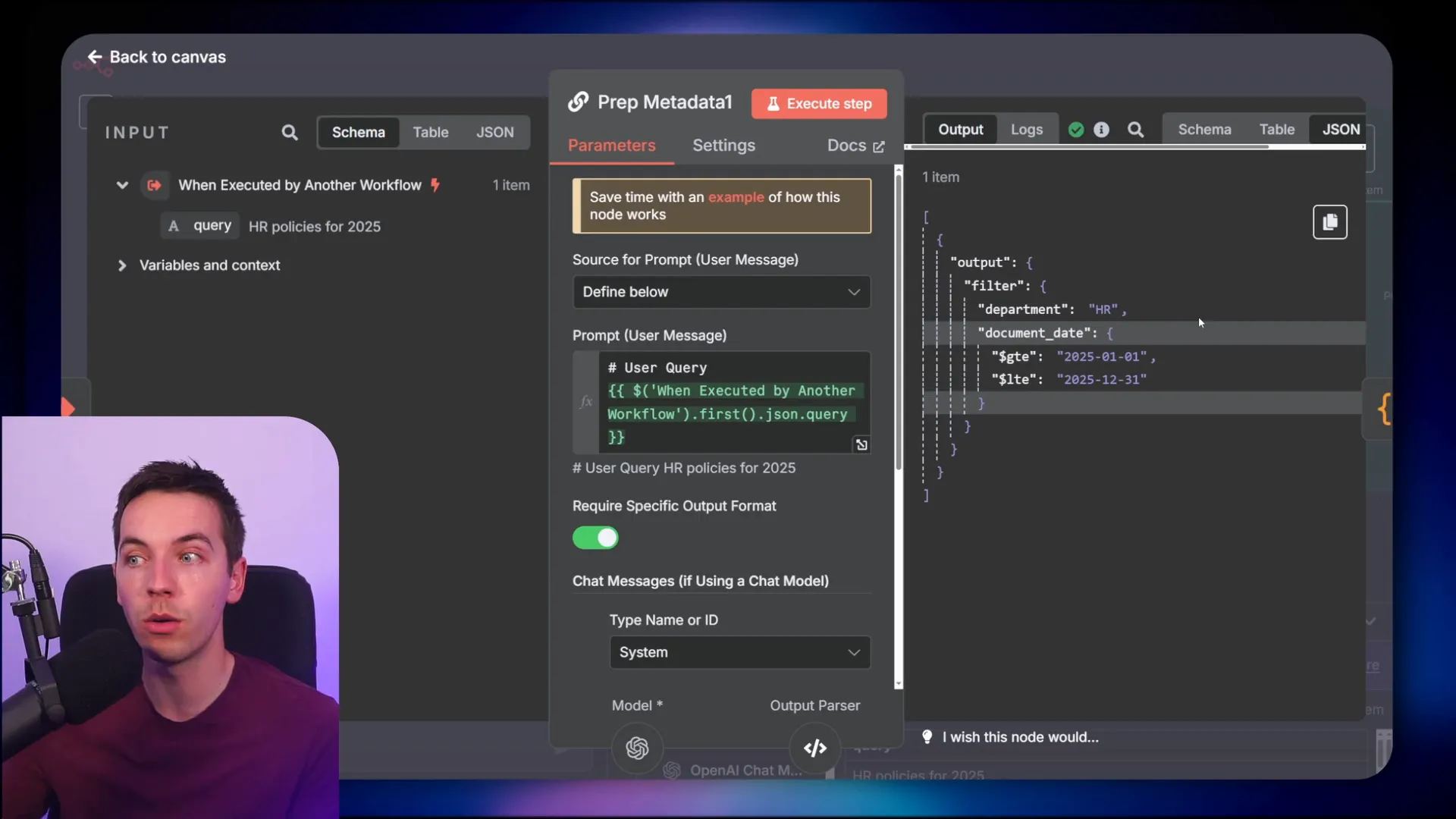
Pinecone’s filtering syntax is different from Supabase’s, so I adapted the JSON schema accordingly. I used AI to update the schema based on Pinecone’s documentation to ensure the filters conform to their expected structure.
The system prompt remains simple because the AI understands the schema and how to generate the correct filter format. This minimalism helps keep the prompt clean and efficient.
Best Practices for Metadata Filtering
Metadata filtering can significantly improve the accuracy of your RAG agent’s retrieval, but it’s important to keep it as high-level as possible. If you make metadata fields too granular, the AI might apply filters inconsistently between ingestion and retrieval, leading to confusion.
Typical use cases for metadata filtering include:
- Segregating data by department or company
- Filtering by product types or categories
- Filtering documents by date to exclude outdated information
Combining these filters with advanced RAG techniques like hybrid search, contextual retrieval, and re-ranking creates a powerful system that retrieves relevant, up-to-date information quickly and accurately.
Final Notes on Implementation
Implementing these advanced metadata filtering techniques requires integrating various components: metadata tables, dynamic prompt generation, JSON schema output parsing, and edge functions or API calls for hybrid search. While this might sound complex, I relied heavily on AI tools to generate the JSON schemas and database functions, which streamlined the process.
Both Supabase and Pinecone have their strengths. Supabase offers a relational database alongside the vector store, making it easier to manage metadata in dedicated tables. Pinecone excels at vector search but requires extra handling for metadata filtering and date formats.
By following this approach, you can build RAG agents that are not just powerful but also precise and context-aware, delivering answers based on exactly the right subset of your data.
