Introduction
I created an automation that takes nearly any file type — documents, slides, spreadsheets, images, audio — and turns it into consistent, searchable content for a Retrieval-Augmented Generation (RAG) agent. In the accompanying walkthrough I show three practical ways to do this: LlamaParse for ease and breadth, Docling for a self-hosted route, and Mistral OCR for fast PDF-first processing. This article breaks down how each approach works, how I wired them into an n8n pipeline, and what settings helped me get reliable Markdown, tables, and images into a Supabase vector store so an agent can answer questions intelligently.
Why this matters
Most AI agents break down when input files are messy. They miss tables, they lose layout and images, or they clutter the vector store with noisy text. I wanted one flow that could accept dozens of formats, preserve structure, and output normalized Markdown that I could chunk, embed, and index. That way the agent gets semantically relevant passages and the ability to show images and tables when needed.
I built a pipeline in n8n that watches a folder (Google Drive in my example), sends files to a parser, receives a structured Markdown output, splits content into chunks, creates embeddings using text-embedding-3-small, and stores those vectors in Supabase. The agent then queries Supabase and uses the returned context to respond.
Overview of approaches
- LlamaParse (LlamaCloud): Quick setup, broad file compatibility, returns rich Markdown and optional HTML tables. It runs on LlamaCloud and supports async jobs with polling or webhook callbacks.
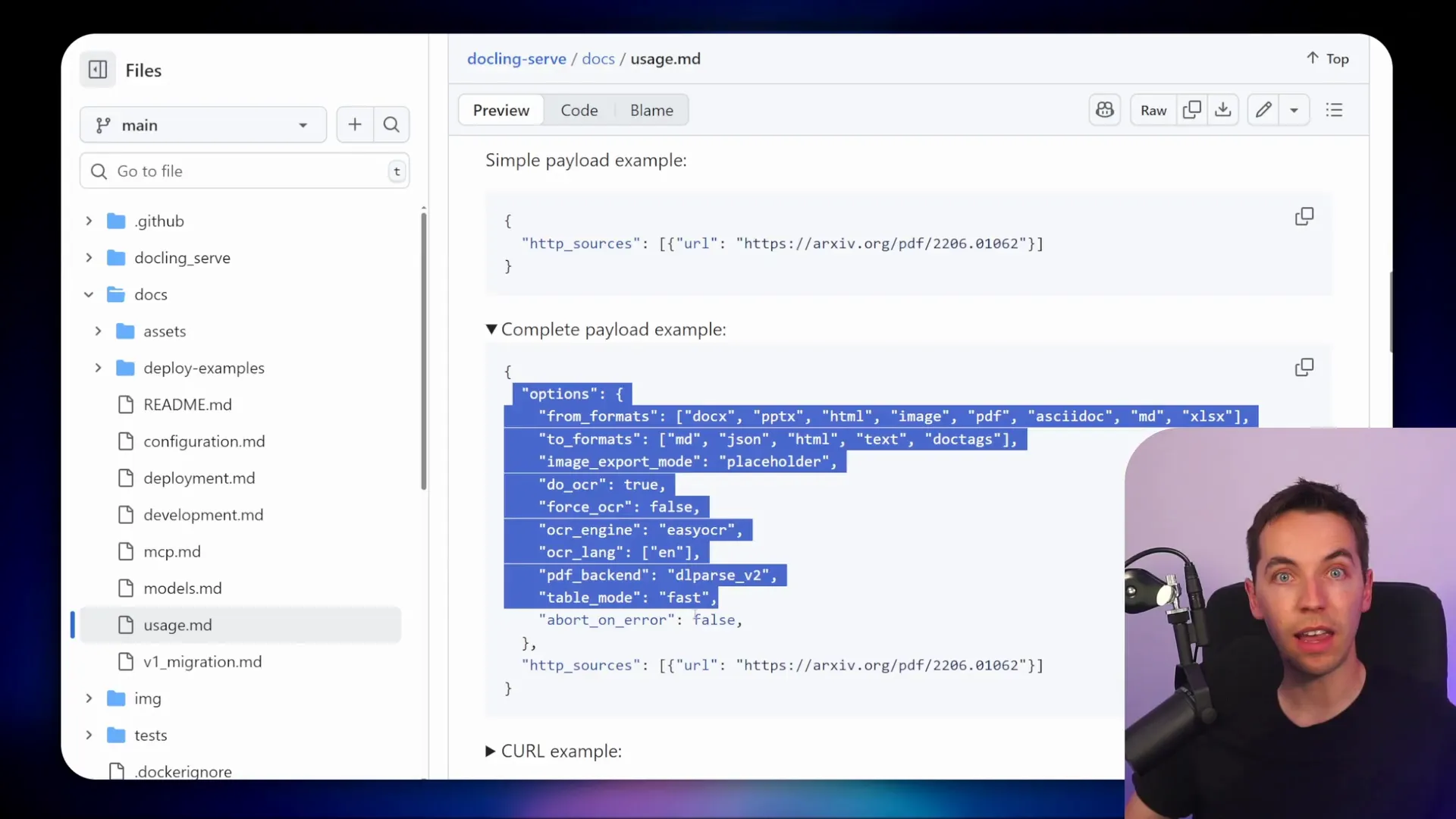
- Docling: Open-source, self-hosted by IBM. Great when you want local control and to avoid external APIs. You deploy it (I used Render), then call its v1/convert endpoint from n8n.
- Mistral OCR: PDF-first, very fast and affordable. It can also return extracted images which helps multimodal RAG setups.
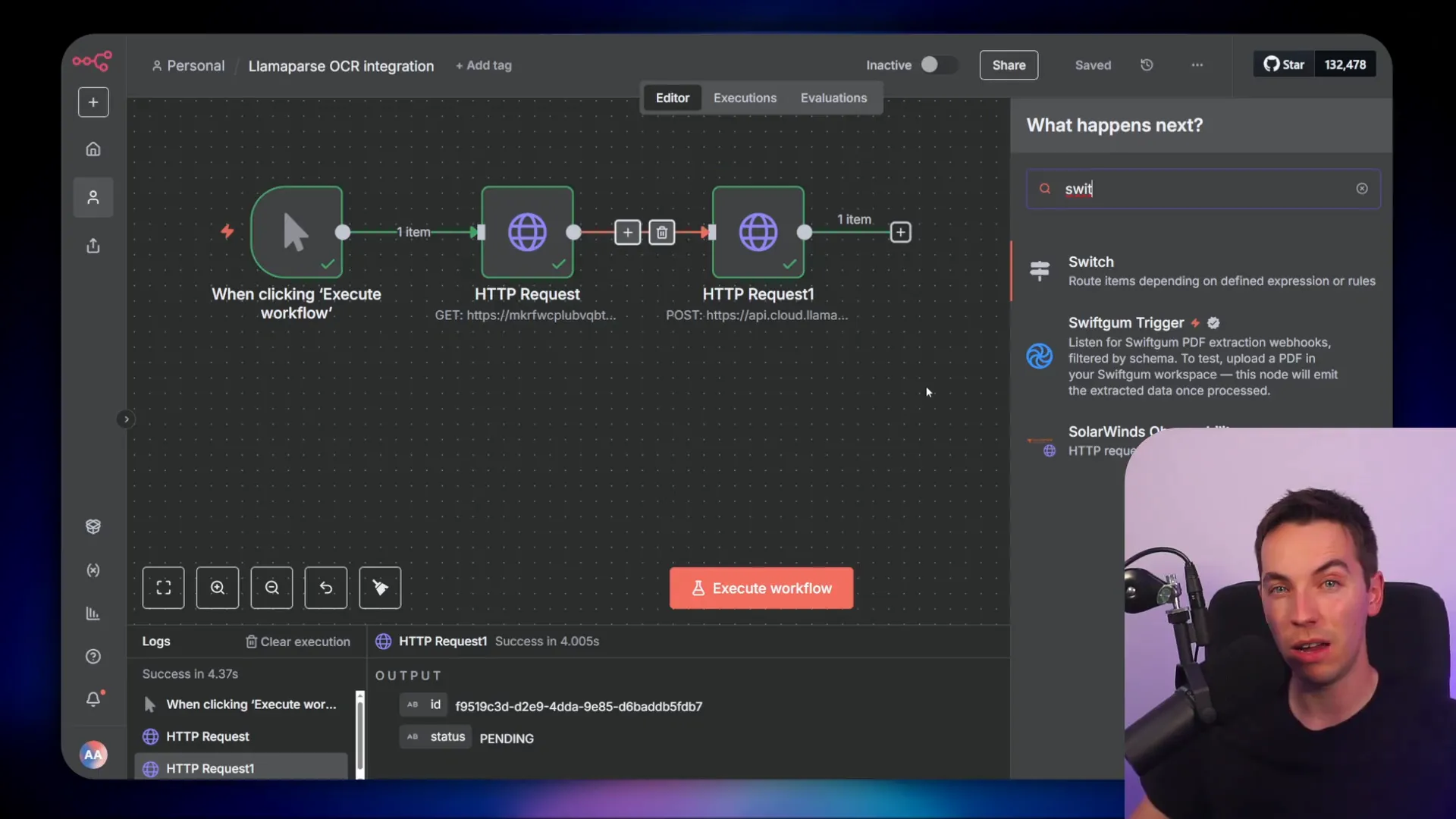
Setting up LlamaParse in n8n
I started with a simple HTTP request node in n8n and imported a cURL example. That gave me the base fields prefilled. The trickiest part is authorization and handling LlamaCloud’s asynchronous job pattern.
First, I moved the API key out of plain text and into n8n credentials. I selected “Authentication” → “Generic Credential Type” and then created a header credential. I named the header “authorization” because that matches the header key the API expects.
When you create the credential value, the header should be “Bearer “. In n8n, set the expression type to “Bearer” or paste “Bearer YOUR_API_KEY” into the credential value. Save it and then remove any plain-text Authorization header you had left in the HTTP node. The HTTP node will pick up the credential and inject it securely into each request.
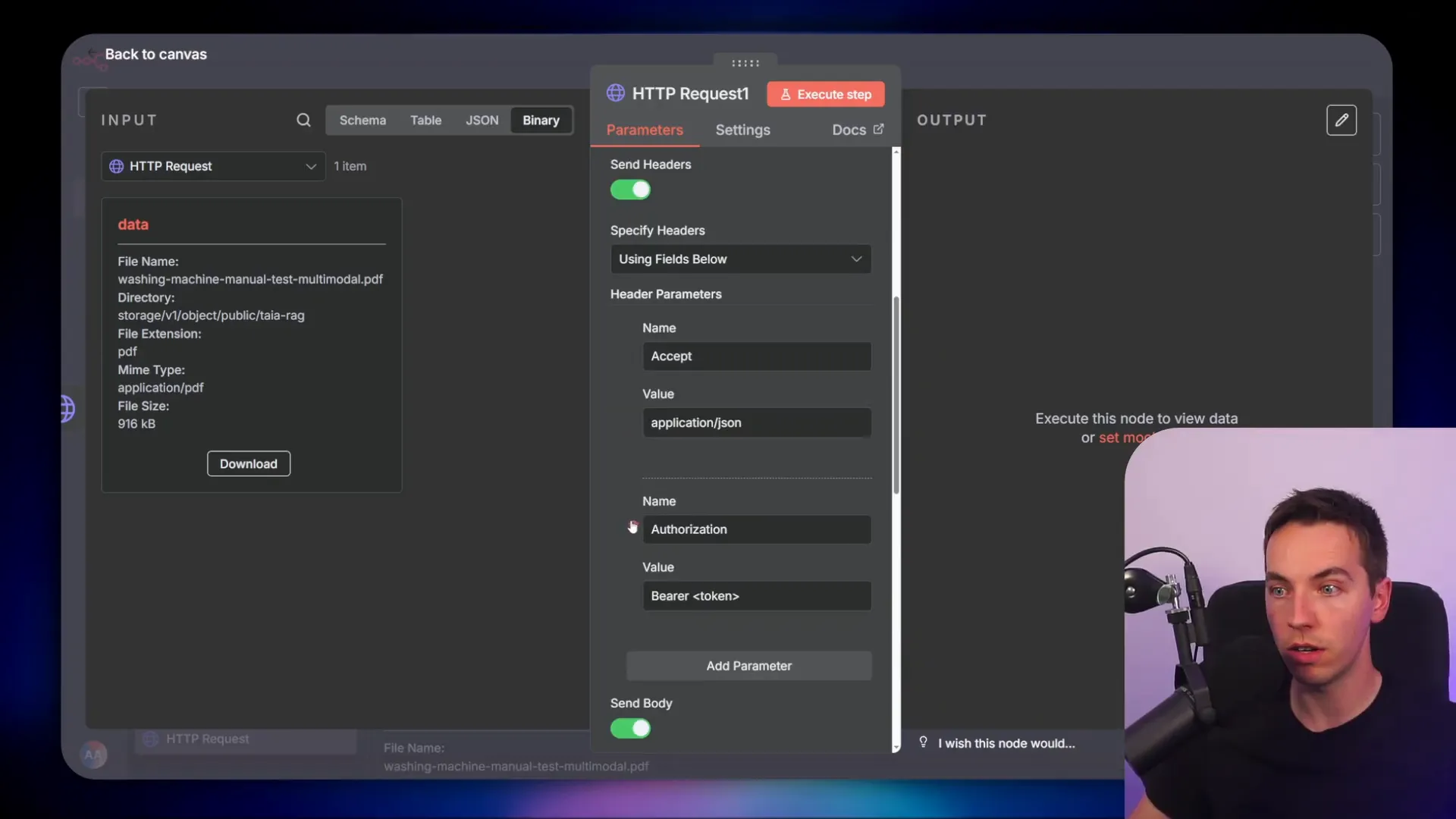
Doing this keeps your workflow clean and lets you reuse the same credential across requests. It also avoids accidentally checking keys into version control or sharing them in logs.

Request options that matter
I enabled a number of options in the request body that changed how the parser returned results:
- Outline table extraction: Set this to true so the parser attempts to detect logical sections and tables in the document.
- Output tables as HTML: I set this to true initially. HTML tables allow merged cells and better fidelity for complex spreadsheets and slide tables. There are trade-offs: HTML is richer, but sometimes Markdown tables are easier to work with downstream.

With those options in place, the initial upload request sends the file to LlamaCloud and returns a job object rather than the parsed content. LlamaCloud processes the file asynchronously.
Asynchronous jobs: polling vs webhook
When you upload a document you usually see an immediate response that contains an ID and a status like “pending”. That means the server accepted the job but hasn’t finished processing. You have two ways to get the parsed content out:
- Polling: Periodically call a job status endpoint until it reports success. Then request the final result.
- Webhook callback: Provide LlamaCloud a public URL. When the job finishes, LlamaCloud POSTs the results to your endpoint, and you process them on arrival.

I tested with polling because it’s simple to set up in n8n and works during development. Polling has predictable control flow in a workflow. I used a switch node to check the job status and, if still pending, waited a few seconds and tried again.
How I implemented polling in n8n
My flow looked like this:
- HTTP node uploads document and returns a job ID.
- Switch node checks if status is “pending.”
- If pending, a Wait node pauses for a few seconds and the HTTP node polls the job details endpoint again.
- Once status changes to “success”, a final GET request fetches the parsed Markdown result.
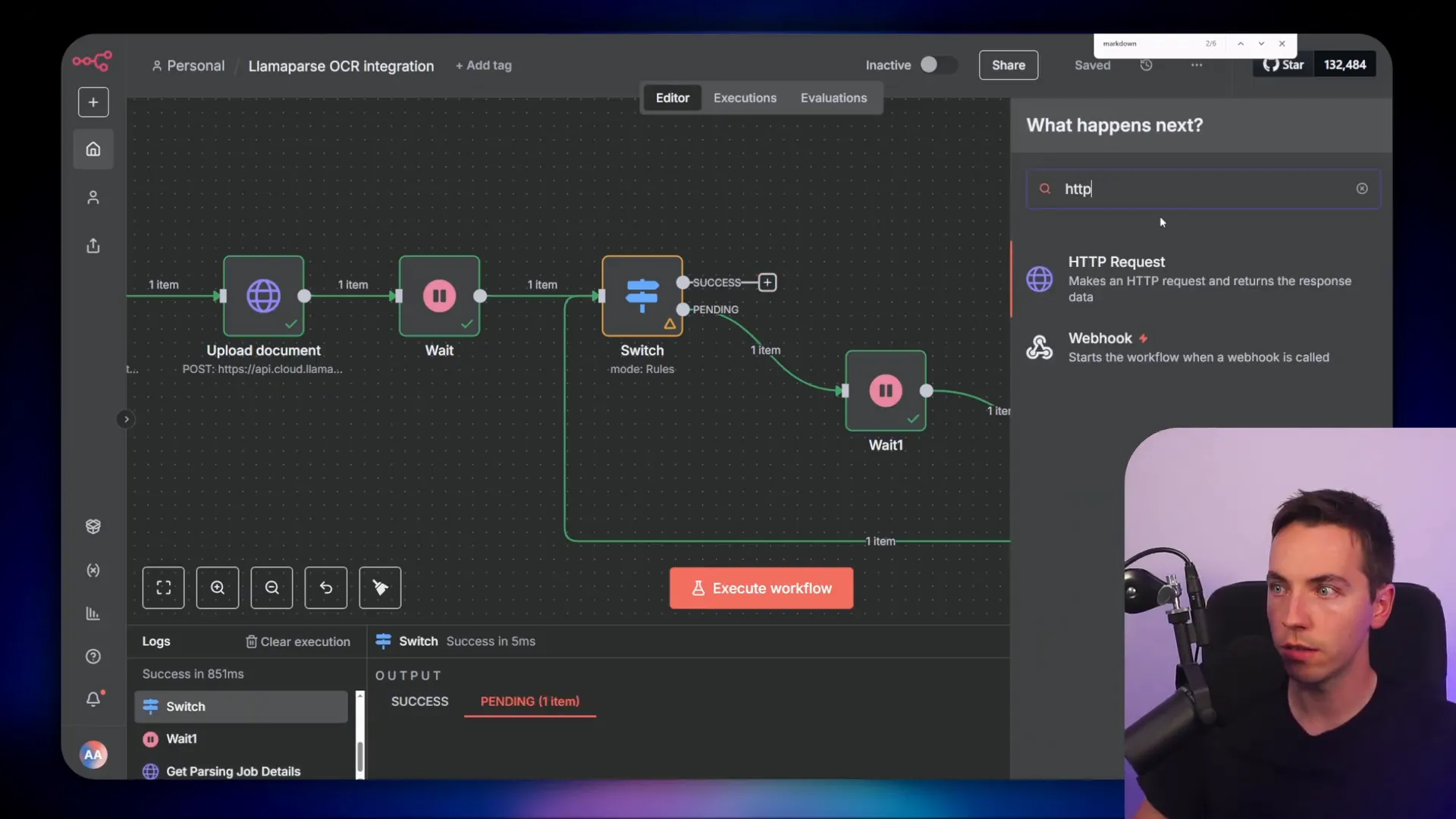
Polling is simple, but it can be wasteful at scale. If you plan to process many large files, a webhook is more efficient. You host a public endpoint and give that to LlamaCloud in the request form-data body. When processing completes, LlamaCloud posts to your endpoint with the job details so you can pickup and fetch the parsed result.
Fetching the parsed Markdown
After confirming the job is successful, I call the LlamaCloud endpoint that returns raw Markdown. The docs show several formats and I chose Markdown for easy downstream chunking and to preserve headings, code blocks, and inline images.
The final GET request uses the job ID returned in the upload response. In n8n I dynamically replace the job ID placeholder with the ID from the switch node. Once the GET returns, I extract a Markdown string that represents the whole file with embedded structure and table HTML where requested.

Why Markdown?
Markdown is portable. It keeps headings, lists, code, and image references intact. It also plays well with chunkers that use headings to create semantically coherent passages. If you prefer fully faithful table handling, you can keep HTML tables and render them in a UI later.
From parsed Markdown to vector store
Once I had Markdown, the next steps were standard for RAG ingestion:
- Normalize metadata (filename, source URL, timestamps).
- Chunk the Markdown into passages with size and overlap settings I control.
- Create embeddings for each chunk using text-embedding-3-small.
- Write vectors and metadata into Supabase’s vector table.
I used a chunk size that balanced context with cost. Too small and embeddings lose semantic richness. Too large and you pay more and risk hitting token limits. I generally used 500–800 token-equivalents per chunk with a 100–150 overlap when passages spanned headings.
Deduplication and idempotency
One common problem is indexing the same file twice. I solved it by computing a deterministic document ID, often a hash based on filename and file size or a storage object ID. Before ingesting, I checked Supabase for an existing vector entry with the same document ID. If found, I updated chunks or skipped ingest depending on whether I wanted to replace or append new content.
Keeping a document-level metadata field like source_id makes audits and deletions straightforward. If a user re-uploads, you can choose to soft-delete old vectors, overwrite, or version them.
Embedding model and cost considerations
I used text-embedding-3-small for embeddings. It’s compact enough to be affordable and good enough for semantic retrieval. If you prefer higher-resolution semantic search, choose a larger model, but expect higher cost per embedding.
Plan embeddings by estimating pages per document, average chunks per page, and embedding cost per chunk. Many services offer free-tier credits and per-page pricing. You should budget for parsing charges (some parsers charge per page) plus embedding costs and storage. I recommend running a few representative documents and measuring the chunks-per-document before projecting costs for a large corpus.
Practical LlamaParse tips
- Agentic mode: Turn it on for documents intended to be actionable or to include agentic instructions. It helps the parser surface steps and ordered lists clearly.
- High-resolution OCR: Use high-res OCR for scanned PDFs or image-heavy documents. It increases CPU work and cost, but preserves layout and embedded images better.
- Adaptive long-table handling: If a table is huge, set a long-table strategy so parsing either breaks it into logical chunks or returns CSV alongside HTML. Large tables can consume tokens quickly and produce noisy embeddings if not managed.
- Outline extraction: This helps metadata and chunking because headings become explicit structural markers in your Markdown output.
- Tables as HTML: Keep tables as HTML when you want to preserve merged cells and complex formatting for downstream presentation.
These settings let you tune for fidelity or for lower cost and simpler outputs depending on your use case.
Integrating into a RAG pipeline
Here’s the full pipeline I built in n8n, step by step:
- Trigger: Google Drive watch node detects a new file.
- Store: Save the file to Supabase or a blob store so it has a public or internal URL.
- Parse: Send an HTTP request to your parser (LlamaCloud, Docling, or Mistral OCR).
- Wait/Poll: Either poll job status or receive a webhook notification when parsing finishes.
- Retrieve: GET the final Markdown (or JSON) parse result.
- Normalize: Extract metadata, sanitize Markdown, and optionally extract images and attachments.
- Chunk: Split the Markdown into chunks with a consistent strategy that accounts for headings and tables.
- Embed: Call text-embedding-3-small to generate embeddings for each chunk.
- Store: Insert vectors and metadata into Supabase’s vector table or another vector DB.
- Agent: Query the vector DB for top-k relevant chunks at runtime and pass them as context to an LLM for answering or acting.
At critical points I included checks and deduplication to avoid reindexing the same doc. I also preserved a mapping between chunk ID and original document so I could later display the source or return a link to the original file.
Introduction to Docling
Docling is an open-source parser built by IBM. I chose it because I wanted a fully self-hosted option that avoids per-page charges and external APIs. With Docling you run the parser in your environment, tune memory and CPU settings, and control the data flow.

Deploying Docling
I deployed Docling to Render for a quick test. The deployment exposed a v1/convert endpoint that accepts JSON describing the source (a URL or file). The steps I used were:
- Spin up a Render service and point it to the Docling Git repo.
- Configure environment variables for resource limits and any optional OCR keys if you want to plug in external OCR engines.
- Deploy and test the UI to upload a sample file.
- Call the v1/convert endpoint from n8n to convert sources into structured Markdown/JSON.
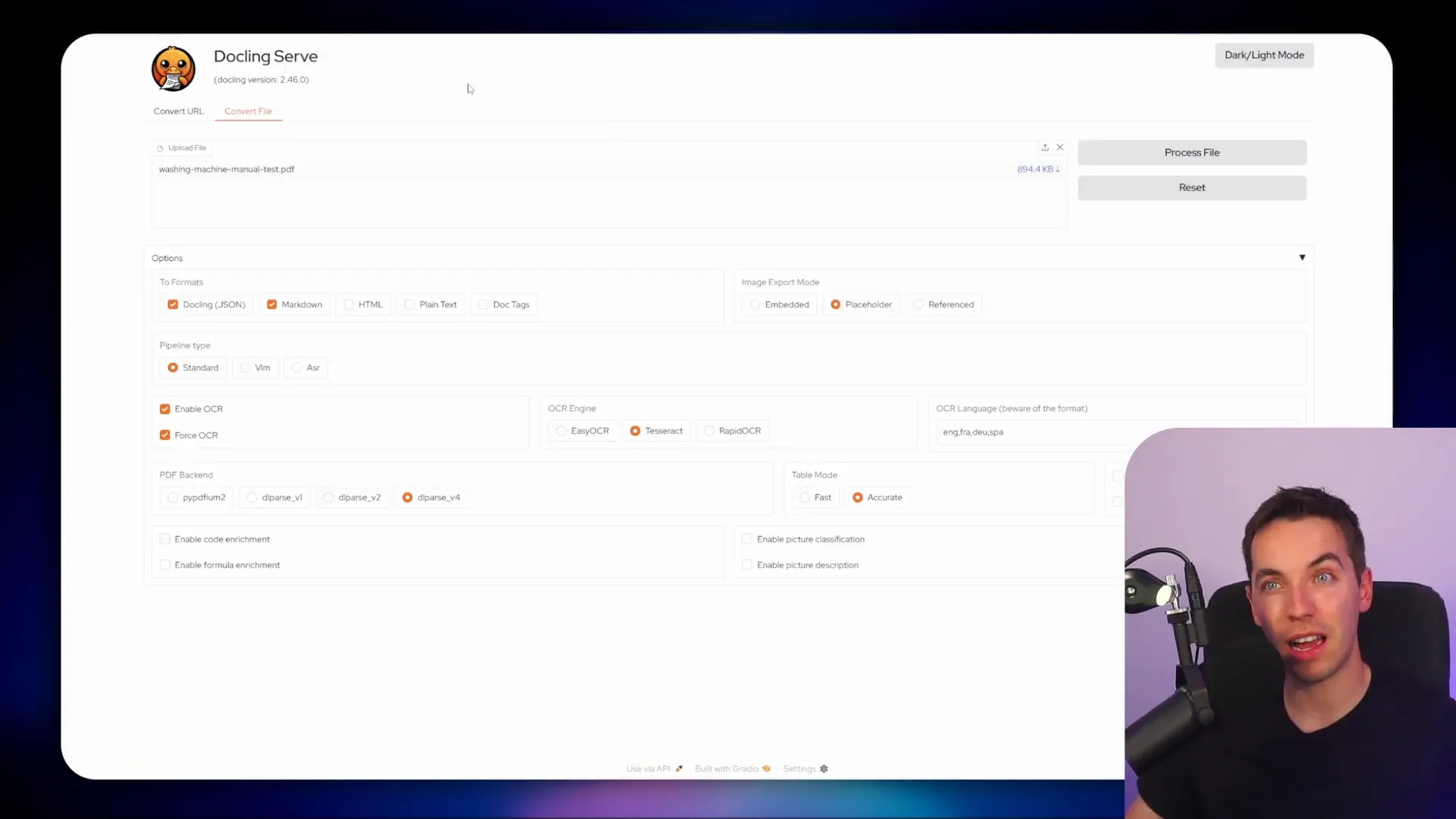
Docling offers a simple API: you POST a JSON payload describing your source and options. You can include a public URL so Docling pulls the file, or it can accept multipart uploads. The API returns a synchronous result for simple cases or an async job for larger files depending on your configuration.
Gateway pattern for Docling
Since Docling runs on your infra, you often don’t want to expose it directly to the internet. I used a gateway pattern that keeps Docling private but allows controlled access:
- Put a minimal public gateway in front of Docling.
- The gateway requires a basic auth username/password and an API key header.
- Requests that pass both credentials are proxied to the internal Docling instance.
This approach gives you a single place to log requests, rate limit, and add authentication without changing Docling. It also helps with safe public endpoints when handling external uploads.

Constructing the v1/convert request
The v1/convert endpoint expects a JSON body. The basic structure contains source info and options for parsing. A typical payload I used looked like this in conceptual terms:
- Source type: http or uploaded file.
- Source URL: public HTTP(S) link or signed URL from Supabase storage.
- Options: output format (markdown, html), OCR settings, table extraction flags.
- Callback URL: optional webhook for async jobs.
I used signed URLs from Supabase storage as the HTTP source so Docling could pull files without exposing storage publicly. Docling then returned structured Markdown which I fed straight into my chunker and embedder.
Mistral OCR for PDF-only workflows
When my corpus was mostly PDFs, I tested Mistral OCR. It’s fast, affordable, and tuned for PDF layouts. If you only need PDFs handled and want high throughput, it’s a good choice.
Mistral can return both plain extracted text and the original images extracted from the PDF. That’s useful for multimodal agents that might show images alongside answers or need to process diagrams separately.
When to pick Mistral OCR
- You have mostly machine-generated or scanned PDFs.
- You care about speed and cost for large PDF batches.
- You want optional extracted images to support image-based question answering.
If your content contains a lot of PPTX, DOCX, Excel, or audio files, LlamaParse or Docling give broader format compatibility. For pure PDFs, Mistral OCR is hard to beat on price and speed.
Putting it all together: example flows
Here are three practical flows I used depending on constraints and priorities.
Flow A — Fast setup with LlamaParse (good for mixed formats)
- Watch: Google Drive watch node.
- Upload: Save file to Supabase and get a URL.
- Parse: HTTP POST to LlamaCloud with outline and table options.
- Poll webhook: Poll job status every few seconds until success, then GET Markdown.
- Chunk & Embed: Split Markdown and create embeddings with text-embedding-3-small.
- Store: Insert vectors into Supabase vector table.
- Query: At chat time, fetch top-k chunks and provide them to the LLM.
Flow B — Self-hosted with Docling (privacy / cost control)
- Watch: Google Drive watch node.
- Upload: Save to internal storage (Supabase private bucket).
- Convert: Send v1/convert to Docling gateway with signed URL and options.
- Retrieve: Get structured Markdown from Docling (sync or async).
- Chunk & Embed: Same as above.
- Store: Supabase vector table.
Flow C — PDF-first with Mistral OCR
- Watch: Google Drive watch node limited to PDFs.
- Upload: Save PDF to a public/presigned URL.
- Parse: Call Mistral OCR, asking for extracted images.
- Chunk & Embed: Convert OCR text to chunks and embed. Store images in object store linked by metadata.
- Store: Supabase for text vectors; object store for images with references in vector metadata.
Common pitfalls and how I avoided them
- Missing images: Some parsers drop images unless you request image extraction. If images matter, enable image return or extract images separately and store them with metadata linking back to chunks.
- Large tables producing poor embeddings: Break huge tables into smaller CSV exports or keep as HTML and store a separate CSV file reference. Then only embed descriptive text or summaries rather than every table cell.
- Duplicated indexing: Use a deterministic source_id to avoid reindexing. Check Supabase before ingesting.
- Cost overruns: Sample 50 representative documents first to estimate parser and embedding costs. That few minutes of testing saves big surprises.
- Token limit errors: Keep chunk sizes compatible with your LLM context window. Use headings to anchor chunk boundaries.
Metadata strategy
Metadata drives traceability and better search results. For each chunk I added these fields:
- source_id — hash or storage object id
- filename — original file name
- page_range — pages covered by the chunk
- heading_path — path of headings above the chunk (useful for context)
- parser — which parser created the chunk (LlamaCloud, Docling, Mistral)
- original_url — link to Supabase signed URL or public file
With these fields, I could reconstruct source passages in the UI and show the exact spot the agent referenced when answering a question.
Security and access control
When you run a public-facing parser or gateway, treat it like any other API:
- Require API keys or basic auth on the gateway.
- Use signed URLs for storage to avoid exposing your buckets indefinitely.
- Log requests and watch for unusual patterns or high-volume uploads.
- Limit file size and types accepted to prevent abuse.
For Docling, I kept the instance behind an internal network and used a gateway only for the minimal public surface required. For LlamaCloud I relied on API keys and recorded usage.
Performance tuning
If throughput matters, parallelize parsing and embedding while throttling based on API limits. I queued documents and used worker nodes that ran concurrently. I also set a circuit-breaker: if parsing fails repeatedly for a file, mark it for manual review rather than looping endlessly.
For OCR-heavy documents, I reduced parse retries and increased OCR resolution only when the fallback text-based parse produced poor quality results. That saved cost and time on straightforward machine-generated PDFs.
Pricing basics
Pricing varies by provider, but here are the main levers to control cost:
- Parser per-page costs: Some managed parsers charge per page. If you have many pages, this is the dominant cost.
- Embedding cost per request: Each chunk creates one embedding. Fewer chunks → fewer embeddings → lower cost.
- Storage cost: Storing raw files, images, and vectors adds recurring costs, but these are usually small compared with parsing and embeddings.
- Free tiers: Many services provide free credits or free-tier calls. Use samples to know how far those credits go.
Estimate cost like this:
- Average pages per doc × expected docs per month = pages/month.
- Parser cost per page × pages/month = parser cost/month.
- Average chunks per page × docs/month = embeddings/month.
- Embedding cost per vector × embeddings/month = embedding cost/month.
- Add storage and overhead to get monthly total.
Doing a quick test run and measuring average chunks per document is the best way to get good estimates.
Example n8n nodes and configuration notes
Here are practical notes on node settings I used in n8n so you can recreate the flow:
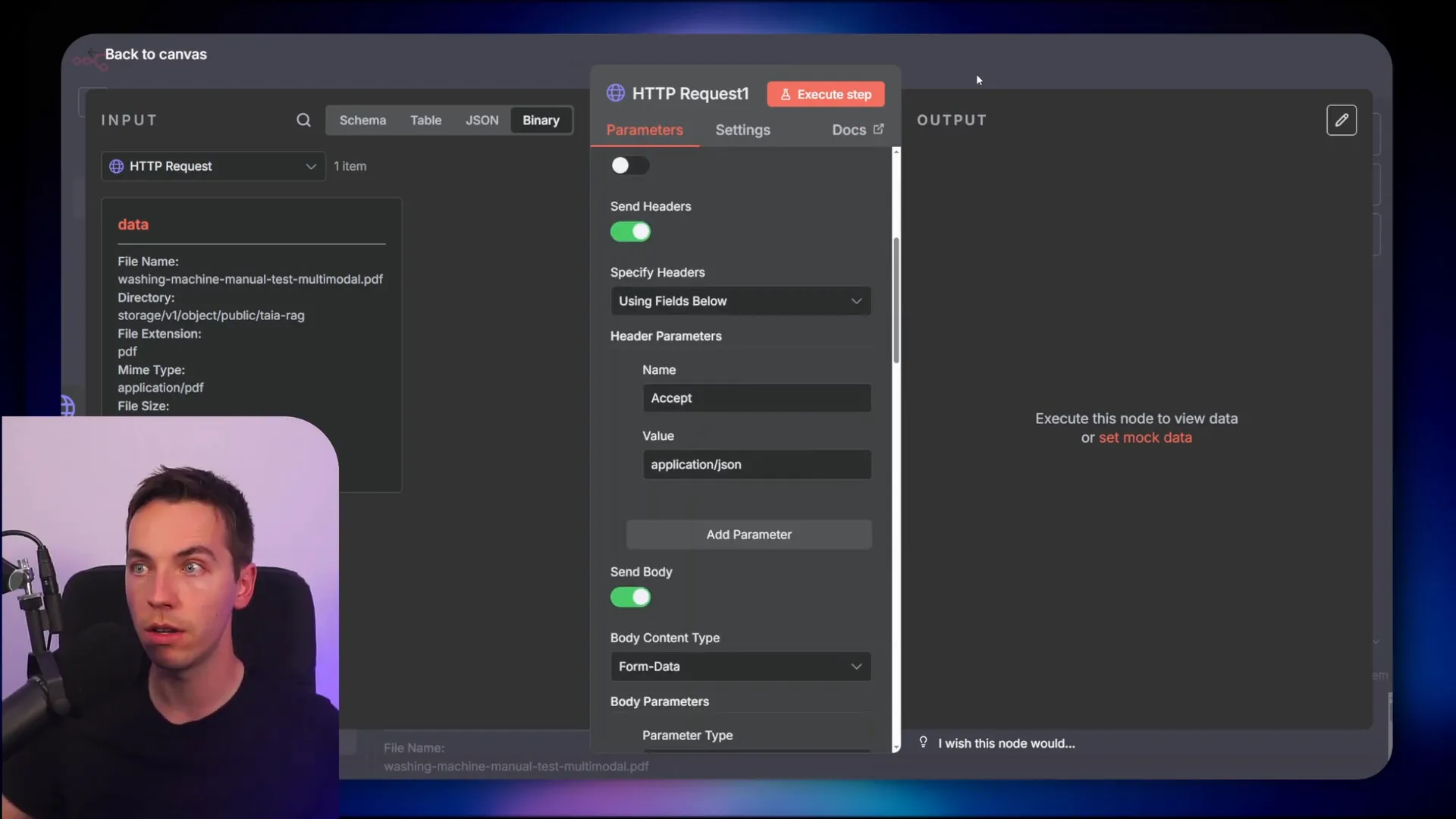
- HTTP Request node (upload): Method POST, content-type multipart/form-data, remove manual Authorization header and use saved credential instead.
- Wait node: Used for polling backoff. I started with 5–10 seconds and increased if jobs took long.
- Switch node: Evaluates “status” field from job status response. Routes to poll again on “pending”, to final GET on “success”, and to error handling on “failed”.
- HTTP Request node (GET results): Method GET, dynamic URL with job ID injected via expression from the upload response.
- Function/Code node: Used to compute document hash and to split/format metadata for Supabase insert calls.
- Supabase node: Insert vectors and metadata. I used upsert to handle re-uploads gracefully.
Presentation and UI choices
When the agent returns an answer, you might want to show the source. Because I stored page ranges and heading paths, my UI could render the chunk text and include a link back to the original file. For table-rich documents, I render the HTML table directly inside the answer UI so users can see preserved layout and merged cells.
For images, I stored extracted images in the same storage bucket and referenced them with the chunk metadata. The UI then can display the image inline with the answer when the chunk is returned.

Troubleshooting tips
If parsing fails:
- Check the file type. Some parsers accept many types but may fail silently on malformed files.
- Inspect the raw job logs if available. They often show OCR failures or memory exhaustion.
- Try smaller test files to verify authentication, endpoint URLs, and callback logic.
- Test with HTML tables off if you see weird HTML artifacts; sometimes Markdown tables are cleaner for downstream processing.
When to choose each parser
- Choose LlamaParse if you want the fastest path to wide format support with a hosted service that returns rich Markdown and optional HTML tables.
- Choose Docling if you want to self-host, avoid per-page API charges, and keep data entirely under your control.
- Choose Mistral OCR if you process large batches of PDFs and need speed and extracted images at low cost.
Final integration notes
Make sure your agent references the parser type in metadata so you can track parsing quality by source. If you see repeated poor-quality parses from a given type, consider a retry policy that uses a different parser or different OCR settings for that file type.
Also, keep monitoring on costs and parsing success rates. Parsers and OCR engines improve fast, so revisit settings periodically and update your pipeline to match the best trade-off for fidelity, speed, and cost.