

More companies are moving towards running their AI agents and systems entirely on local hardware. This shift is motivated by concerns over privacy, compliance, reducing cloud dependency, and cutting operational costs. The primary business use case for AI right now is enabling employees to interact with AI agents that are deeply informed by the company’s own data and knowledge base.
I created an automation that replicates this concept with a fully local version of a NotebookLM-style app, which lets you chat with your documents. This system runs entirely offline on your own machine, leveraging open source tools like Supabase, n8n, and Ollama. I’ll walk through the demo of this local system and then share a detailed step-by-step guide on how to set it up yourself.
What Is a Fully Local RAG System and Why It Matters
Retrieval-Augmented Generation (RAG) systems combine large language models (LLMs) with document retrieval mechanisms. This means the AI doesn’t just generate text based on pre-trained knowledge—it actively pulls relevant information from your own documents or data sources to provide accurate answers.
Running these systems locally means everything stays on your own hardware. No sensitive data leaves your network, which is critical for companies with strict privacy or regulatory requirements. It also avoids reliance on cloud services that can be costly and introduce latency.
However, building a local RAG system isn’t as simple as swapping cloud-based models for local ones. It requires rethinking backend workflows and adapting the architecture to the constraints of local machines, which often have limited GPU memory and compute power compared to cloud servers.
Overview of the Local InsightsLM System
This local version of InsightsLM is built on Cole Medin’s excellent Local AI package, which bundles together several key components:
- Supabase for backend database, authentication, and edge functions
- n8n for workflow orchestration and automation
- Ollama for running local large language models (LLMs) and embeddings
- Whisper ASR container for local audio transcription
- Coqui TTS for text-to-speech synthesis to generate podcasts
All of these services run inside Docker containers on your local machine, communicating via local ports. This setup means the frontend app itself does not require any code changes to work fully offline. The backend workflows have been re-engineered to fit within the limits of smaller local models, specifically the Qwen3 8 billion parameter model with quantization.
Uploading and Embedding Documents
Using the app, you can create a new notebook and upload various source documents. For example, I uploaded a 180-page PDF of Formula 1 technical regulations. Once uploaded, the system automatically generates a notebook overview and embeds the document into Supabase’s vector store.
This embedding process breaks the document into chunks (in this case, 674 chunks) and converts each chunk into vector embeddings using the Nomic text embedding model. These vectors allow the system to efficiently search for relevant information when you ask questions.
The notebook overview generation workflow triggers a call to Ollama’s LLM to create a title and description for the notebook. A random color is also assigned for visually distinguishing notebooks on the homepage.
The entire process of generating the notebook details and embedding took about 56 seconds on my system, which uses an NVIDIA GeForce 4070 GPU with 8GB VRAM. The longest step was loading the document into Ollama’s context for generating the title and description, which took 39 seconds. Embedding the document chunks took about 8 seconds.
Asking Questions and Chat Workflow
Once the document is embedded, you can ask questions like “What are the minimum mass requirements for F1 cars?” The system triggers a chat workflow that:
- Fetches the chat history
- Uses the Qwen3 model to generate a search query
- Queries the vector database for relevant chunks
- Feeds those chunks back into Ollama to generate a response
- Processes citations to build a detailed JSON structure
- Saves the response and citations into Supabase
The answer is displayed with clickable citations that link directly to the relevant section of the document, providing transparent sourcing. For example, the system correctly answered that the minimum mass requirement for F1 cars is 800 kilograms and linked to the exact text in the regulations.
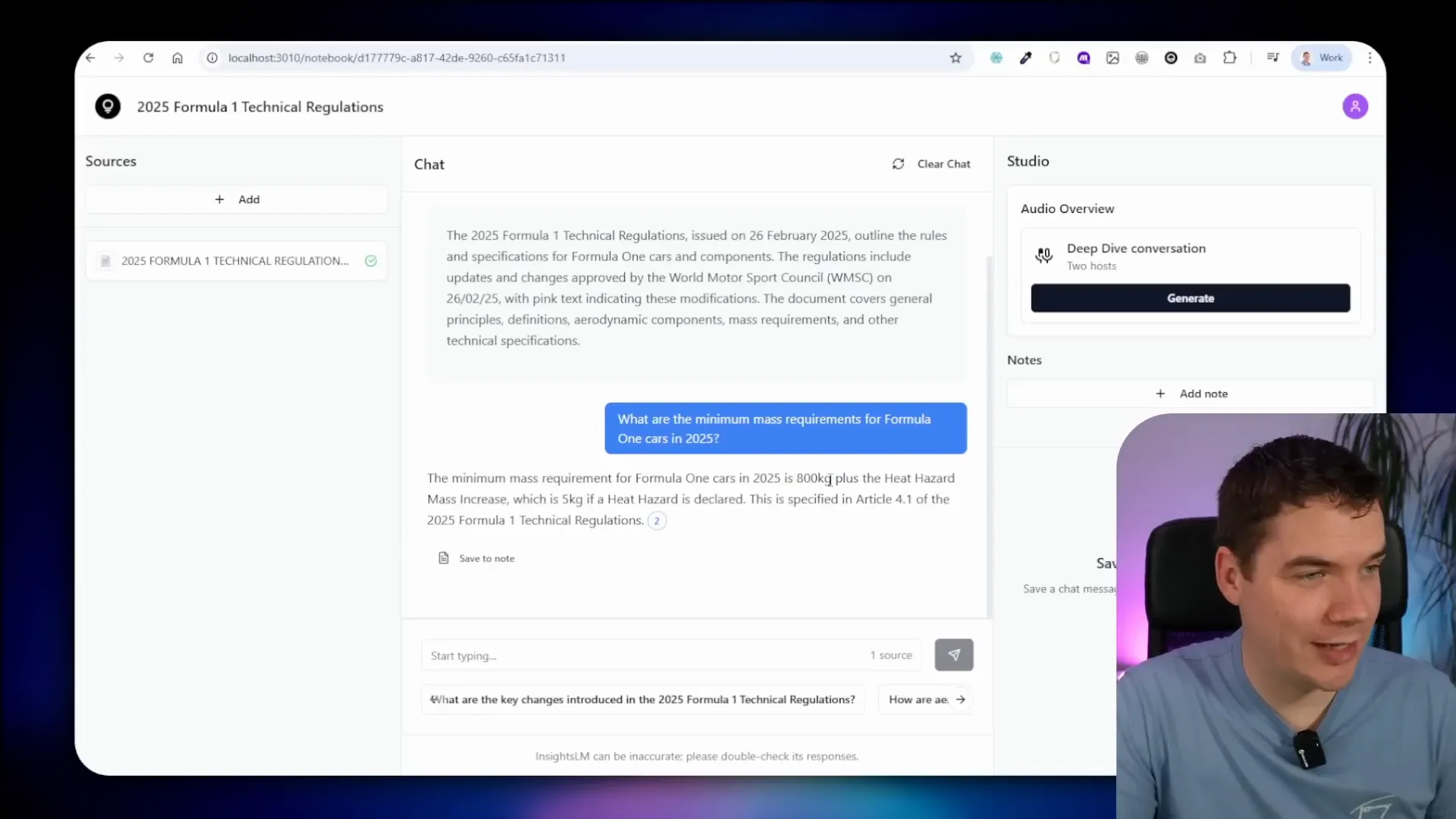
This chat flow is quite different from the cloud-based version of InsightsLM, which simply hits a powerful AI agent capable of complex reasoning and output. Local models like Qwen3 8B don’t have the same capacity, so I broke down the process into smaller steps that reliably produce answers and citations.
Handling Complex Queries and Limitations
More complex questions, such as “Can you give me an overview of the various rules in the document?” pose challenges because vector stores return a limited number of chunks. Summarizing or overviewing a full document ideally requires access to the entire text.
One potential solution is dynamically adjusting the number of chunks retrieved based on question complexity, which I plan to explore in future versions.
On my hardware, some queries caused the system to slow down or fail due to GPU VRAM limitations. For example, the Qwen3 8B model pushed the 8GB VRAM limit and caused timeouts. Clearing the cache and retrying sometimes helped the system respond within seconds.
This highlights the importance of matching local models to your hardware capabilities to ensure smooth operation.
Additional Features: Audio Transcription and Text-to-Speech
The system supports uploading audio files like MP3s, which are transcribed locally using the Whisper ASR container. When you upload an audio file, it triggers a workflow that sends the binary data to Whisper running on port 9000. The transcription results, including a summary and full text, are saved and displayed in the app.
Besides PDFs and audio, you can also add URLs to scrape web content. For example, I added URLs from Formula 1’s official site, such as the 2025 schedule and race results. The system successfully summarized the pages and stored the full markdown content.
You can also save notes within notebooks to keep track of your thoughts or discussion points.
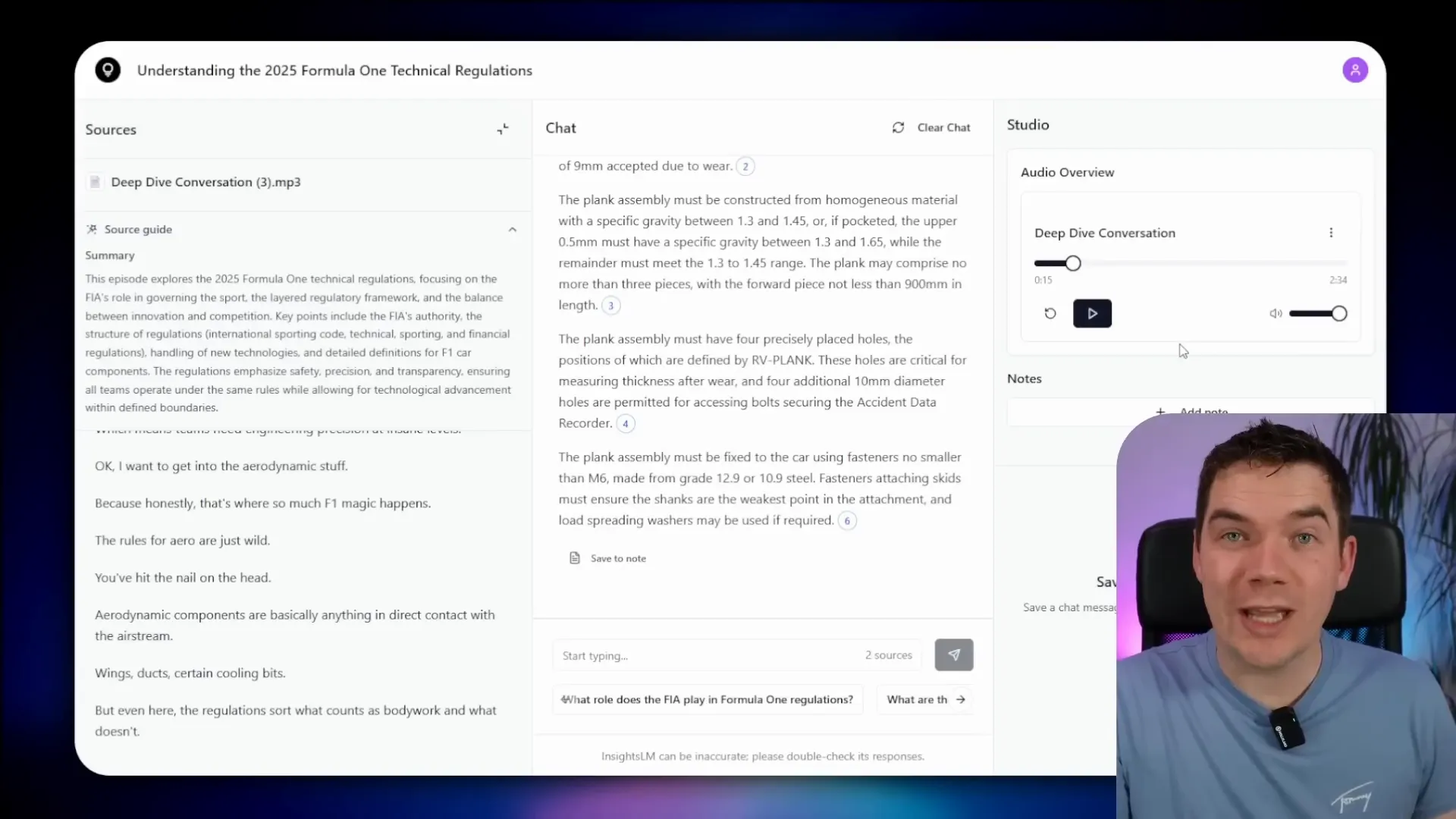
Generating Podcasts from Notebooks
The app includes a deep dive conversation feature that generates podcasts from notebook content. This uses Coqui TTS for text-to-speech synthesis. Although the quality isn’t as natural as some cloud-based services like Gemini or Eleven Labs, it’s quite impressive for a fully local, Docker-based system.
The podcast generation workflow truncates sources to fit hardware limits, then uses Ollama to generate a transcript, which Coqui TTS converts into audio. The audio is uploaded and made available for playback within the app.
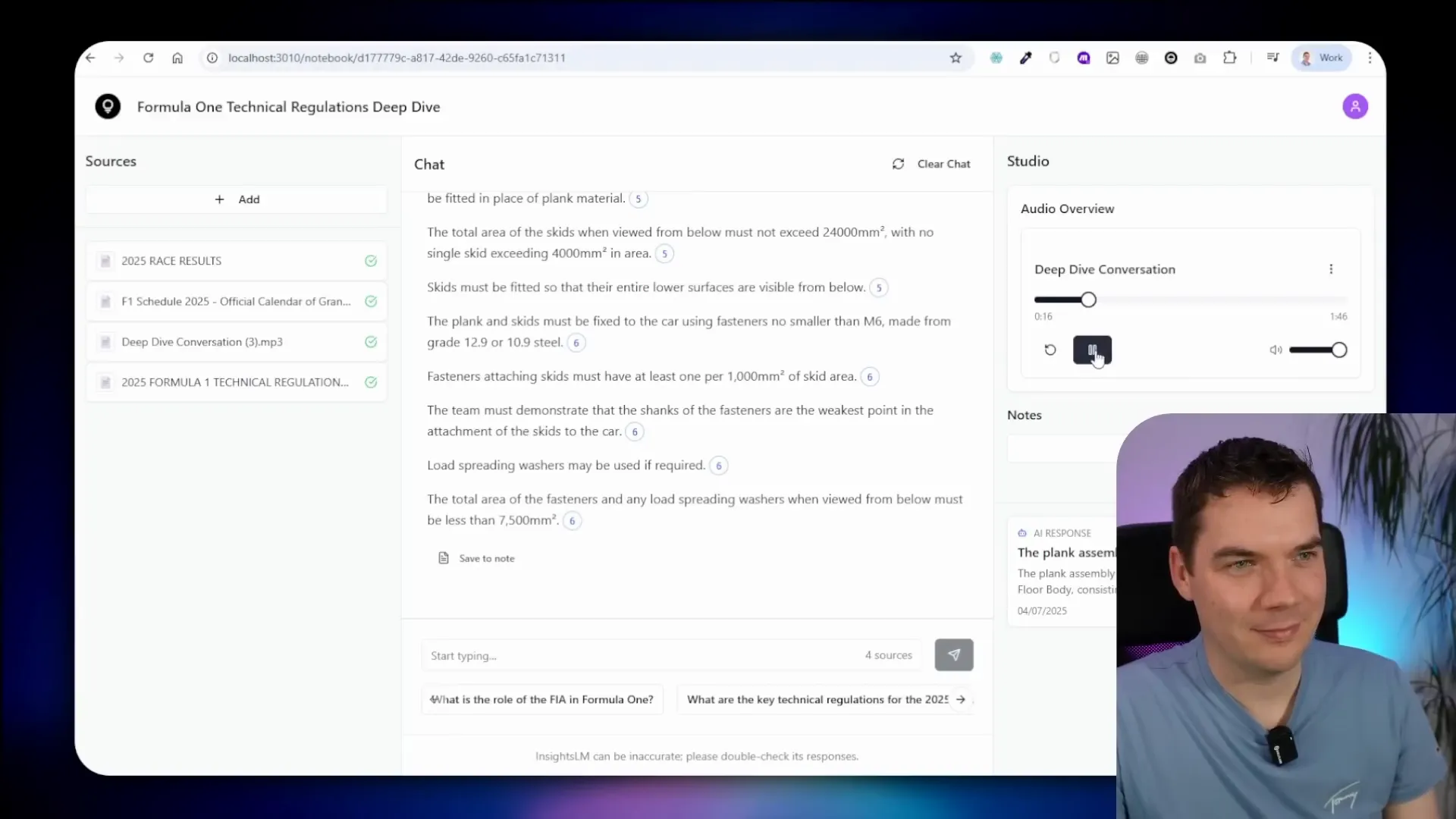
For example, the podcast about the 2025 Formula 1 technical regulations provides an engaging overview of the rules that govern the sport’s fastest machines. The voice is robotic but clear and understandable.
Setting Up Your Own Fully Local InsightsLM System
To get this running on your own machine, start by cloning Cole Medin’s Local AI repo. This repo contains all the components needed, including n8n, Supabase, and Ollama. The installation instructions are well documented in Cole’s repo.
Next, clone the InsightsLM local package repo from my GitHub, which contains additional files required to integrate InsightsLM workflows and functions.
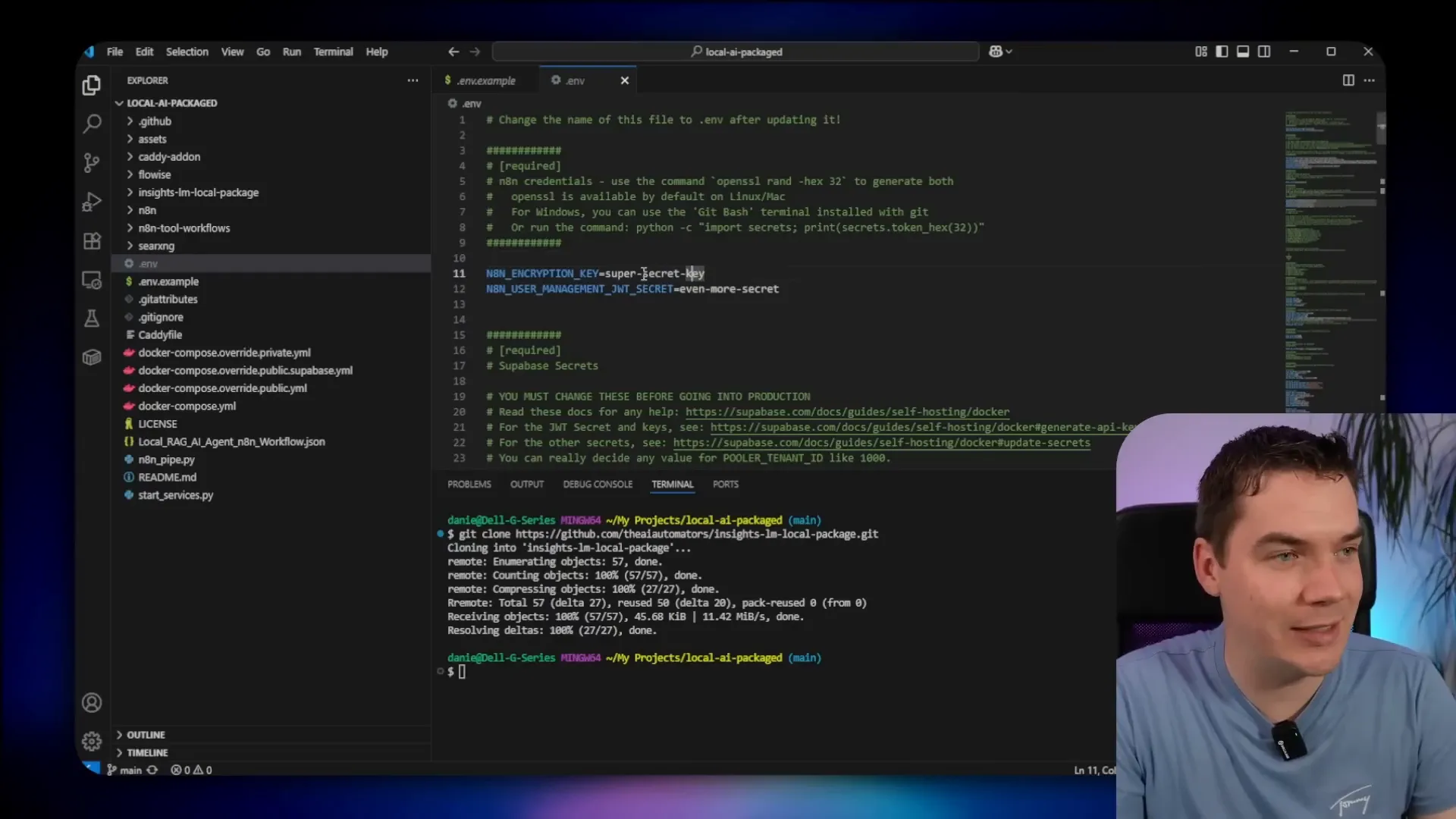
Before launching, you need to set some environment variables in a .env file. These include secrets for n8n, Postgres, JWT, and Supabase role keys. I used a password manager like LastPass to generate secure random keys. The environment variables also specify URLs for Whisper transcription and other services.
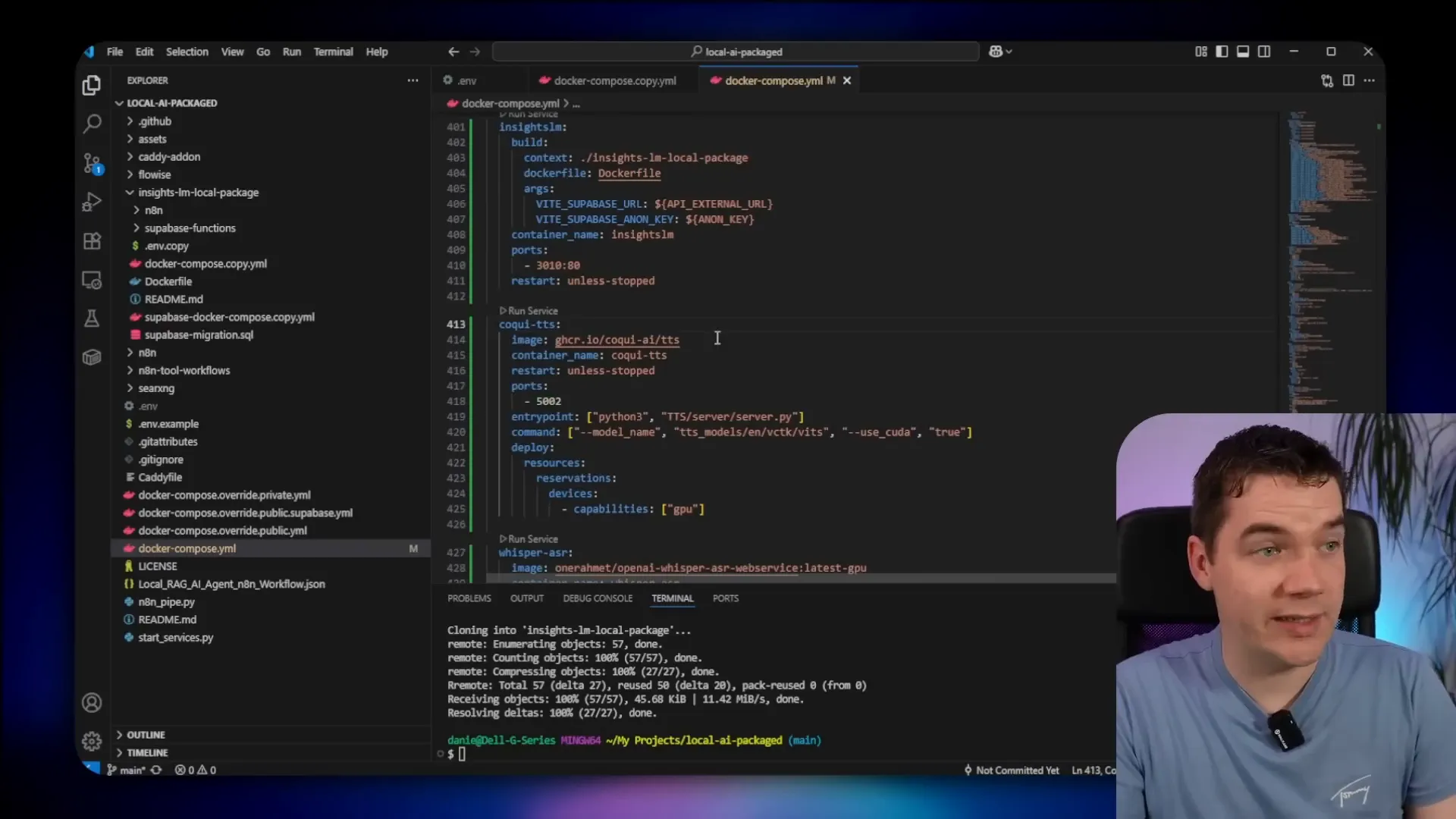
After setting environment variables, update the main Docker Compose file by adding a Whisper cache volume and three new services: InsightsLM, Coqui TTS, and Whisper ASR. Both Coqui and Whisper are configured to use GPU profiles, so if you are on Apple Silicon or other hardware, you may need to adjust these profiles accordingly.
Also, change the model version from Qwen 2.5 to Qwen 3 in the Docker Compose configuration to use the latest 8 billion parameter model with quantization.
Once everything is configured, start the Docker containers using the provided Python script in Cole’s repo, which manages the multi-container startup process. The initial download and setup can take time since over 30GB of container images are involved.
After the containers are running, access the Supabase Studio dashboard on port 8000 to manage your database. It might take a few minutes for the dashboard to load initially.
Run the Supabase migration script from the InsightsLM local package to create the necessary tables, policies, and storage buckets. This includes tables for documents, notebooks, notes, and more.
Copy the InsightsLM Supabase functions into the Supabase volumes folder and update the Docker Compose file for Supabase to include environment variables needed by the edge functions. This step ensures that the functions can communicate with n8n and Ollama services correctly.
Stop and restart the Docker containers to apply these changes. Once restarted, you can access n8n at port 5678 to manage workflows.
Import the InsightsLM workflows into n8n and configure credentials for n8n API access, Supabase API, and Ollama. This setup links all parts of the system together.
Activate all workflows except the extract text one, which is no longer needed after import.
Logging In and Using the Local InsightsLM App
To log in to the InsightsLM app, create a user in Supabase’s authentication dashboard. Once logged in, you can create notebooks and upload documents as demonstrated earlier.
The system processes uploads quickly, generating notebook overviews and embedding documents for search. You can ask detailed questions and get responses with citations.
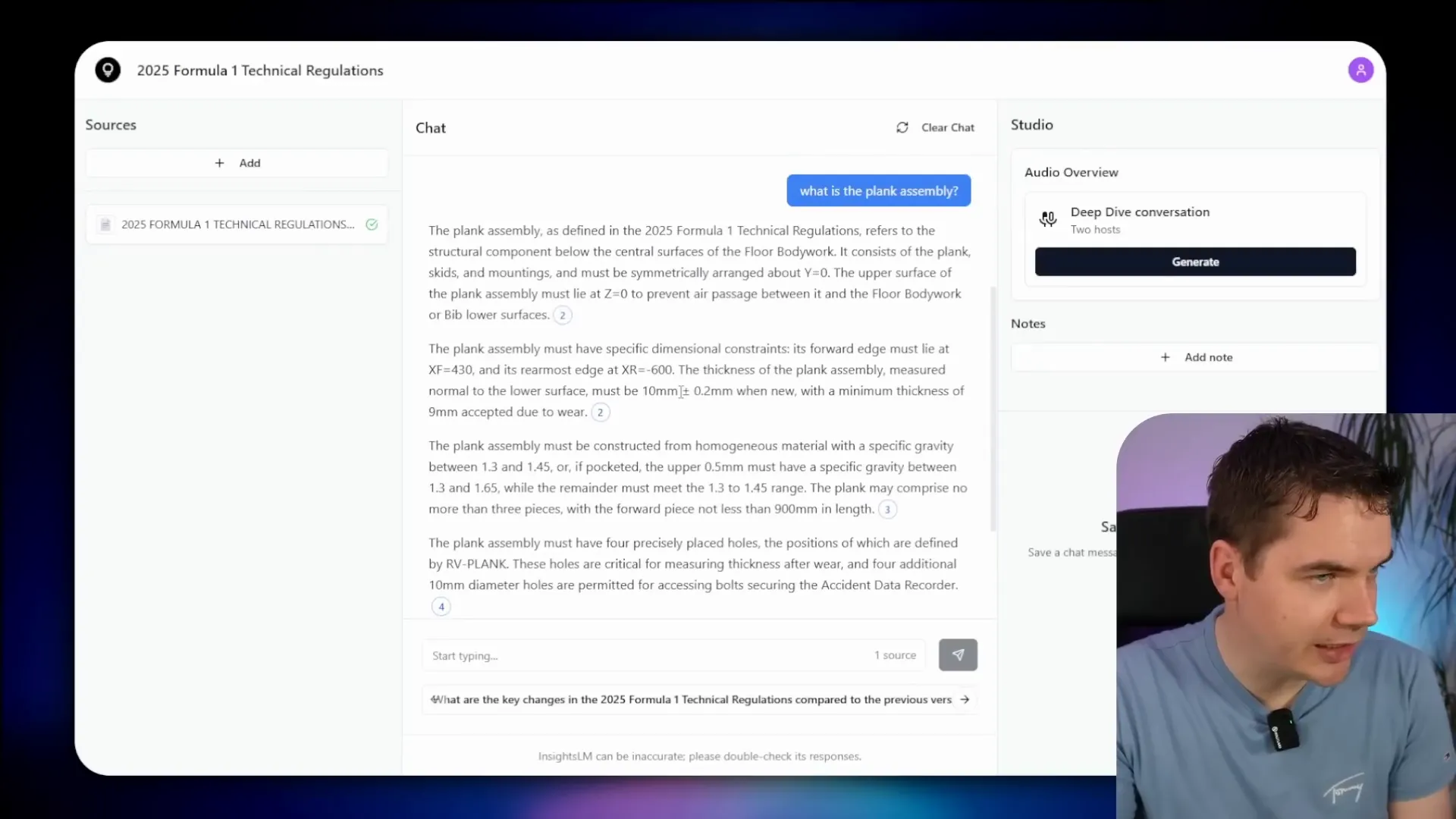
Uploading audio files triggers Whisper transcription, which runs locally and efficiently given the hardware capabilities.
Generating podcasts from notebook content is also available, creating audio files through Coqui TTS and Ollama.
Benefits and Considerations of Running AI Fully Locally
This fully local system gives you complete control over your data and AI workflows. It removes privacy risks associated with cloud services and eliminates ongoing cloud costs. The entire stack is containerized, making it portable and isolated within your network.
On the flip side, hardware limitations require careful model selection and workflow optimization. Smaller local models like Qwen3 8B can deliver reliable results but may lack the sophistication of large cloud-hosted models with hundreds of billions of parameters.
Adapting prompts, workflows, and citation methods helps make these smaller models practical for real-world question answering. The system architecture reflects this balance between capability and hardware constraints.
Overall, this project shows that self-hosted, fully local AI assistants grounded in your own documents are achievable today with open source tools and some configuration effort.
