

In building AI-powered Retrieval-Augmented Generation (RAG) agents using n8n, I discovered a simple adjustment that can dramatically improve their effectiveness. This tweak takes just about ten seconds to implement but can make a significant difference in how well your agents understand and retrieve information. Even experienced users might overlook this detail, yet it’s one of the most impactful changes you can make to your RAG pipelines.
In this article, I’ll walk you through the core concepts of chunking documents for RAG, explain why splitting by markdown headings works better than the default methods, and show you how to set up your n8n workflows to take full advantage of this approach. Along the way, I’ll cover handling different document types like Google Docs, PDFs, and HTML, ensuring your data is properly structured before it’s stored in your vector database. Finally, I’ll demonstrate the results of this fix in action with a practical example.
Understanding Chunking in RAG Systems
At the heart of any classic RAG system lies the process of breaking down documents or web pages into smaller pieces called chunks. These chunks are then converted into vector embeddings and stored in a vector database. This setup allows your AI agent to quickly search and retrieve relevant information based on semantic similarity when answering questions or performing tasks.
In n8n, this chunking is managed by the data loader node within your RAG pipeline. Typically, the default setup splits documents into chunks of about one thousand characters, with some overlap between chunks to preserve context. While this approach sounds reasonable, it often leads to what I call the “sliding window problem.”
This problem occurs because the chunking process slides a fixed-size window across the text, breaking it at arbitrary points like new lines or paragraphs without considering the document’s logical structure. The result is many chunks that lack proper context, making it harder for the AI agent to understand and retrieve useful information accurately.
Why Splitting by Markdown Headings Works Better
A more effective approach is to split documents based on markdown formatting, particularly headings. Markdown is a lightweight markup language that uses simple syntax to structure content with headings, lists, tables, and more. By chunking documents according to markdown headings, each chunk retains a coherent section of the content, improving relevance and context when retrieved.
For example, instead of arbitrary character-based chunks that might slice through paragraphs or sentences, markdown-based chunks start at headings and include the content beneath them. This organization aligns with how humans naturally divide information, making it easier for the AI agent to understand the context of each chunk.
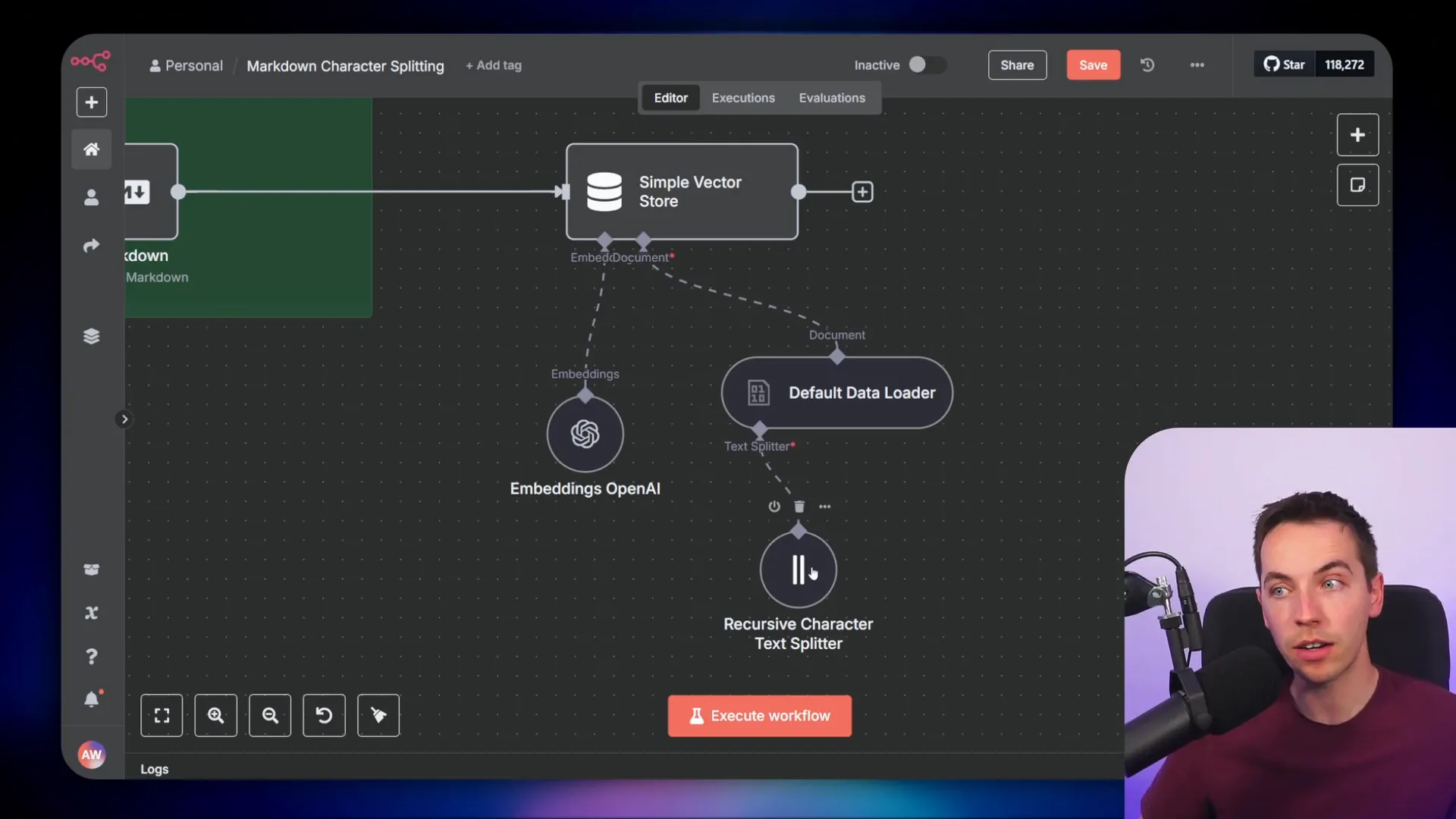
In my automation, I take a web page response in HTML, convert it to markdown, and then pass it to the vector store through the data loader. When splitting documents this way, the splitter prioritizes headings before anything else, which creates much better-organized chunks.
Configuring the Text Splitter Correctly in n8n
While markdown splitting is a powerful feature, it’s not enabled by default in n8n’s character splitter. The default splitter splits text by paragraphs, new lines, and spaces rather than markdown structure. This limitation causes many users to miss out on the benefits of markdown chunking.
Inside the character splitter node, you can press the “Add Option” button to see the choice to split text by markdown. Interestingly, the UI suggests that markdown splitting is the default option, but this can be misleading. If no split code parameter is explicitly set, the splitter falls back to the basic method of splitting by paragraphs and new lines.
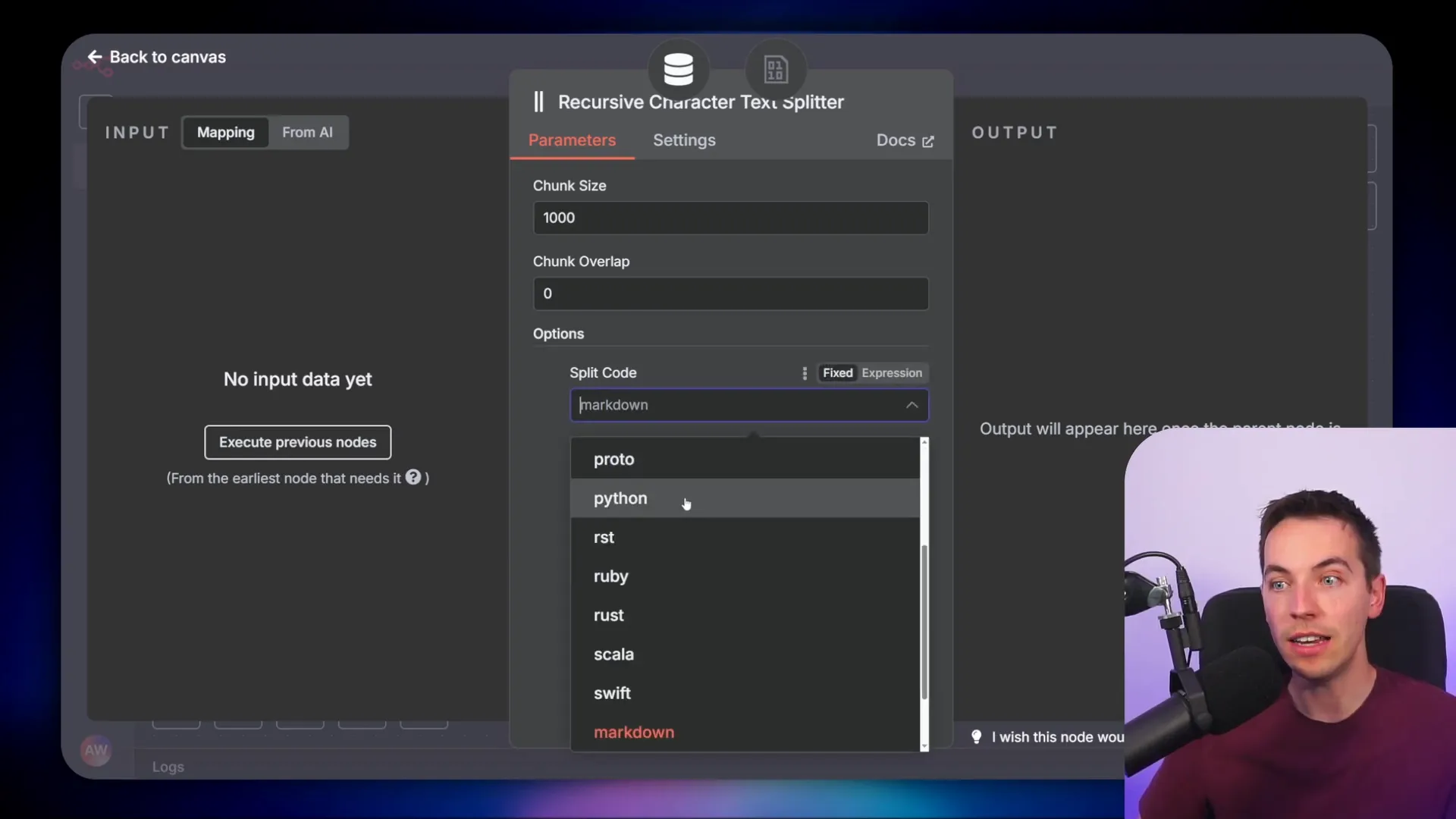
To fix this, you need to ensure that your character splitter node is configured to split by markdown. I prefer using the recursive character splitter node with the markdown option explicitly added. This change increases the number of chunks slightly but greatly improves their quality and relevance.
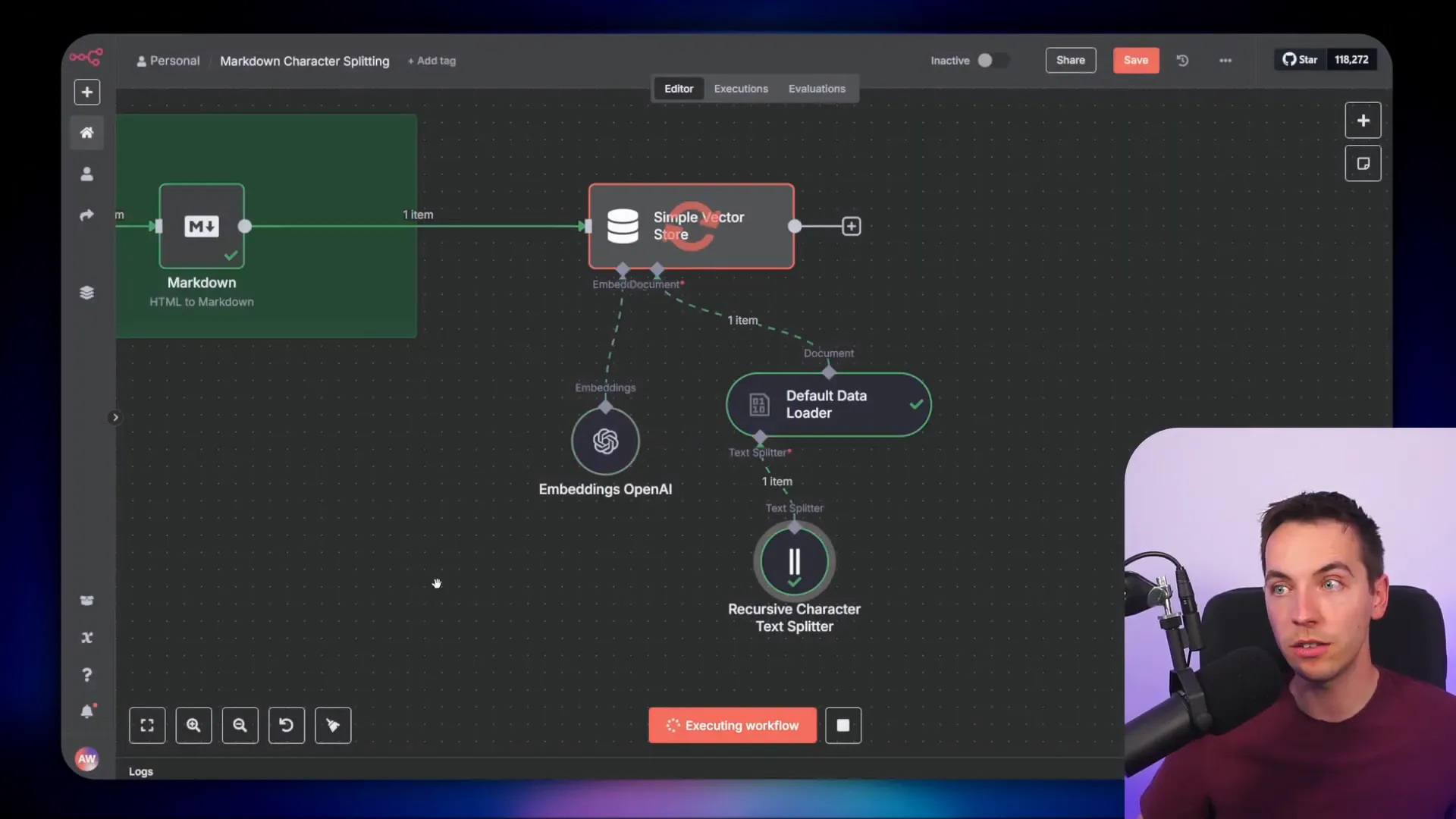
Looking into the code behind this splitter, if no split code parameter is passed, it defaults to the basic splitting approach. So, the first step to improving your RAG agents is to go into your text splitter and select the markdown splitting option.
Preparing Your Data: Converting to Markdown Before Chunking
To make the most of markdown splitting, your data needs to be in clean markdown format before it reaches the splitter. This means converting various document types — like Google Docs, PDFs, and HTML pages — into markdown first.
In my setup, I created an automation inspired by a blueprint from a RAG masterclass. It watches for new files in Google Drive and also has a webhook to ingest web pages. When a new file is detected, a switch node checks the file’s MIME type to determine how to process it.
For Google Docs, I use the “Get a Document” node with the “simplify output” option set to false. This ensures the output retains the document’s structure. Then, I pass the structured output to a code node that converts it into markdown. I actually had ChatGPT generate this conversion code, and it worked perfectly on the first try. This shows how well AI tools can assist with working on structured data from Google Docs.
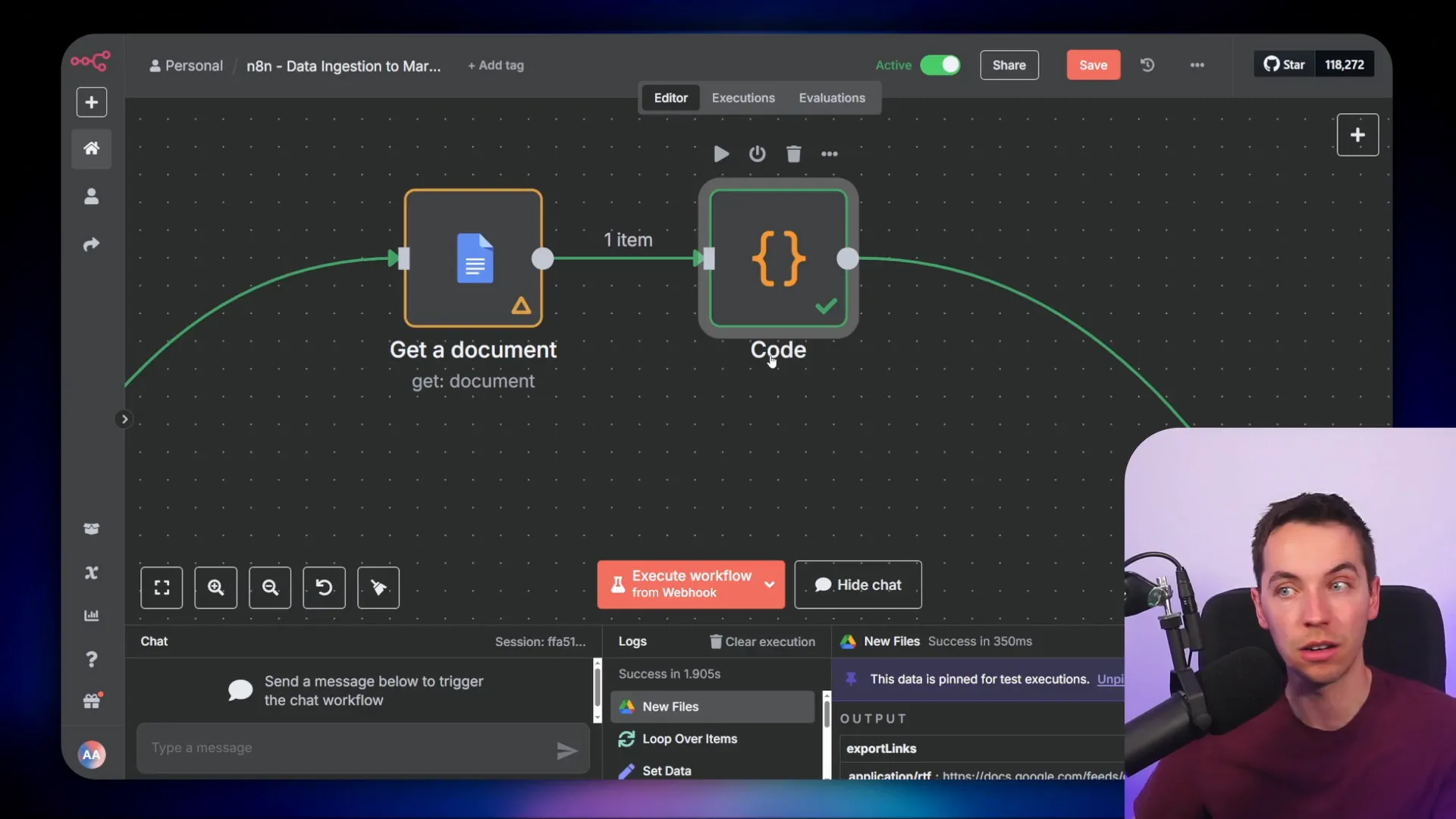
On the right side of the workflow, you can see the resulting markdown. It includes headings, tables, and bullet points — all formatted cleanly to help the splitter do its job.
Handling PDFs: Using OCR for Clean Markdown
Extracting markdown from PDFs is trickier. The standard extract-from-file node in n8n only returns plain text, which loses formatting and structure. To solve this, I use the Mistral OCR API, which can convert PDFs into clean markdown.
This approach preserves headings and other structural elements, which the splitter can then use to create meaningful chunks.
Processing HTML Content
For HTML content, I use an HTML-to-Markdown node. Alternatively, you can use a service like Firecrawl.dev, which crawls and scrapes websites, returning clean markdown for those pages. This method was explained in detail in the RAG masterclass I followed.
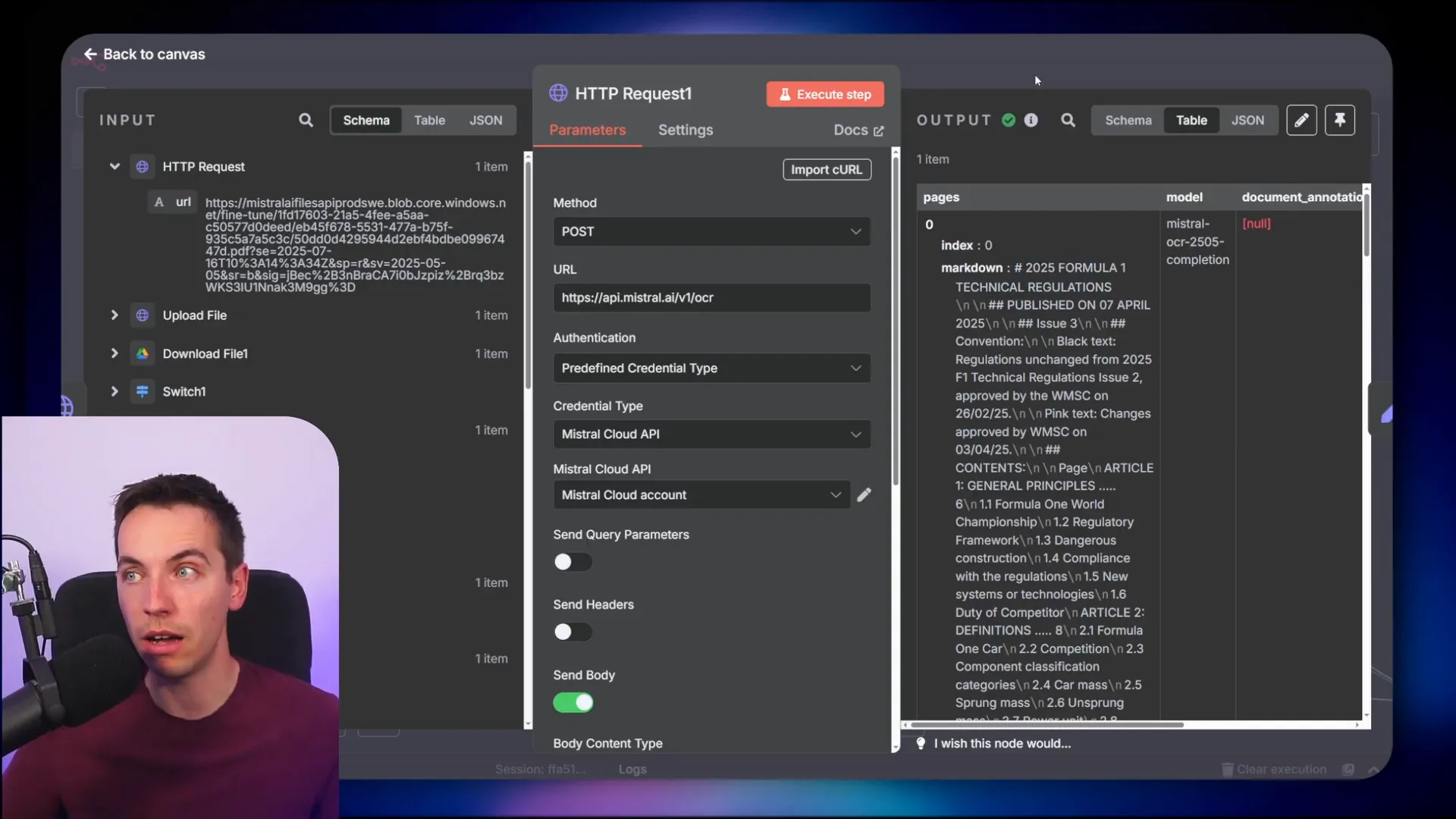
Once your data is converted to markdown, the splitter can accurately divide it into chunks based on headings and other markdown elements.
Troubleshooting Markdown Chunking Issues
Sometimes, even when your markdown has plenty of headings, the splitter might not chunk the document properly. The first thing to check is whether your markdown is correctly formatted.
For instance, if you take HTML from a page and convert it to markdown, it should be well-structured and recognizable by the splitter. However, if you do extra processing on the markdown that alters its format — like escaping characters or duplicating nodes improperly — the splitter might fail to recognize headings and structure.
In one example, I duplicated a markdown conversion node, which escaped the markdown incorrectly. Running the workflow again resulted in chunks that were not split correctly because the markdown format was broken.
Maintaining clean markdown throughout your pipeline is essential for the splitter to work as intended.
Seeing the Fix in Action: RAG Agent Query Example
To show how this fix improves real-world results, I set up an AI agent with access to the vector database built using markdown-based chunking. I asked the agent, “How does long term memory work in n8n?” The agent queried the vector database and retrieved relevant semantic chunks.

The agent’s response was accurate and contextually rich. When I inspected the vector database tool, the first chunk returned started with a proper heading, indicating the answer was well contextualized.
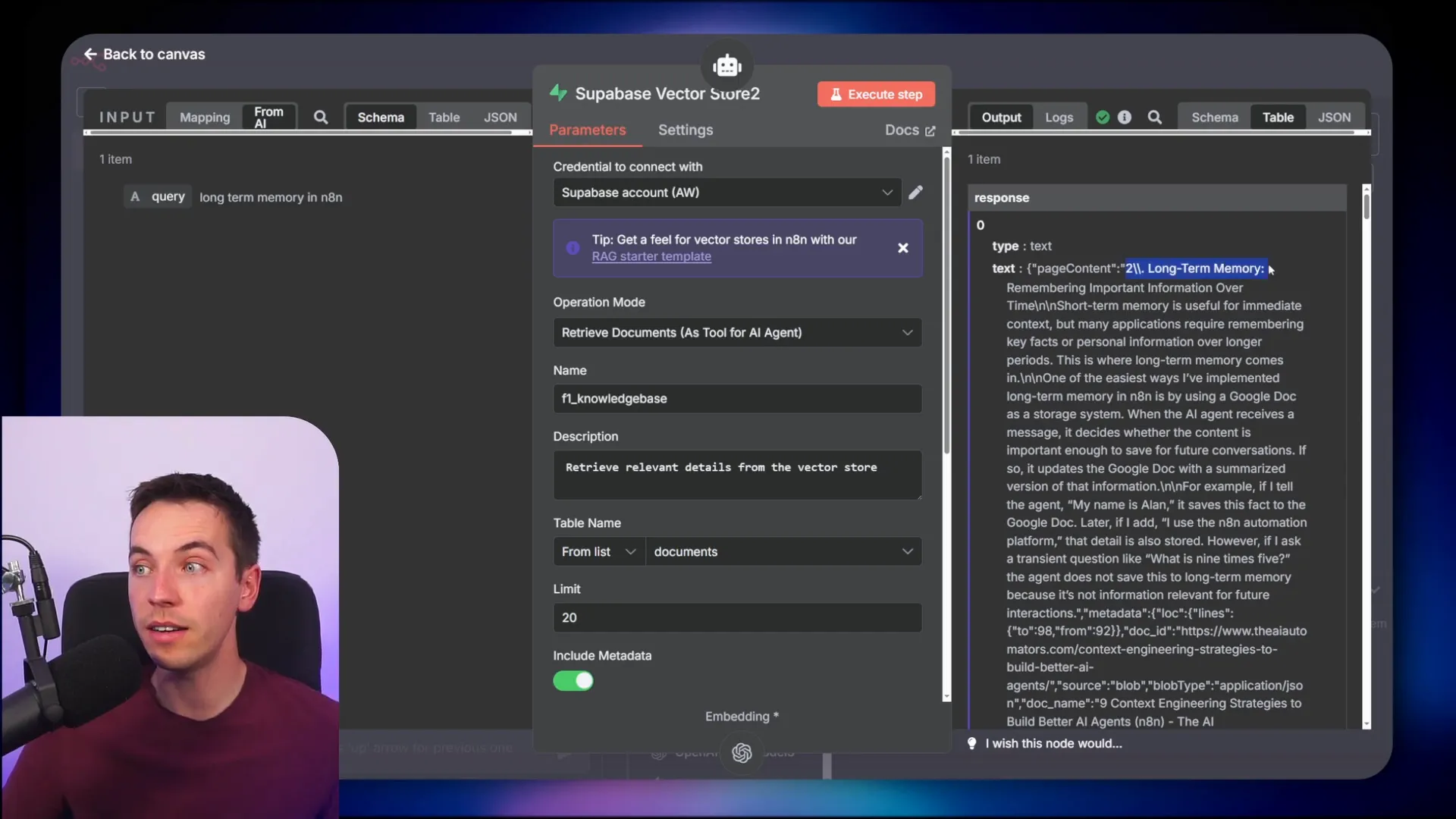
Good chunking not only improves retrieval but also lays the foundation for more advanced techniques like re-ranking and contextual retrieval, which further enhance your RAG agents’ performance.
Summary of Key Steps to Improve Your RAG Agents
- Choose markdown splitting in your recursive character splitter: This ensures chunks are organized around meaningful content sections rather than arbitrary character counts.
- Convert all unstructured data to clean markdown: Use code nodes, APIs like Mistral OCR, or HTML-to-Markdown converters to prepare your data before chunking.
- Verify markdown formatting remains intact: Avoid extra processing that might corrupt markdown structure and prevent proper chunking.
- Handle different file types appropriately: Use specialized nodes or APIs for Google Docs, PDFs, and HTML content.
- Test your agent with real queries: Confirm that chunks retrieved contain proper context and headings for accurate responses.
By following these steps, you can upgrade your n8n RAG agents to deliver much more meaningful and context-aware answers. This one small fix to how you chunk documents can multiply your agent’s effectiveness tenfold.
