

Context engineering has become a crucial skill for anyone working with AI agents today. As these agents grow more advanced and capable of independent operation—accessing the web, knowledge bases, and various tools—the traditional approach of prompt engineering no longer suffices. The key challenge is managing the context window, which is the limited amount of text the AI model can process at once. Without careful handling, the context can quickly become overloaded or polluted, reducing the agent’s effectiveness.
In this article, I will share nine context engineering strategies that I use within n8n to make AI agents smarter, more efficient, and less prone to errors. These techniques cover everything from managing short-term and long-term memory to isolating context, summarizing data, and handling large-scale research workflows. Each method helps control and optimize the information fed to the AI, improving performance and reliability in practical applications.
Understanding the Context Window and Its Importance
The context window is like the working memory of an AI model. Andrea Karpathy described large language models (LLMs) as a new kind of operating system, with the context window acting as the RAM. This RAM is limited, meaning the AI can only consider a certain amount of text at a time—measured in tokens. Tokens roughly correspond to pieces of words or characters.
This limitation means that the AI agent cannot remember or process endless information at once. Instead, it must be fed the right information at the right time, and excess or irrelevant data must be trimmed or managed carefully. Without this, the agent’s answers might become inaccurate, contradictory, or distracted by irrelevant details.
1. Short-Term Memory: Keeping Recent Interactions in Focus
Short-term memory is the simplest form of context management. It involves storing recent interactions between the user and the AI agent so the agent can refer back to them as the conversation progresses. In n8n, setting this up is straightforward.
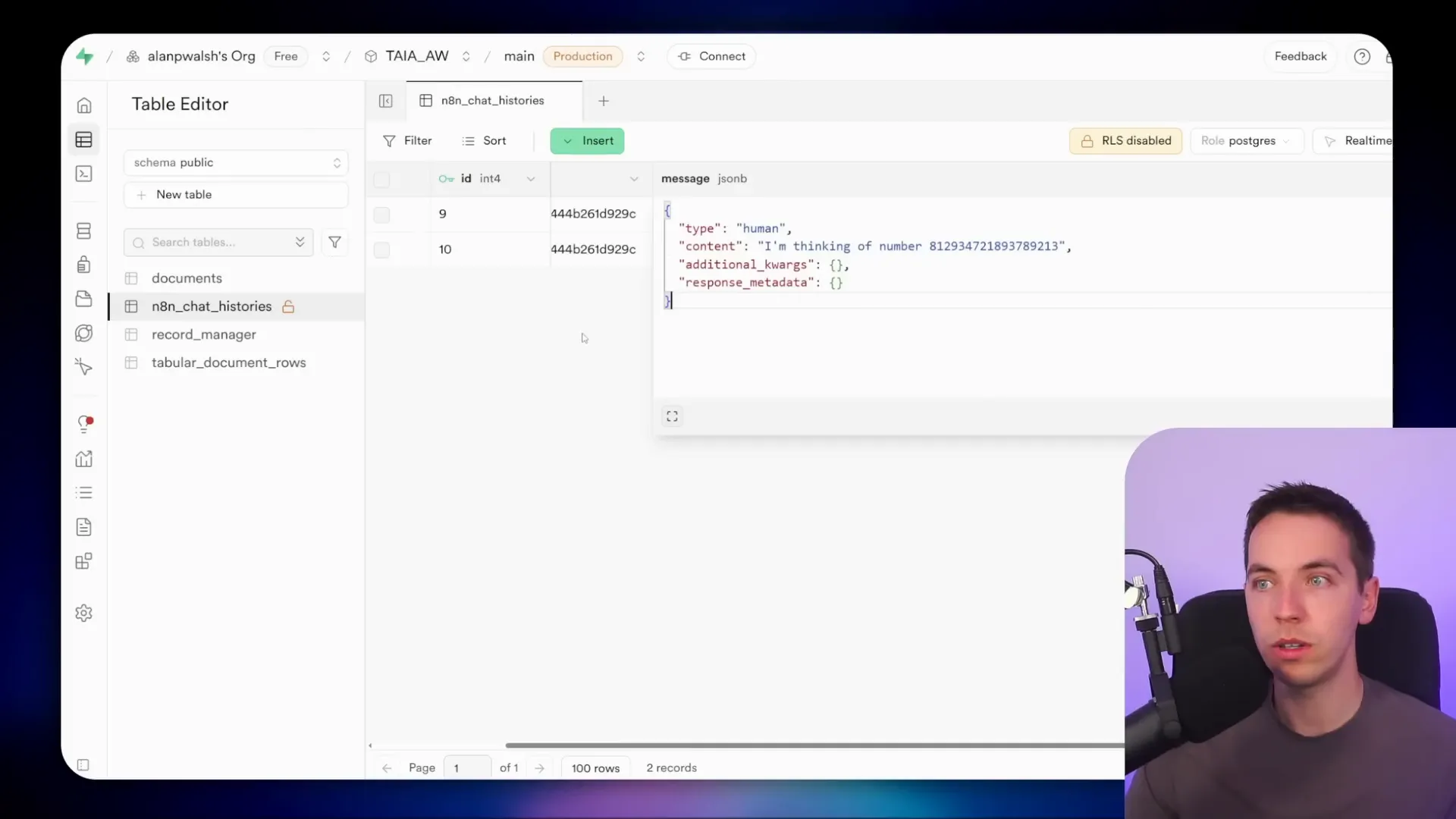
I created a simple AI agent using n8n that uses either “simple memory” or an external database like Postgres to store recent messages. With simple memory, you just specify how many recent interactions the model should keep in mind. For example, if I think of a number and save it in memory, I can later ask the agent what the number was, and it will recall it correctly because that information remains in the short-term memory.
Using Postgres chat memory takes this a step further by saving these interactions in a structured database. You can see each message and response stored as entries, making it easier to track and manage. However, it’s important to remember this still counts as short-term memory—it only retains a limited number of recent messages based on the defined context window size.
Since LLMs operate with token limits, monitoring token usage is essential. In n8n, you can check token consumption for each call to the model, helping you optimize memory size and avoid exceeding limits.
2. Long-Term Memory: Remembering Important Information Over Time
Short-term memory is useful for immediate context, but many applications require remembering key facts or personal information over longer periods. This is where long-term memory comes in.
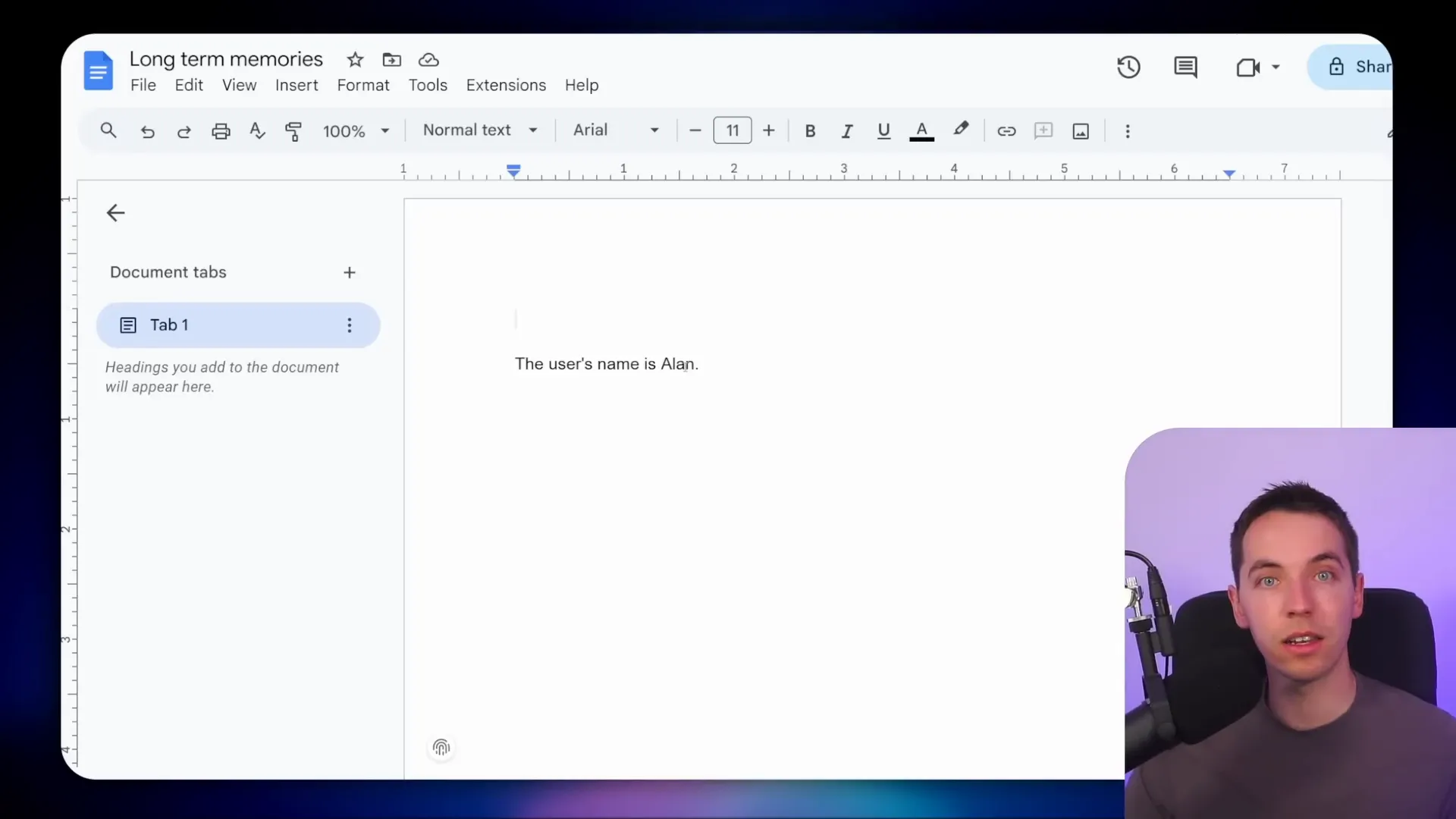
One of the easiest ways I’ve implemented long-term memory in n8n is by using a Google Doc as a storage system. When the AI agent receives a message, it decides whether the content is important enough to save for future conversations. If so, it updates the Google Doc with a summarized version of that information.
For example, if I tell the agent, “My name is Alan,” it saves this fact to the Google Doc. Later, if I add, “I use the n8n automation platform,” that detail is also stored. However, if I ask a transient question like “What is nine times five?” the agent does not save this to long-term memory because it’s not information relevant for future interactions.
This method is flexible—you can use Google Sheets, Airtable, or any database that suits your needs. You could also categorize memories by type or even integrate a retrieval-augmented generation (RAG) system for more advanced memory handling.
Inside the agent, I pass the retrieved long-term memories along with the current chat input. The system message instructs the AI on how to use this memory effectively, asking it to summarize key personal information clearly and briefly, ideally in one or two sentences. This approach mirrors what platforms like ChatGPT do when they update their internal memory with memorable user details.
3. Context Expansion Through Tool Calling
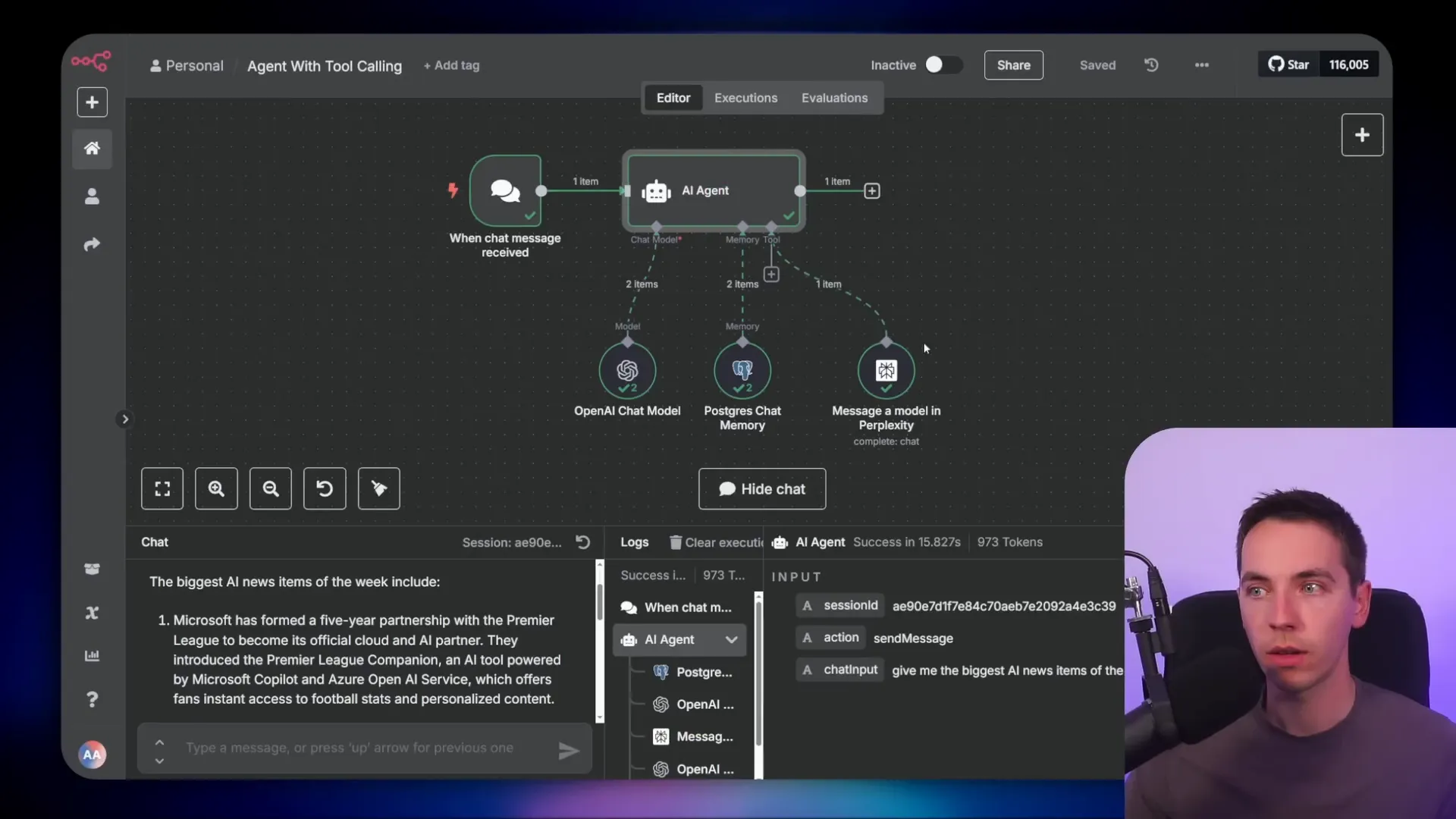
Tools add significant power to AI agents by allowing them to access live data or perform specific functions dynamically. In n8n, I connect various tools to the agent, and the AI decides which tool to call based on the user’s message.
For instance, I integrated a tool called Perplexity, which provides access to live web data. When I ask the agent to give me the biggest AI news items of the week, the agent doesn’t have that information in its current context. Instead, it calls the Perplexity tool, injecting the live data into the conversation dynamically.
The response from Perplexity is then summarized by the agent and sent back to me. Behind the scenes, the agent first retrieves short-term memory, sends the user query to the OpenAI chat model, which triggers the tool call, receives the tool’s response, and then re-sends that to OpenAI for final processing.
This process works well, but it also shows how the context window can quickly become polluted if you’re not careful. Each tool call adds data to the context, increasing token usage and risking overload. Deep research tools, for example, can return large volumes of data, making it crucial to manage what gets injected and how.
4. Retrieval-Augmented Generation (RAG): Handling Large Knowledge Bases
RAG is a powerful technique that lets AI agents access vast amounts of data without overloading the context window. The idea is to break large documents into smaller chunks, store them in a vector database, and retrieve relevant pieces based on semantic search queries.
In one example, I loaded the entire content of a 39-page PDF—including text, images, and tables—into a RAG system. When I asked the agent a question about the document, it queried the vector store and responded with information grounded in the data, complete with images where relevant.
In another setup, I used a Google Drive folder containing various documents. A data ingestion workflow processed these files, vectorized their content, and saved it into a Supabase vector store. The agent then queried this store to answer questions like “What are your shipping policies?”
The results returned from the vector store are loaded directly into the AI model’s context for response generation. While RAG systems provide dynamic context, they also require careful engineering to avoid overwhelming the model with too much data at once.
It’s important to note that the entire response from the vector store is dumped into the context window, just like other tool calls. There’s no hidden magic; managing the size and relevance of retrieved data is essential for performance.

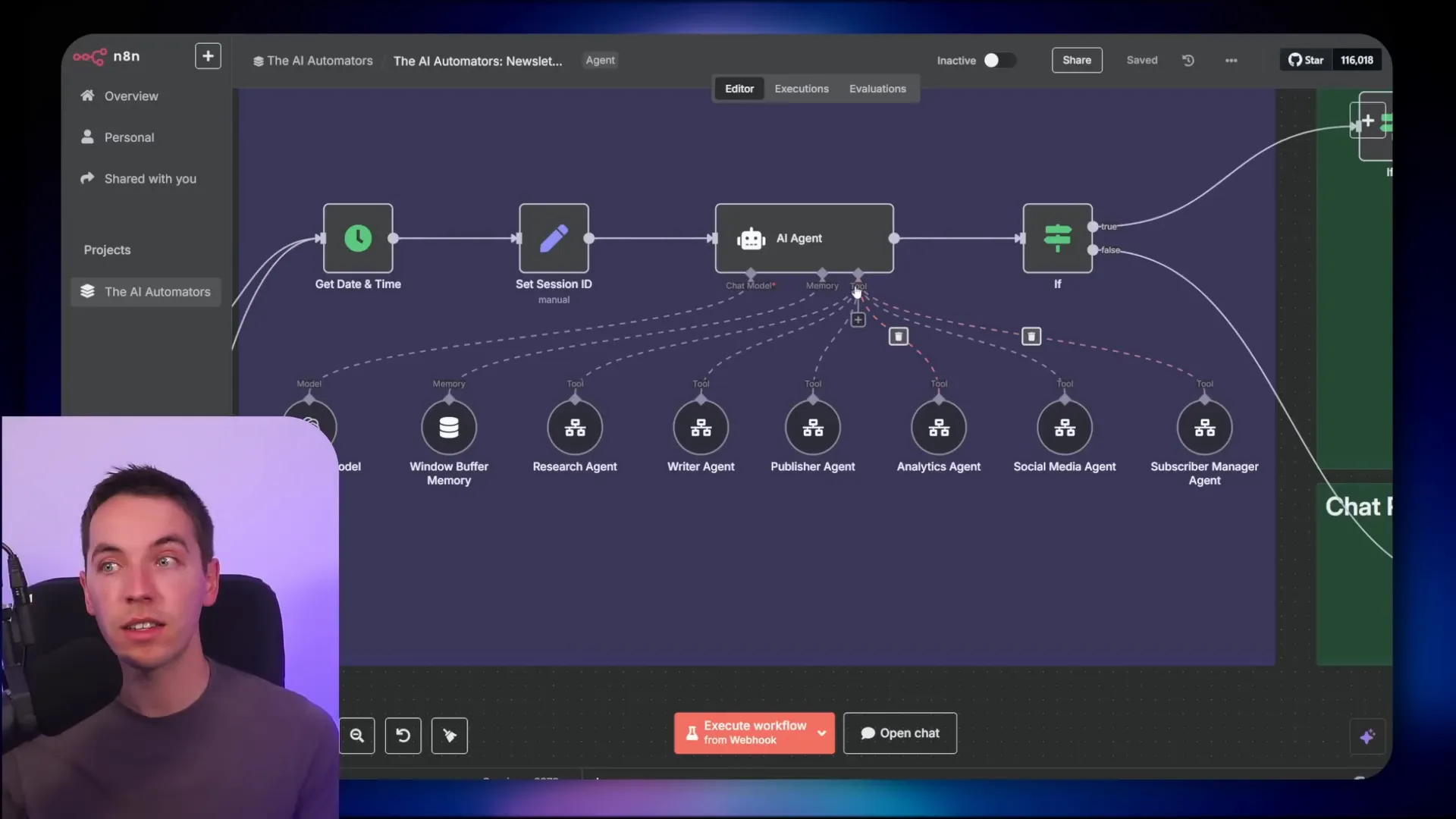
5. Context Isolation: Keeping Subtasks Separate with Multi-Agent Teams
When AI agents have to handle many tools and tasks, the context window can get cluttered quickly. To address this, I use context isolation by splitting responsibilities across multiple sub agents, each with its own memory and context management.
For example, I created an AI agent team to handle newsletter generation. This team includes sub agents responsible for research, writing, publishing, analytics, social media posting, and subscriber management. Each sub agent operates within its own workflow, managing its own context and toolset.
This approach prevents the main agent from being overwhelmed by too many tools or too much context. Instead, the main agent delegates specific tasks to sub agents, which process their data and return concise results. This keeps the overall system organized and efficient.
One sub agent might receive the markdown of a web page or search results and decide how to handle it without polluting the main agent’s context. This multi-agent system can be extended as far as needed, with layers of supervisors and tools nested within sub agents.
This strategy is one of the few ways to natively manage external tools without overwhelming the main agent’s context window in n8n.
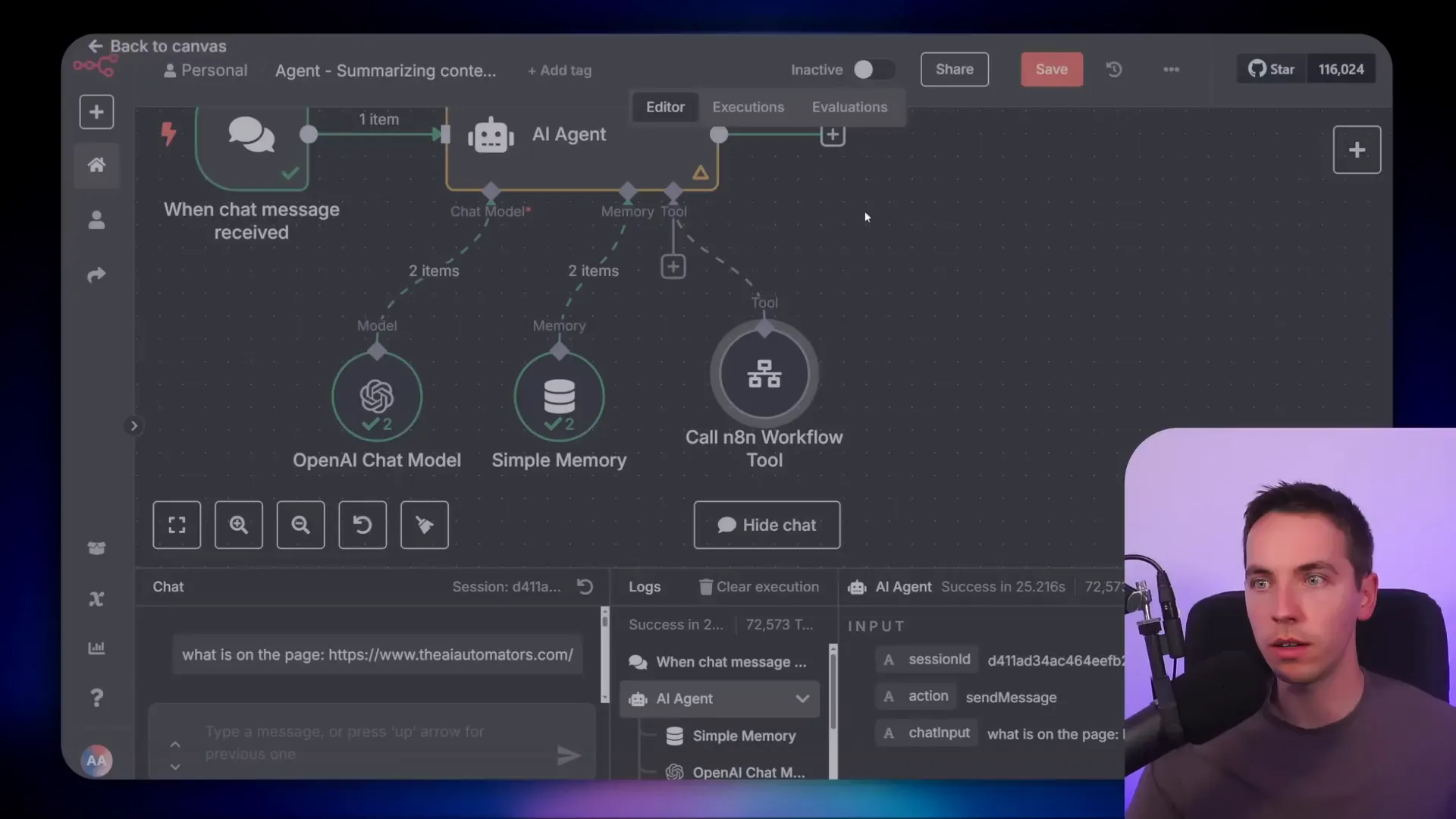
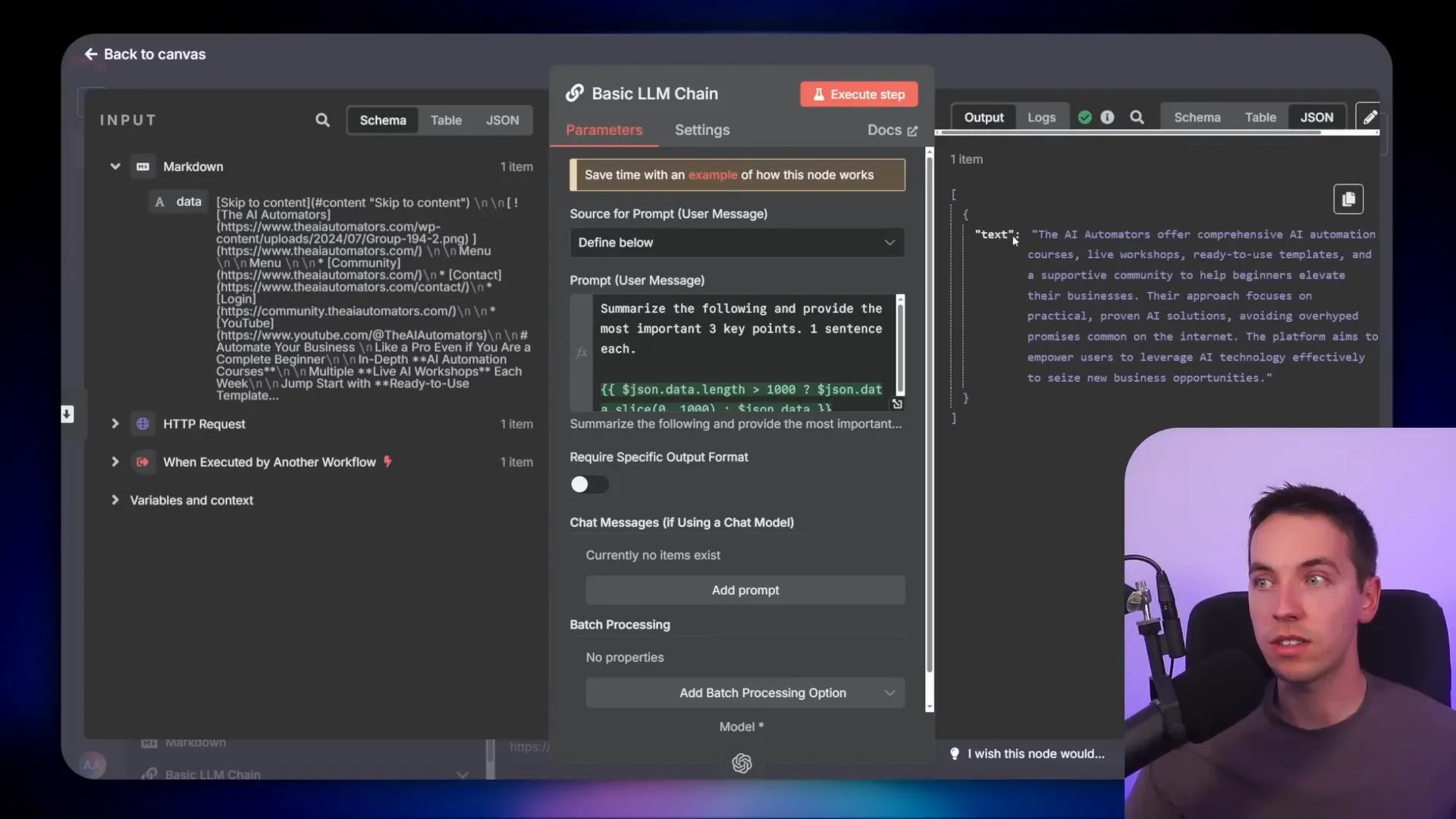
6. Summarizing Context: Compressing Data Before Feeding It to the AI
Summarizing context is a form of context compression that helps reduce the amount of data sent to the AI model. Instead of dumping large chunks of raw data into the context window, I create workflows that summarize or distill the information first.
For a simple example, I connected an HTTP request tool that scrapes the entire HTML of an external website. Sending the full HTML to the AI model is expensive and inefficient, especially if repeated multiple times or combined with other tools.
To improve this, I created a separate workflow that scrapes the page, then passes the HTML to an AI chain that summarizes the content into three key points, each one sentence long. This summary is far more manageable and relevant for the AI to process.
I then call this summarizing workflow from the main agent, which receives only the concise summary instead of the full HTML. This keeps the main agent’s context clean and reduces token usage, speeding up processing and cutting costs.
You can use either an LLM chain or a sub agent within the summarizing workflow, depending on your needs. This method is especially useful when dealing with large or complex external data sources.
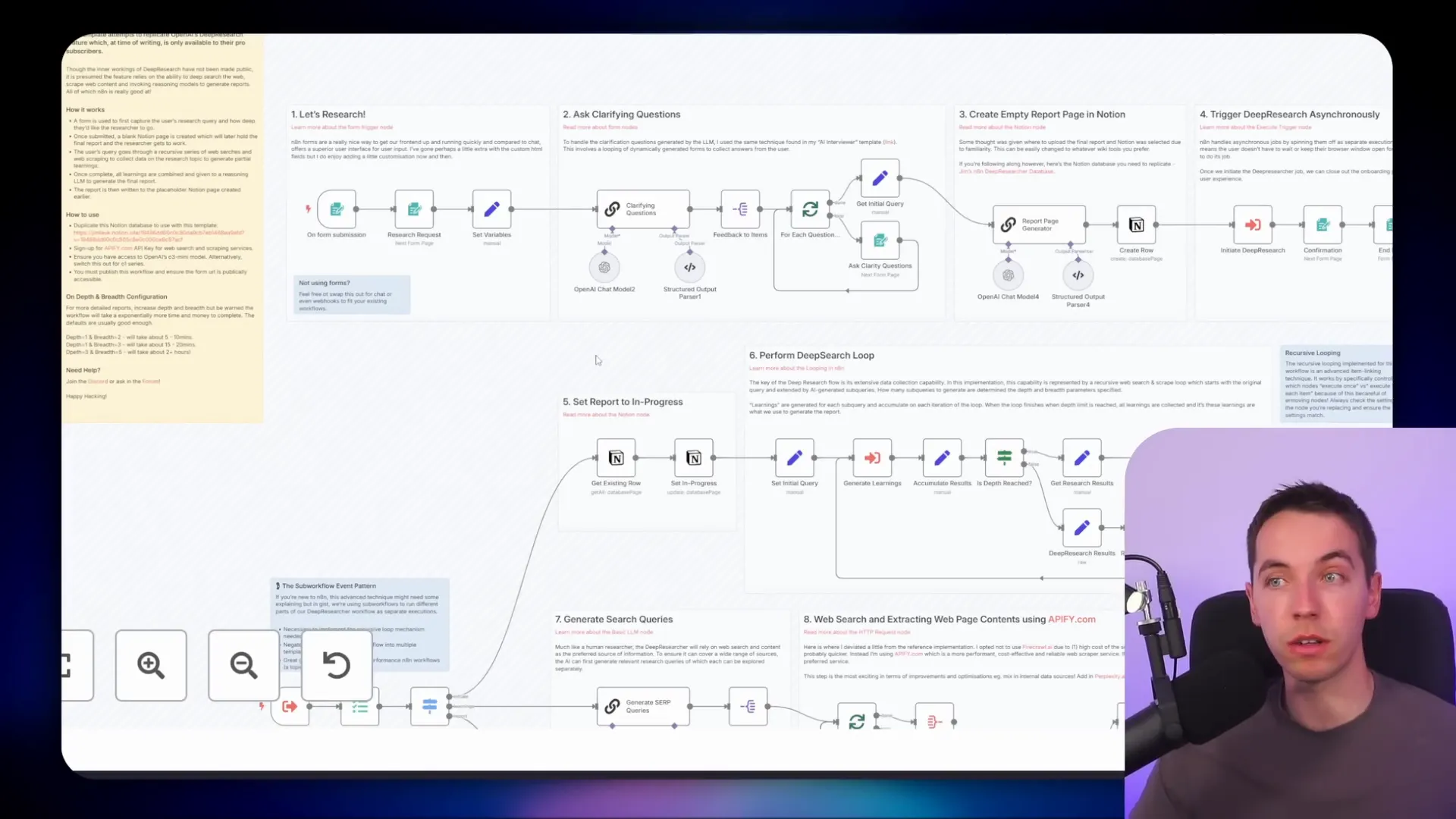
7. Deep Research Blueprint: Managing Long-Running, Data-Heavy Tasks
Deep research is an advanced use case that requires careful context management because it involves scraping and processing large amounts of data over extended periods.
I built a deep research blueprint in n8n that takes a research topic submitted through a form and performs extensive data collection and analysis. This workflow executes a sub workflow multiple times, managing how context is passed between nodes to avoid overloading any single step.
The system researches topics one by one, compiles findings, and uses a chain-of-thought model to generate a comprehensive report. This deterministic routing of context is necessary to handle the volume of data involved.
Deep research workflows can take hours to complete, especially on higher settings, but they demonstrate how n8n can handle very long-running tasks that require managing vast context effectively.
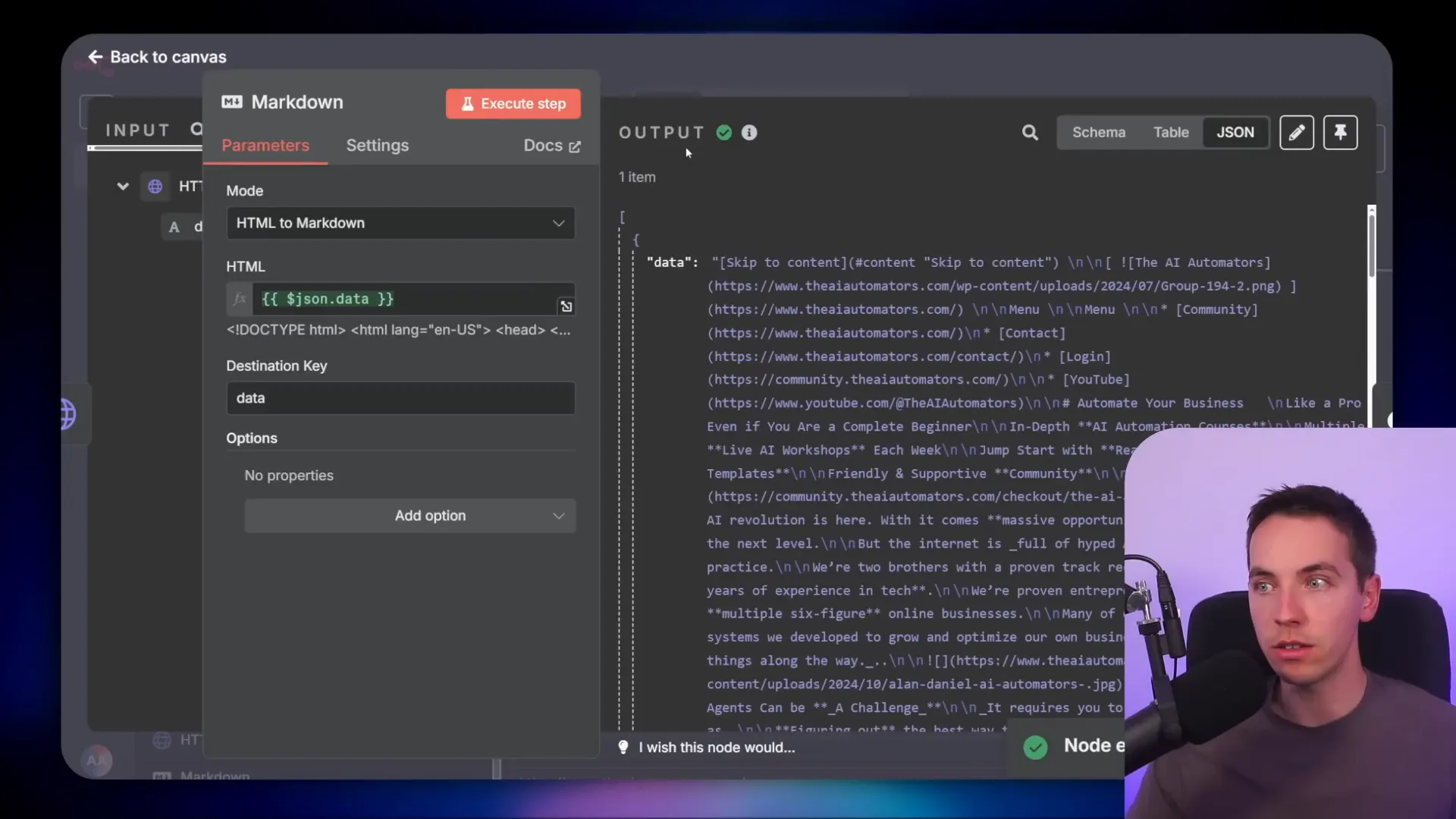
8. Formatting Context: Making Data More AI-Friendly
The format of your context matters. Raw HTML from web scraping contains a lot of extra information that’s not useful for the AI and can consume many tokens unnecessarily.
To optimize this, I convert HTML to Markdown, which is much cleaner and easier for the AI model to understand. Using n8n’s markdown node, I transform the scraped HTML before passing it into the AI chain.
This simple step greatly reduces token usage, making the process cheaper and faster. Alternatively, you can use services like Firecrawl.dev, which return web page content directly in Markdown format, saving you the conversion step.
Formatting context properly helps ensure the AI focuses on the most relevant information and improves overall agent efficiency.
9. Trimming Context: Reducing Data Size to Fit Token Limits
Sometimes, you need to trim the context to fit within token limits or reduce costs. A straightforward way is to limit the length of the text passed to the AI model.
For example, I use a simple expression that takes only the first 1,000 characters of the scraped Markdown content before sending it to the AI. This basic trimming can speed up processing and reduce expenses.
Other ways to trim context include reducing the short-term memory window length or limiting the number of chunks returned by a vector database query. These strategies help maintain a manageable context size without sacrificing too much relevant information.
Why Context Engineering Matters: Avoiding Common Pitfalls
As AI agents grow more capable and complex, managing context becomes critical. If you don’t control the context properly, you risk several issues:
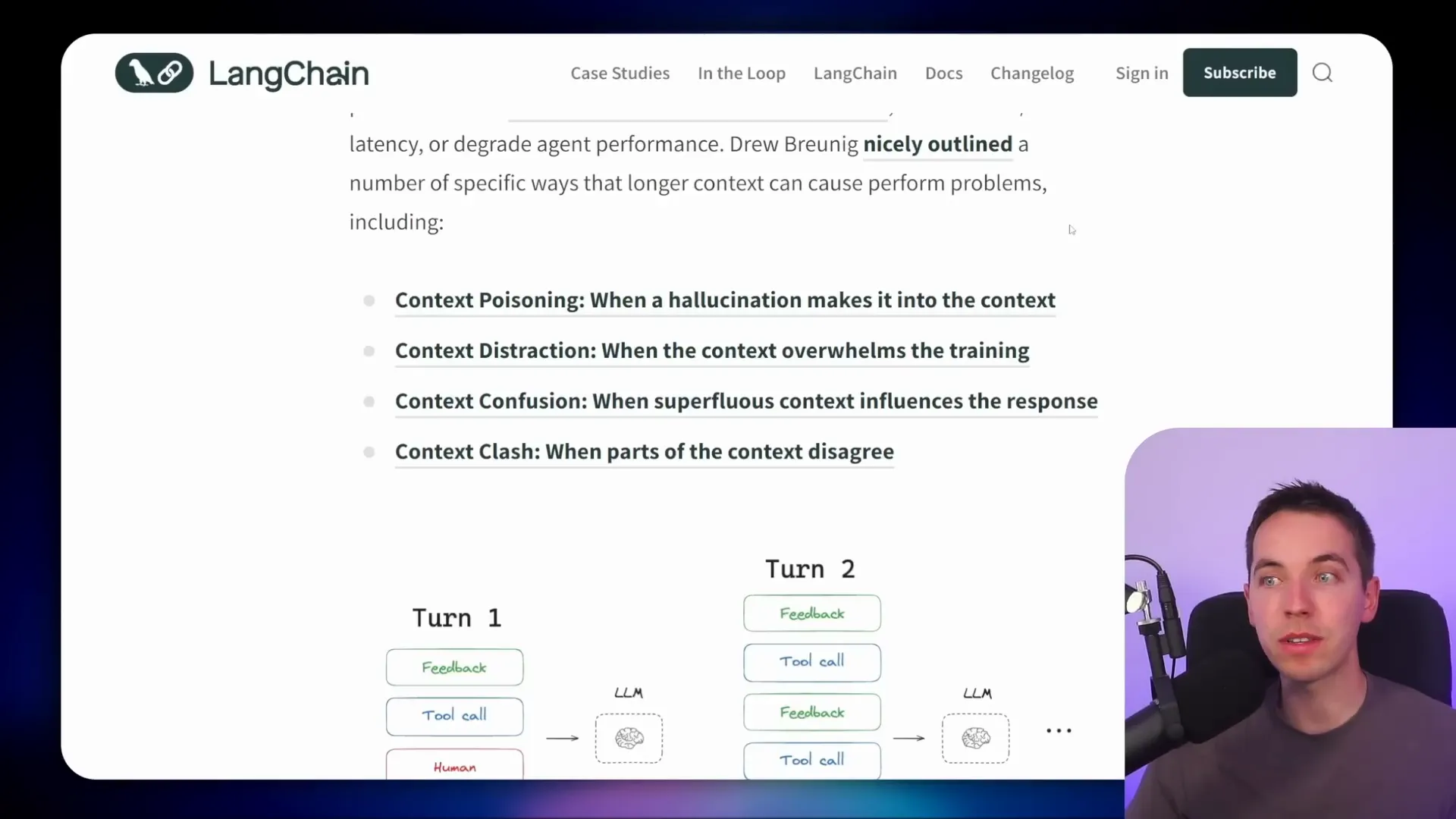
- Context Poisoning: When hallucinations or incorrect facts sneak into the context, the AI might faithfully reproduce those errors in future responses.
- Context Distraction: Too much information can confuse the AI, making it hard to focus on the relevant details—the classic needle-in-a-haystack problem.
- Contradictory or Irrelevant Information: Excess or conflicting data can degrade answer quality and cause inconsistent behavior.
These problems highlight why context engineering is one of the most important skills when building AI agents and automations. It’s about feeding the AI the right information, in the right format, at the right time.
Final Notes on Building Smarter AI Agents
We’ve moved beyond simple prompt engineering. Today’s AI agents tap into external sources, vector databases, and multiple tools, making their context much more dynamic. This shift demands a broader set of strategies to manage context effectively.
By combining short-term and long-term memory, tool calling, RAG, context isolation, summarization, formatting, and trimming, you can build AI agents that are more accurate, efficient, and reliable. Each technique helps keep the context window under control, ensuring your AI models perform at their best.
These strategies form a toolkit that empowers you to design AI workflows capable of handling complex, real-world tasks without succumbing to the limitations of token windows or context pollution.
