

In this blog, I explore Cache-Augmented Generation (CAG), a groundbreaking retrieval method that taps into server-side memory from OpenAI, Anthropic, and Google Gemini. I compare it with traditional Retrieval-Augmented Generation (RAG) to determine which method is more efficient and effective for various applications.
Introduction to CAG and RAG
Cache-Augmented Generation (CAG) and Retrieval-Augmented Generation (RAG) are two innovative approaches to enhancing the capabilities of large language models (LLMs). Both methods aim to improve the quality and relevance of responses generated by these models, but they do so in distinct ways.
CAG leverages server-side caching to store large sets of documents, allowing the model to access these documents quickly without needing to send the entire dataset with each query. This method is particularly useful for scenarios where quick access to extensive information is crucial.
On the other hand, RAG is built around the concept of breaking documents into smaller chunks, which are then embedded and stored in a vector database. This allows the model to retrieve relevant pieces of information based on user queries. While RAG has been a reliable approach, it comes with its own set of challenges, particularly when it comes to maintaining the relevance and accuracy of the retrieved information.
Demo of CAG in Action
To illustrate how CAG operates, I created a workflow using Google Gemini. In this setup, I loaded a comprehensive document—the technical regulations of Formula One—into the system. This document is lengthy, spanning 179 pages, and is stored in a PDF format.
The first step involves extracting text from the PDF and caching it on Google’s cloud servers. Once the document is cached, it generates a unique cache ID, which is essential for future queries. For instance, when I asked about the rules surrounding the Gurney, a specific component of an F1 car, the system used the cached information to provide a detailed response without needing to send the entire document again.

Understanding RAG: The Basics
RAG operates through a two-stage process. Initially, data must be ingested into a vector database. This involves taking a document and splitting it into manageable chunks. Each chunk is then transformed into a numerical representation through an embedding model, allowing for efficient storage and retrieval.
Once the data is in the vector database, it can be queried. When a user submits a question, the query is also converted into a numerical representation, enabling the system to find the most relevant chunks of information. These chunks are then sent to the LLM to generate a response. While effective, RAG can face challenges regarding the accuracy of the retrieved chunks, especially if they are independent of one another.

Exploring CAG: How It Works
CAG introduces a different architecture by focusing on caching. Instead of breaking down documents into chunks, it allows for the entire document to be cached and accessed via a simple cache ID. This method significantly reduces the amount of data that needs to be processed with each query.
For example, when I set up a CAG workflow with OpenAI, the system efficiently retrieves cached information without the need to resend the entire document. This approach not only speeds up response times but also simplifies the process of managing data. The cached content can remain accessible for an extended period, enhancing the user experience.

CAG vs RAG: A Head-to-Head Comparison
When comparing CAG and RAG, several factors come into play, including accuracy, data freshness, latency, and cost. CAG tends to provide more accurate responses due to the large context it can retain, while RAG may struggle with context loss, especially when chunks are independent.
In terms of data freshness, RAG has the advantage. Any updates made to the vector database are immediately available for queries, ensuring that the information is current. CAG, however, requires a mechanism to refresh the cache, which can add complexity.
Latency is another area where CAG excels. The preloaded knowledge in the cache allows for rapid responses, making it suitable for applications like chatbots that require quick turnaround times. On the other hand, RAG can be slower due to the need to process smaller chunks of data.
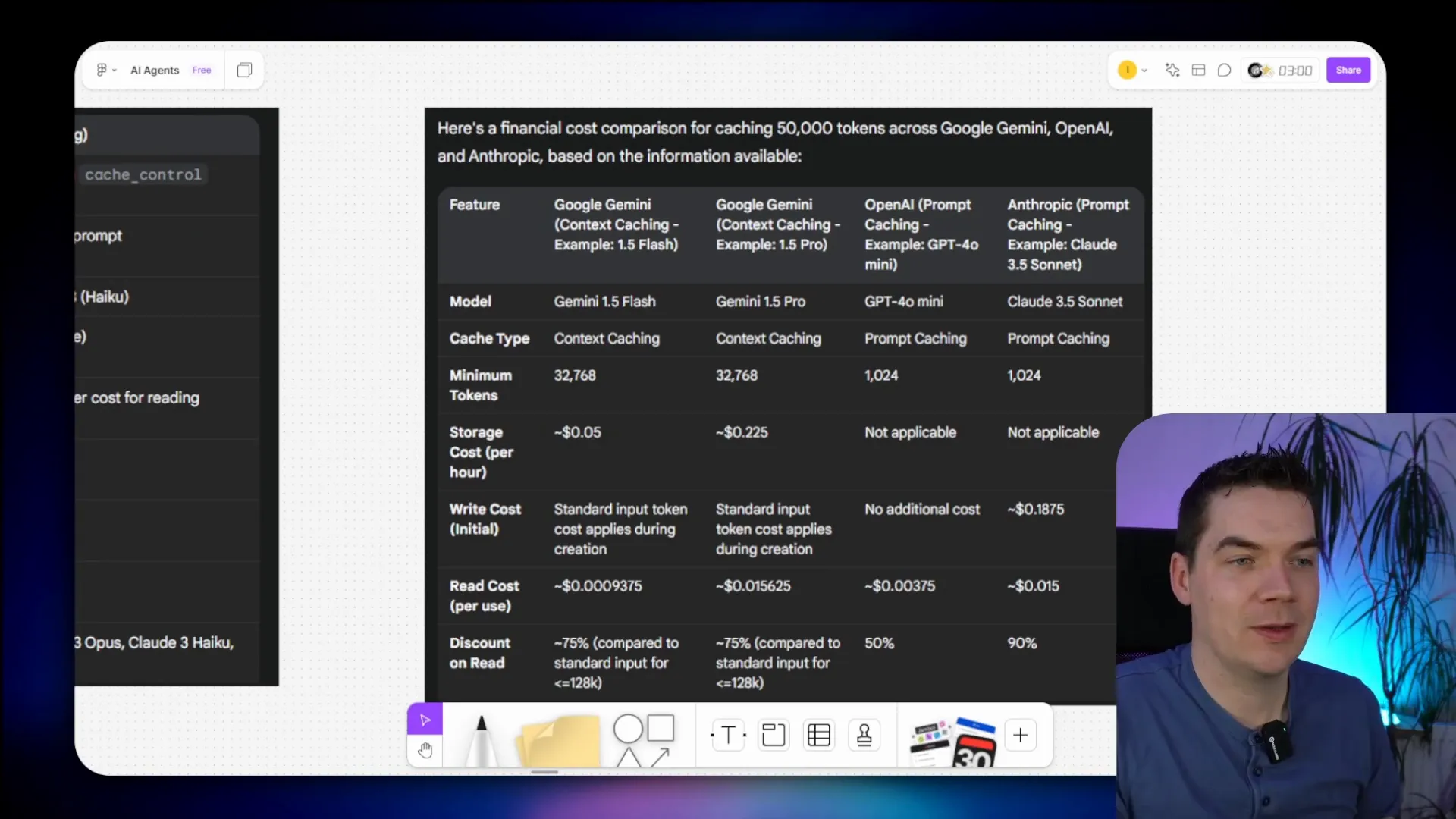
Cost is a significant consideration as well. RAG generally incurs lower costs because it deals with smaller chunks of data. In contrast, CAG can become expensive, especially when working with large datasets. Providers have different pricing structures, so budgeting is essential when considering implementation.
Setting Up CAG in N8N
Setting up Cache-Augmented Generation (CAG) in N8N is straightforward but requires a few steps to ensure everything runs smoothly. I created an automation that integrates Google Gemini, OpenAI, and Anthropic models. Here’s how to get started.
Initial Configuration
First, you need to create an N8N workflow. Begin by setting up the necessary nodes for Google Gemini. You’ll want to ensure your Google Cloud credentials are correctly configured. This allows you to upload documents and access your cache efficiently.

Uploading Documents
Next, upload your documents to Google Gemini. I recommend using a PDF for complex documents. When you upload a file, you’ll receive a unique cache ID. This ID is crucial for retrieving the cached content later.

Creating the Cache
Once your document is uploaded, configure the cache settings. You can set the Time-To-Live (TTL) to determine how long the cache remains active. For example, you might set it to one hour for frequently changing documents or up to two days for static content.
Sending Queries
After the cache is established, you can set up a node to send queries. When a user submits a query, pass the cache ID along with the query to Google Gemini. This ensures the system retrieves the correct cached document.

CAG Architecture: Key Components
The architecture of CAG consists of several key components that work together to enhance data retrieval and response generation. Understanding these components can help you leverage CAG effectively.
Cache Storage
At the core of CAG is the cache storage system. This system allows documents to be stored and accessed quickly without needing to resend the entire dataset with each query. The cache can hold large amounts of data, making it suitable for extensive documents.
Cache ID Management
Each uploaded document generates a unique cache ID. This ID plays a vital role in querying and retrieving data. You must manage these IDs efficiently, storing them in a database or a no-code tool for easy retrieval.

Query Handling
Queries are processed by sending the cache ID along with the user’s question. This design minimizes data transfer and speeds up response times. The system retrieves the relevant cached content and generates a response based on the entire document context.
Challenges with RAG
While Retrieval-Augmented Generation (RAG) has its merits, it also comes with several challenges that can impact performance and user experience.
Chunk Independence
RAG operates by breaking documents into smaller chunks. However, this independence can lead to problems. If chunks don’t contain relevant context, the model may generate less accurate responses. This issue becomes more pronounced when the chunks are too small or poorly defined.
Maintenance Overhead
Maintaining a RAG system can be resource-intensive. When documents are updated, the vector database must also be updated. This entails deleting old vectors and importing new ones, which can lead to additional overhead and complexity.
Context Loss
Another significant challenge with RAG is context loss. When independent chunks are retrieved, the model may not have access to all the necessary context needed to generate a coherent answer. This can result in outputs that feel disjointed or incomplete.

Advantages of CAG
CAG offers several advantages that make it an appealing option for developers and businesses looking to enhance their AI capabilities.
Improved Accuracy
One of the primary benefits of CAG is its potential for improved accuracy. By retaining the entire document in cache, the model has access to a broader context. This leads to more precise and relevant responses, especially for complex queries.
Reduced Latency
CAG also significantly reduces latency. Because the data is preloaded into the cache, response times are much faster compared to RAG. This speed is particularly beneficial for applications requiring real-time interactions, such as chatbots.
Simplified Workflow
Setting up CAG can be less complicated than RAG. With fewer steps involved in data management, developers can focus on building features rather than maintaining the underlying infrastructure. This simplicity can lead to quicker deployment and iteration cycles.

Cost Analysis: CAG vs RAG
Cost is a crucial factor when deciding between CAG and RAG. Here’s how they compare.
Cost of Storage
CAG typically incurs higher storage costs due to the nature of caching entire documents. Providers like Google Gemini charge for storage based on the duration files remain in cache. In contrast, RAG often has lower storage costs since it deals with smaller chunks of data.
Query Costs
Each query to a cached document in CAG may incur a read cost. However, providers often offer discounts, so you might only pay a fraction of the cost compared to sending the entire document. RAG, while generally cheaper, may require additional costs for maintaining the vector database.
Budgeting for Implementation
When implementing CAG, it’s essential to budget for both storage and query costs. If your system is already using RAG, analyze your typical inference rates and estimate how those costs might change with a CAG setup. This analysis will help you make an informed decision.
Data Freshness and Maintenance
Data freshness is crucial in any retrieval system. With Retrieval-Augmented Generation (RAG), updates are immediate. When a vector database receives new information, it’s available for queries right away. This ensures the responses delivered are current and relevant.
On the other hand, Cache-Augmented Generation (CAG) requires a different approach. Cached documents can become outdated if not refreshed. Establishing a system to manage the cache lifecycle is essential. This includes determining how often to refresh the cache and how long to keep documents stored. For example, I typically set a Time-To-Live (TTL) for one hour to two days, depending on the content’s volatility.
To maintain data freshness in CAG, I often create a monitoring system. This system checks if the cached documents are still valid. If they’re not, I’ll either refresh the cache or remove outdated entries. This proactive approach helps ensure users receive accurate information.
Use Case Scenarios for RAG
RAG shines in scenarios where data is frequently updated or large knowledge bases are involved. Here are some specific use cases:
- Research Databases: In environments where new studies and papers are constantly published, RAG allows for real-time access to the most recent information.
- Dynamic Content Websites: Websites that frequently update their content, like news outlets, benefit from RAG’s ability to pull the latest articles and information.
- Legal and Compliance: In legal settings, regulations and guidelines can change rapidly. RAG ensures that legal professionals have access to the most current laws and regulations.
In these cases, the ability to quickly update and retrieve information makes RAG the ideal choice. The independence of chunks means that even if one section is outdated, the rest can still provide relevant context.

When to Use CAG
Cache-Augmented Generation is best suited for scenarios where the data is relatively static and speed is essential. Consider these situations:
- Chatbots: For customer service chatbots, quick access to product manuals or FAQs can enhance user experience significantly.
- Educational Tools: Tools that provide students with quick references to textbooks or academic papers can benefit from CAG’s rapid retrieval capabilities.
- Static Documentation: In environments where the information doesn’t change often, like technical manuals, CAG can provide fast and accurate responses without constant updates.
In these cases, the speed of response is paramount. CAG can deliver answers almost instantaneously, providing a smoother experience for users.

The Future of CAG and RAG
The future of both CAG and RAG looks promising. As technology evolves, we might see enhancements in both methods. For CAG, improvements in caching mechanisms could lead to better management of data freshness. This would allow caches to be updated more seamlessly, reducing the need for manual refreshes.
For RAG, advancements in embedding models and vector databases could enhance the accuracy of retrieved chunks. This would minimize context loss and improve the quality of responses. Integrating contextual retrieval techniques could also help mitigate the issues associated with chunk independence.
Ultimately, the choice between CAG and RAG will depend on the specific requirements of the application. Understanding these methods and their strengths will allow developers and businesses to make informed decisions about which approach to adopt.
