

In this article, I’ll share how I built a complex full-stack web application using no-code tools over just three days. The app, Insights LM, is a fully functional clone of Google’s NotebookLM, packed with advanced features like file uploads, AI-powered document chat using Retrieval-Augmented Generation (RAG), inline citations, podcast generation, and more. I achieved this without writing any code, using a tech stack composed of Lovable for the front end, Supabase for authentication, database, and storage, and n8n for automation workflows.
This project showcases how these no-code tools can be combined to build a sophisticated web app that connects front end, back end, authentication, and automation seamlessly. Throughout the build, I encountered challenges and solved them step-by-step, which I will explain here to provide insight into the process.
Demo and High-Level Architecture
Starting with a quick demo, the user lands on a login screen where they enter their credentials. Once authenticated, they reach the dashboard where they can create a new notebook. Uploading documents initiates processing workflows that index the content in a vector store, enabling AI-powered chat grounded in the uploaded documents.
For example, if you ask, “What are the claim procedures for lost baggage?” the AI agent queries the vector store containing the indexed documents and generates a factual, verifiable response with inline citations.
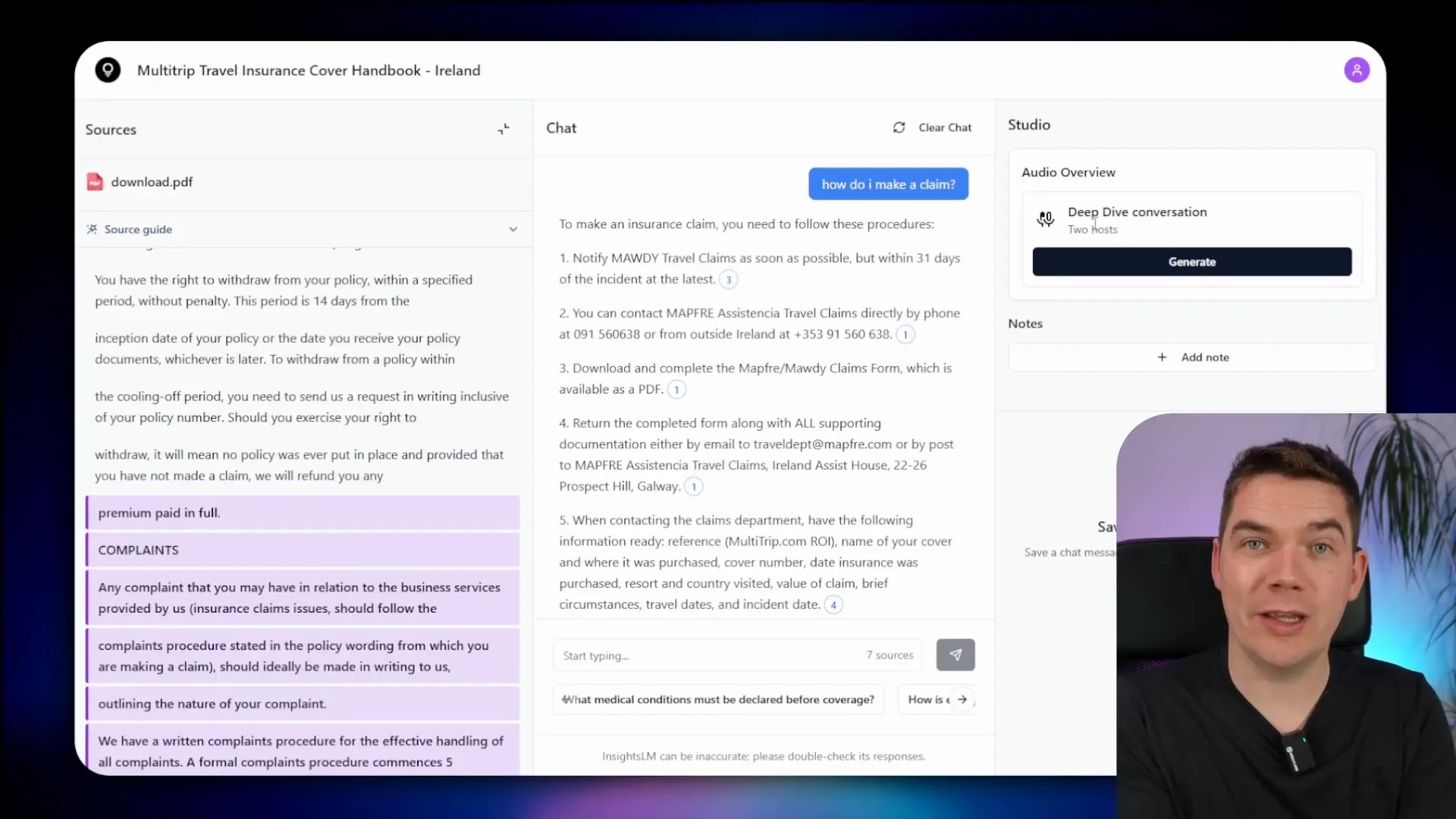
The citations link directly to specific sections of the source documents, making it easy to verify the AI’s answers. Additionally, the app supports generating podcast-style audio overviews where two hosts discuss the notebook content.
The architecture consists of a React front end built with Lovable, Supabase handling authentication, data storage, and file storage, and n8n managing the automation workflows. Supabase Edge Functions act as the bridge between the front end and n8n workflows, triggering document chunking, notebook description generation, and more.
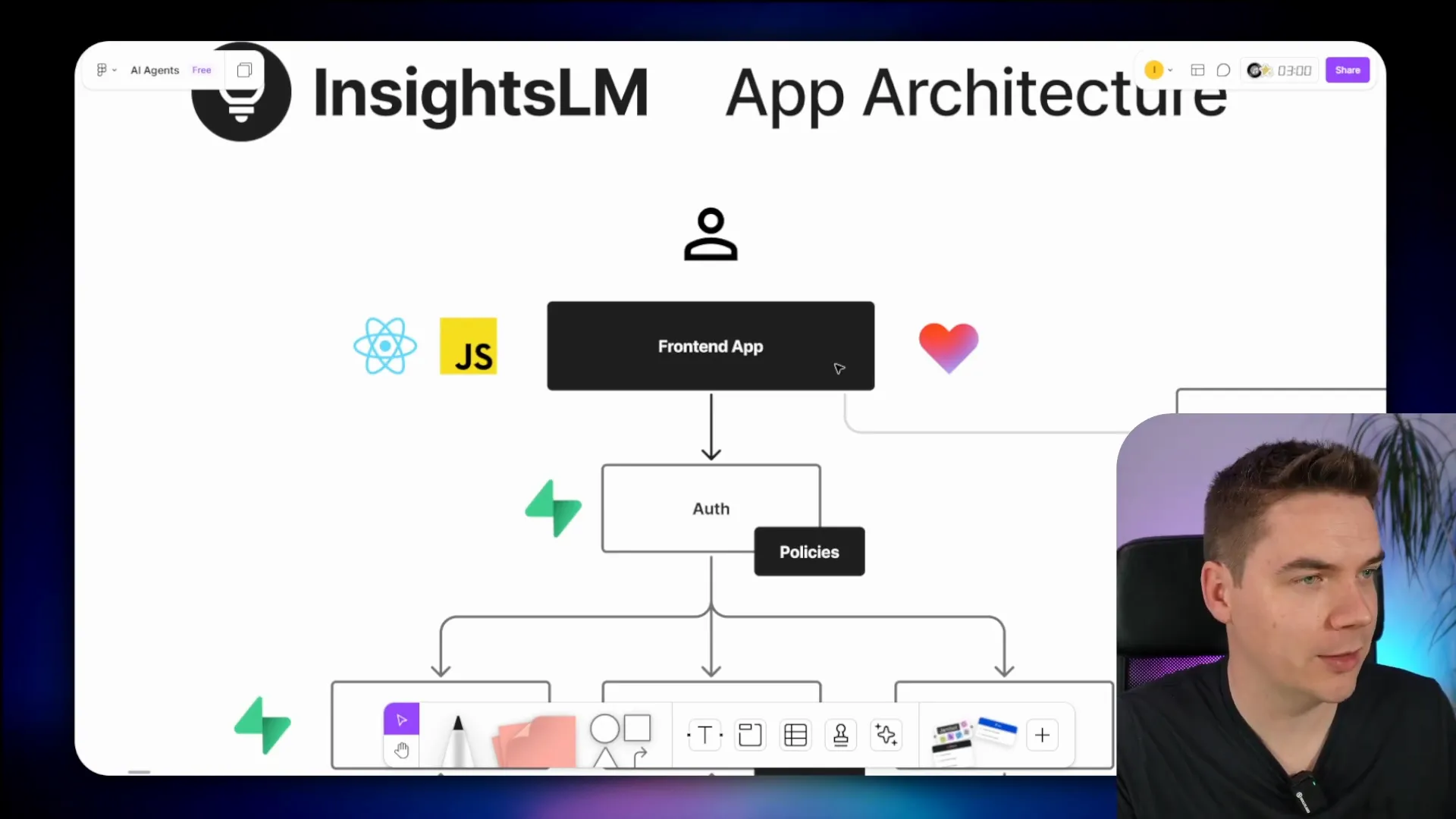
Supabase policies ensure users only access their own data, and while it would be possible to build all processing logic in Edge Functions, n8n proved invaluable for quickly wiring up complex workflows.
Getting Started with Lovable and Supabase
I began by crafting a clear prompt for Lovable to create a blank project with core features: notebook creation, document uploads, AI-based chat grounded on documents, audio overviews, and note saving. I specified using Supabase for authentication and data storage, and n8n for backend workflows.
First, I asked Lovable to implement login and logout screens and an empty dashboard, explicitly disallowing user registration within the app to keep control over user accounts.
After creating a new project in Supabase named “my notebook lm,” I connected it to Lovable. Lovable then generated the authentication flow using Supabase’s authentication system.
To test the login, I manually added a user in Supabase’s authentication panel and logged in through the app. The dashboard initially had unnecessary sign-up links, which I removed by updating the app’s prompts and code.
Building the Front End Screens
I took screenshots of Google’s NotebookLM dashboard to guide Lovable in updating the dashboard UI to reflect two states: one with no notebooks and one with multiple notebooks. While the AI-generated UI wasn’t pixel perfect, it was close enough to proceed and could be refined later.
Lovable recommended building the front end first using placeholder text before integrating the database to avoid schema issues. So I asked it to build the notebook interface itself, showing an empty notebook with sections for sources, chat, and a studio panel for audio overview and notes.
After approving the plan generated by Lovable, the notebook page was created with the expected layout. I then cleaned up the interface by removing unnecessary features like the “discover” button, sharing options, and multi-language support using Lovable’s element selection and deletion tools.
Next, I created the “Add Sources” pop-up screen modeled after NotebookLM’s design, refining it through iterations and restoring previous versions when the UI didn’t match expectations. I simplified the file upload process to support drag and drop only for this phase.
Integrating the Back End Database
With the front end mostly complete, I planned the database schema through Lovable’s chat mode. The schema included tables for notebooks, sources (documents), chat messages, and user-created notes. I removed unused tables like user preferences and notebook collaborators to keep things simple.
Private storage buckets were enforced by setting policies to prevent public access to uploaded files.
After creating the tables in Supabase, Lovable connected the front end UI to the database. Creating a new notebook and uploading a source triggered some errors, which I resolved by instructing Lovable to create notebooks in the database when the user clicks “Create New” and to redirect properly to the notebook page.
I enabled editing notebook titles both on the dashboard and within the notebook itself. I also added a delete notebook feature with a confirmation pop-up, improving usability.
Managing Sources and Storage
Uploading sources created entries in the database but initially did not upload files to Supabase storage. I instructed Lovable to upload files to a “sources” bucket in folders named after the notebook ID to prevent file clutter.
After fixing the file path linkage between the database and storage, I added functionality to remove sources, including deleting files from storage, and to rename sources via a context menu triggered by right-clicking on each source item.
Generating Notebook Titles and Descriptions
To automate notebook metadata, I created an n8n webhook workflow triggered when the first source is uploaded. It downloads the file securely from Supabase storage, extracts the text, and sends it to an LLM to generate a title and description in JSON format.
Supabase Edge Functions handle the communication between the front end and n8n, ensuring secure API calls with header authentication.
The generated title and description are saved back to the notebook record, with a generation status field tracking progress for UI feedback.
Implementing Chat with AI and RAG
The chat feature has two parts: basic conversation with an LLM and a RAG component that retrieves relevant document chunks from a vector store to ground responses in uploaded documents.
Each chat message triggers an n8n webhook that calls an AI agent. The chat history is saved in a dedicated Postgres table in Supabase, using the notebook ID as the session ID to isolate conversations per notebook.
Lovable was used to refactor the app to use this n8n-managed chat history table exclusively, removing duplicate chat tables.
Messages are posted to the webhook, and loading indicators show “AI is thinking” while the agent processes the query. I improved the UI to immediately display the user’s question while awaiting the AI’s response, enhancing responsiveness.
To improve readability, I enabled markdown rendering for chat responses, allowing proper formatting of new lines, bold text, and more.
Document Chunking and Vector Store
When documents are uploaded, they are chunked and embedded into a vector store using Supabase’s PGVector extension. I enabled this extension and created a documents table to store chunk embeddings, metadata, and content.
An n8n workflow downloads the document, extracts text, splits it into chunks using a recursive character text splitter, generates embeddings with OpenAI’s embedding model, and upserts them into the vector store with metadata including the notebook ID.
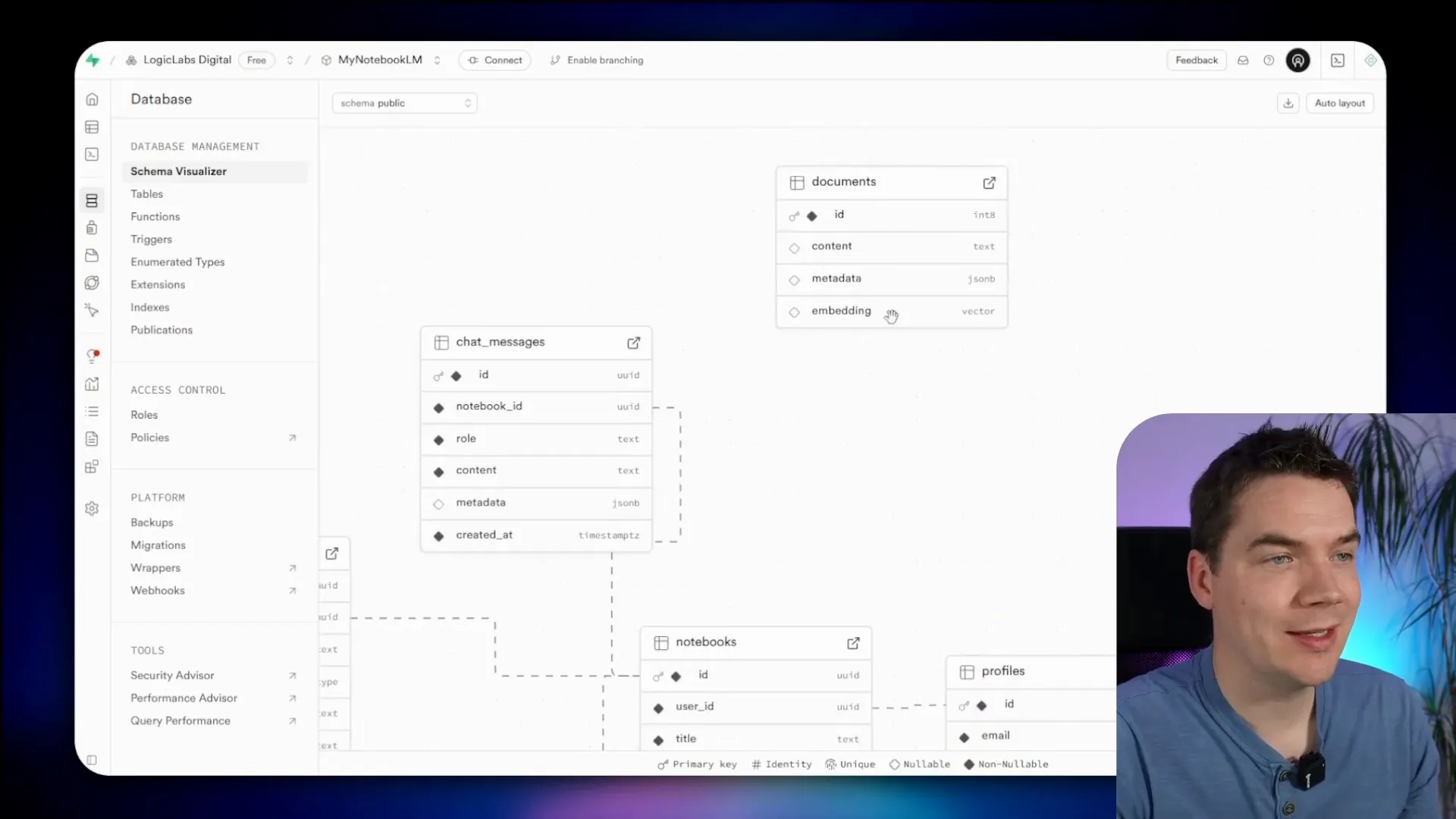
After chunking, a callback updates the source’s processing status. The AI agent queries this vector store with a metadata filter on notebook ID to ensure responses are based only on the notebook’s documents.
Inline Citations and Source Preview
To build trust and verifiability, I implemented inline citations in AI responses that link to specific chunks and line numbers within the source documents.
Each citation is rendered as a clickable button in the chat interface. Clicking a citation opens the corresponding source text on the left panel and highlights the relevant lines.
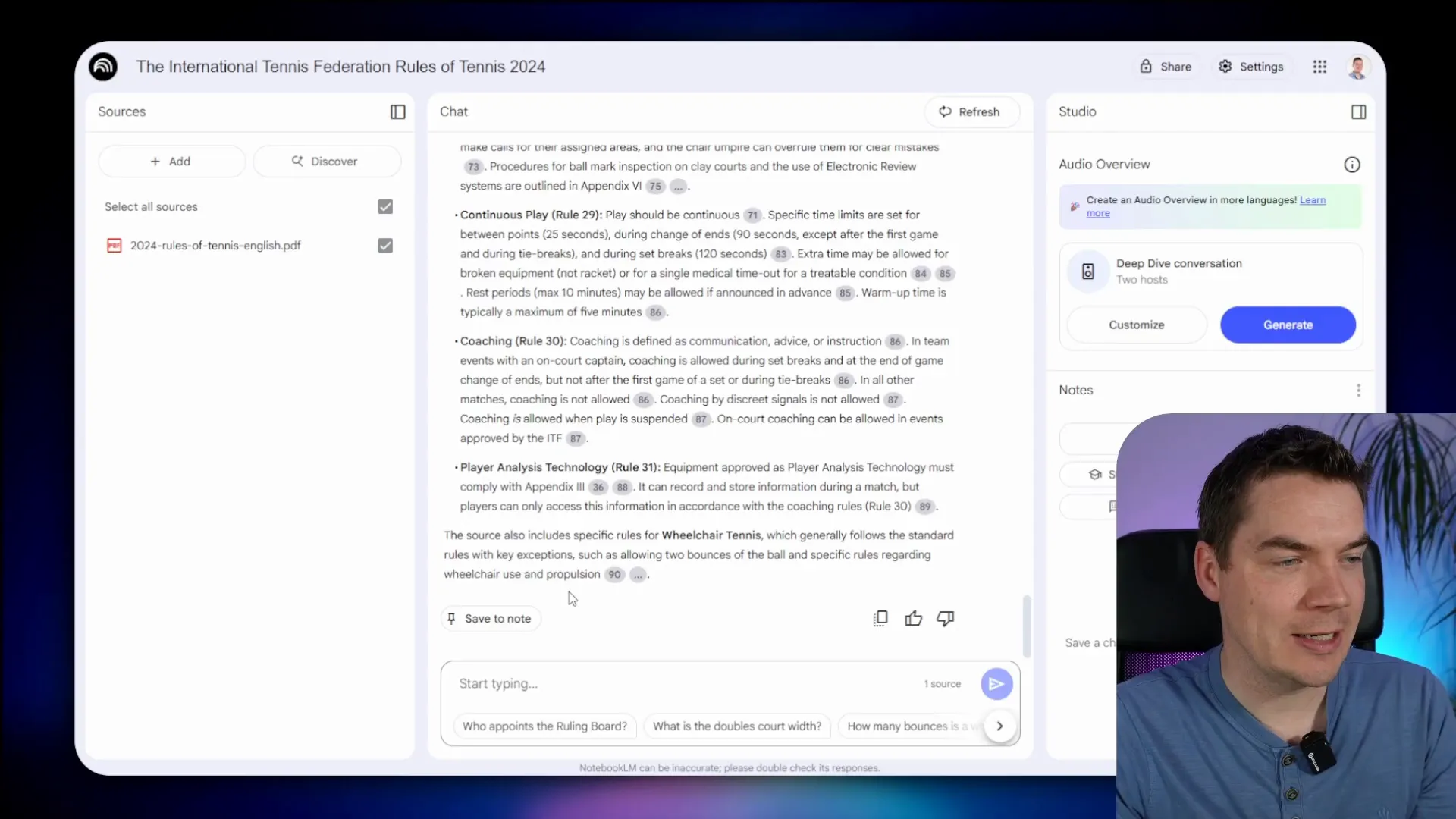
The chunking process was enhanced to include source ID and display name metadata for each chunk, and to generate summaries for each source document using an LLM.
Lovable helped design the UI to handle structured JSON responses from the AI agent containing text and citation data, making parsing and rendering straightforward.
Supporting Multiple File Formats
Initially supporting PDFs only, I extended the system to handle audio (MP3) and plain text files.
For audio files, I integrated OpenAI’s transcription in n8n to convert speech to text, which is then chunked and embedded similarly to PDFs.
For text files, I added a branch in the workflow to directly extract text content for chunking.
Suggested Questions Feature
Inspired by NotebookLM, I implemented a feature to generate example questions based on the content of the first uploaded source. These questions appear at the bottom of the chat interface as clickable prompts that populate the chat input and trigger a query.
Example questions are generated by the LLM during notebook detail generation and saved as a JSON array in the notebook record.
Notes Feature
The notes section on the right side allows users to save AI responses or manual notes linked to the notebook.
Clicking “Save to note” on an AI response saves it as a read-only note with citations rendered similarly to the chat interface. Users can also add, edit, or delete manual notes.
Titles for AI response notes are generated with a separate Edge Function calling an LLM to produce concise summaries.
Podcast Generation
One of the most exciting features is podcast generation. Using Google’s Gemini 2.5 text-to-speech API, I created an n8n workflow that synthesizes a podcast-style audio overview featuring two hosts discussing the notebook’s sources.
The workflow aggregates all source texts, generates a podcast script with dialogue, converts it to audio, and uploads the MP3 to Supabase storage. The front end plays this audio with controls, including download and delete options.
To handle large audio generation times exceeding Edge Function limits, I split the workflow into job submission and real-time status updates using Supabase’s real-time features to show progress and playback availability.
Deployment and Commercial Use
After completing version one, I published two GitHub repositories:
- InsightsLM Public Repo: Cloud-based, production-ready React app using OpenAI or Gemini services. It has gained over 200 stars and 100 forks.
- InsightsLM Local Package: Fully offline Docker containerized setup with local AI inference using Ollama, local Whisper for transcription, and Koki TTS for audio generation. This version keeps data on-premises for privacy and compliance.
Supabase is open source, but n8n uses a sustainable use license allowing free internal business use. For SaaS deployment, an n8n enterprise license may be required. Alternatively, workflows can be converted into Supabase Edge Functions to avoid n8n licensing constraints.
This project demonstrates how no-code tools can be combined to create an advanced AI research and productivity app, empowering users to interact with their documents in new ways while maintaining data security and control.
