

OpenAI recently published an open source orchestration spec called Symphony. On the surface, it looks like a practical system for scaling autonomous coding agents. But the deeper value isn’t just the tool itself. It’s the architecture lesson sitting underneath it.
The big shift is simple. As coding agents get better, the human stops being the person writing most of the code and becomes the person building the scaffolding around the agent. At that point, the hard problem changes. It stops being “how do I prompt this coding model?” and becomes “how do I build a system that can run agents reliably, at scale, with the right feedback loops and the right human checkpoints?”
That is why Symphony matters.
OpenAI framed it around a bottleneck they hit internally while trying to create software with zero lines of manually written code. Once the coding agents became efficient enough, people could no longer keep up with them. The humans became the slow part of the process. Symphony was their answer: an orchestration layer that lets agents pick up tasks and keep working with less supervision.
That idea has huge implications far beyond Codex or OpenAI. I think the real lesson is the three-layer mental model underneath systems like this:
- The model, which reasons and generates outputs
- The harness, which wraps the model and manages the actual behavior of the system
- The orchestrator, which coordinates many agents, tasks, and human checkpoints at a higher level
If you’re building any serious AI system, especially one involving coding agents, understanding those layers is far more useful than copying any single framework.
Why Symphony exists
Back in February, OpenAI shared an internal experiment around creating software with no manually written code. The engineer’s role shifted away from hand-coding features and into creating the setup that allowed coding agents to work independently.
That shift is easy to miss, but it’s fundamental.
Once an agent can generate code, edit files, run tools, and iterate on feedback, the limiting factor is no longer the model’s raw ability alone. The limiting factor becomes the process around it. How does the agent know what to work on? How is each task isolated? How do you stop sessions from stepping on each other? How do you decide when a human needs to step in?
Symphony is OpenAI’s answer to those questions in the context of software development.
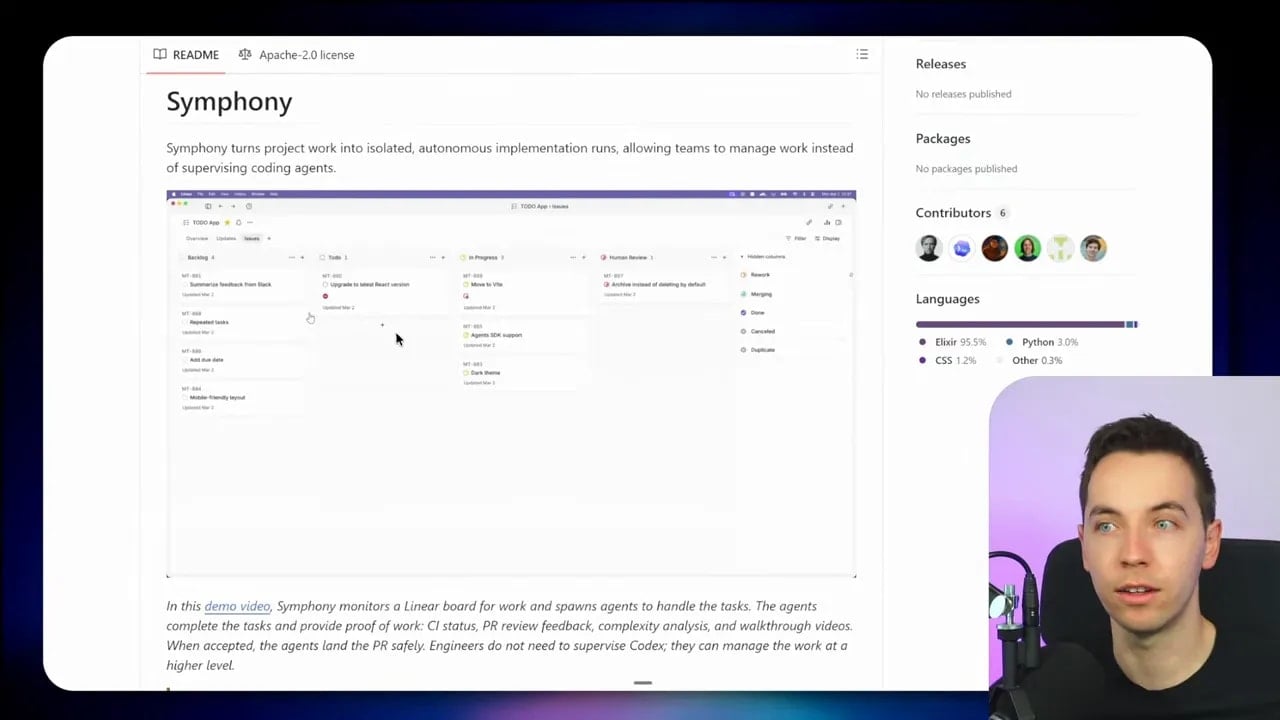
What Symphony actually does
At its core, Symphony is an agent orchestrator. It connects an issue tracker, such as Linear, to coding agents. Then it ensures that for every open ticket, an agent is running in its own isolated workspace and working continuously until the task is done.
That means the issue tracker becomes more than a project management board. It becomes a state machine for agent work.
A simplified version of the flow looks like this:
- A task appears in the issue tracker
- Symphony detects the task
- It starts or assigns a coding agent to that task
- The agent works in an isolated environment
- The system tracks status and reports back when needed
- The task continues until it reaches a done state
This is a very different mode of working from manually opening several coding chat tabs and supervising each one. Instead of managing sessions directly, the human interacts with a higher-level system. The board becomes the control surface.
That matters because it changes how teams operate. People can work at a higher level of abstraction. In theory, it can also involve less technical team members more directly, because the interface is the task board rather than the agent terminal.
OpenAI’s GitHub repository is mostly a spec rather than a full polished product. There’s a spec.md file that describes how the system works, plus a prototype implementation in Elixir. OpenAI also explicitly encouraged people to point their preferred coding agent at the spec and have it build an implementation in any language they want.
That is another useful signal. Symphony isn’t being presented as “use our exact stack or nothing.” It is being presented as a pattern.
You don’t even need to use Codex if you don’t want to. The architecture can orchestrate other coding agents as well. OpenAI highlighted examples of people adapting the pattern to other tools, including cloud-based coding sessions.
How the reference setup works
If you use the reference Elixir version, the rough setup is straightforward:
- Clone the repo
- Connect it to a Linear account with a personal API key
- Let the system continuously poll tickets
- Use Codex in app server mode as the agent runtime
“App server mode” means the Codex CLI runs as a long-lived process. Symphony can then call it programmatically rather than restarting it from scratch every time.
There is some marketing attached to all this, of course. OpenAI claimed that this approach led to a 500% increase in landed pull requests on some teams. Whether or not a given team sees that exact number isn’t the main point. Plenty of development teams have arrived at very similar architectures independently.
OpenAI did not invent orchestration around coding agents. What they did do is put a recognizable name and an open spec around a pattern that many builders are already moving toward.
The actual lesson: the harness is where the engineering happens
Most people hit the same wall when they try to move past a few coding chat sessions.
An agent looks impressive in a single session. Then you try to scale it. You want more autonomy, more tasks in parallel, more reliability, and less hand-holding. Suddenly the architecture gets messy.
This is where the idea of an agent harness becomes useful.
A good definition comes from Philip Schmid: an agent harness is the infrastructure that wraps around an AI model.
I like that framing because it makes one thing very clear. The model is important, but it isn’t the whole system. In fact, it usually isn’t even most of the system.
The easiest analogy is this: the model is like a CPU.
A CPU is essential, but by itself it doesn’t give you a usable computer. You still need memory management, file systems, input and output, process control, permissions, scheduling, and a lot more. The same idea applies here.
An LLM can reason over inputs and generate outputs. That’s the core capability. But almost everything people associate with “agent behavior” sits outside the model itself:
- Chat history and memory
- Tool calling
- Execution of those tools
- Sub-agent management
- Permission boundaries
- Session lifecycle
- Context injection
- State persistence
- Feedback loops
All of that is harness code.
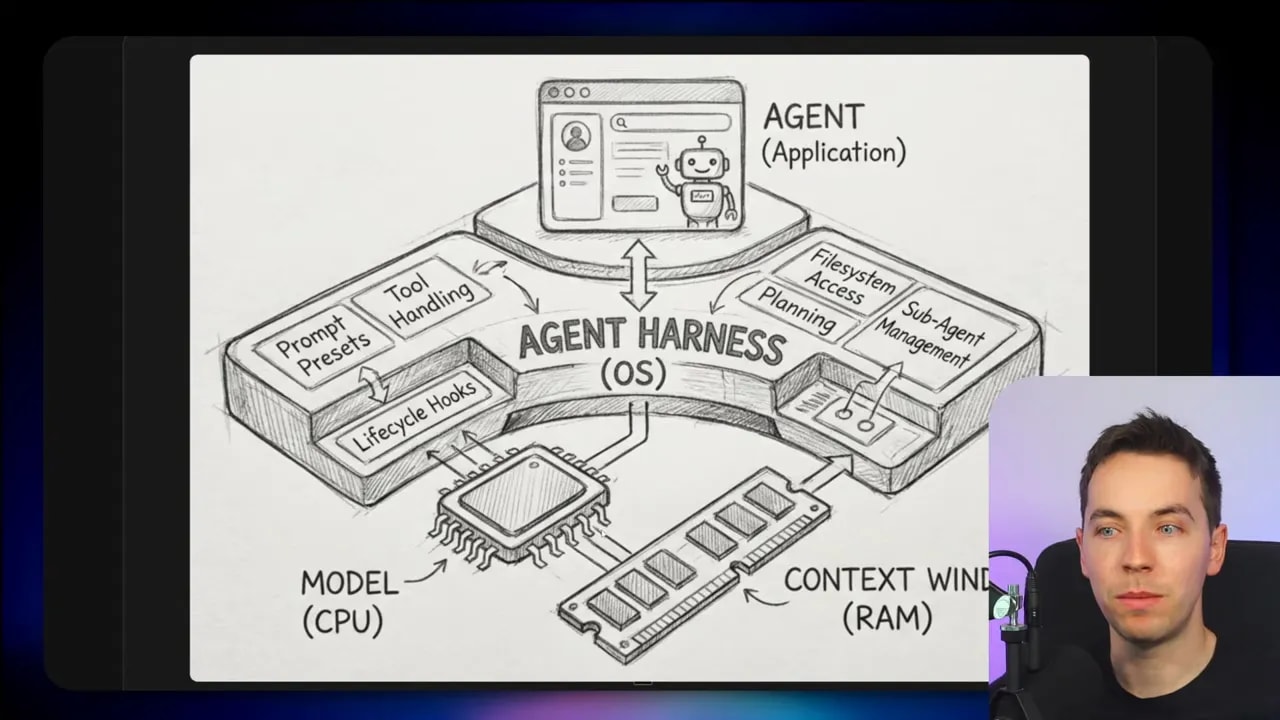
Why “agent harness” feels vague
The term has become broad because it can refer to many different parts of an AI system. That is why I find Brigette Berkler’s mental model especially helpful. She splits the harness into two layers:
- The inner harness
- The outer harness
That distinction clears up a lot of confusion very quickly.
The inner harness: what ships inside the coding agent
The inner harness is everything that comes built into your coding agent already.
If you’re using tools like Claude Code, Cursor, or Codex, they don’t just expose a raw model. They ship with a lot of extra structure around that model. That structure often includes:
- Sub-agent handling
- Sandboxed code execution
- Built-in tools
- Skills or task patterns
- Hooks
- Permission controls
- Workspace management
That built-in functionality is already powerful. It is one reason modern coding agents feel dramatically more capable than a plain chatbot with a code prompt.
Still, the inner harness only gets you so far.
If your goal is to let coding agents work with less supervision, then the real challenge is confidence. You need ways to trust the result enough that a human doesn’t have to check every tiny step manually.
There are several common attempts to improve this:
- Provide better repository context
- Improve prompting
- Use metaprompting frameworks like Superpowers, GSD, or BMAD
Those approaches help. They can make the first attempt much better. But they are rarely enough on their own.
A stronger prompt doesn’t solve the core operational problem of autonomous work. It doesn’t reliably reset context. It doesn’t manage retries cleanly. It doesn’t enforce deterministic validation. It doesn’t coordinate many concurrent sessions.
That is where the outer harness starts to matter.
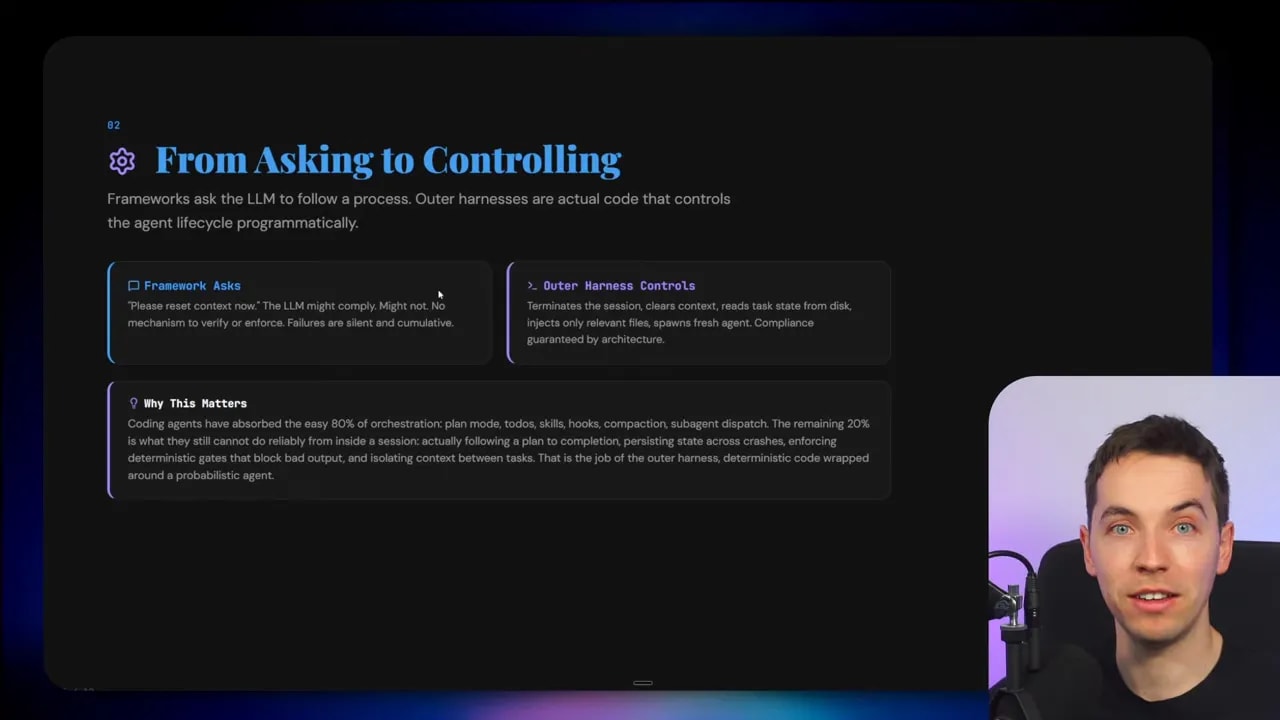
The outer harness: code that controls the agent lifecycle
The outer harness is actual code you write around the coding agent to manage its behavior programmatically.
This is a huge shift in mindset.
Instead of asking the agent to manage itself through clever prompt instructions, you move critical control into software. The system stops hoping the agent behaves properly and starts enforcing useful behavior from the outside.
For example, imagine you want an agent to reset context after a certain point and continue from saved task state.
A prompt-based approach might say something like:
Please clear your context and resume using the summary below.
An outer harness approach does this deterministically:
- Terminate the current session
- Clear context
- Read task state from disk
- Inject the relevant files and instructions
- Start a fresh session from that state
That difference is massive.
Once you start handling the lifecycle in code, you can build systems that are much easier to reason about. You can track state explicitly. You can restart jobs safely. You can add validation at every stage. You can turn an agent from a clever demo into a process.
Projects like Ralph loops, Gastown, and Archon all fit this broad pattern. They act as outer harnesses in different ways.
The cybernetic governor idea
One of the most useful descriptions from the harness engineering literature is that the harness acts like a cybernetic governor. In simple terms, it regulates the codebase or task flow using both guidance and feedback.
That means two things need to exist:
- Feedforward guidance that helps the agent make a better first attempt
- Feedback mechanisms that measure the output and push corrections back into the loop
This is where the distinction between guides and sensors becomes really useful.
Guides: anything that improves the first attempt
Guides are all the things that steer the agent before or during execution so its initial attempt is more likely to be useful.
Typical guides include:
- Project instructions in an agents.md file
- Skills and playbooks
- Examples of preferred patterns
- Repository context
- Task-specific instructions
- Architectural rules
These are important because they reduce pointless errors and make the output more aligned with how you want the system to behave.
But guides are not enough. Even a well-informed agent will still make mistakes. It may produce code that compiles but breaks your standards. It may ignore subtle constraints. It may pass one check and fail another.
So the system needs a way to inspect what the agent produced and feed that information back into the next iteration.
Sensors: the feedback loop that actually makes autonomy work
Sensors are the checks that evaluate an agent’s output.
This is one of the most important ideas in reliable AI systems. If you don’t have sensors, you don’t really have a dependable autonomous process. You just have a model generating output and hoping for the best.
There are two broad categories of sensors.
1. Deterministic sensors
These are computational checks that do not rely on AI at all. They are rule-based, repeatable, and machine-verifiable.
Examples include:
- Linters
- Type checks
- Schema validation
- Unit tests
- Formatting checks
- Static analysis
If the agent writes code, you can run these checks automatically and feed the results back into the loop.
I think one of the strongest points in the harness engineering framing is that these computational checks are heavily underused by AI builders. People often jump straight to prompts and model choice, while ignoring the fact that some of the best reliability gains come from plain deterministic software checks.
That makes sense when you think about it. If your issue is something a machine can verify directly, then you should use a direct check. Don’t ask another model to guess whether a schema is valid when a parser can tell you for sure.

2. Inferential sensors
Some outputs can’t be verified cleanly with strict computational rules. That is where inferential sensors come in.
These use AI to evaluate AI.
A common pattern is LLM as a judge. One model generates an output, then another model reviews it against a set of criteria. Ideally, you use a different model or at least a separate review pass. The judgment then gets fed back into the main agent loop.
Examples might include:
- Checking whether code follows architectural intent
- Reviewing whether a document summary missed key clauses
- Assessing whether a research answer is well-supported
- Evaluating whether an implementation actually addressed the ticket
Inferential sensors are useful because many real tasks involve quality, judgment, and interpretation rather than just syntax.
Still, I wouldn’t treat them as a replacement for deterministic checks. The strongest systems use both. Let the machine verify what it can verify directly, and use AI review for the parts that need judgment.
Humans still matter, but in different places
As systems become more autonomous, the human role doesn’t disappear. It changes shape.
Instead of micromanaging every coding session, the human helps design and improve the outer harness. That means choosing the right guides, building the right sensors, deciding the escalation points, and placing review at the moments that matter most.
This is a much better use of human attention.
If a person has to sit in front of every agent session and constantly steer it, then the system won’t scale. The human becomes the bottleneck again. But if the person only steps in for ambiguity, approval, or exception handling, the whole setup works far better.
A simple outer harness example: the Ralph loop
A Ralph loop is a simple but useful example of an outer harness pattern.
The idea is straightforward. You run an external loop that keeps spawning fresh agent sessions again and again until a target condition is met. That target could be passing checks, satisfying review criteria, or getting approval from human reviewers.
What matters here is that the loop is external to the agent. The harness controls retries and iteration. The agent doesn’t have to be trusted to manage that process itself.
That gives you brute-force persistence in a structured way.
OpenAI described an approach where the agent runs in a loop until human reviewers are satisfied. That is a basic outer harness. Many other systems start there and then add richer controls, better state tracking, more checks, and parallel execution.
Archon, Gastown, and the move from thin loops to full harnesses
There is a spectrum here.
At one end, you have a thin orchestrator that simply keeps rerunning sessions until something passes. At the other end, you have full harness systems that enforce deterministic workflows, coordinate subtasks, run tasks in parallel, and add multiple review layers.
Tools like Archon sit further along that spectrum. They let you build your own outer harnesses and enforce a more deterministic structure around agent behavior. They often include ready-made workflows and can support parallel task execution.
Gastown is another useful example because it takes the idea of the Ralph loop and multiplies it. Instead of one loop, you can have many running in parallel with orchestration around them.
That gets powerful very quickly. It can also get chaotic very quickly.
And that leads to the next layer.

The third layer: orchestration and scheduling
Once you have agents with inner harnesses and outer harnesses, you may find yourself building yet another layer above them. This is the orchestrator or scheduler layer.
This layer doesn’t just manage one agent session. It manages many tasks, many agents, and the flow of work across the whole system.
That is where Symphony fits.
OpenAI positions Symphony as a higher-level multi-agent orchestration system. It sits above individual coding agent sessions and coordinates work across a task board.
By the time you reach this layer, you’re no longer asking “how should this prompt be phrased?” You’re asking things like:
- Which open tasks should trigger agents?
- How do I isolate workspaces?
- How do I stop agents from colliding with each other?
- How do I map task states to agent states?
- Where should human approval happen?
- How do I keep many autonomous sessions running cleanly in parallel?
That is orchestration.
These are mental models, not hard boundaries. The lines blur. Some frameworks include parts of several layers at once. But the distinction is still useful because it helps you diagnose where your actual bottleneck is.
Why parallel agents get hard so quickly
As soon as you try to run many agents at once, two problems show up almost immediately.
1. Agents clash with each other
If multiple agents work across the same project, they can overlap, duplicate work, break assumptions, or interfere with the same files. Parallelism sounds great until two sessions try to move the same part of the codebase in different directions.
That is why isolation, task boundaries, and orchestration rules matter so much. You can’t just start more sessions and hope coordination emerges by itself.
2. Human-in-the-loop design becomes critical
You do still need people involved. But they need to be inserted into the right parts of the process.
If humans are forced into every step, the whole system stalls. If humans are removed from every step, quality and trust collapse. The real challenge is choosing the points where human attention adds the most value.
That might mean:
- Approving task definitions
- Reviewing risky code changes
- Resolving ambiguous requirements
- Approving final merges
- Tuning the harness after repeated failures
Good orchestration is partly a technical problem and partly an interface problem. The system has to make it easy for humans to intervene at the right level without forcing them into constant supervision.
Why Linear is such a smart interface choice
One of the cleverest aspects of Symphony is the choice of Linear as the human interface.
Instead of inventing some exotic control panel for autonomous agents, OpenAI uses something teams already understand: a ticketing system.
That means the task board becomes the shared language between humans and agents.
People define work as tickets. Symphony picks up those tickets. Agents operate against those tasks. Status lives in the board. Humans check progress in a familiar place.
This choice matters because it lowers friction. It also creates a clean abstraction. The human doesn’t need to manage the raw session lifecycle. The human manages the work itself.
Applying the same mental model outside coding agents
Although the examples here focus on coding agents, the same architecture applies more broadly to agentic systems in general.
I use this inner harness, outer harness, and orchestrator framing for AI applications well beyond software development.
Take a contract review system as one example. The inner harness might be the core agent capabilities: reading documents, extracting clauses, generating summaries, and calling tools. The outer harness would add deterministic process around that, such as:
- Required workflow steps
- Document validation checks
- Schema-based extraction requirements
- AI review passes for quality control
- Escalation to a human reviewer for high-risk findings
That is still harness engineering. It’s the same basic idea, just applied to a different domain.
The same goes for research systems. A deep research harness may be much more open-ended and agentic than a contract review harness. But it can still have deterministic scaffolding around it, such as citation checks or multiple layers of review before results reach a human.
Deterministic versus probabilistic harnesses
Another helpful way to think about harnesses is as a spectrum.
Some harnesses are very deterministic. They follow a strict workflow with explicit stages and machine-checkable outputs. A contract review flow often fits this shape.
Other harnesses are more probabilistic. They are broader, more open-ended, and more agentic throughout. Deep research systems often look like this.
Neither style is automatically better.
The right choice depends on the task:
- If the task has clear stages, fixed rules, and structured outputs, lean more deterministic
- If the task involves exploration, synthesis, or ambiguity, allow more probabilistic behavior
Even the most open-ended system can still benefit from deterministic checks around the edges. That is a key point. You don’t need to choose between creativity and structure. Good systems combine both in the right proportions.
What this means for AI builders right now
I think one of the biggest mistakes people make is putting too much emphasis on the model and not enough emphasis on the surrounding system.
A stronger model helps. Better prompts help. But once you try to run autonomous agents in production, the real engineering work shifts into scaffolding.
That means spending more time on things like:
- Task decomposition
- Session management
- Context injection
- State persistence
- Validation loops
- Retry logic
- Human review placement
- Parallel orchestration
In other words, the future of AI engineering looks less like chatting with a model and more like building a controlled environment around one.
Symphony is a useful case study because it makes that shift visible. It shows what happens when a team stops treating coding agents as assistants and starts treating them as workers inside a larger operating system.
How I would think about building from the Symphony spec
If I were using Symphony as a starting point for my own system, I wouldn’t treat it as a finished product I need to copy exactly. I’d treat it as an architecture pattern.
The key ideas I’d carry forward are:
- Use a task system as the human control surface
- Map each task to an isolated agent workspace
- Keep agent lifecycle management outside the prompt
- Add deterministic sensors before adding more AI judges
- Insert human review at high-value checkpoints instead of every step
- Think in layers: model, harness, orchestrator
That layered thinking is what keeps these systems understandable as they grow.
If you’re struggling with autonomous coding agents today, there is a good chance the problem isn’t that the model is too weak. It may be that the outer harness is too thin or the orchestration layer is missing entirely.
That is the real message behind OpenAI open-sourcing Symphony. Yes, the spec itself is interesting. Yes, the Linear-to-agent workflow is useful. But the deeper value is the architecture pattern it points to.
The model is the engine. The harness is the control system. The orchestrator is the layer that turns many agents and many tasks into an actual operating process.
That is where reliable AI systems start to take shape.
