

Three of the biggest names in AI all made moves in the agent space within a single week. Anthropic launched Claude Managed Agents. LangChain answered with Deep Agents Deploy. Then OpenAI shipped the next evolution of its Agents SDK.
At first glance, these looked like three separate announcements. They weren’t. They were three different answers to the same underlying problem: how do you actually build and ship AI agents in production without getting buried in infrastructure, memory, sandboxes, orchestration, and vendor lock-in?
That’s the part that matters.
If you’re building AI systems right now, your biggest decision isn’t just which model to use. It’s which agent building approach you choose. That decision affects your memory layer, your infrastructure, your deployment model, your compliance posture, and how painful it will be to change course later.
I think a lot of people felt some confusion around these launches because they were marketed in different ways, but there’s a clear structure underneath all of them. Once you see that structure, the whole landscape becomes easier to reason about.
I break it down into five tiers on a build-to-buy spectrum. On one end, you write everything yourself and keep full control. On the other, you configure an agent inside somebody else’s SaaS product and get maximum convenience. The three announcements from Anthropic, LangChain, and OpenAI sit at different points along that spectrum, and that’s exactly why comparing them loosely can be misleading.
The real issue isn’t model choice. It’s where you give up control.
There are hundreds of agent platforms and frameworks available now. That sounds like abundance, but it creates a serious architecture problem. If you pick the wrong layer too early, you can spend the next 18 months fighting your own stack.
Most teams focus first on prompts, tools, and model performance. Those matter, of course. But the harder problem usually appears later. Where is memory stored? Who owns the runtime? How are sandboxes provisioned? Who controls the harness? Can you switch models later? Can you self-host? Can you meet privacy and compliance requirements?
Those questions start as technical details and end up becoming business constraints.
That’s why the recent launches are worth paying attention to. They’re signals of how the major players think this market will develop.
Anthropic’s Claude Managed Agents is really an infrastructure play
Let’s start with Claude Managed Agents, because that announcement triggered most of the discussion.
Anthropic presented it as a fully cloud-hosted agent platform. In simple terms, the pitch is this: instead of building your own runtime, sandboxing, orchestration, session management, and execution environment, you let Anthropic handle all of it.
Anthropic charges 8 US cents per session hour for active runtime. In return, it gives you the “brain” and the “hands.”
That brain-versus-hands framing is useful.
- The brain is the model plus the harness. The harness is the actual agent loop that decides what to do next.
- The hands are the execution environments. That means sandboxes, code execution, tool calling, MCP integrations, and the runtime needed to take action.
Claude Managed Agents also includes session management and orchestration around all of that. So the idea is straightforward. Anthropic runs the infrastructure, handles scaling, and abstracts away the ugly production work that usually sits around agent systems.
That part is genuinely useful.
If you’ve ever tried to ship an AI agent into production, you know the hard bits don’t stop at calling a model API. You need safe code execution. You need credential management. You need permission boundaries around tools. You need tracing. You need a way to manage long-running sessions without building a fragile pile of glue code around them.
Claude Managed Agents tries to solve exactly that.
What Claude Managed Agents actually shipped
Once you strip away the launch framing, the product that actually shipped is more modest than many people expected.
The basic building blocks are there:
- System prompts
- Tools and MCPs
- Agent skills
- Session tracking and conversation history
- Separate environments for execution
- Installed libraries inside those environments
- Credential vaults that keep access tokens away from the sandbox and the model
That’s a solid foundation for a hosted agent system. But a lot of the most interesting capabilities were not generally available.
Features like:
- Outcome-based tasks
- Multi-agent orchestration
- Stateful memory
- Evaluator agents that self-check and iterate
Those were held back in limited research preview. So while the announcement sounded like a leap forward in managed agents, the product available to most builders felt more like an early hosted agent builder with some promising parts still behind the curtain.
Why the launch landed with both interest and confusion
I think the confusion came from two places.
First, Anthropic has been shipping new products and features at a very fast pace. There’s overlap across the portfolio, and if you aren’t carefully separating them in your head, it’s easy to wonder how Claude Managed Agents differs from existing options.
For example:
- The Messages API lets you call Claude directly and run your own loop.
- The client SDKs make those direct integrations easier in different languages.
- The Claude Agent SDK gives you more harness-level behavior inside a library.
- Claude Managed Agents moves past the library layer and hosts the infrastructure for you.
That’s a meaningful distinction, but it isn’t always obvious from product names alone.
Second, Anthropic talked about managed agents as a kind of meta-harness. The argument is that harnesses can’t stay fixed forever because they need to keep pace with model capability. If Anthropic controls the managed harness, Anthropic can keep adapting it as Claude evolves.
That’s an interesting idea. It could be a genuine advantage if the provider keeps improving the runtime faster than most teams could on their own.
But there’s a trade-off, and it’s a big one.
By using Claude Managed Agents, you are ceding control of the harness and much of the infrastructure to Anthropic. Depending on your use case, that may be completely fine. Or it may be unacceptable.
The lock-in question with Anthropic
Claude Managed Agents is tightly tied to Anthropic. That’s the point, really. Anthropic hosts the infrastructure and Anthropic controls the runtime behavior.
If your main goal is speed, and your use case can live inside Anthropic’s environment, that may be worth it.
If you need model choice, self-hosting, stricter compliance controls, or the freedom to move your harness elsewhere later, it becomes harder to justify.
That’s also why this announcement quietly puts Anthropic in competition with cloud providers like Google Cloud Vertex AI Agent Builder and AWS Bedrock AgentCore. Those platforms also help teams deploy, manage, and scale agent systems in production. The difference is that cloud providers usually give you more freedom across models and frameworks.
So the brain-versus-hands separation isn’t new. Anthropic just packaged it in a sharper, model-specific form.
LangChain’s Deep Agents Deploy is “open,” but that word needs context
The day after Anthropic’s launch, LangChain responded with Deep Agents Deploy, explicitly framed as an open alternative to cloud-managed agents.
That positioning was smart because it hit the exact weakness in Anthropic’s approach: lock-in.
LangChain’s argument was that the deepest lock-in in agent systems isn’t always the model. It’s the memory and runtime behavior that build up inside a closed harness. Once your agent’s state, traces, orchestration logic, and execution history live inside someone else’s managed platform, leaving becomes painful.
That’s a real point.
To understand Deep Agents Deploy, you first need to understand Deep Agents itself. Deep Agents is LangChain’s MIT-licensed agent harness built on top of LangChain and LangGraph. It’s meant for more advanced agent use cases such as:
- Long-running tasks
- Multi-step workflows
- Large context handling
- Code execution inside sandboxes
- Persistent stateful memory
- Human-in-the-loop flows
That’s the harness layer. Then comes the hard production question: where do you deploy it, and how do you scale it?
That’s the problem Deep Agents Deploy tries to solve.
What Deep Agents Deploy is actually doing
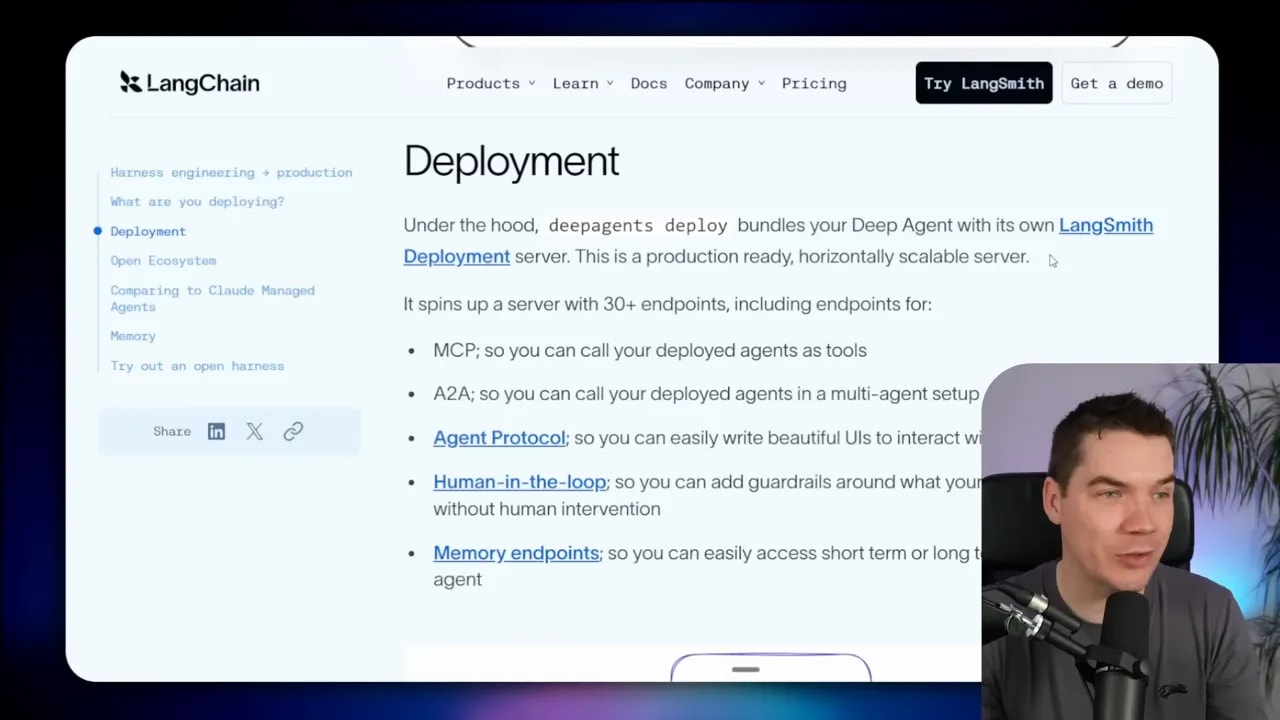
At a practical level, Deep Agents Deploy packages your agent and spins up a deployment server around it. That server exposes more than 30 endpoints so other systems can communicate with the agent. It uses standard protocols like A2A and MCP. It also supports files like agents.md, which help define agent behavior and capabilities.
You still need safe execution environments for code and tools. For that, LangChain allows different sandbox providers such as:
- Daytona
- Modal
- Runloop
- A beta option on LangSmith infrastructure
That gives you more flexibility than Anthropic’s managed approach. You can choose your model. You can choose your sandbox provider. You control the harness because you are deploying the harness.
Those are meaningful benefits.
Why “open” is a little more nuanced than it sounds
This is where the story gets more complicated.
LangChain was careful to say “open alternative,” not “fully open source deployment stack.” That wording matters. To use Deep Agents Deploy in practice, you need to package your Deep Agent with a LangSmith deployment server. LangSmith is a SaaS product run by LangChain. It is not open source.
So yes, the harness itself has open-source roots. But the deployment path being promoted sits inside LangChain’s own commercial platform.
That means the openness is partial. It is more open than Claude Managed Agents in key ways, especially around model choice and harness control. But it is not pure freedom all the way down.
There’s also the commercial catch. You need a paid LangSmith Plus plan or above, which costs $39 per seat per month. And self-hosting is restricted to the enterprise plan.
That creates an awkward irony.
LangChain positioned cloud-managed agents as a walled garden with serious lock-in. Yet if you want the deployment workflow they’re offering for Deep Agents, you still need to join LangChain’s own SaaS ecosystem.
That doesn’t make Deep Agents Deploy bad. It just means the “open” framing should be read carefully. This is a more flexible deployment option, not a lock-in-free utopia.
OpenAI’s new Agents SDK takes a different swing
Then OpenAI entered the conversation with the next evolution of its Agents SDK.
OpenAI’s move is interesting because it did not launch a direct equivalent to Claude Managed Agents. It didn’t present a fully hosted managed agent platform. Instead, it improved the library layer by baking more harness behavior into the SDK itself.
That matters because it places OpenAI in a different part of the stack.
According to OpenAI’s framing, the earlier version of the Agents SDK was more suited to chatbot-style flows that might involve five, six, or seven steps. That’s a very different class of problem from the long-running, tool-heavy, looping agents that many teams are trying to build now.
The updated Agents SDK aims to close that gap.
It can handle capabilities such as:
- Inspecting files
- Running commands
- Editing code
- Long-horizon tasks
- Controlled sandbox execution
- Memory handling
- Workspace mounts
In other words, OpenAI is moving more harness-like features into the SDK, while still leaving hosting and deployment in your hands.
OpenAI’s critique of both rivals
OpenAI took a fairly diplomatic approach in its announcement, but the competitive positioning was obvious.
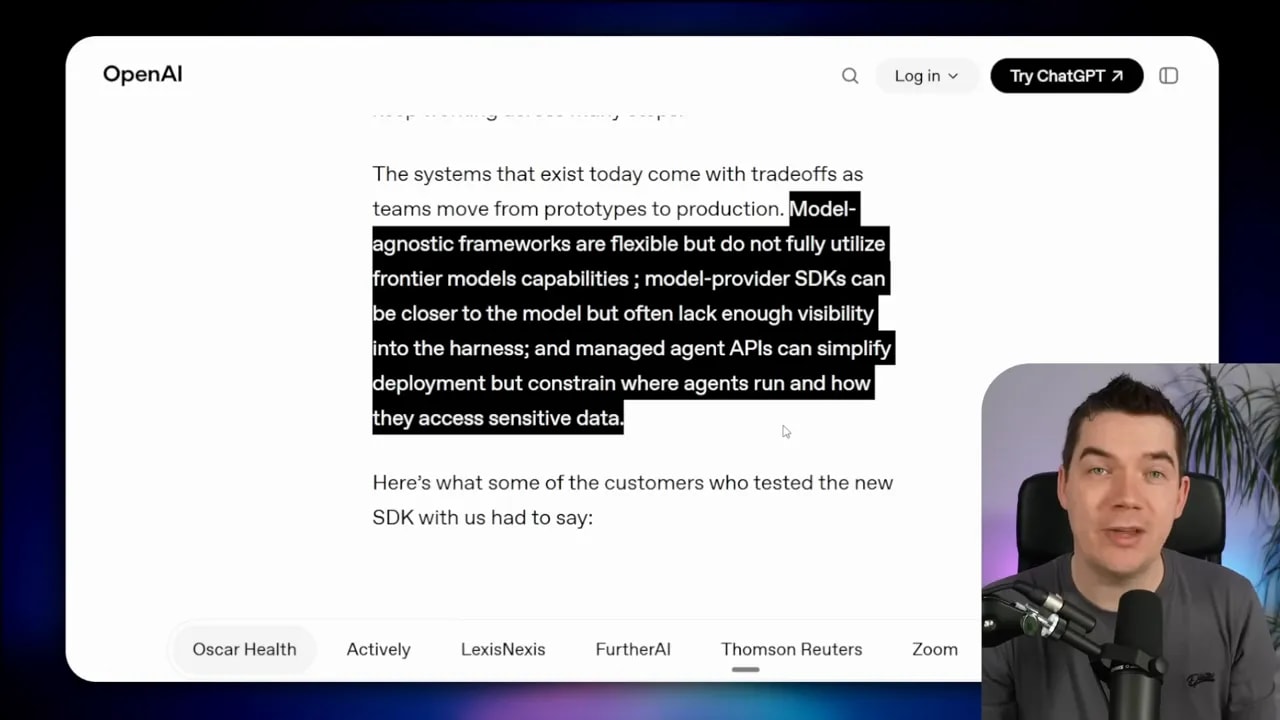
Against managed agent APIs like Anthropic’s, OpenAI pointed out that hosted platforms can restrict where agents run and how they access sensitive data. That’s a polite way of saying managed platforms can become too constraining.
Against model-agnostic frameworks like LangChain, OpenAI argued that flexibility can come at the cost of fully using frontier model capabilities. That’s another fair point. General-purpose frameworks often lag behind model-specific features or fail to exploit them fully.
So OpenAI’s pitch is this: use a more capable SDK, get better harness behavior, and stay closer to model capabilities without handing over your entire runtime to a managed platform.
That makes the OpenAI approach feel closer to LangChain than Anthropic, but with a stronger model-native emphasis.
How open is OpenAI’s approach?
OpenAI’s Agents SDK is open source, and there’s no extra platform fee on top of standard model usage and whatever sandbox provider you choose. The SDK supports similar sandbox providers to what LangChain uses, including Daytona, E2B, and Modal.
There’s also a similar separation of concerns. You can keep things like a secrets vault separate from the harness and separate from the sandbox.
Although the SDK is obviously primed for OpenAI models, it still sits in a more open category than a managed runtime like Claude Managed Agents because you host it yourself.
That distinction is the key one.
The five-tier build-to-buy spectrum for AI agents
Once you zoom out from the weekly announcements, a much clearer picture appears.
I find it useful to sort the entire agent platform landscape into five tiers. These tiers run across a build-to-buy spectrum:
- Tier 1: maximum control
- Tier 2: frameworks and SDKs
- Tier 3: managed infrastructure
- Tier 4: visual low-code platforms
- Tier 5: embedded SaaS agents
As you move from left to right, you usually gain speed and convenience but lose flexibility and portability.
That trade-off sits underneath almost every architecture decision in this space.

Tier 1: Vanilla code and direct model APIs
This is the most hands-on option. You build your agent in custom code and call models directly through APIs.
Examples include:
- Anthropic Messages API
- Google Gemini API
- OpenAI API platform
You can also use each provider’s language SDKs to make integration easier. Anthropic has client SDKs. Google has its GenAI SDK. OpenAI has Python and JavaScript libraries.
At this tier, you get access to the core model features:
- Chat completions
- Streaming
- Function calling
- Multimodal inputs and outputs
But the full agent loop is yours to build and run.
You decide how memory works. You decide how tools are called. You decide how retries, guardrails, tracing, orchestration, and state management are handled.
This gives you maximum flexibility. It also gives you the most work.
Tier 2: Agent frameworks and agent SDKs
Tier 2 adds a harness layer. Instead of building every part of the loop yourself, you use a framework or SDK that handles much of the agentic behavior.
This includes things like:
- Tool dispatching
- Handoffs
- Guardrails
- Multi-agent patterns
- State handling
- Longer-running loops
Examples here include:
- Claude Agent SDK
- OpenAI Agents SDK
- Google Agent Development Kit
- LangGraph
- Deep Agents
- CrewAI
- PydanticAI
This tier is a sweet spot for many teams. You still host the code and infrastructure yourself, but you avoid writing every low-level piece from scratch.
Even inside this category, there are different philosophies.
CrewAI, for example, emphasizes being independent and written from scratch rather than layered on top of another framework. That speaks to a common frustration in AI tooling: too much abstraction often creates bloat.
PydanticAI takes a leaner approach and gives you a lighter framework to build on.
The farther you move into abstraction, the more careful you need to be. Convenience can save time early. It can also create friction later if the framework hides too much or becomes hard to adapt.
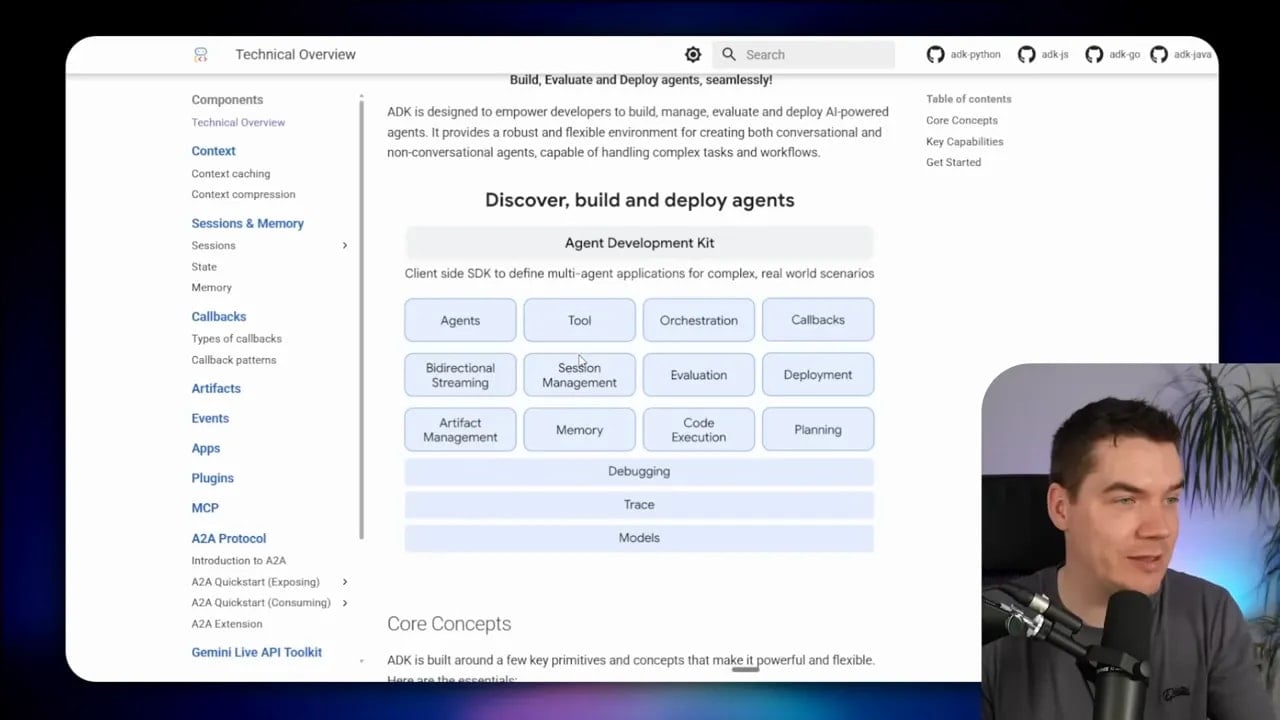
Tier 3: Managed infrastructure and deployment platforms
This is where the recent announcements from Anthropic and LangChain largely sit.
Tier 3 is about production infrastructure wrapped around agents. Instead of only giving you a harness library, these platforms handle more of the runtime burden. That may include:
- Containers and sandboxes
- Tool execution environments
- Permissions and credential boundaries
- Tracing
- Session orchestration
- Scalability
Examples include:
- Claude Managed Agents
- Google Vertex AI Agent Builder
- Azure Foundry Agent Service
- AWS Bedrock AgentCore
- Deep Agents Deploy through LangSmith
- E2B, Modal, and Daytona for sandbox infrastructure
This tier exists because real production agent systems need more than prompts and tools. They need runtime discipline.
The benefit here is obvious. You offload painful infrastructure work. You get to production faster. You avoid building sandboxes, orchestration layers, and tracing stacks from nothing.
The cost is just as obvious. You give up some control. In some cases, you give up a lot.
Claude Managed Agents is the strongest example of that trade-off. It’s highly convenient, but tightly constrained. LangChain’s approach is more flexible, but still tied to LangSmith in practice.
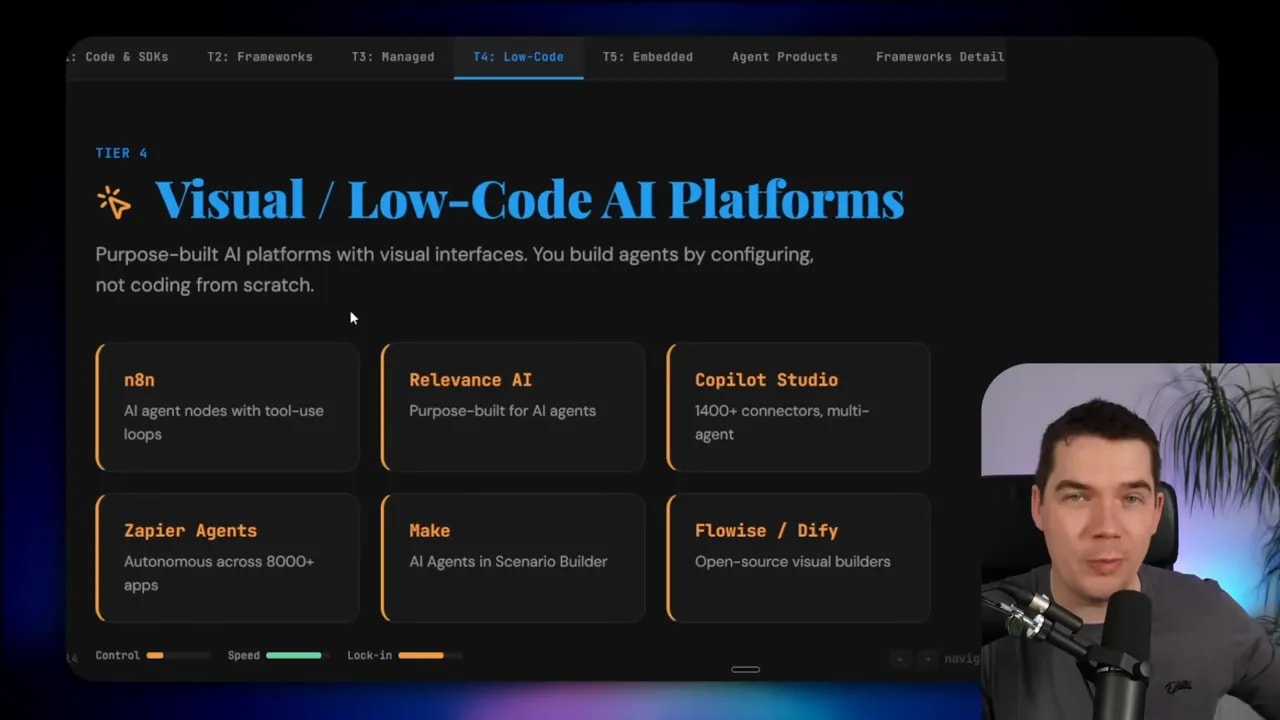
Tier 4: Visual low-code AI platforms
Tier 4 shifts from coding agents to configuring them.
These are visual platforms that let you assemble AI systems with flows, nodes, and interfaces rather than handwritten application logic. They often work well for teams that need speed and don’t require deep custom engineering.
Examples include:
- n8n
- Relevance AI
- Copilot Studio
- Zapier Agents
- Make.com
- Flowise
- Dify
These tools can produce useful and surprisingly capable agent systems. They’re less flexible than code-first approaches, but much faster to deploy for many use cases.
Because they are hosted platforms, you usually don’t need to separately think through deployment infrastructure in the same way you would at Tier 1 or Tier 2.
Tier 5: Embedded SaaS agents
This is the far end of convenience.
Instead of building your own agent stack, you use agents built into software platforms you already rely on. These are task-specific, product-embedded agents, often aimed at internal business workflows or customer support use cases.
Examples include:
- Salesforce Agentforce
- Intercom Fin
- HubSpot Breeze
- Atlassian Rovo
Research from Gartner suggests that 40% of enterprise applications will include task-specific agents by 2026. That direction makes sense. Many businesses don’t actually need a custom general-purpose agent platform. They need a useful agent inside the tools they already use.
This is the fastest route to value for a lot of companies. It is also the least flexible route.
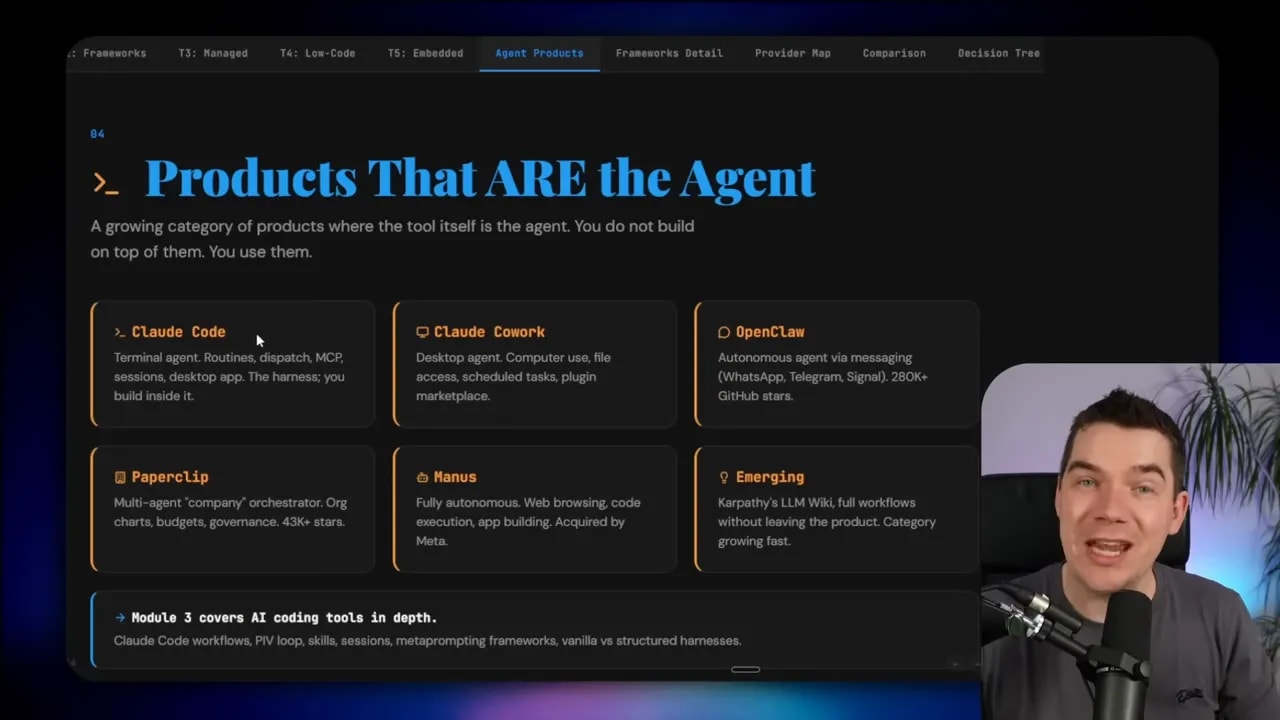
Some agent products sit outside the spectrum entirely
There’s one more distinction that helps clear up confusion in this space.
Not every AI agent product belongs on the build-to-buy spectrum above.
That five-tier model is for products and platforms you use to build or deploy your own agent systems.
But some products are themselves the agent. You don’t build on top of them. You use them directly.
Claude Code is a good example. It’s a terminal agent product with routines, dispatching, desktop and mobile access, and the ability to spin up containers in the cloud that can work with GitHub repositories. The harness is already there. The product is the agent.
OpenClaw is another example. It acts as an autonomous agent you communicate with directly, rather than a framework you build into your own application.
This distinction matters because it stops you from comparing unlike with unlike. A hosted agent product is not the same thing as an agent framework. A managed runtime is not the same thing as a low-code builder. An SDK is not the same thing as an embedded SaaS assistant.
How I’d choose between the tiers
There is no universally correct tier. There are only trade-offs.
If I need full control, I’d stay in Tier 1 or Tier 2. That gives me ownership of the codebase, the runtime, the memory architecture, and the deployment model.
If I need speed to market, I’d look harder at Tier 3, Tier 4, or Tier 5. That usually means accepting some lock-in in exchange for faster delivery.
If I need model choice, I’d avoid systems that tightly bind me to a single provider. That pushes me toward model-agnostic frameworks and more flexible infrastructure.
If I have strict privacy or compliance requirements, I’d strongly prefer self-hosting or a platform with clear data protections and deployment guarantees.
If my use case is long-running, tool-heavy, and stateful, I’d pay close attention to the harness itself. That’s where many agent systems fail. The quality of your harness affects whether the system behaves reliably over time.
And if my use case is actually just a narrow business workflow inside an existing tool, I might skip custom agent architecture completely and use an embedded SaaS agent instead.
What the Anthropic, LangChain, and OpenAI launches actually tell us
The interesting part of these launches isn’t simply that three companies shipped agent features in one week. It’s that each company exposed a different belief about where value sits in the stack.
Anthropic is betting that many teams want a managed runtime and are willing to hand off the harness to move faster.
LangChain is betting that teams still want control of the harness and memory, but need easier deployment into production.
OpenAI is betting that stronger SDK-level harness support can satisfy many advanced use cases without requiring a fully managed platform.
All three are responding to the same pain point. Building agents that work in demos is easy. Building agents that keep working in production is hard.
That is why this moment matters.
The stack is starting to separate more clearly into layers. Models are one layer. Harnesses are another. Sandboxes are another. Managed infrastructure is another. Visual builders and embedded SaaS agents sit further along the convenience side.
Once you understand those layers, the noise drops away. You can stop chasing whichever launch happened last week and start picking the right architecture for the system you actually need to build.
That’s the real decision here. It’s not Anthropic versus LangChain versus OpenAI in some abstract sense. It’s which layer do you want to own, and which layer are you willing to rent?
