

I created an automation that lets powerful cloud language models answer questions about private company documents without ever seeing real sensitive data. The cloud model only ever receives surrogate values. Real names, passport numbers, financials and other secrets stay inside my network. This article explains how I put that together, the challenges I ran into, and the practical trade-offs you should consider if you want to adopt a similar approach.
Why this matters
Large language models are useful for searching and summarizing internal documents. They can boost productivity. They also introduce real risk. Sensitive data leaking to a cloud provider could violate GDPR, HIPAA, PCI DSS and many internal policies. There are multiple leakage paths:
- Users might paste confidential texts directly into a chat.
- Agents can call internal APIs or databases that contain personal or financial data.
- Tooling can concatenate multiple content sources and inadvertently expose secrets.
Legal safeguards like data processing agreements help. They are not enough on their own. I added a technical safeguard that prevents sensitive information from leaving my perimeter in the first place. That reduces the blast radius of operational errors or malicious prompt injections.
How I demonstrated the idea
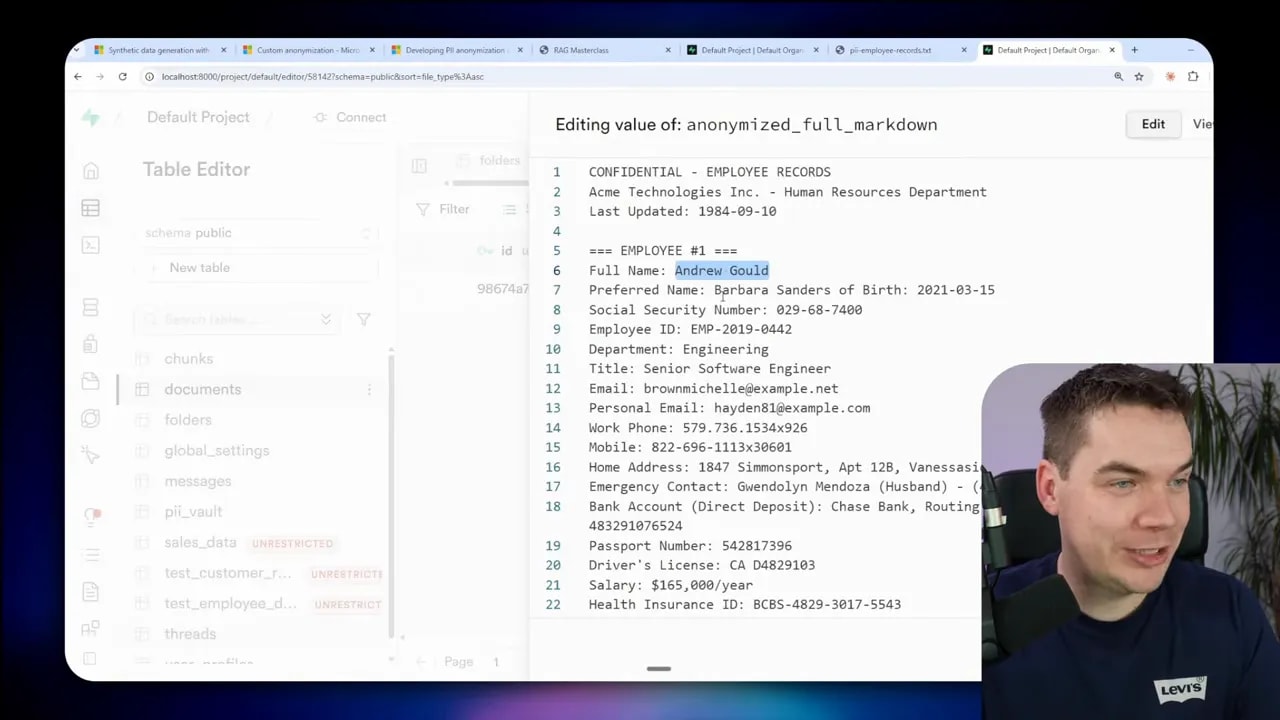
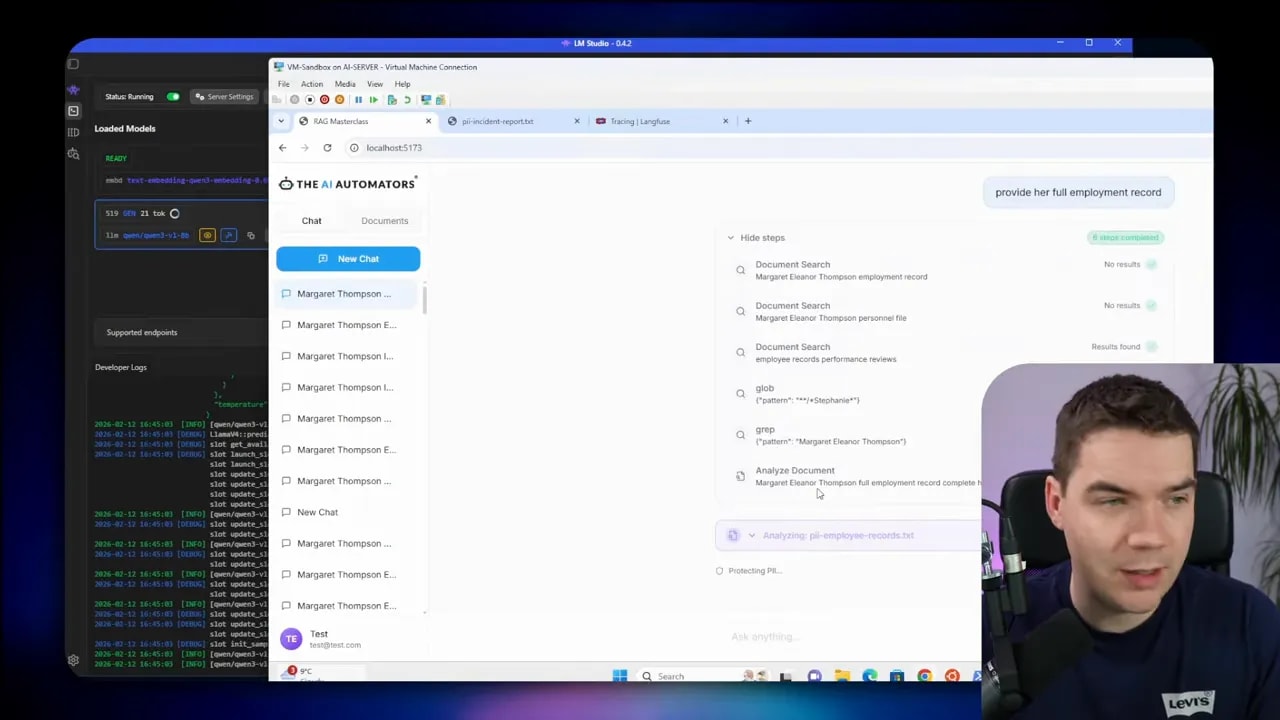
I built an app where a user asks a question and a cloud LLM (Claude Haiku in my case) answers. The trick is that the cloud LLM never sees real names or numbers. I replace them with surrogates, run the LLM on the anonymized data, then re-insert the original values for the user-facing output.

When I asked about a staff member in the chat, the system showed an answer as if the model had full access to the records. It didn’t. The cloud LLM was working with surrogate names. I kept the mapping in a secure registry so the application could restore the real values before rendering the final response.
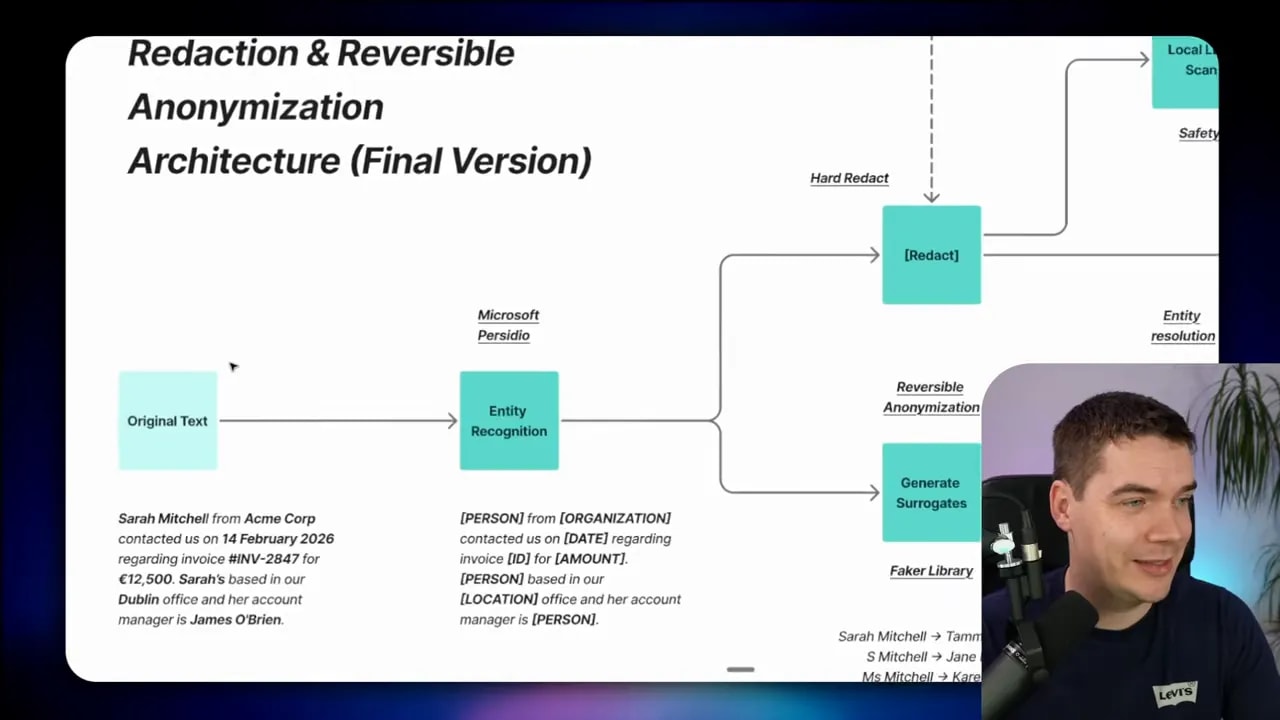
Two distinct strategies: hard redaction and reversible anonymization
There are two useful patterns for removing sensitive content.
- Hard redaction: permanently remove content so it can never be restored. Think of credit card numbers or cryptographic keys. These must not reappear downstream.
- Reversible anonymization: replace the original with a surrogate. Keep a mapping so you can re-identify the entity later. This is useful for names, addresses and many kinds of PII when you need coherent LLM responses.

Hard redaction is irreversible by design. Use it for truly sensitive identifiers. Reversible anonymization keeps context and lets the model reason over natural sentences. For example, replacing “Sarah Mitchell from Acme Corp” with “Person_1 from Company_3” yields better model outputs when those placeholders are swapped for realistic fakes created by a faker library.
When to choose which
- Use hard redaction for tokens that must never reappear: card numbers, cryptographic keys, social security numbers.
- Use reversible anonymization for things that benefit from context: names, emails, locations and sometimes dates.
- If an item is both sensitive and needed for calculations (like invoice totals), don’t send it to the cloud. Either compute locally or design the system to run those calculations before anonymization.
Detecting sensitive data: layered detection model
There is no single bullet for detection. I combined multiple techniques so they reinforce each other.
- Pattern matching (regex): great for structured identifiers—emails, IP addresses, phone numbers, credit card numbers with checksums.
- Named entity recognition (NER): models that spot person names, organizations and locations from unstructured text.
- Context enhancement: a rule layer that looks at surrounding tokens to raise confidence. For example, text that appears after “SSN” is more likely an identifier.
- Local LLM safety net: for edge cases and obfuscated PII, a small local model can reason about ambiguous fragments, boosting recall.
Microsoft Presidio is an open-source framework I used for the bulk of the detection. It implements many of these detection strategies, but it doesn’t provide a vault or mapping layer, so I added that around Presidio.
High-level flow I implemented
My system follows a clear path whenever a user asks a question or a tool is invoked. These are the core steps:
- Receive user input.
- Run entity detection with Presidio and pattern rules.
- Decide which entities to hard redact and which to anonymize.
- Generate surrogates for anonymized entities using the Faker library.
- Resolve entities across the text so references to the same person map to the same surrogate.
- Persist mappings in a secure registry (the PII vault).
- Send the anonymized content to the cloud LLM.
- When the cloud LLM responds, ensure it prints surrogate forms exactly so I can re-identify them and swap back the originals.
- Render the de-anonymized response to the user in the UI.
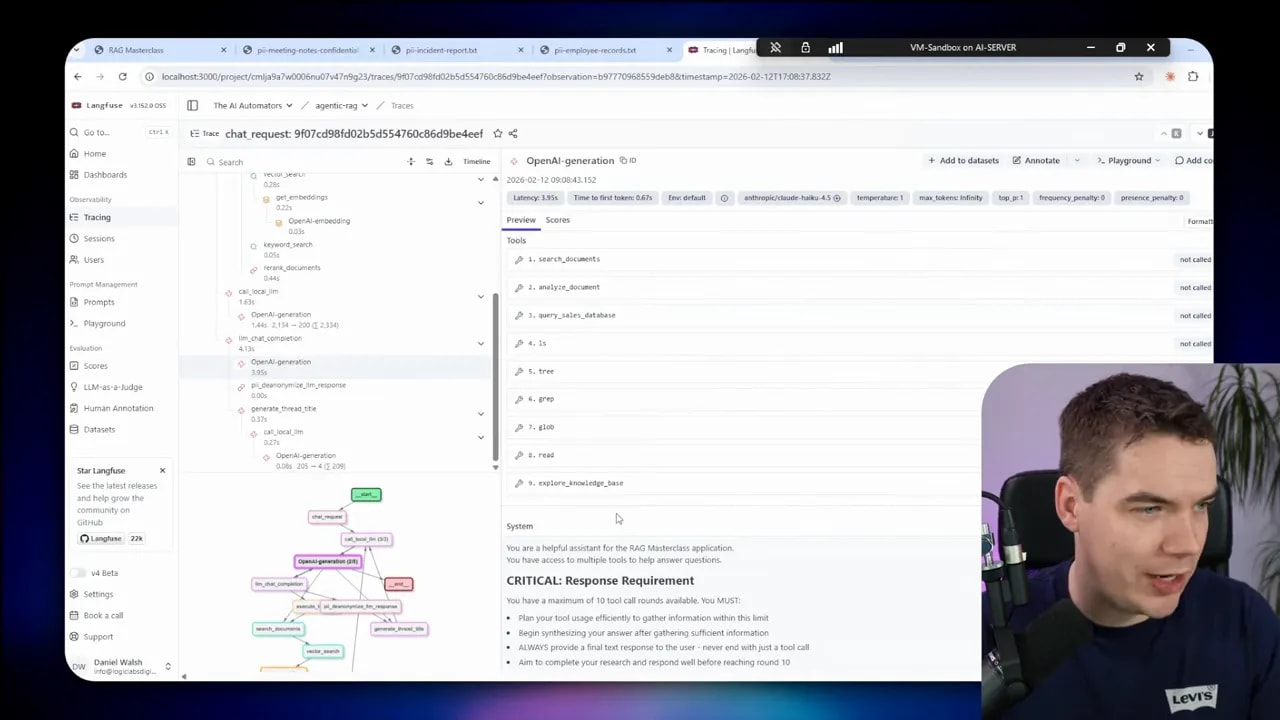
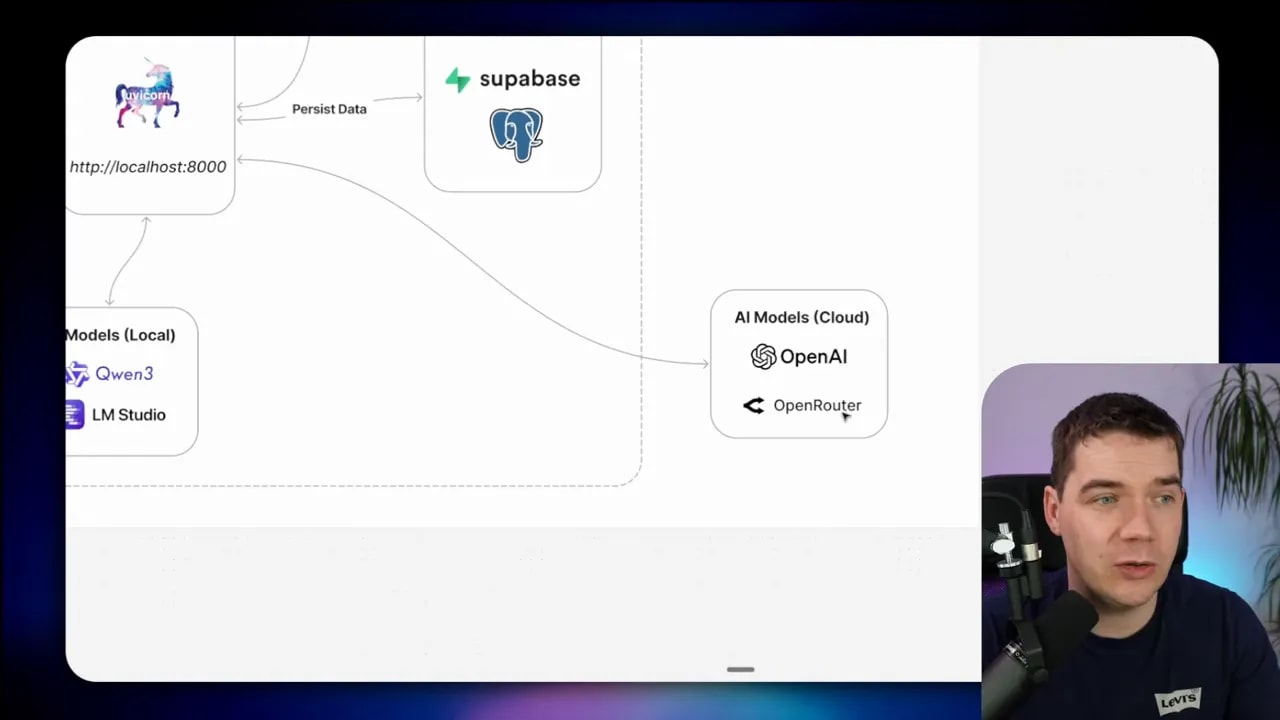
Architecture and components
I built a web app with a React frontend and a Python backend. Supabase hosts the Postgres database, authentication and file storage. Local models run inside my network; cloud models run via OpenRouter to Claude Haiku for the final reasoning pieces.
- Presidio detects PII types.
- Faker generates realistic surrogate values (names, emails, dates).
- Local LLM (Qwen 3 8B) does entity clustering and final safety checks.
- Cloud LLM (Claude Haiku) performs heavy reasoning but only on anonymized content.
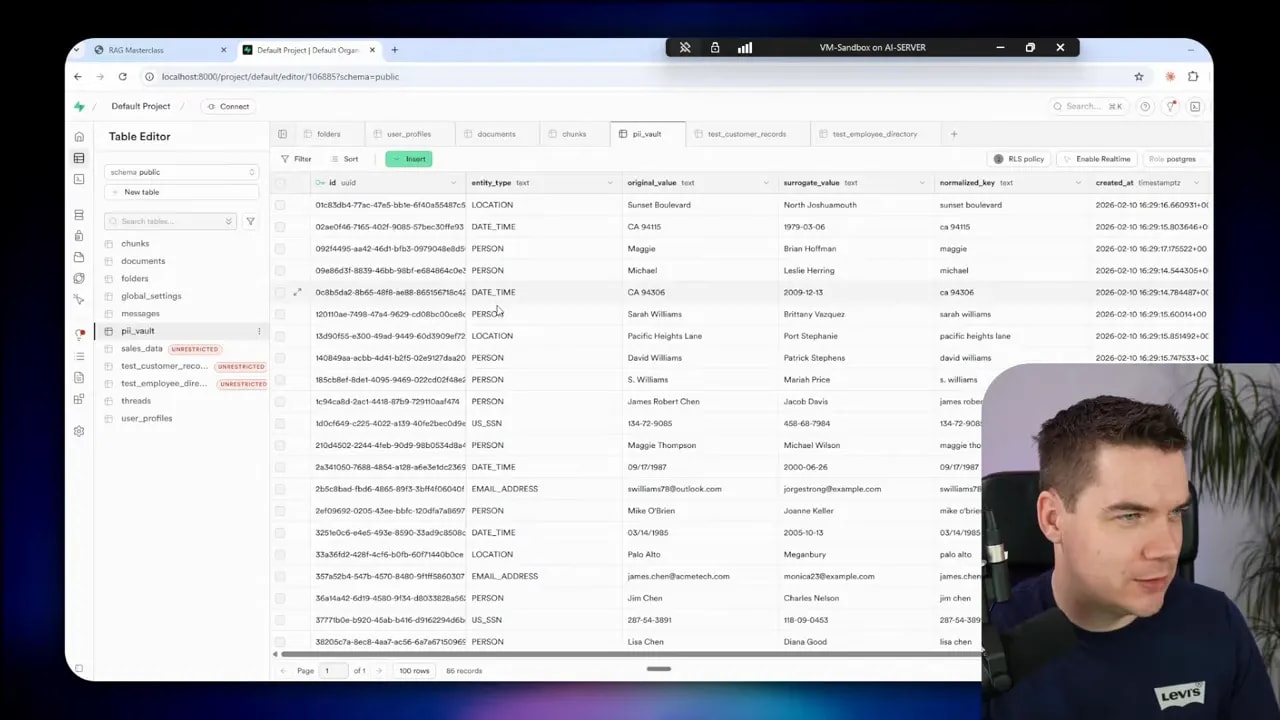
- Supabase stores the PII vault, anonymized chunks, and original documents (originals never travel to the cloud).
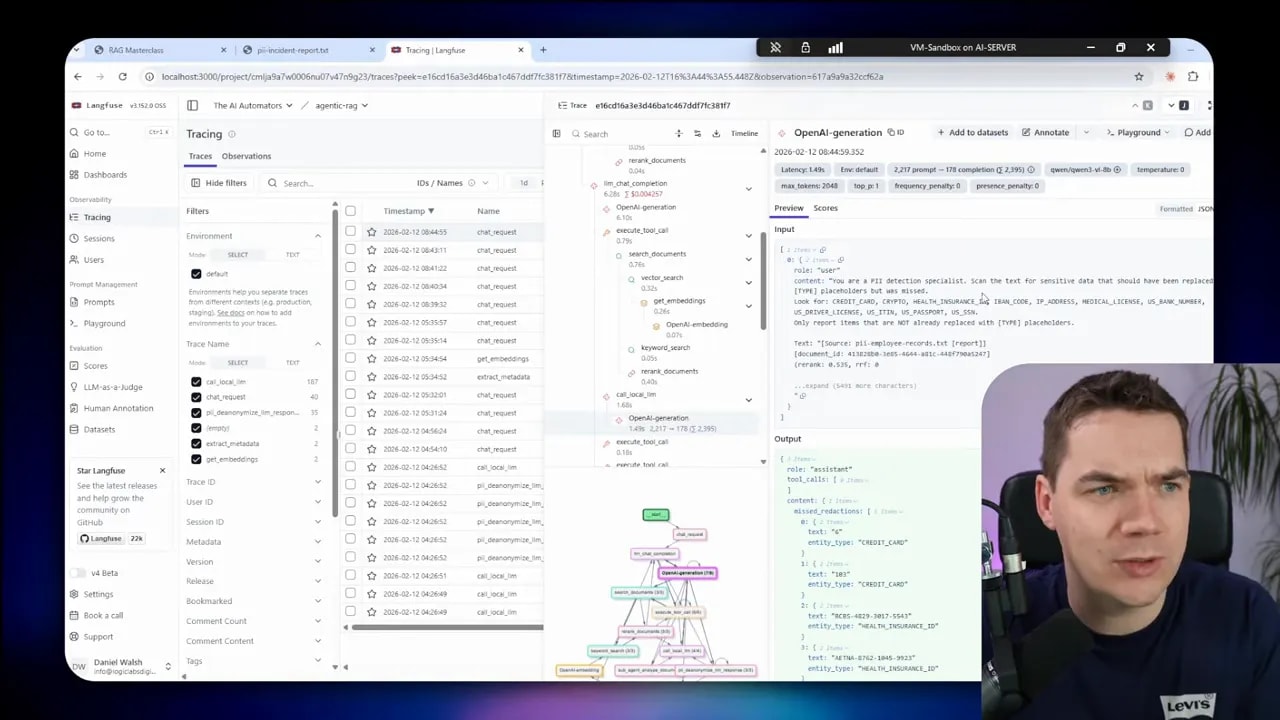
- Langfuse traces requests and verifies that the cloud LLM never received real PII.
Design choices for the PII vault and mapping scope
Deciding the vault’s scope was a key step. I weighed three options:
- Per-document mapping: easy to reason about but breaks coherence across multiple documents.
- Per-thread (conversation) mapping: works well for a single chat session but loses global consistency.
- Global mapping: consistent across tools and documents, but riskier because it creates a central store of mappings.
I ultimately chose a hybrid: persistent vault entries with a conversation-specific registry for active mappings. That way a single conversation maintains consistent surrogate assignments while the global vault helps reuse existing surrogates when appropriate.
![Presentation slide showing a clustering flow: 'Local LLM' and 'Algorithm' arrows to '[Replace]' then 'Save to Registry'; presenter inset at bottom-right.](https://www.theaiautomators.com/wp-content/uploads/2026/03/clustering-flow-save-to-registry.jpg)
Tool integration and the tricky parts
Tool calls complicate redaction. The cloud LLM works with surrogates. My backend must translate surrogate-based tool arguments back to real values before executing searches or SQL queries. After execution, results must be anonymized again before returning them to the model.
That flow applies to any external system: vector stores, SQL databases and third-party APIs. The sequence is:
- LLM issues a tool call with surrogates.
- Backend de-anonymizes the tool arguments and executes the tool.
- Backend anonymizes the tool output.
- Cloud LLM reasons over anonymized tool results and produces a surrogate-based answer.
- Backend re-identifies surrogates for the final user output.

Streaming responses add another layer of complexity. The cloud LLM streams tokens. A surrogate can be split across tokens. I buffer streamed chunks server-side and only forward them to the UI after I can reliably detect surrogates and replace them with real values. This prevents partial or broken replacements hitting the user interface.
The entity resolution problem and why it’s hard
A small example illustrates how messy anonymization can become in free text. Consider a single employee referenced multiple times as:
- Margaret Thompson
- Margaret Eleanor Thompson
- Maggie Thompson
- M. Thompson
Naive replacement assigns a new surrogate for each detected name instance. The result is incoherence: one person ends up represented by multiple fictitious names across the same record. That destroys context and undermines any reasoning built on those documents.
I tested Presidio on such documents. It did a solid job detecting names. The issue arose when I generated faker surrogates and didn’t perform effective entity normalization. The faker library is excellent for generating realistic values, but it’s not a resolver. I needed a clustering step to unify variants of the same identity.
Clustering strategies I used
I explored two approaches:
- Algorithmic clustering: heuristics based on lowercasing, nickname libraries, standard abbreviation rules and string similarity. This is fast and deterministic. It handled many cases reliably.
- Local LLM-based clustering: I prompt a local LLM to decide which detected entities refer to the same real-world identity. That model can reason over context and handle tricky abbreviations and free-text variations.
In practice, I combined both. Algorithmic clustering handles the majority of cases. I fall back to the local LLM for ambiguous clusters. This balances speed and quality.
Local LLMs as a safety net
Microsoft Presidio doesn’t support local LLMs directly, but I integrated one as a final safety pass. The local model has two jobs:
- Entity resolution: map detected entities to canonical registry keys so surrogates are consistent.
- Missed PII detection: scan the anonymized text to find PII that pattern rules and NER missed.
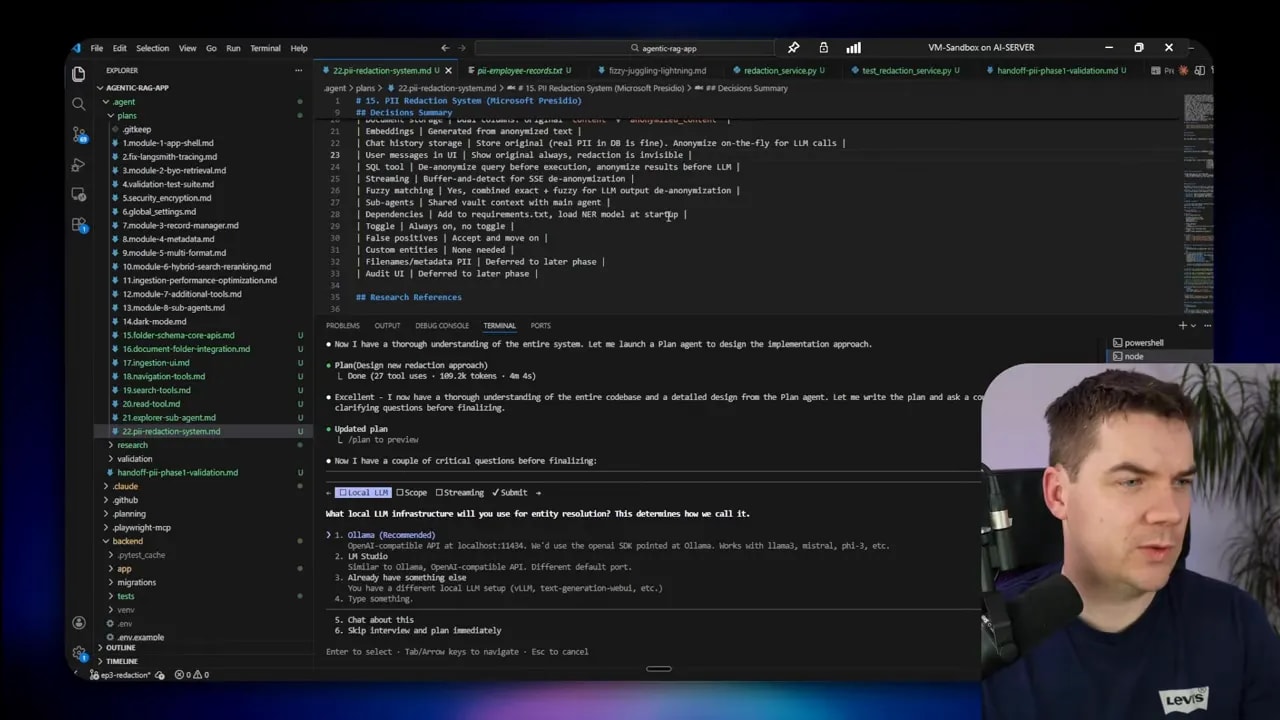
For entity resolution I used Qwen 3 8B running on my server. It’s not as capable as the largest cloud models, but it’s fast enough for clustering and small reasoning tasks. Using it increased latency, but improved accuracy dramatically. Where I could accept longer response times I used the LLM resolver. Otherwise I chose the algorithmic mode.
Implementation notes and operational details
Here are important choices I made while building the system. They represent trade-offs you should consider for your environment.
Embedding generation
I created embeddings from anonymized text. If the embeddings were created from real text, those embeddings could leak sensitive content to a cloud vector store or to a cloud model. For auditability and debugging, I stored both the anonymized and original text side-by-side in the database. The original never leaves the network.
Chat history storage
I store placeholders in the chat history. If I sent a conversation to the cloud LLM later, it must not include real PII. The front end always renders de-anonymized text for users by replacing placeholders at the API layer before delivering the content.
Tool arguments and execution
All tool arguments are translated back to real values before executing tools such as database queries or vector searches. I then anonymize the result sets before sending them to the cloud model.
Hard vs reversible decisions
I defined configurable lists:
- Entities always hard-redacted (credit cards, SSNs, crypto keys).
- Entities eligible for reversible anonymization (names, emails, addresses).
These lists are environment-specific. You should calibrate thresholds and categories to match internal policies.
Streaming and buffering
To avoid split-token surrogate leaks, I buffer the LLM stream until I can reliably detect and replace surrogates in complete tokens. This adds a small delay to the UI, but prevents partial leaks and broken replacements.
Collision avoidance with Faker
Faker can generate values that collide with real-world names already in the vault. I implemented a check when creating a surrogate to avoid collisions. If a generated surrogate already exists in the vault or matches a known real entity, I generate a new one.
Testing, validation and traces
I generated synthetic test files with many PII variations to validate the system. Tests covered ingestion, chunking, embedding creation and end-to-end chat flows. Unit tests validated the redaction service, and integration tests checked that the cloud LLM never received real PII.
Tracing was critical. I used Langfuse to track how each request transformed through the pipeline. That let me confirm that the cloud LLM only ever handled anonymized data. I intentionally kept Langfuse and tracing self-hosted so traces never left my environment.
Using Agent Teams to accelerate development
I used Claude Code‘s Agent Teams feature to parallelize research and implementation. The pattern worked well: assign small research tasks to independent agents, let a team lead orchestrate the flow, and keep shared foundations centralized (database schema, core redaction service).
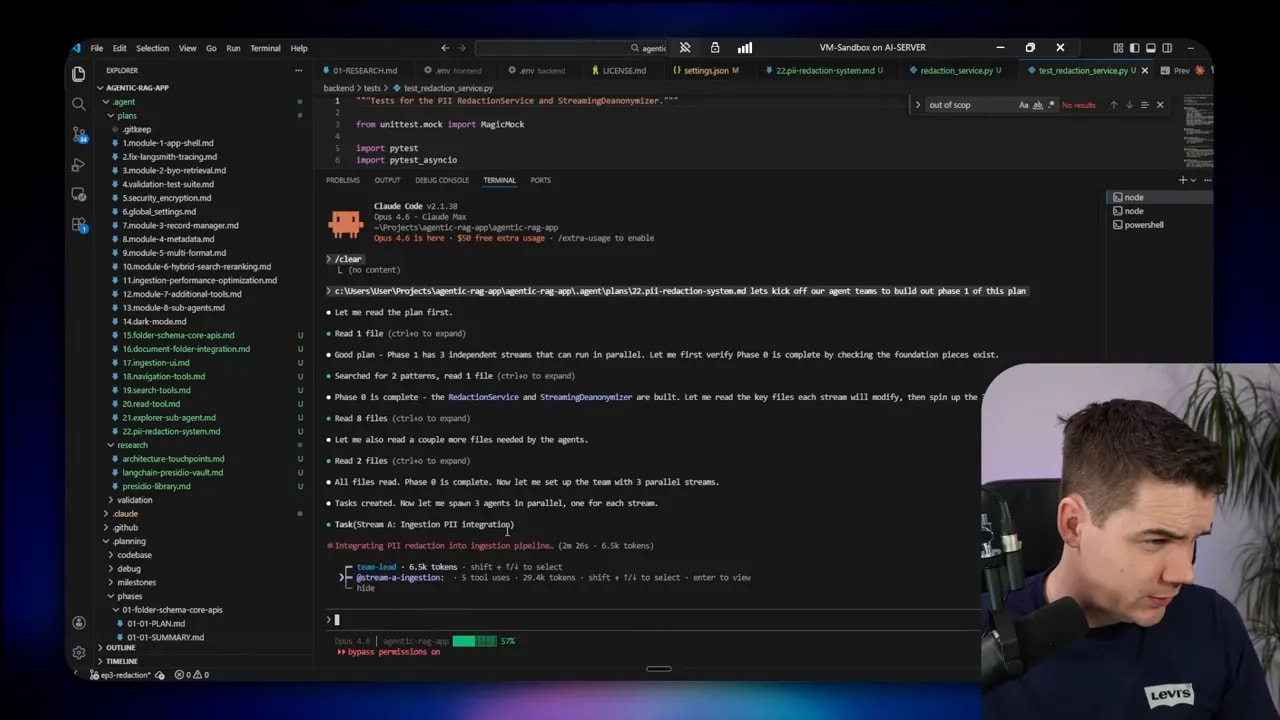
Each agent worked on a focused stream: ingestion, chat streaming, and tool integration. That allowed me to move through phases quickly while keeping shared components stable. The team lead handled handing off plans and aggregate summaries so individual agents didn’t duplicate work.
Common failure modes and how I fixed them
Here are the problems I encountered and my practical solutions.
Issue: inconsistent surrogates for the same entity
Problem: one person referenced several ways got different faker names for each mention. That ruined coherence.
Fix: add entity resolution. I clustered detected mentions and mapped them to a single canonical registry key. I combined deterministic algorithms with a local LLM fallback for ambiguous clusters.
Issue: missed sensitive entities
Problem: Presidio missed some ids and obfuscated PII.
Fix: run a final LLM safety pass. The local LLM inspects anonymized text to detect likely missed entities and returns candidates for hard redaction. This checkpoint increased recall considerably.
Issue: tool calls used surrogate names and failed to find records
Problem: a vector search or SQL query executed with surrogate terms instead of real values. The tool returned no results.
Fix: translate tool arguments back to real values before executing the tool. Then anonymize the results before sending them to the cloud model.
Issue: surrogates crossing entity boundaries
Problem: a surrogate generated for one field mistakenly replaced another unrelated field.
Fix: enforce stronger normalization keys. When saving mappings, I used normalized keys (lowercase, stripped punctuation) tied to entity types. I also added fuzzy matching and Levenshtein distance checks to correctly identify near-miss replacements produced by cloud models during generation.
Issue: pronoun mismatch after replacement
Problem: a woman’s name was replaced by a male surrogate, so pronouns in the original text no longer matched.
Fix: I used a gender-guessing library to pick surrogate names that align to expected pronouns. That avoids obvious gender mismatches in regenerated text.
Lessons learned and pragmatic trade-offs
Building this highlighted several trade-offs. I’ll list the most important ones and how I addressed them.
- Air-gapped equals greater control but higher cost. If you can run everything locally, do it. Local models and embeddings remove the need for reversible anonymization in many cases, but they require expensive infrastructure.
- Cloud models are still more capable. If you want the best reasoning quality, you may need cloud models. Reversible anonymization narrows the risk enough to justify their use for many tasks.
- Entity resolution is the core problem. Without consistent entity mapping, reversible anonymization collapses. Invest effort in entity clustering and validation.
- Defense in depth pays off. Combine detection, local LLM checks, hard redaction, access controls and legal safeguards. No single layer is enough.
- Simplicity helps. My first architecture was over-engineered. Simplifying to a clear anonymize-send-reverse pattern reduced bugs and made the system easier to validate.
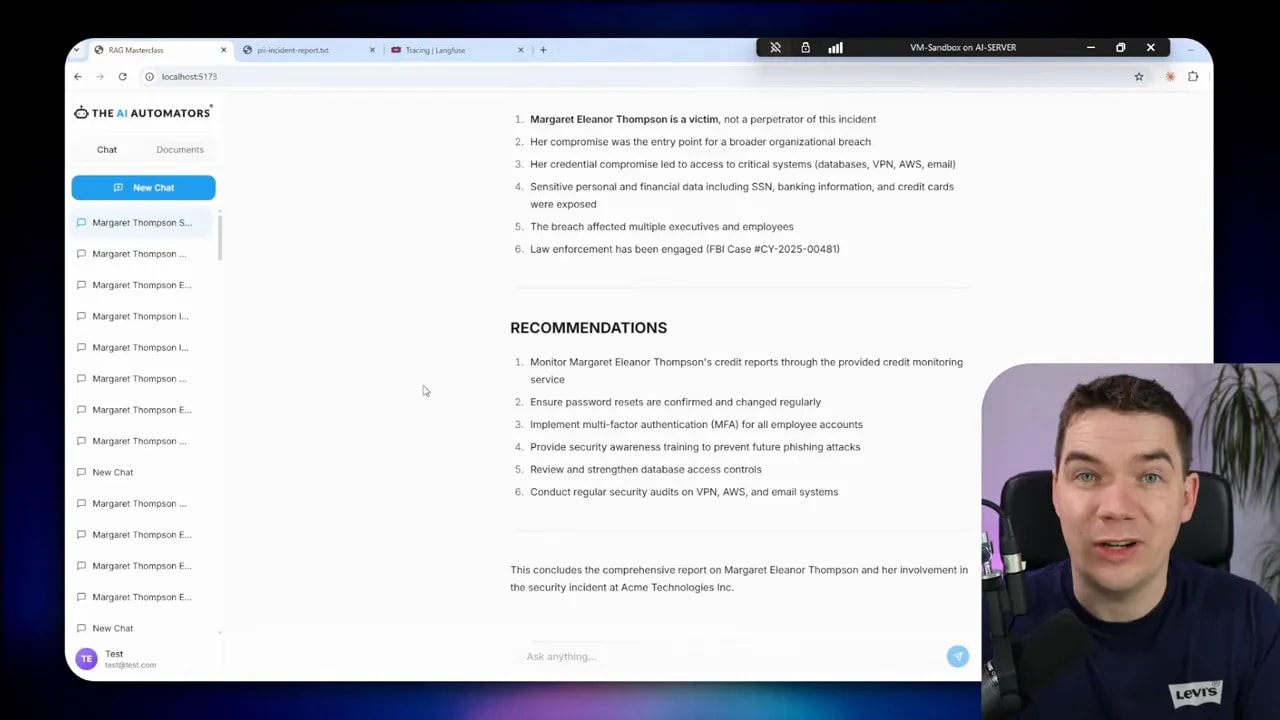
Key operational recommendations
The following items capture practical defaults I used in this build. They’re meant as starting points you can adapt.
- Always store placeholders in chat history. This guarantees that any conversation sent to a cloud LLM contains no real PII.
- Create anonymized embeddings. Generate vector embeddings from anonymized chunks to prevent leakage through vector stores.
- Keep the vault encrypted for sensitive values. Encrypt entries like card numbers and passports if you store them at all.
- Buffer streamed LLM outputs. Prevent split-token leaks by buffering and replacing surrogates server-side before pushing tokens to the frontend.
- Use deterministic fallback approaches. Algorithmic clustering covers many cases faster than LLM-based resolution. Reserve LLM use for ambiguous or high-risk items.
- Define strict scopes for redaction. Choose whether surrogates are global, per-thread or per-document depending on your privacy needs and use cases.
- Audit and trace everything locally. Use a self-hosted tracing system so you can confirm what the cloud LLM saw without sending traces outside your network.
What I changed after testing
As I iterated, I introduced several improvements that made the system far more reliable:
- Hard redaction for critical entity types.
- Entity resolution mode switch: algorithmic vs LLM. You can choose the right balance between speed and accuracy for your deployment.
- Simplified LLM prompts and outputs to reduce processing overhead on local models.
- Collision checks before assigning faker surrogates.
- Gender-aware surrogate generation for pronoun alignment.
- Langfuse integration to validate that cloud calls only saw anonymized inputs.
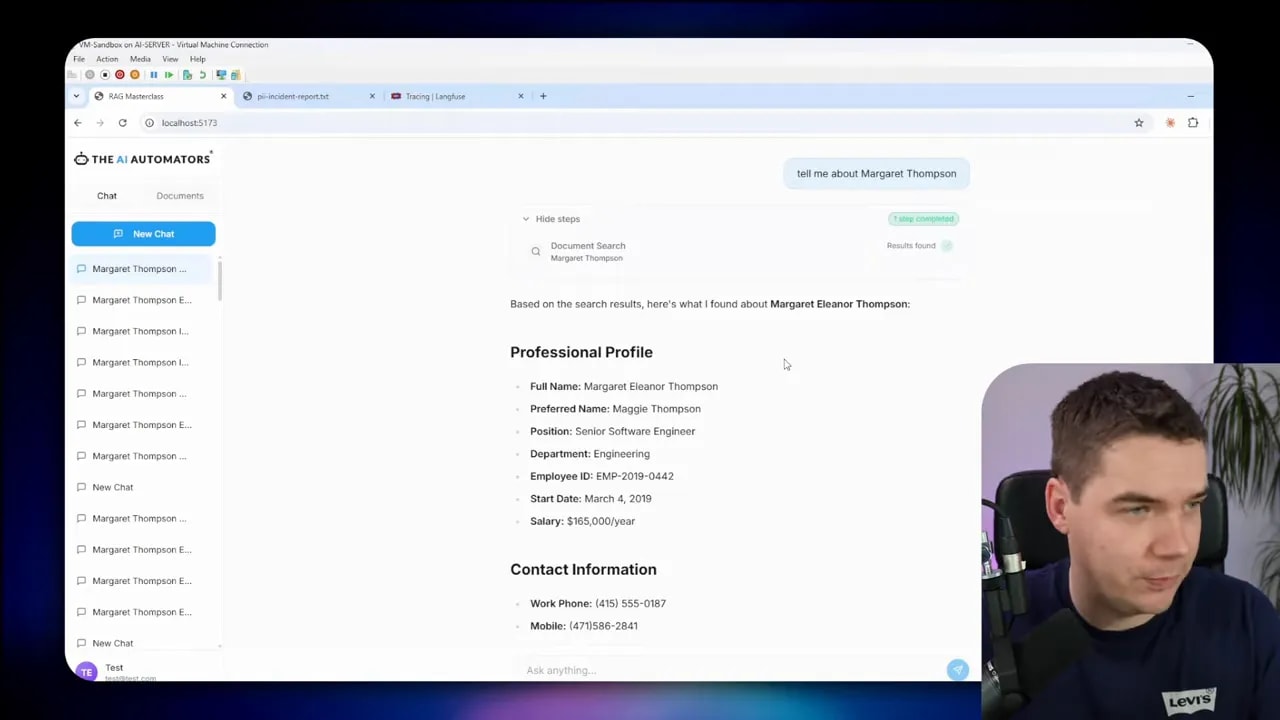
Where this approach breaks down
There are real limitations you should understand:
- Calculations are unsafe with surrogates. If the model must compute days overdue or VAT, surrogate dates or amounts will produce wrong answers. For calculations, perform them locally and return computed results.
- Spatial reasoning fails. Any location-based reasoning about distances or routes will be incorrect if you replace addresses with unrelated fake locations.
- Latency increases with local LLMs. Adding a local resolver improves quality but adds latency. You must balance responsiveness vs accuracy.
- Entity linking at scale is challenging. With thousands of documents, clustering and consistency become harder. Invest in robust normalization and validation tooling.
Final notes on operationalizing this pattern
Deploying a redaction and reversible anonymization layer is realistic for many organizations. It protects sensitive data while allowing cloud LLMs to provide value on private knowledge. The implementation requires careful design of mappings, tool translation, streaming buffers and fallback checks.
I built the solution incrementally. I started with a simple pipeline and iterated. The biggest wins came from simplifying the architecture and centering the design around a clear contract: the cloud model only ever sees surrogates. Keep that contract simple and enforce it at the API layer. That makes validation and auditing practical.
If you implement a similar system, focus first on defining what must be hard redacted and what can be safely anonymized. Then add deterministic clustering and a local LLM safety net for the ambiguous cases. Finally, instrument every step so you can prove to auditors and stakeholders that real PII never left your perimeter.
