

I built AI agents for businesses and quickly learned that vector search is powerful but not a cure-all. Vector search shines for conceptual, fuzzy queries. It struggles when answers require exact matches, structured calculations, or chaining facts across systems. Over hundreds of projects I helped with, the same blind spots showed up again and again. I started to think of retrieval as an engineering problem: choose the right retrieval method for each question type and you dramatically reduce hallucinations, incomplete answers, and brittle behavior.
Why retrieval matters more than you might expect
When someone asks an AI agent a question, the agent must decide whether it has enough context to answer or whether it needs to fetch more information. That loop—reason, decide, fetch, answer—repeats throughout a conversation. Treating retrieval as a generic vector lookup turns that loop into a gamble. You may get the correct chunks back. Or you may get similar but irrelevant material that confuses the model.
Vector search returns the most similar items to a query embedding. Similarity is not the same as relevance. Similarity is a geometric notion. Relevance depends on the user’s intent, constraints, and sometimes exact identifiers. If your system needs precision, you need a different tool.
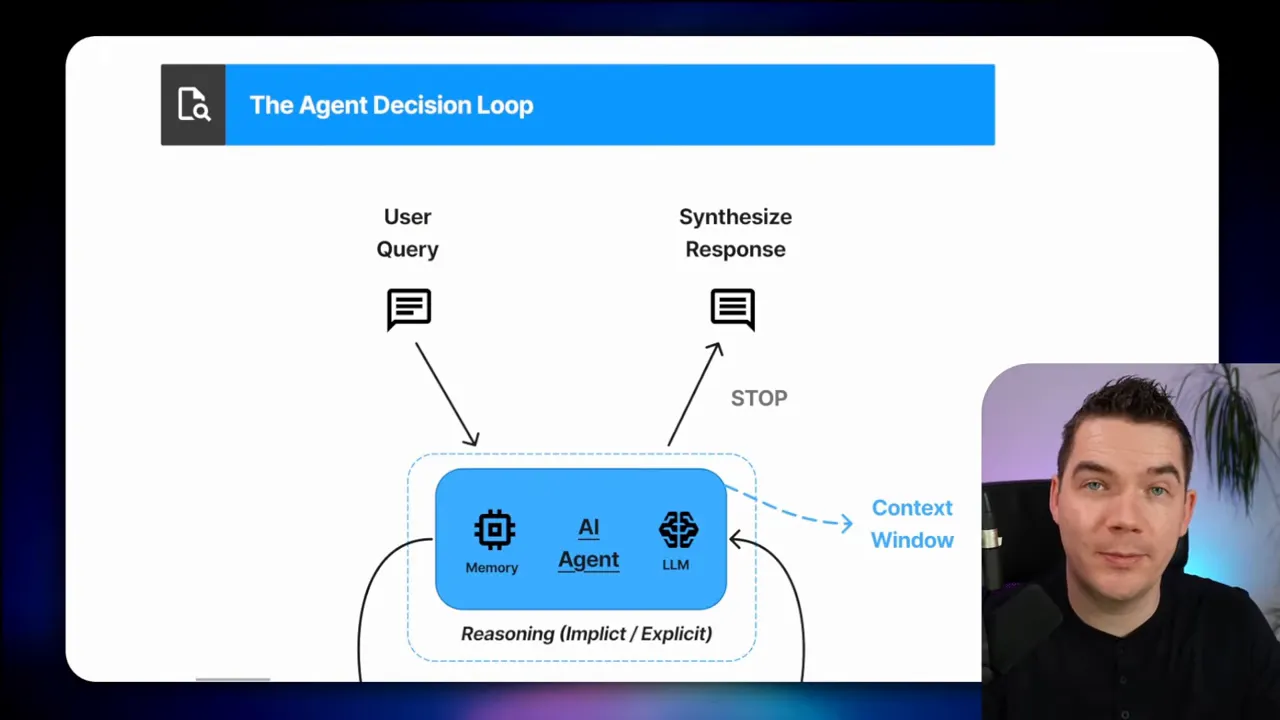
Retrieval engineering: the practical toolbox
I group retrieval techniques into a toolbox. Each tool fits specific question types:
- Vector search for conceptual, semantic queries where approximate matches are fine.
- Lexical search and pattern matching for exact codes, IDs, and short domain-specific tokens.
- Hybrid search when you need both semantic and lexical strengths.
- SQL or structured lookups for tabular queries, counting, sums, and time-based metrics.
- Knowledge graphs for relationship traversal, multi-hop questions, and global pattern detection.
- API calls and system queries to fetch canonical, authoritative values from the source of truth.
- Document processing such as batch summarization or map-reduce when an answer requires synthesizing many parts of a large document.
- Multimodal retrieval when the answer must include images, diagrams, or other media in-line.
- Re-ranking and verification steps to enforce recency or other constraints after an initial retrieval pass.
All of these are still RAG—retrieval augmented generation—so long as the retrieved content feeds the model and helps produce the final response. Calling them separate tools just reminds us to pick the right one for the job.
How I think about question types
I find it helpful to classify requests by the kind of reasoning or data retrieval they require. Below are nine real-world question types that commonly break semantic-only systems, with the retrieval strategy that reliably solves each case.

#1 Summary questions: full-document extraction
Scenario: You have a transcript of a leadership meeting and someone asks, What decisions were made in the leadership meeting?
Why vector search fails here: decisions are sprinkled across the transcript. They might not be tagged or explicitly labeled as decisions. A vector store will likely return a handful of chunks that are similar to the query, but it will probably miss many decision points. Partial answers here are misleading because a missed decision can change the outcome.
What works:
- Full-document processing. If the transcript fits within the model context, load it entirely and let the model extract decisions. If it is too large, run a batch summarization workflow that identifies decision statements across chunks and aggregates them.
- Document processing sub-agent. Delegate the task to a specialized worker agent that reads the whole transcript, extracts decision items, and returns a compact structured list to the main agent so you don’t waste the main model’s context window.
- Agentic RAG only when paired with principled loop logic. The agent can iteratively search, ask focused follow-ups, and keep fetching until coverage meets a threshold, but it must know how to measure coverage.
- Metadata filtering to pin the search to the exact meeting or date before attempting extraction.
If you need to automate this, I created an n8n automation that performs chunked summarization and then consolidates decision items into a single structured output. That approach reduces missed items and gives you an auditable trail back to the source chunks.

#2 Distributed feature extraction: product documentation
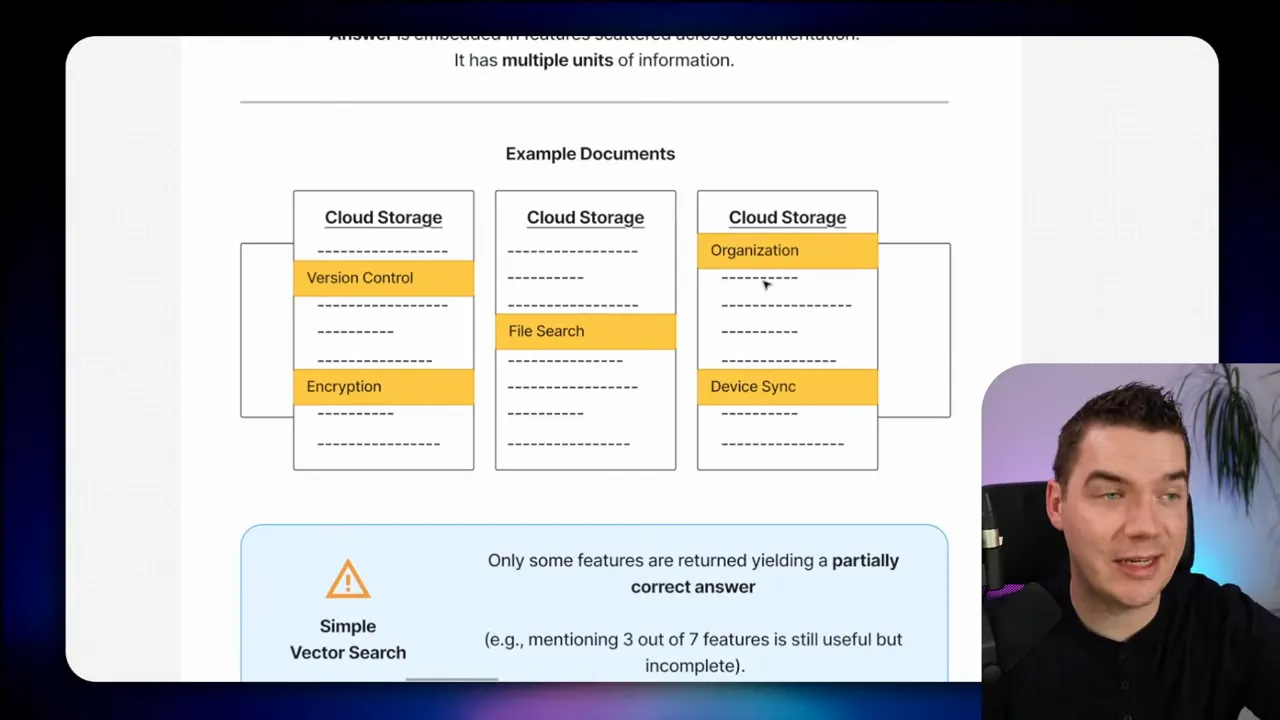
Scenario: A knowledge base holds cloud storage documentation. Someone asks, What are the main features of the service?
Why vector search fails here: features such as version control, encryption, or device sync can be described across many pages. A semantic search may return some parts but not a complete list. The answer becomes partial rather than inaccurate, but partial answers rarely satisfy product or support teams.
What works:
- Document processing and indexing of canonical lists. If there is already a features page, index it explicitly. If not, create an extraction job that searches across documents, pulls potential feature mentions into a staging area, and deduplicates items into a single features document.
- Hybrid search so you keep semantic discovery while also surfacing exact matches to product-specific phrases.
- Periodic batch jobs that create curated summary pages for common informational queries. These pre-processed summaries become high-precision retrieval targets.
This pattern converts scattered knowledge into a single reliable retrieval point. I often add a metadata tag like “canonical_features” so retrieval can prefer the curated item over raw fragments.
#3 Report summarization: synthesize every section
Scenario: Someone asks for a comprehensive summary of an internal report.
Why vector search fails: a long report gets broken into chunks. A vector store returns the top-k most relevant chunks, which might include the executive summary but miss technical details. Missing sections leads to incomplete summaries that can be misleading.
What works:
- Map-reduce summarization. Break the document into chunks, summarize each chunk, then merge the chunk summaries into a final top-level summary.
- Hierarchical summarization. Summarize at multiple levels: paragraph, section, chapter, then whole. This is especially effective when documents have natural structure.
- Dedicated document sub-agent that reads entire reports and returns structured outputs such as “Key findings”, “Recommendations”, and “Data caveats”.
If the report is stored as a PDF with tables or images, convert it into machine-friendly markdown or structured JSON first. Several OCR and document parsers do a much better job when content is token-friendly.
#4 Exact single facts: when one unit of truth matters
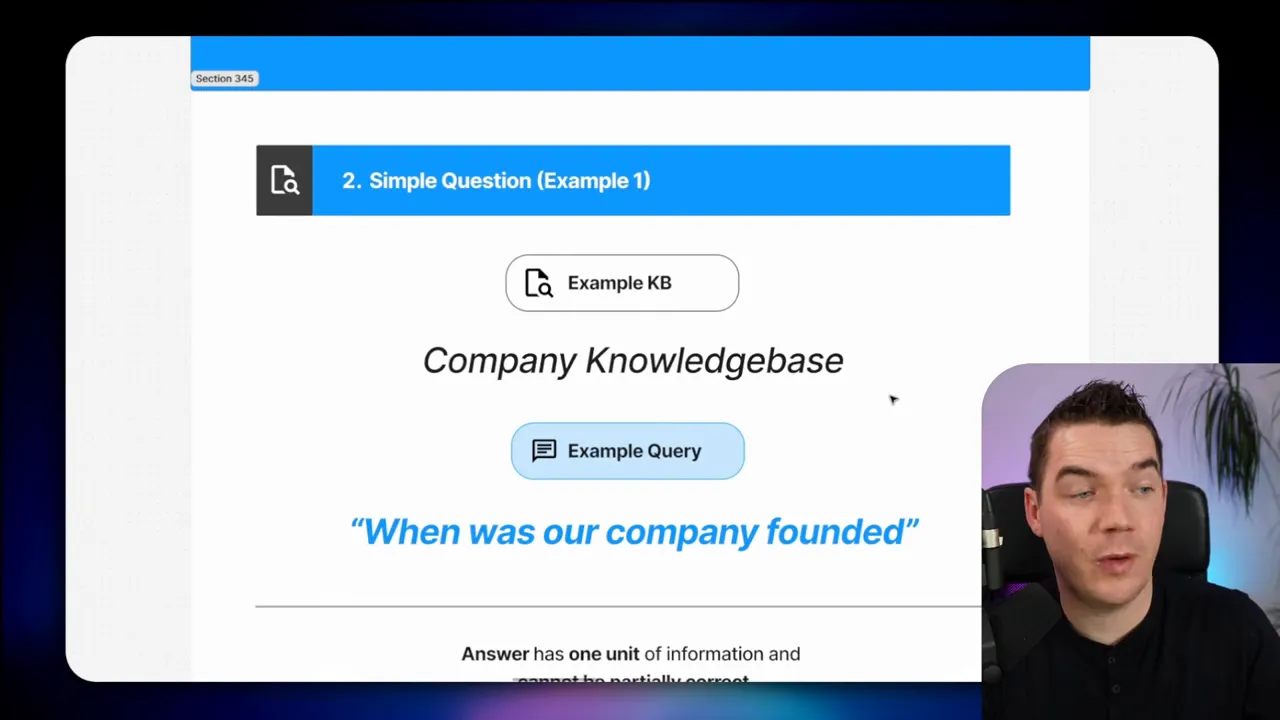
Scenario: A user asks, When was our company founded? or Who created the Blue Sheet system?
Why vector search may fail: some single facts work well with semantic search. If the founding year appears verbatim in a chunk, the embedding will likely match. But domain-specific tokens like “Blue Sheet” or regulatory codes like “15 CFR 744.21” are risky. Embedding models may not encode these rare or synthetic tokens well because they rarely appeared in training data.
What works:
- Lexical search or exact match for company-specific terms and identifiers. Use database lookups, keyword indexes, or a search engine that supports exact matching.
- Pattern matching and regex when identifiers include punctuation or structured tokens. Regex will find “15 CFR 744.21” even when hybrid embeddings split it into tokens.
- Glossaries and short structured tables for domain terms. A company glossary provides an authoritative mapping of internal names to definitions.
- Hybrid search as an intermediate step when you want both semantic recall and lexical precision.
I built an n8n workflow that first tries an exact lookup in a glossary table and falls back to a semantic search only when the exact lookup fails. That yields predictable results and cuts down on false positives.
#5 Recency-dependent facts: the current CEO and similar queries
Scenario: Who is the CEO of our company?
Why vector search fails: the knowledge base may mention many past CEOs across decades. Semantic similarity does not favor recency. A vector store may return older documents that match the phrase “CEO”, producing outdated answers.
What works:
- Metadata filtering. Tag document chunks with publication dates and filter for the most recent items before ranking. When answering “current” questions, limit retrieval to the newest documents or a specific date range.
- Structured lookups such as an org chart or a database of officers. Those sources give a single canonical value for “current CEO”.
- Re-ranking by recency. Use a re-ranker that can take candidate chunks and reorder them by metadata like date or document type.
- Clarifying queries. When ambiguity exists, design the agent to ask whether the user means “current” or “historical”. That simple step avoids assumptions.
#6 Tabular and numeric lookups: financials and time-series
Scenario: What was our revenue in Q2 2024?
Why vector search fails: numeric values are often embedded inside tables or PDFs. A semantic query may find text talking about Q2 results but miss the table cell with the exact number. The result is unreliable if users need authoritative figures for reporting.
What works:
- Structured data queries. Use SQL or a BI API to fetch exact numeric values from the financial system. Then display the exact value and cite the source.
- Table extraction and markdown OCR. Convert financial PDFs into cleaned tables with parsing tools so the data becomes queryable.
- API-first retrieval. If your ERP, finance, or reporting tool exposes an API, call it directly for canonical numbers.
- Re-ranking with metadata to prefer official reports or the latest filings over informal mentions.

I integrated a spreadsheet agent in n8n that reads from an accounting table. When someone asks revenue questions, the agent queries the table directly and returns the exact figures with a reference. That removes uncertainty and makes the agent trustworthy for finance teams.
#7 Aggregation questions: counts and computed metrics
Scenario: How many customer support tickets were closed last month?
Why vector search fails: counting or computing across many documents requires aggregation that rarely appears verbatim in text. Each ticket might exist as an individual document, but the total count is not embedded anywhere.
What works:
- SQL or analytics queries against your ticketing system. These systems already expose endpoints that return counts based on filters.
- API calls to the ticketing platform with the proper date filters. Return the computed result rather than attempting to compute by aggregating text chunks.
- Post-processing tools such as a calculation microservice. The LLM can request the count, then call a service that performs the aggregation and returns a precise number.
When I handle aggregation queries, I prefer the LLM to orchestrate the call rather than compute locally. The model acts as the conductor, issuing an API call and formatting the result. That keeps computations accurate and auditable.

#8 Global questions: themes across a corpus
Scenario: What are the recurring operational challenges mentioned across all team retrospectives?
Why vector search fails: this question spans the whole knowledge base. No single document contains the complete answer. A vector search will sample a subset of retrospectives and produce a partial, biased summary.
What works:
- Knowledge graphs. Graphs extract entities and relationships from documents, then link repeated concepts across the corpus. You can query the graph for frequently co-occurring themes such as “deployment delay” or “communication gap”.
- Map-reduce corpus summarization. Process the corpus in batches to extract themes, then merge and rank them by frequency and impact.
- Pre-computed indices that periodically compute common themes and make them available as high-level retrieval points rather than relying on on-demand sampling.
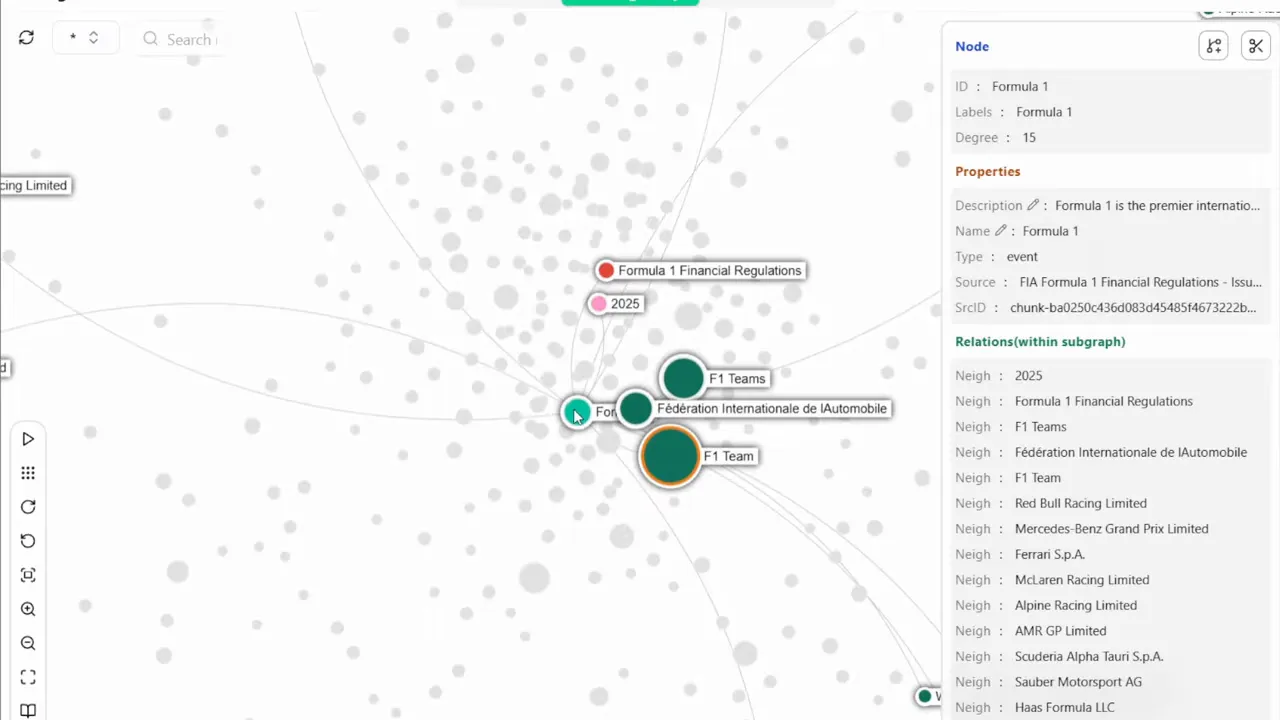
I set up a pipeline that extracts entities from retrospectives and stores them in a graph database. Queries asking about recurring themes hit the graph and return ranked concepts with counts and example documents. This gives leaders a defensible view of cross-team issues instead of a one-off answer.
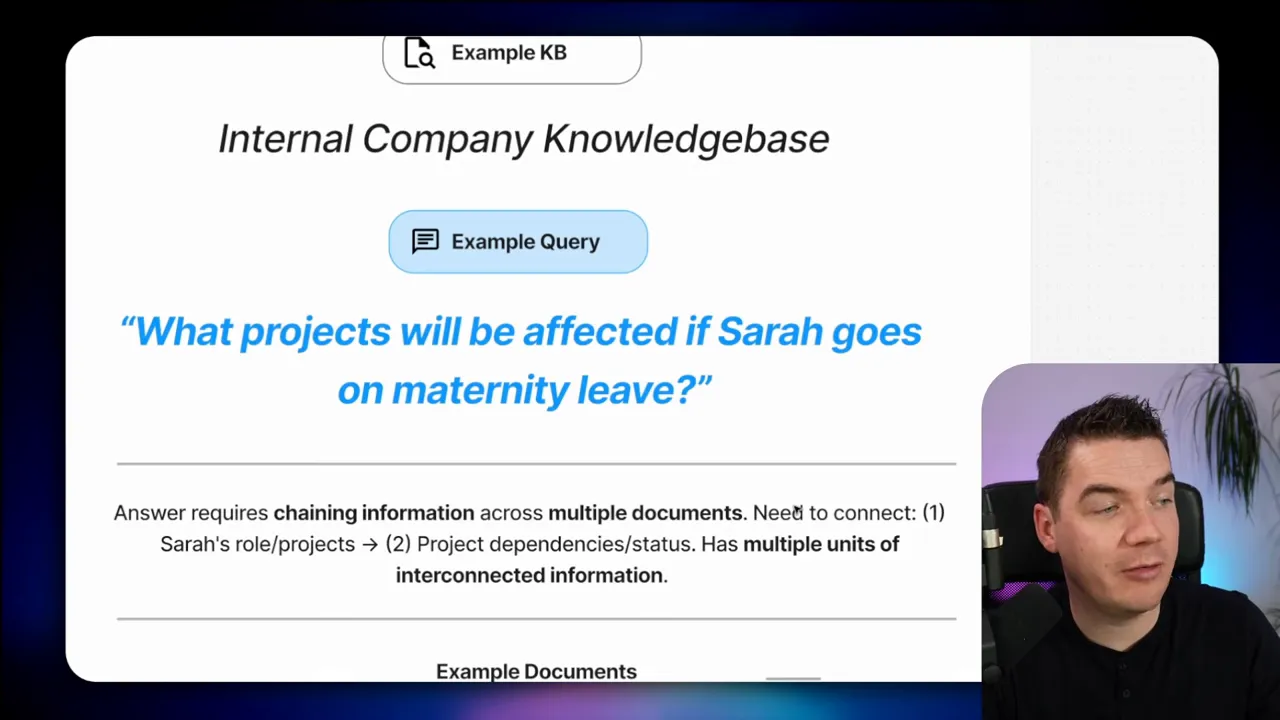
#9 Multi-hop questions: chaining facts across systems
Scenario: What projects will be affected if Sarah goes on maternity leave?
Why vector search fails: the answer requires chaining employee roles, project assignments, timelines, and dependencies. Those facts might live in different systems: HR, project management, and dependency tables. Vector search can surface isolated pieces but struggles to join them into a reliable chain.
What works:
- Knowledge graph traversal when your data model links people, roles, projects, and dependencies. Traversal gives a clear path from Sarah to impacted deliverables.
- Agentic multi-step retrieval combined with verification steps. The agent queries HR for Sarah’s role, then queries the project tracker for assignments, then re-checks timelines and risk items. Each step is explicit and auditable.
- Structured APIs that provide role-to-project mappings. The LLM orchestrates multiple calls and synthesizes the results.
A knowledge graph gives the highest trust. When I model these relationships upfront, I can answer multi-hop questions deterministically rather than relying on reasoning over disconnected text.
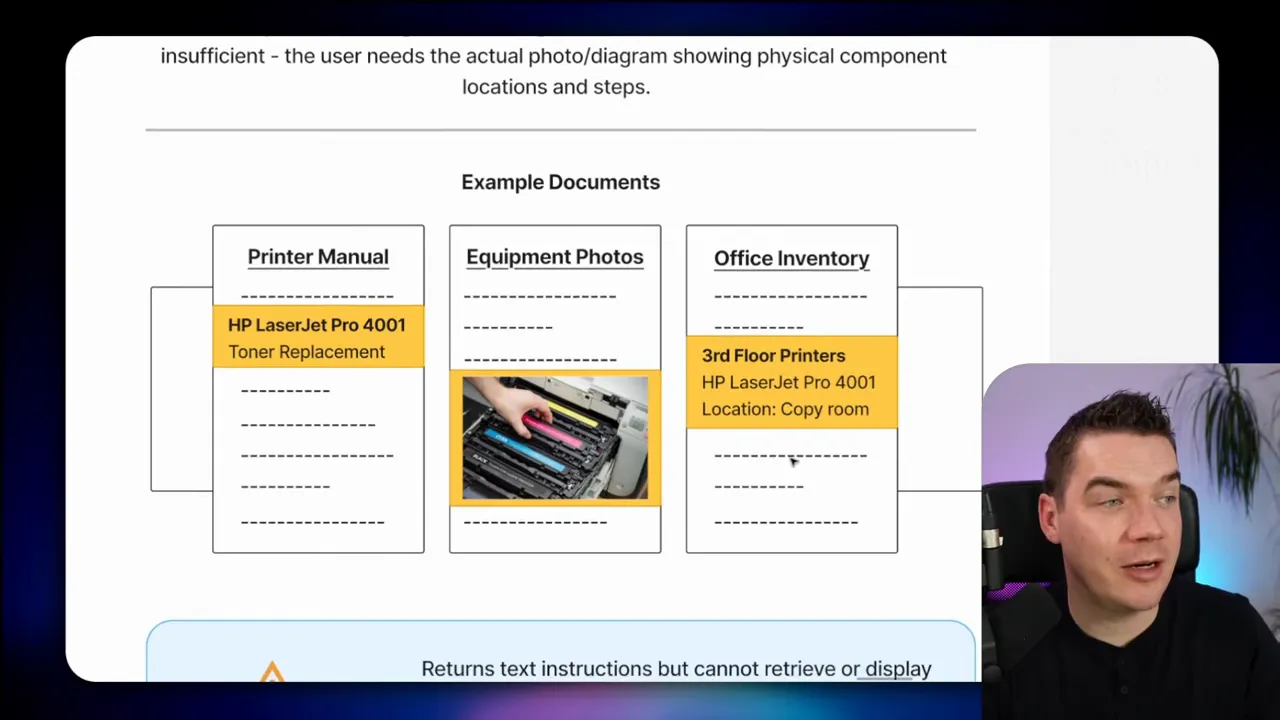
#10 Multimodal questions: images and diagrams
Scenario: How do I replace the toner cartridge in the third-floor printer? Show me the diagram.
Why vector search can be insufficient: a text-only system may list steps, but many operational tasks require images or annotated diagrams. The user needs the diagram aligned to the exact printer model.
What works:
- Multimodal RAG. Index images together with text chunks so the agent can return the correct diagram inline.
- Metadata filtering by equipment model and location. This ensures the diagram corresponds to the correct device.
- Agentic retrieval that fetches image assets, signs URLs if necessary, and injects them into the conversation safely.
When I build these agents, I store images in a CDN and index the URLs in the vector store metadata. The retrieval returns both the text steps and the image link so users get a complete answer.
#11 Post-processing and computed analytics
Scenario: Is our customer churn rate trending up or down over the past six months?
Why vector search fails: this is a calculated metric. If the churn rate hasn’t been precomputed and stored, an agent that only searches text cannot reliably compute the trend by sampling documents. Calculations require raw data and a computation step.
What works:
- SQL or analytics systems to fetch churn numbers per month, then run trend calculations in a dedicated service.
- Computation toolchains that the agent can call to perform math, e.g., a microservice or a spreadsheet API.
- Pre-computation where possible. If your analytics team can compute churn daily, the agent simply retrieves the canonical figure and avoids runtime calculation errors.
I prefer the agent to trigger an analytics query and present the chart or numeric trend. That gives the user a direct, verifiable result instead of a model-generated estimate.
#12 Handling false premises: avoid chasing fiction
Scenario: Which VP led the Berlin office before it closed?
Why vector search can lead to hallucination: the question contains a false assumption if the company never had a Berlin office. If the corpus mentions both “Berlin” and “VP” in unrelated documents—say expansion plans—an LLM fed unrelated chunks might synthesize a plausible but false answer.
What works:
- Exhaustive search and verification. Run a broad search looking for evidence that the Berlin office existed. If no evidence appears, the agent should flag the premise as unsupported and state the actual facts.
- Context expansion to include surrounding paragraphs and metadata so the agent sees full evidence rather than isolated mentions.
- Verify-answer pattern. After producing an answer, require the agent to point to source chunks or mark the claim as unsupported when evidence is absent.
- Evaluation and ground-truth tests for your agents so you catch these mistakes before they reach users.
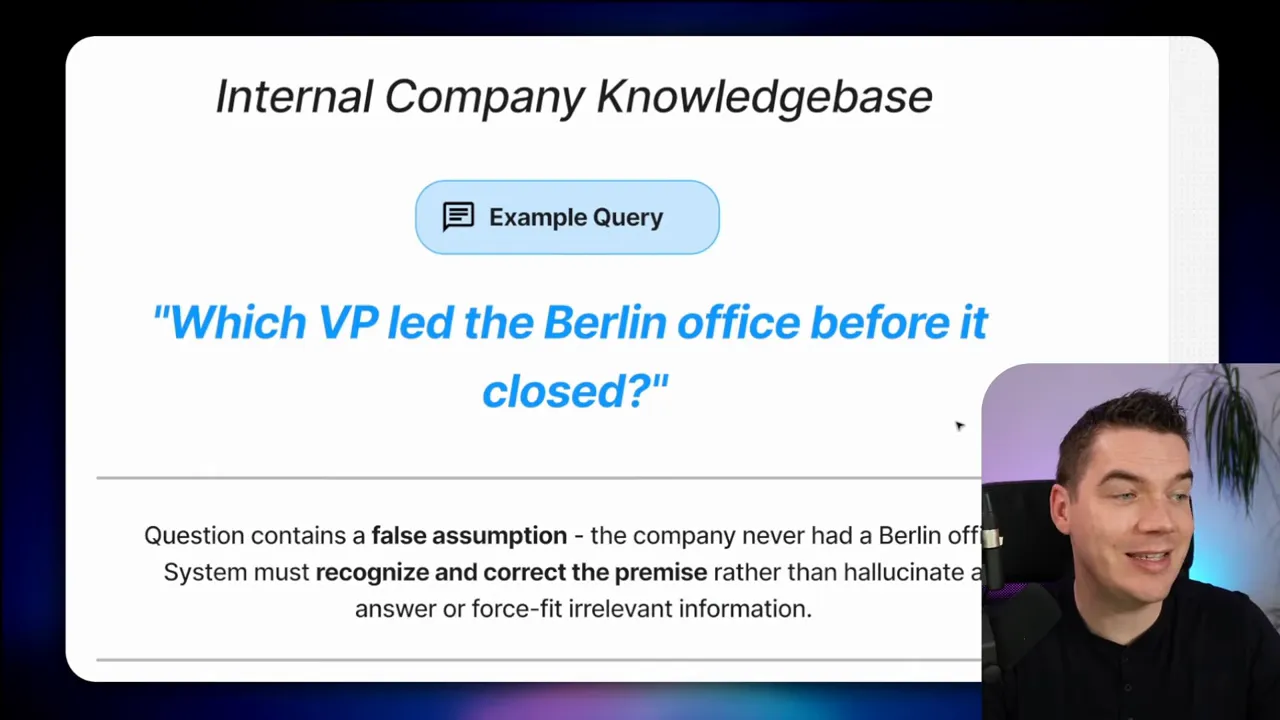
When I design agents for sensitive queries, I add a verification step that refuses to answer when the evidence is weak. This prevents the model from inventing supporting facts to satisfy a user’s request.
How to combine techniques in practice
Most real systems need a hybrid approach. Here are patterns I use when building production-grade agents.
Hybrid pipelines
I combine multiple retrieval methods in prioritized steps. For example:
- Try a structured lookup for canonical facts (org chart, financial table, glossary).
- If no canonical hit, perform a lexical search for exact identifiers using regex.
- Next, run a vector search limited by metadata filters.
- Finally, call a re-ranker that considers recency, source type, and confidence scores.
This progressive fallback reduces false positives and improves consistency. The model receives the best available evidence rather than a random selection of similar chunks.
Sub-agents and task delegation
Large or complex tasks benefit from specialized sub-agents. I often create:
- A document-processing agent for summarization and extraction.
- A calculation agent that performs numeric computations and data cleaning.
- An API orchestration agent that handles auth and queries to internal systems.
The main agent coordinates these workers. That design preserves the main model’s context for high-level synthesis while delegating heavy lifting to dedicated services.
Metadata, schema, and provenance
Good metadata can be the difference between a correct answer and a hallucination. I always include:
- Document type: memo, financial report, policy, transcript.
- Creation and publication dates.
- Source system or owner.
- Model of equipment or product identifier when relevant.
Embed provenance in every output so users can see the cited chunks or the API that provided the result. That builds trust and makes auditing straightforward.
Re-ranking and verification
After an initial retrieval pass, re-ranking helps enforce business rules such as recency, authority, or cost. You can use small models or heuristics to reorder results before you send them to the main LLM.
Verification is a second, post-generation step. Ask the model to match its claims against returned sources and flag any unsupported assertions. If the claim lacks evidence, force the agent to either ask a clarifying question or respond with a qualified statement such as “I could not find evidence that…”

Operational tips when you build
- Model your common queries first. Determine whether they require exact numbers, images, multi-hop links, or global themes.
- Prefer canonical sources for high-stakes answers. Finance, legal, and HR should be answered by the systems of record whenever possible.
- Design fallbacks and clarifying prompts. Make the agent ask for clarification when a question is ambiguous or when a false premise is detected.
- Run regular evals. Build tests that mirror real queries and include ground-truth checks to surface regressions.
- Use precomputation for expensive analytics and global themes. Many queries are repeated; precompute and cache those results.
Common retrieval architectures I use
Here are two practical architectures that have worked in production for me.
Architecture A: Real-time hybrid responder
- Request arrives at the agent.
- Agent checks a lightweight cache for precomputed answers.
- Agent runs an exact lookup in structured stores (glossary, org chart, finance table).
- If no hit, perform a lexical search for identifiers and regex matching.
- Run a vector search constrained by metadata filters.
- Re-rank candidates by recency and source type.
- Model generates the response with citations to the chosen candidates.
- Verification step checks claims against the cited sources.
This flow keeps latency reasonable and ensures high-precision answers for most common queries.
Architecture B: Batch knowledge synthesis
- Nightly or weekly batch jobs build derived indices: canonical summaries, feature lists, entity-resolved graphs, and trend metrics.
- These derived artifacts are stored as high-confidence documents or graph nodes.
- Realtime queries prefer derived artifacts, falling back to live retrieval only when needed.
Batch synthesis works well when your corpus is large and many queries are repetitive. It trades storage and compute for speed and reliability at query time.
Measure success: what to evaluate
When you build retrieval systems, you need metrics beyond raw accuracy. Focus on:
- Precision of retrieved evidence—how often does the retrieved chunk actually support the answer?
- Coverage—for summary and global questions, did you capture the full set of relevant items?
- Freshness—do answers change appropriately when newer documents arrive?
- Auditability—can you trace every claim back to a cited source or a computation?
- User trust—are users accepting the answers without verification, or are they checking sources frequently?
Automated eval suites that include false-premise tests, recency checks, and numeric verification catch many problems early. I use a mix of unit tests that call each retrieval method and end-to-end tests that simulate real user queries.
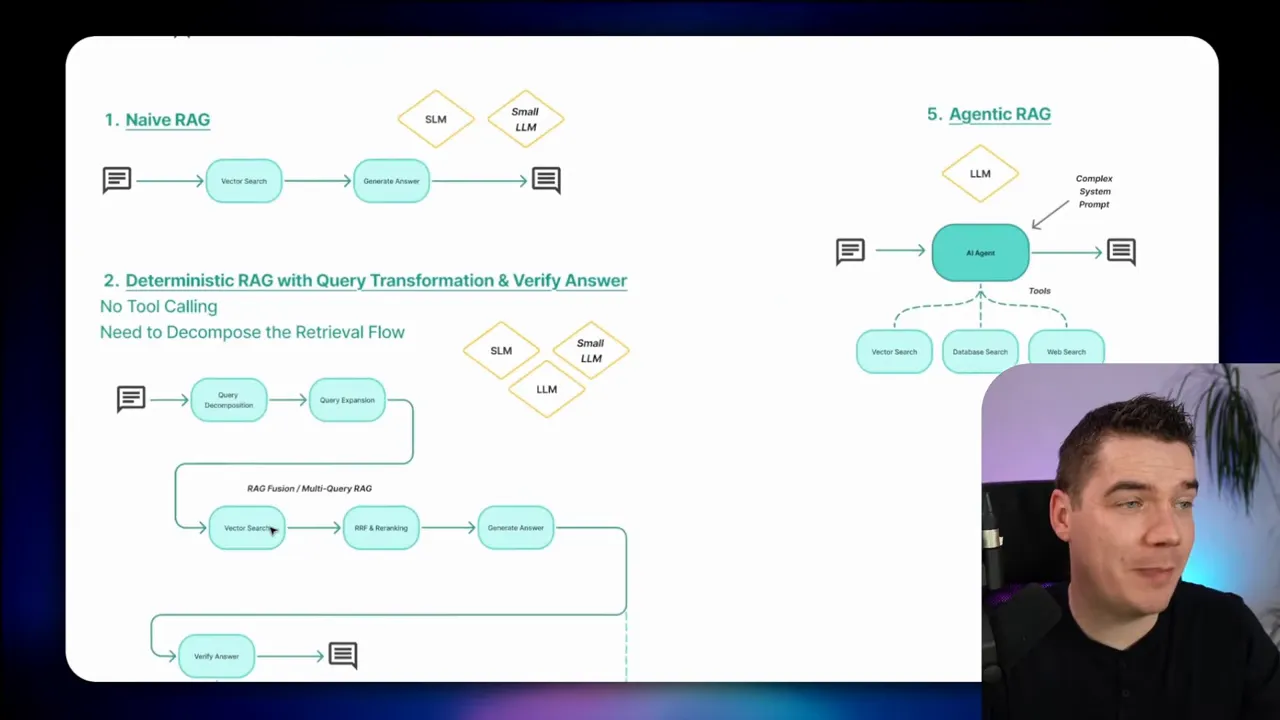
Short checklist before you deploy
- Classify the top 50 queries your users request and assign the preferred retrieval method.
- Ensure system-of-record APIs exist for finance, HR, and critical metrics. If they do not, create precomputed indices.
- Index images and diagrams with metadata that includes model numbers and locations.
- Implement clause-based verification that refuses to answer when evidence is insufficient.
- Run a test sweep for false-premise questions and multi-hop scenarios.
Final operational note
Vectors are an essential tool, but they’re just one part of the solution. A reliable agent uses a combination of techniques: exact lookups for identifiers, structured queries for numbers, graph traversal for relationship questions, and multimodal retrieval for images. When I design agents I pick retrieval strategies to match the question type. This approach lowers hallucinations, increases coverage, and builds systems people actually trust.
