

I created a video that walks through how I built a dynamic hybrid RAG (Retrieval-Augmented Generation) search engine in n8n, and this article captures that same approach in detail. My goal here is to explain why vectors alone often fail, how different retrieval methods work, and how you can combine them so an AI agent retrieves the right information every time.
Why vectors aren’t enough
RAG systems live or die by retrieval. If the agent can’t fetch the right chunk of text, it can’t produce a correct answer. Most modern tutorials stop at dense embeddings. Dense vectors are excellent for capturing meaning, but they struggle when you need exact matches. Example: product codes, serial numbers, or small tokens hidden inside messy PDFs. Those often get lost during tokenization or text extraction.
I tested this firsthand. I loaded 10GB of product manuals into a Supabase vector store. That resulted in roughly 215,000 chunks. I then asked a few simple questions about a random Whirlpool refrigerator manual and got disappointing replies. The agent couldn’t find a specific product code that I knew was present in the dataset.
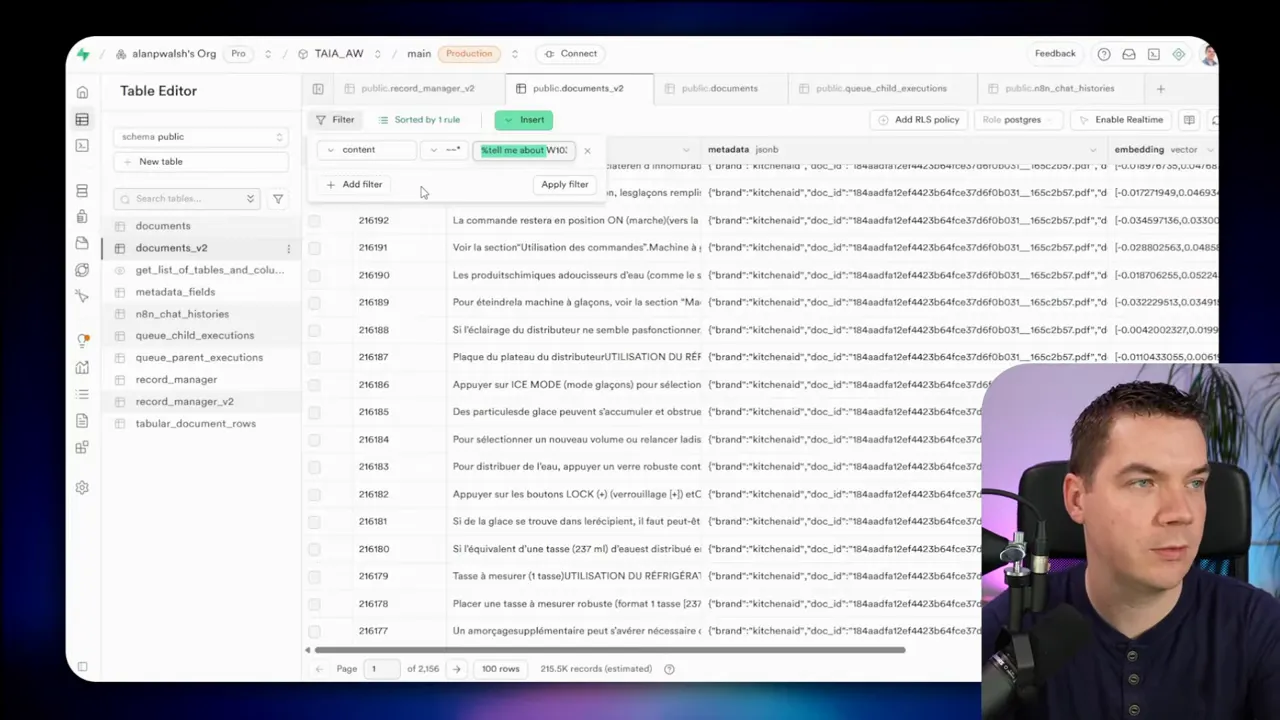
To debug, I used a direct wildcard search on the documents table and found four rows containing that code. That told me the data was there, but my RAG agent was failing to fetch it. That led me to explore the retrieval stack in detail and ultimately build a hybrid system that lets the AI dynamically change search weights depending on the query.
Overview: the three retrieval methods
My hybrid system combines three complementary retrieval approaches:
- Dense embeddings — semantic, vector-based retrieval.
- Sparse lexical retrieval — tokenized full-text search such as BM25 or TSVector.
- Pattern-based retrieval — character n-gram or trigram search, wildcard and regex matching, and fuzzy matching.
Each method has strengths and weaknesses. My system lets an LLM decide which to prioritize for a given query. If the query looks like a product code, the agent shifts weight toward pattern matching. If the query is conceptual, the agent favors dense retrieval.
Messy, unstructured data: the root of many retrieval issues
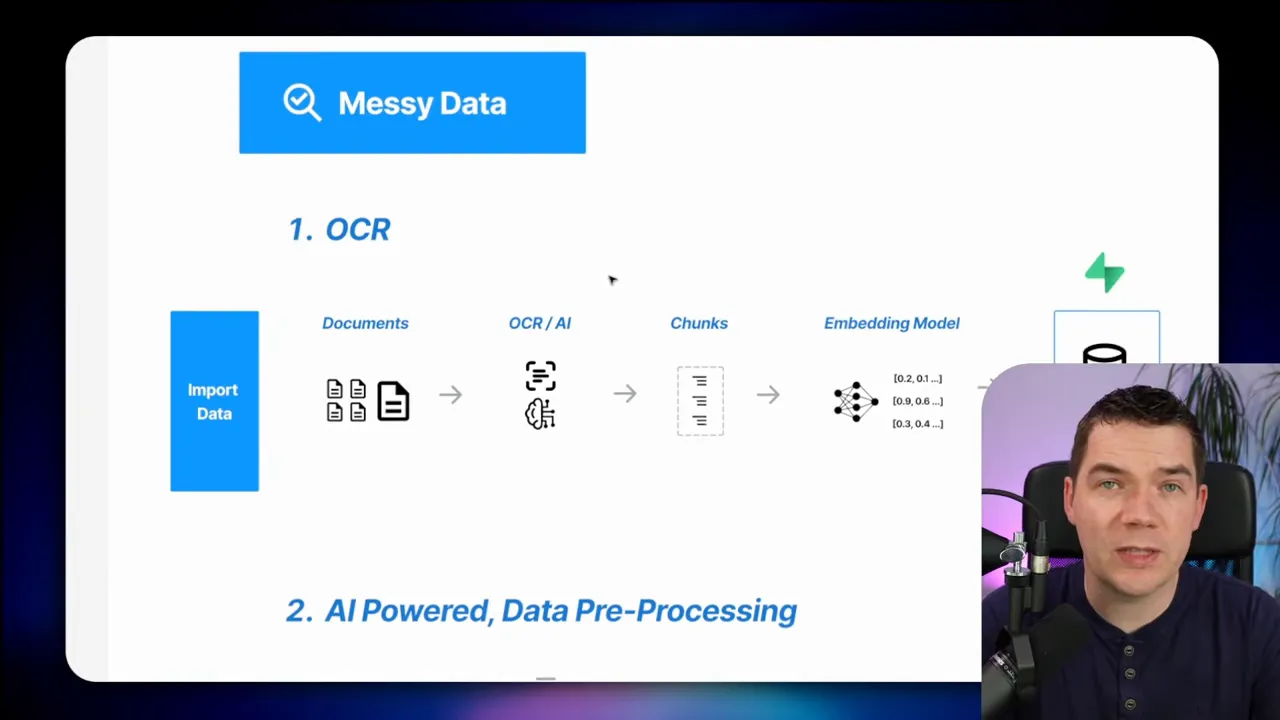
Most enterprise data is unstructured. PDFs, Word docs, emails, transcripts, and scanned documents make up a large portion of useful content. These formats often lose layout and structure during extraction, which breaks search.
In my example, a 36-page manual became about 200 chunks. Only two of those chunks actually contained the product code text as a contiguous substring. The extraction tool I used in n8n pulled machine-readable text but ignored layout. Lines bled together. Words and codes merged with surrounding text. The extracted token stream was noisy and inaccurate.
There are two pragmatic approaches to fix this at ingestion time:
- Use OCR that preserves layout. Services such as Mistral OCR can keep headings, tables, and formatting. Proper OCR often yields cleaner chunks with correctly positioned tokens. OCR isn’t perfect for all scans, but it usually helps a lot.
- Preprocess with human or AI-assisted extraction. Send chunks into an LLM to extract structured metadata or chunk descriptions. Then prepend that cleaned information to the chunk or add it as metadata. This step can save you from teasing answers out of noisy text later on.
Even with these improvements you’ll never achieve a perfectly clean dataset. That’s why you must provide retrieval fallbacks. Those fallbacks are what make a RAG system dependable.
Dense embeddings explained
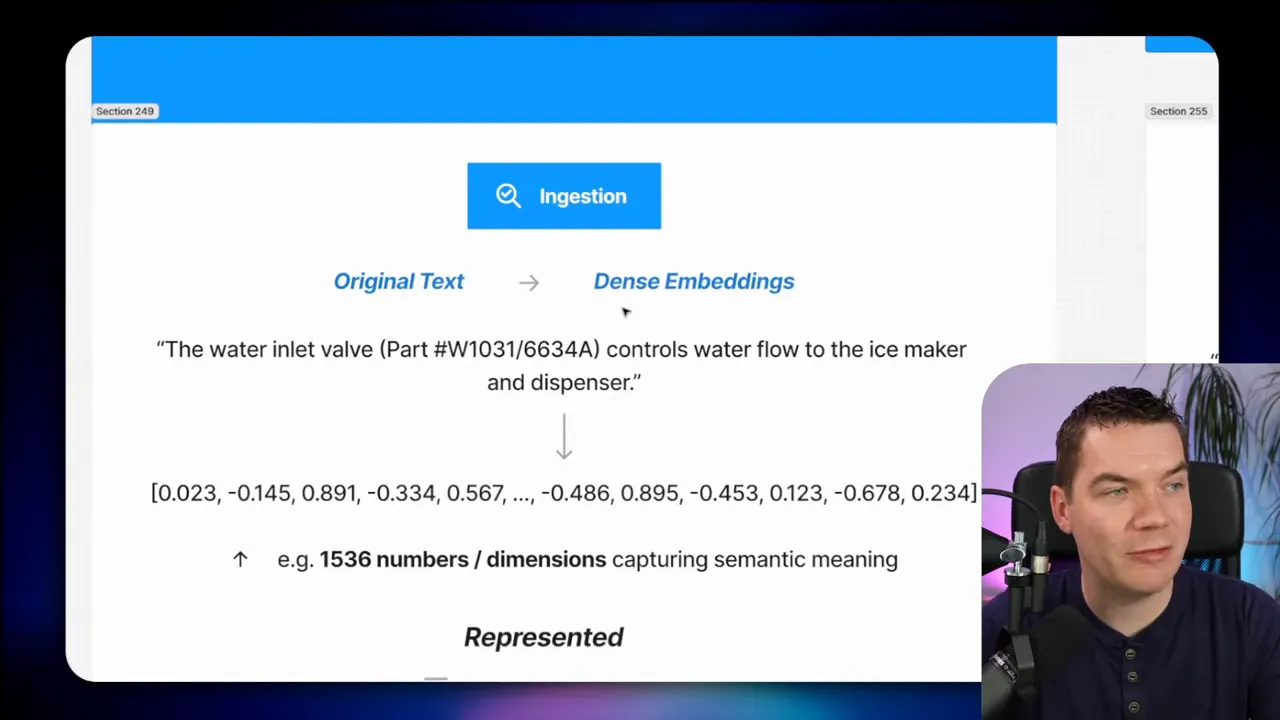
Dense embeddings represent text as high-dimensional vectors. When you ingest a document, you transform each chunk into a vector using an embedding model (for example, OpenAI text-embedding-3-small).
Vectors capture semantic meaning. If a chunk discusses cars, its vector will be close to other car-related vectors. Queries are also converted to vectors. The vector store then finds the nearest neighbors using measures like cosine similarity.
Why dense embeddings are powerful:
- They discover conceptually related content even across different wording.
- They handle synonyms and paraphrases.
- They can be multilingual (depending on the model).
Why dense embeddings sometimes fail:
- They’re opaque. You rarely know why a match was returned.
- They don’t guarantee exact string matches. They’ll return conceptually relevant chunks rather than exact matches of codes or IDs.
- They rely on the model’s prior training. Arbitrary part numbers and internal codes aren’t part of that general knowledge, so embeddings might not place them meaningfully in vector space.
In practice, dense embeddings are best for conceptual questions: “Why won’t my ice maker make ice?” or “How do I optimize performance?” If you need an exact product code match, dense vectors are unlikely to be sufficient on their own.
Sparse lexical retrieval: inverted indexes and sparse embeddings
Sparse lexical search covers a family of techniques grounded in tokenization and indexing. Classic approaches include BM25 and TF-IDF. A modern Postgres implementation uses TSVector and TSRank. Learned sparse models (such as some Pinecone offerings) produce sparse vector-like representations keyed by term IDs and weights.
How traditional inverted index search works:
- Text is tokenized by an analyzer. The analyzer may lowercase, stem words, remove stop words, and strip punctuation.
- Tokens and their positions are stored in an inverted index (mapping tokens to the documents that contain them).
- At query time, the query text is tokenized in the same way, then tokens are looked up in the index. Candidate documents are scored and returned in rank order.
Why lexical retrieval helps:
- It offers explainable matches. You can see which tokens matched and why.
- It’s fast and precise for many queries.
- It’s the backbone of most search engines and enterprise text search.
Why lexical retrieval fails in some cases:
- It’s language-dependent. Tokenizers assume language-specific rules; a single tokenizer struggles with mixed-language content.
- It can break apart codes. A part number that contains punctuation or appears without spaces can be mis-tokenized, producing tokens that don’t match a user’s query.
- It has trouble with typos and partial matches unless you add fuzzy matching layers.
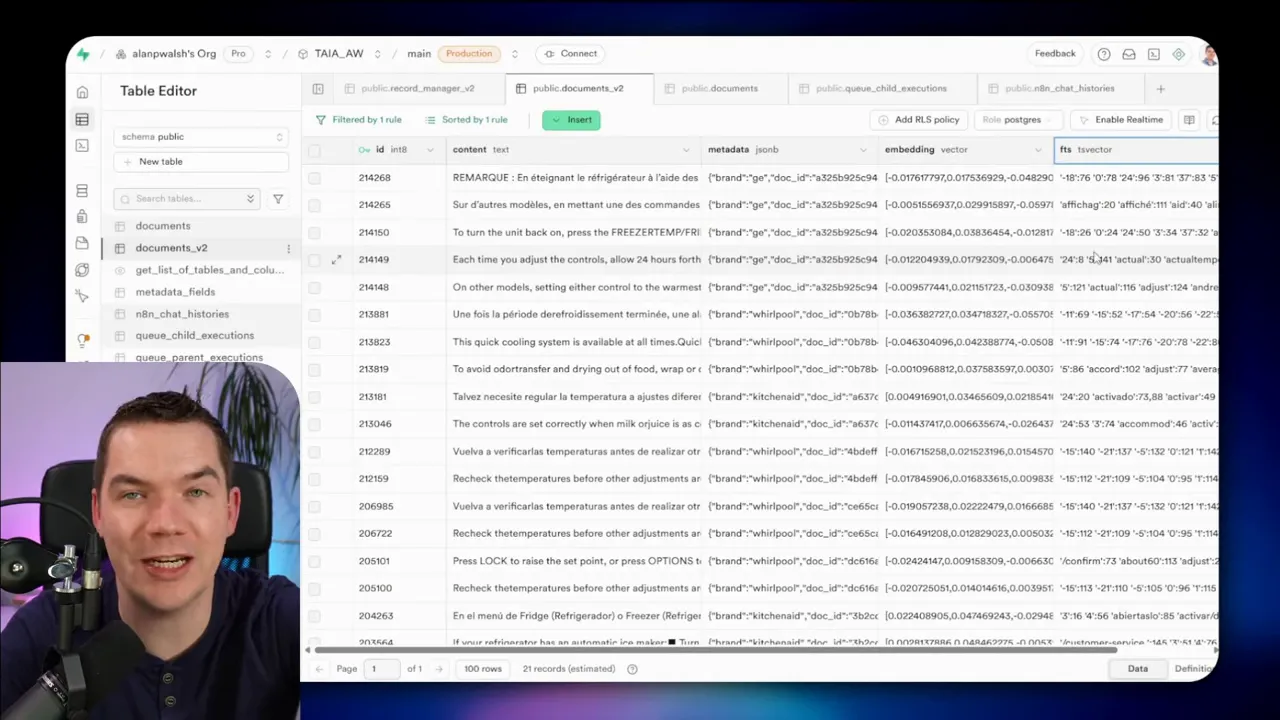
I saw all of these problems in my experiments. The TSVector index in Supabase extracted tokens that looked bizarre when the source text lacked proper whitespace. The part number got split and mangled, so a straightforward full-text query didn’t return the expected chunk.
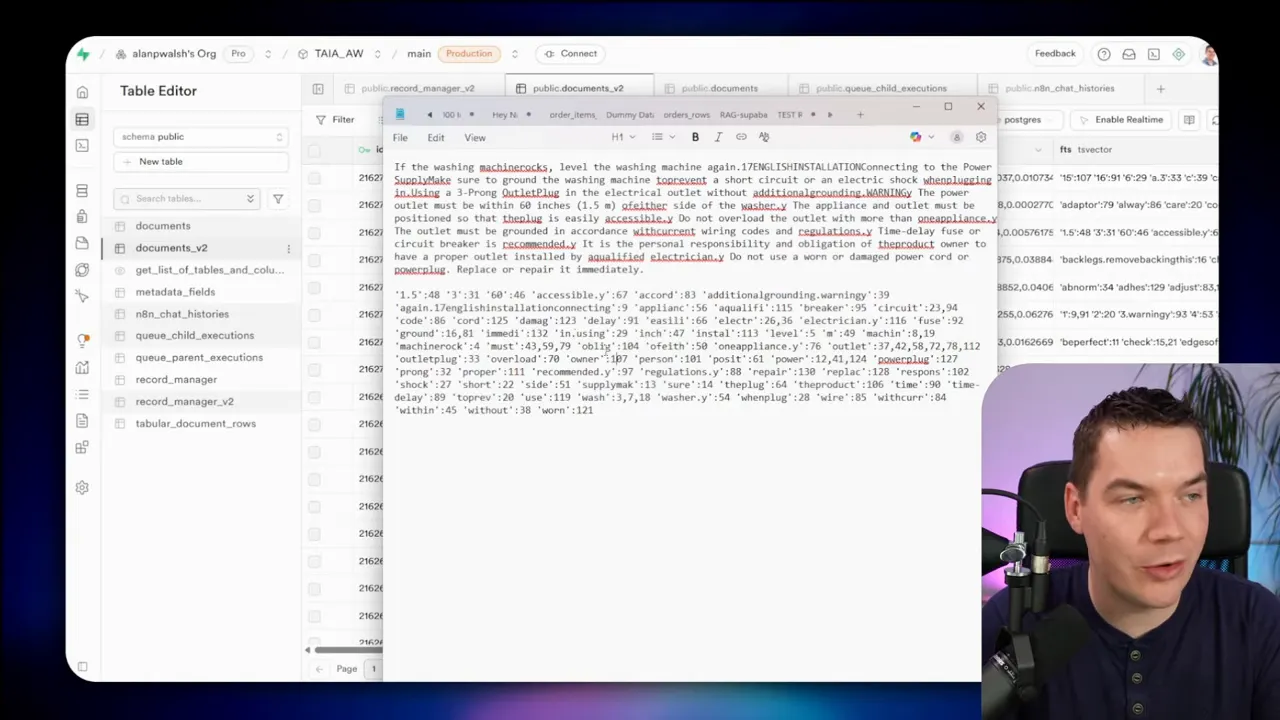
Sparse learned representations
Learned sparse models blend some advantages of dense and lexical methods. They map text to term IDs and weights. The model has a vocabulary and produces a sparse embedding indicating which vocabulary terms matter and how important they are.
I tested Pinecone’s Sparse English V0 model. It returns indices and weights — term IDs mapped to weights. A word like “water” might map to an ID with a weight of 0.78 in context.
Learned sparse is a step up from raw inverted indexes in some domains. You get semantic expansion and weighted term importance. However, it still requires specific training data and language assumptions. It won’t reliably match arbitrary codes unless the model’s vocabulary and training implicitly support those patterns.
Pattern-based retrieval: n-gram and trigram matching, wildcards and fuzzy matching
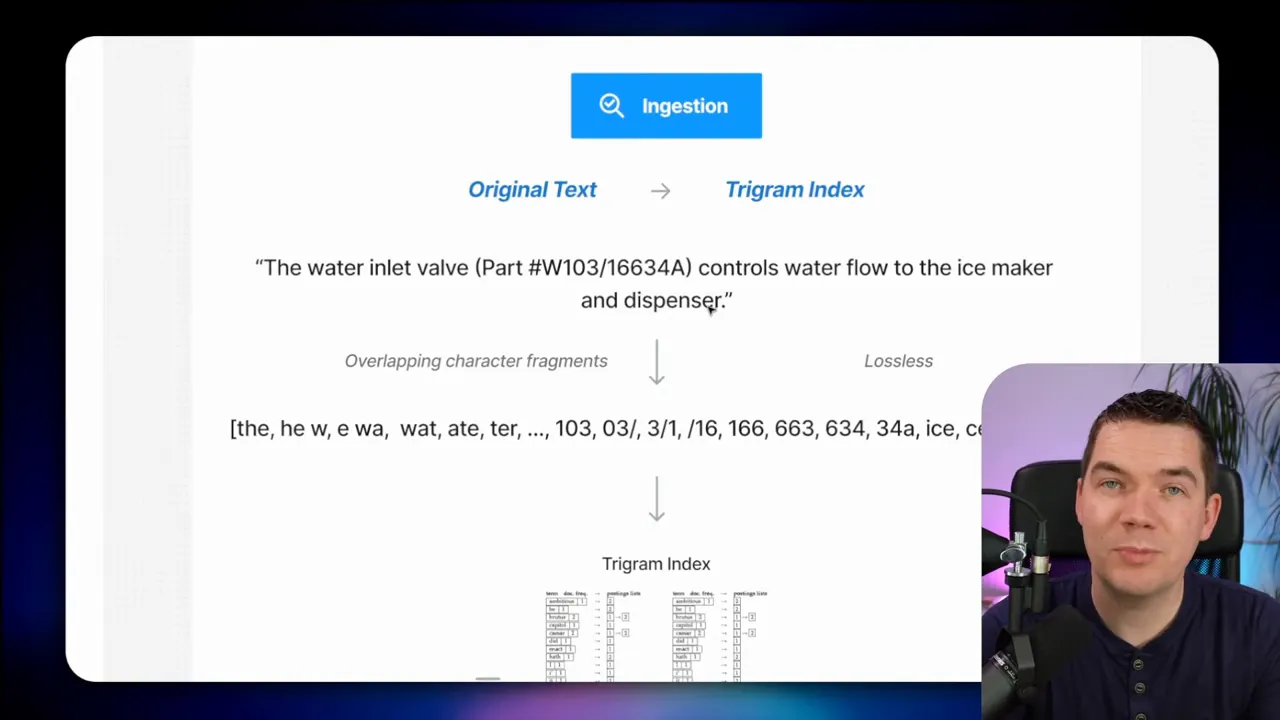
When both dense and sparse retrieval fail to find an exact token or code, pattern-based retrieval can step in. This approach treats text as overlapping character fragments rather than tokens. The most common implementation is n-gram indexing. I used trigram (3-character) fragments in my tests.
How n-gram indexing works on ingestion:
- Take the original text chunk.
- Generate overlapping character fragments. For trigram indexing, create sequences like “THE”, “HE ”, “E W”, “ WA”, “WAT”, and so on.
- Store these fragments in an index that maps each fragment to the chunk(s) that contain it.
How queries work:
- Break the query string into the same character fragments.
- Look up those fragments in the trigram index.
- Aggregate and rank candidate chunks by how many fragments align with the query.
This method excels at substring matches. If a product code appears almost exactly as a substring within a chunk, pattern matching finds it. It also supports fuzzy matches and simple regexes. Because you match characters, the process is language-agnostic. It works even with mixed-language chunks or languages that use non-Latin scripts (though you must ensure the right character handling).
Tradeoffs of pattern matching:
- High precision on exact and near-exact matches.
- Good for fuzzy matching of typos and partial codes using edit distance approaches.
- Indexes can become large because many overlapping fragments are stored for each chunk.
- The similarity score is rudimentary. It reflects fragment overlap more than semantic relevance.
In my tests, wildcard searches on the Supabase table without trigram indexing took around two seconds. With a trigram index, the same search dropped to about 100 milliseconds. That’s well within acceptable bounds for an interactive agent.
Putting it together: dynamic hybrid search
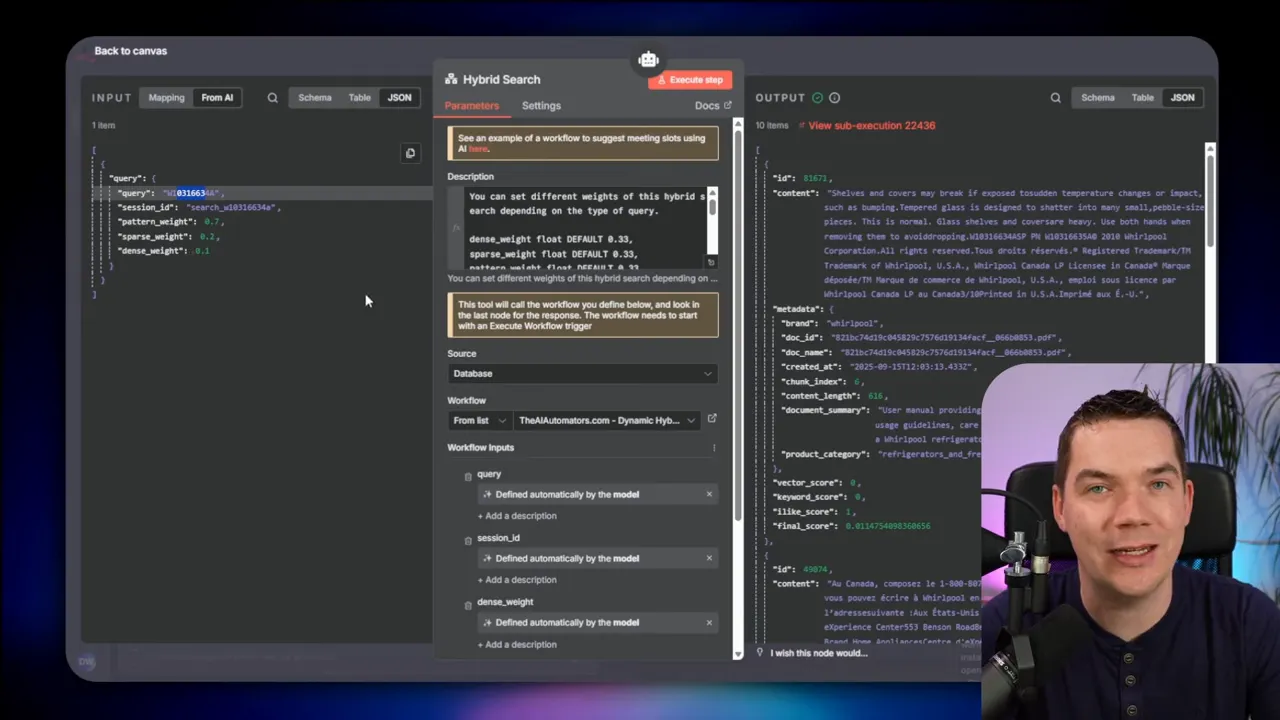
After exploring each retrieval method, I built a dynamic hybrid search function. The core idea is simple: treat dense, sparse, and pattern matching as tools. Let the agent pick the weights for each tool based on the query.
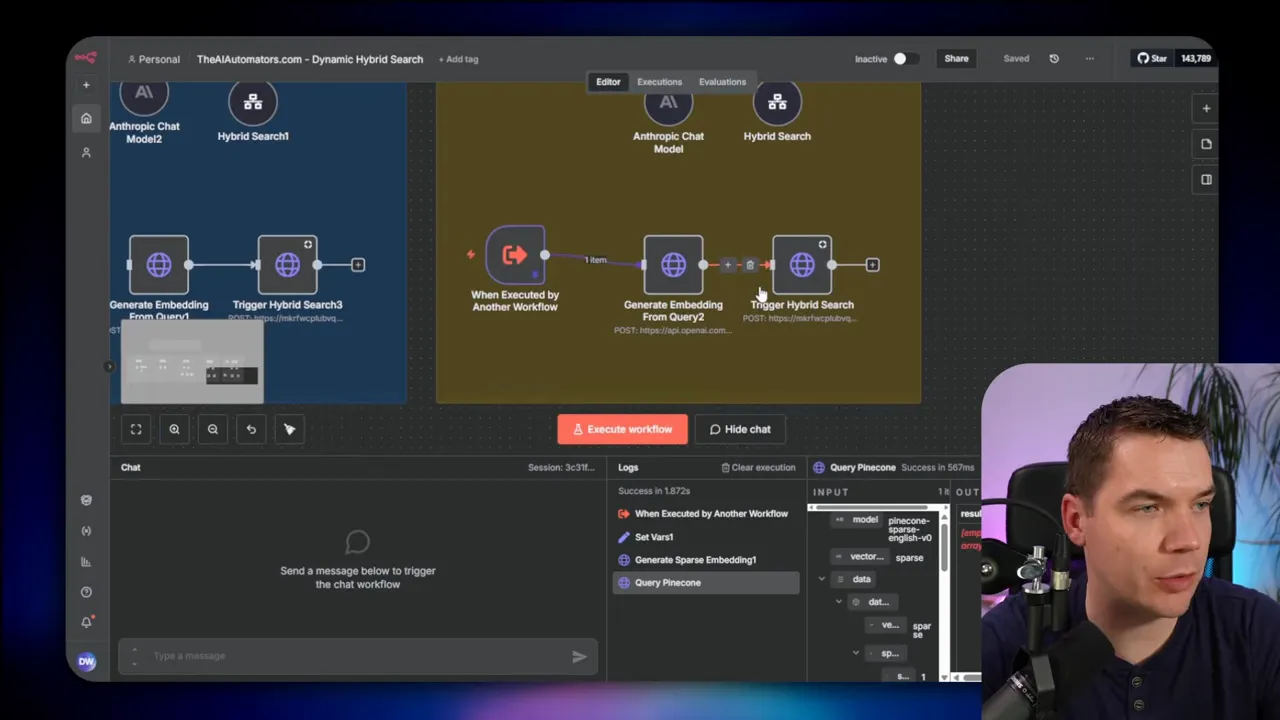
Here’s the high-level architecture I implemented in n8n:
- The agent receives a user query.
- The agent (an LLM) reasons about the query and returns a set of weights for the three retrieval methods. It also returns the query text and any metadata filters.
- An n8n workflow prepares a payload that contains the dense query embedding, the raw query text, and the chosen weights.
- The payload is sent to a Supabase edge function that relays it to a database function.
- The database function runs three weighted queries (vector, TSVector, and ILIKE/wildcard or trigram lookup), and it fuses the results using Reciprocal Rank Fusion (RRF).
- The fused results are returned to the agent, which generates the final answer.
This setup keeps queries efficient and makes the agent adaptable. For a part number query, the agent may set pattern matching to 70%, sparse to 20%, and dense to 10%. For a conceptual query, the weights flip toward dense retrieval.
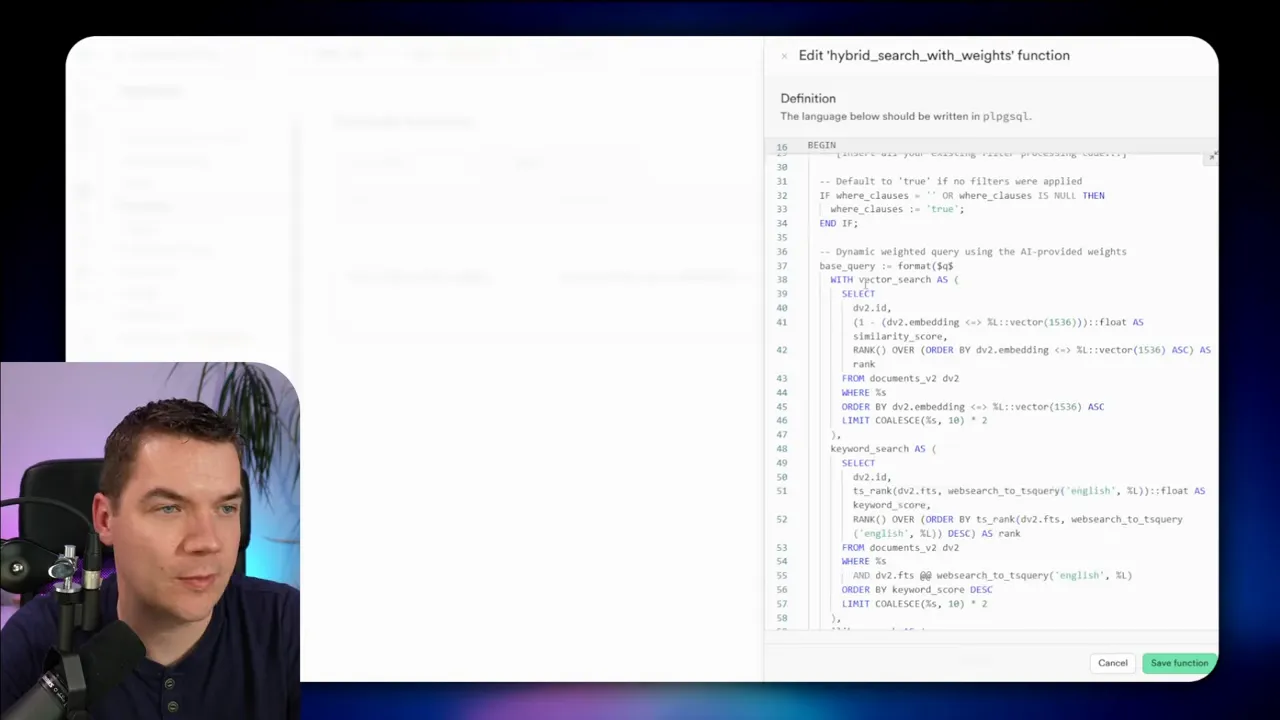
How I implemented weighted retrieval in the database
The database code sits at the heart of the hybrid search. I used a Supabase/Postgres database function that accepts multiple arguments. These include the dense embedding vector, the raw query text, metadata filters, and three weight parameters for vector, keyword, and pattern matches.
Inside the function I do several things:
- Declare variables and normalize inputs.
- Apply metadata filters to narrow the candidate set if needed. This helps when you want to search within a subset of documents (for example, a single product family or language).
- Run a vector query against the embedding column using cosine similarity or the appropriate Postgres extension.
- Run a TSVector full-text search on the FTS column and compute TS_RANK to score lexical matches.
- Run an ILIKE/wildcard query or trigram-based lookup on the content column for pattern matches.
- Apply scoring multipliers based on the incoming weights.
- Fuse the result sets using Reciprocal Rank Fusion to produce a final ranked list of chunks.
Reciprocal Rank Fusion is particularly useful here because it combines ranked lists without requiring raw scores from each system to be comparable. RRF simply sums the reciprocal ranks (e.g., 1/(k + rank)) across sources. The weights can scale the contribution of each source, effectively boosting or reducing the importance of a result’s rank in a given retrieval method.
I iterated on the function with a few LLM-assisted prompts and fine-tuned the logic. The final function was longer than the average SQL procedure, but it remained manageable because each step was modular.
How the agent decides the weights
The weight decision happens in the LLM layer. I designed the agent to look at the query and metadata, then return a small structured payload with weight values for the three retrieval types.
Examples of weight decisions:
- “Find information about product code X123-45-A” → pattern 70, sparse 20, dense 10.
- “Why does the ice maker not work?” → dense 60, sparse 30, pattern 10.
- “Show troubleshooting steps for model XY-200” → dense 40, sparse 40, pattern 20.
The LLM uses simple heuristics. If the query contains a long alphanumeric token, punctuation-heavy codes, or patterns that look like IDs, it favors pattern matching. If the query is a how/why conceptual question, it favors dense embeddings. If a query references a common phrase or well-known term, the LLM may prefer sparse search since TSVector handles common expressions well.
That reasoning is straightforward for a human. It’s also simple enough for an LLM to perform reliably in production when you constrain it to a few clear rules and examples. The LLM then sends the numeric weights to the n8n workflow, which builds the hybrid search payload.
Real examples I ran
Two queries illustrate how the hybrid approach helps.
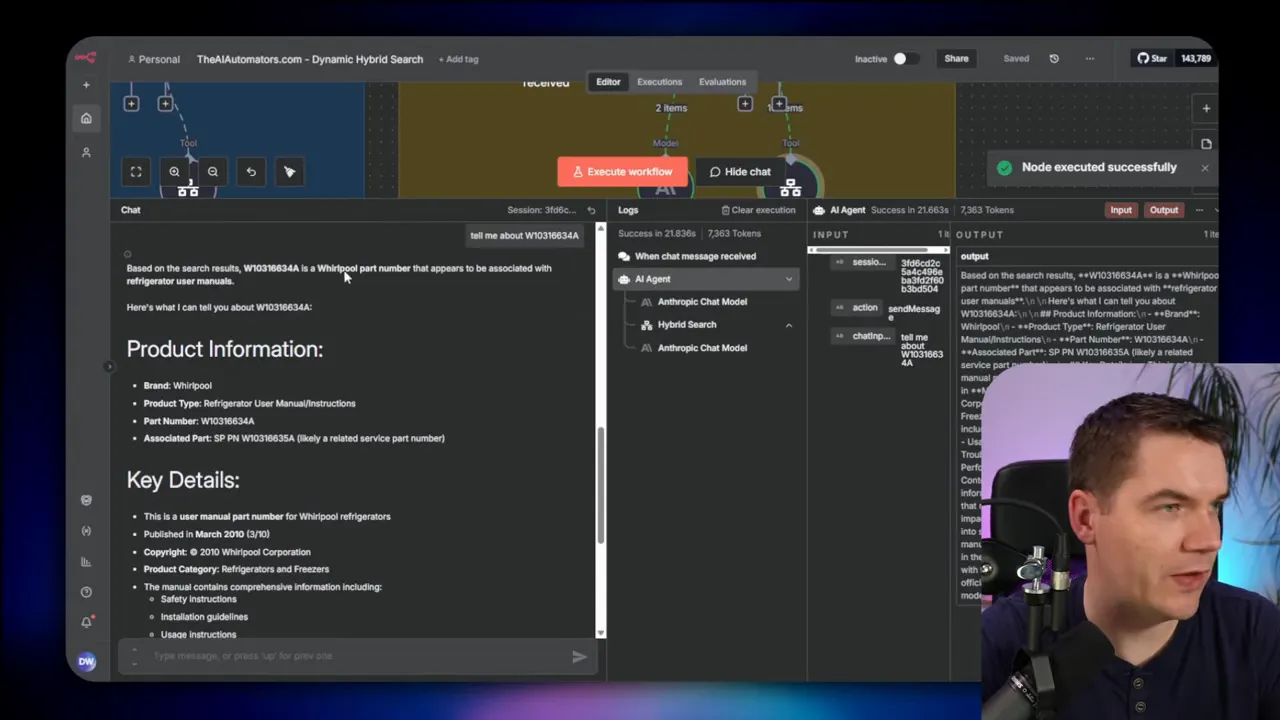
Query: “How do I turn on the ice maker?”
I ran this query with no product code. The TSVector full-text search in Supabase returned several relevant chunks about ice makers and controls. Dense embeddings also returned conceptually similar chunks. The hybrid fusion produced a coherent answer that included steps and safety notes. The system worked well because the question was conceptual and text describing procedures is easy for dense or lexical search to find.
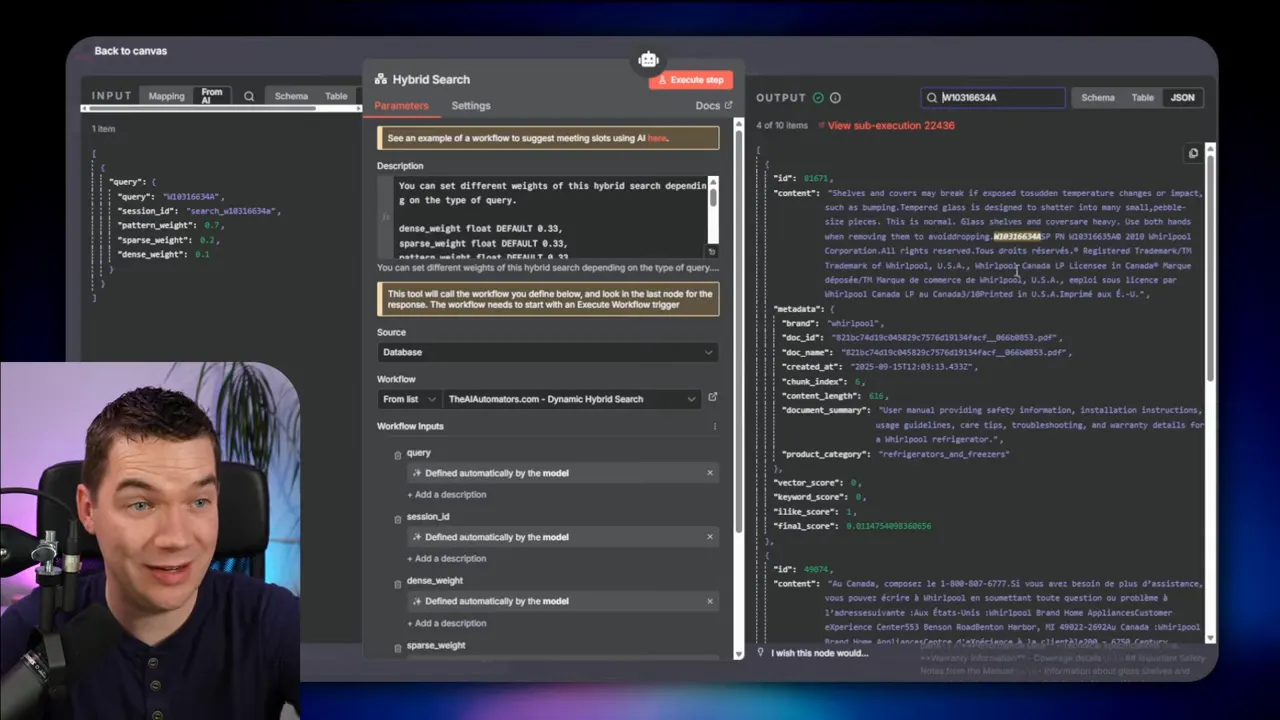
Query: “Tell me about product code X-AB123-7Z” (example)
For this code search, dense embeddings returned no useful chunks. The TSVector index also missed the exact code because tokenization had mangled the raw extraction. Pattern matching returned the exact chunks that contained the code as a substring. Once the agent had those chunks, it assembled a correct and specific answer, including product type, manual references, and related parts.
That retrieval success came from switching retrieval weight to pattern matching. In the hybrid call, the agent set pattern to 70%, sparse to 20%, and dense to 10%. The database fused results accordingly and returned the correct chunks.
Pattern matching details and optimizations
Pattern matching isn’t complicated, but there are some implementation details that matter.
- Trigram indexing: Create a trigram GIN or GIST index on the content column in Postgres. This accelerates wildcard and similarity searches dramatically.
- Use ILIKE for simple wildcard matches: ILIKE ‘%code%’. This is simple and effective, but slow without trigram indexing.
- Fuzzy matching: Implement edit-distance or Levenshtein filters when you need to catch typos. Levenshtein works well for short alphanumeric tokens.
- Regex for patterns: When codes follow a structured format (e.g., letters-digits-letters), leverage regex to find that exact pattern.
- Limit candidate set with metadata: If you know the product family or language, apply metadata filters first so pattern searching runs on fewer chunks.
One important optimization is to keep the pattern search lightweight in the hybrid fusion step. If pattern matching returns a lot of low-quality matches, it can drown the fused results. Use thresholds for pattern similarity or require a minimal overlap score for trigram matches.
Handling multilingual content
Multilingual data complicates tokenization. The TSVector pipeline expects language-specific analyzers. If your data mixes English and French in the same document, tokens get mixed and search quality drops.
Options to manage mixed languages:
- Detect language during ingestion and split chunks by language attribute. Index each chunk with its language-specific analyzer.
- Store the original text and an OCR/cleaned version as separate fields. Use the most appropriate field for the search method.
- Rely more on pattern matching for tokens and codes that are language-agnostic.
In my tests, the Whirlpool manual contained both English and French. That mixed content contributed to tokenization errors in TSVector and complicated learned sparse models. Pattern-based retrieval bypassed the tokenization step since it matches characters rather than tokens, which is why it succeeded where others failed.
Index sizes, performance, and costs
Each retrieval method has storage and performance implications.
- Dense vector store: Embeddings add a 1,024–1,536-dimensional vector per chunk. That consumes space and increases vector DB costs (Pinecone, Milvus, etc.).
- Inverted index / TSVector: Efficient for tokens. Postgres with TSVector is space-efficient and cheap to run for many use cases.
- Trigram / n-gram: Can blow up index size because every chunk stores many overlapping fragments. Expect larger storage needs for trigram indexes.
Balancing cost and performance:
- Shard or partition data by domain or product set. Keep trigram indexes on subsets that actually need them (e.g., parts catalogs).
- Store embeddings only for chunks you expect to need semantic search for. Use hybrid ingestion logic to decide which chunks get dense vectors.
- Use metadata filters to reduce the search space early. That lowers query cost and improves response latency.
In my experiments, binary searches on trigram indexes with proper indexing delivered roughly 100ms query times. Vector queries can vary based on vector DB configuration. Sparse TSVector queries are typically very fast in Postgres.
Reliability and explainability
Explainability matters in production. Dense vectors lack transparency, which can be problematic for regulated industries or when auditing is required. TSVector searches are transparent: you see the tokens and can explain why a result matched. Pattern matching is also transparent; you can point to the exact substring that matched.
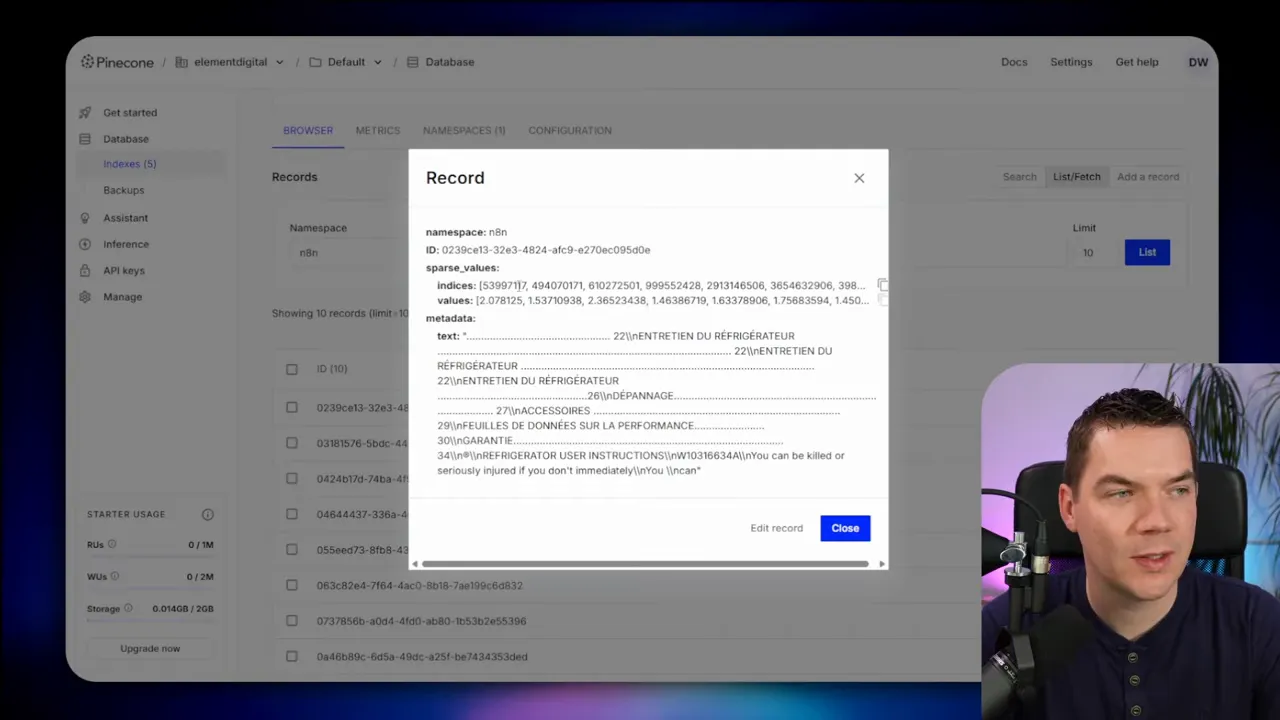
To increase trust, I include provenance data with each chunk: document ID, chunk index, page number, and a short chunk summary. When the agent returns an answer, it also provides the source chunks and highlights the matching lines. That makes it easy to verify the agent’s output.
Practical recommendations for building dynamic hybrid RAG
Here are concise steps to implement a production-ready dynamic hybrid RAG system similar to mine:
- Ingest and OCR all PDFs and scanned docs to preserve layout. Use an OCR tool that returns structured output where possible.
- Split documents into chunks with a sensible length and overlap. Include page number and chunk index as metadata.
- Create multiple indexes in your storage layer:
- Dense embeddings in a vector DB for semantic search.
- TSVector or an inverted index in Postgres for lexical search.
- Trigram or n-gram index for pattern matching where needed.
- Build an LLM-based agent that returns retrieval weights based on simple rules and examples. Keep the rules constrained and test them widely.
- Implement a hybrid search function that takes embeddings, raw query text, weights, and metadata filters. Run the three retrieval steps and fuse results using Reciprocal Rank Fusion or a similar algorithm.
- Return matched chunks with provenance and allow the agent to load or summarize the full document if a deep dive is needed.
- Monitor and log retrieval decisions so you can refine weight heuristics and address failure cases.
Following these steps will reduce hallucination by ensuring the agent has access to the most precise chunks for any given query.
Edge cases and failure modes
No system is perfect. Expect some edge cases and design fallbacks:
- Partial code matches: Use trigram overlap and set a minimum similarity threshold. If a match is weak, return a clarifying prompt rather than a definitive answer.
- Confused tokenization: For documents with heavy formatting or unusual separators, create a preprocessing step that cleans or normalizes separators before indexing.
- Empty or null embeddings: Guard against empty text or truncated chunks. Truncate inputs to the embedding API’s limits and log truncated passages.
- Multilingual noise: Detect language and prefer pattern-based searches for language-mixed chunks when looking for codes.
- Large result sets: Cap candidate lists from each retrieval method and then fuse the top-k lists. Don’t try to fuse all matches; that wastes compute and harms precision.

What I automated in n8n
I built the entire orchestration in n8n for several reasons:
- n8n lets me compose tools easily. The agent and search subworkflows are simple to link.
- I can reuse subworkflows for sparse, dense, and hybrid searches without duplicating logic.
- It’s straightforward to send the payload to a Supabase edge function and then to a database function.
The workflow looks like this:
- User query arrives in the chat flow.
- Agent reasons and returns a payload: weights, query text, any metadata filters.
- n8n generates a dense embedding for the query and attaches it to the payload.
- n8n calls the hybrid search edge function in Supabase with the dense embedding, raw query, and weights.
- Supabase relays the request to the database function, which runs the weighted searches and returns fused results.
- Agent consumes the returned chunks and generates a final answer, including chunk provenance.
Because each retrieval method is modular, I can swap providers easily. I use Pinecone for sparse learned embeddings and Supabase/Postgres for TSVector and trigram indexing in my experiments. You can replace Pinecone with any vector DB that supports sparse or dense vectors.
Next practical step: load or summarize the full document
Once the agent finds a relevant chunk, the natural next step is to provide a tool to load the full source document or to produce an automatic summary. That makes the answers richer and allows users to inspect the context. I plan to build a tool that optionally loads the entire document or runs a focused summarization workflow for any returned document ID. That tool will be another callable step in the agent’s toolkit.
Building this additional tool will let the agent answer follow-up questions like “Show the whole section that mentions this part number” or “Summarize the entire manual.” It also reduces the chance of a partial-answer problem where the agent cites a short snippet without enough context.
Summary of lessons learned
I’ll highlight the main practical lessons from my experiments:
- Dense embeddings are necessary but not sufficient. They capture meaning, not exact text.
- Lexical retrieval is reliable and explainable, but it depends heavily on tokenization quality.
- Pattern-based retrieval is the secret weapon for product codes, IDs, and fuzzy substring matches.
- Combining these methods and letting an LLM dynamically weight them yields much higher precision than any single approach.
- Preprocessing at ingestion (OCR, language detection, and AI-assisted extraction) reduces many failures but cannot eliminate them entirely.
- Provenance and transparency in results increase user trust and make debugging easier.
Each of these lessons influenced how I structured the hybrid search and the agent’s tools. The hybrid approach makes the RAG agent robust against messy data and real-world documents.
That covers the full architecture and the reasoning behind each choice. The final system is flexible, fast, and accurate for both conceptual questions and exact code lookups. It brings together semantic understanding and precise pattern matching so the agent can answer reliably across a broad range of queries.
